前言
在业务迭代中,随着数据量的上升,会出现慢SQL情况,但是当我们去分析单条SQL的时候,发现其执行速度并没有那么慢,原因是什么呢,那么就可能是RDS服务器IO产生了瓶颈。
日常,我们可以通过 IOPS(Input/Output Per Second) 指标来衡量 IO 是否处于健康的范围。我们使用的阿里云 RDS 通常根据不同的规格做了不同的 IOPS 限制。如果短时间内频繁的操作,不管是 SELECT 带来的读磁盘操作,还是 INSERT、UPDATE、DELETE 带来的写磁盘操作,均可能会触发最大 IOPS 限制。本文将从实际业务分析,探讨根据 IOPS、Redo 写次数等指标定位 IO 触发瓶颈的原因,如何优化。
一、业务背景
活动 MySQL 规格:4C,最大连接数 2500,最大 IOPS 4500。
早上 10 点,是活动业务 QPS 最高的时候,因为这时候通常会释放奖品库存。有段时间,监控爆出了慢 SQL 的问题,但是通过监控指标观测 QPS 的时候,并没有到达预想中的峰值,但是读写RT会出现一些突刺。再进而查看 IOPS 指标,我们发现异常得高,如下图:

阿里云 RDS 中 MySQL 的 IOPS 指标

阿里云 RDS 机器的 IOPS 指标
你可能会发现 RDS 实例最大限制不是 4500 吗?为何这里已经达到了 11000 以上了呢?起初我理解的是 MySQL 统计 IOPS,大部分操作都命中了缓冲区,限制的磁盘 IOPS。后面也咨询了 DBA,说是 IOPS 其实没办法准确限制。这到底是什么情况?我们接着往后看。
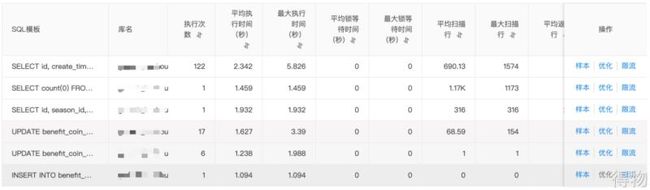
这时候会统计出来一些查询类的慢 SQL,我们优先去分析这些 SQL 的执行计划,发现其走了索引,也会回表,扫描的行数比较大:
同期慢 SQL 统计
产生慢 SQL 的表,是一张业务明细表,每个用户平均每天产生的数据量约 20 条,假如日活 5w 的话,每天的增量 100w,半年产生的数据约 2 个亿,该业务已持续运营 一年以上。那么面对这样的场景,我们该如何定位原因、如何动手优化呢?
二、分析方法
各个业务线有很多预警、告警,很容易监控到 RDS 运行异常问题。当我们拿到异常的时候,首先肯定是通过监控图表观测技术指标,确定影响范围,设计止血方案,然后才是定位问题,解决问题。
相对来说,IOPS 过高等告警都是短暂性的,一般发生在业务高峰期。这种情况经常是渐变产生的,随着业务增长,数据量也在增长,表结构也越来越复杂,一些早期的 SQL 在索引选择上发生了变化,取得目标数据扫描的行数越来越多。
1. MySQL 指标
上面的业务背景中数据库 QPS 峰值 1 w,TPS峰值 2.5 k。下面结合这个前提来分析 MySQL 的运行指标。除了上面提到的 IOPS 指标,Buffer pool 请求次数、Redo 写次数等数据指标,这些健康指标协同起来看,会发现该时段真实产生的读、写操作都比较频繁。
其中 innodb_rows_read 已经达到 22w 以上,innodb_rows_updated 达到 1w 以上,相对来说读操作被放大了 22 倍,写操作被放大了 4 倍。
(1) Redo 写次数

(2) Row Operations

(3) Buffer Pool 请求次数

(4) 慢 SQL
(5) 其他指标
如果 MySQL 在 IO 方面出现了阻塞的现象,也可以观察以下几个指标:
参数名 |
意义 |
备注 |
Innodb_data_pending_fsyncs |
当前阻塞的 fsync 操作 |
一般为 0,比较高的话,看一下 innodb_flush_method 的设置 |
Innodb_data_pending_reads |
当前阻塞的 read 操作 |
一般为 0,如果指标较高且影响业务的话,参考读压力的应对方式 |
Innodb_data_pending_writes |
当前阻塞的 write 操作 |
一般为 0,如果指标较高且影响业务的话,参考写压力的应对方式 |
Innodb_os_log_pending_fsyncs |
写redo log 时,当前阻塞的 fsync 操作 |
一般为 0,如果大于 0 的话,通常就是 IO 设备的瓶颈,考虑把 redo log 迁移到 SSD 或者做 IO 隔离,独占 IO 设备的性能 |
Innodb_os_log_pending_writes |
写redo log 时,当前阻塞的 write 操作 |
一般为 0,如果指标较高且影响业务的话,参考写压力的应对方式 |
这些指标阿里云未在健康图表上给出,应该是觉得目前的图表已经够用了。这些指标可通过登录 RDS 执行 show global status like '%innodb%read%' 查看,但是这类指标一般是累计值,需要对比上一个取值时间的差值才能有比较实际的作用,通常也是用来判断 MySQL 的读写比例用,结合上表的 pending 数据和其他的系统指标来综合判断 IO 系统的负载。
2. 机器I/O分析
一般情况,业务开发无法直接或者间接访问 RDS 机器的,经常由 DBA 统一管理。这里,我们可以了解一下 Linux下I/O 分析工具。
(1) iostat
iostat -x

关于 CPU 的指标,我们重点看 %iowait 和 %idle 两个指标。
%iowait:CPU 等待输入输出完成时间的百分比;
%idle:CPU 空闲时间百分比。
若%iowait 的值过高,则表示硬盘存在 I/O 瓶颈;若 %idle 值高,表示 CPU 较空闲。如果 %idle 值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量。%idle 值如果持续低于 10,那么系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
关于 Disk 指标,我们重点看 %utils、svctm、await 和 avgque-sz几个指标。
avgqu-sz: 平均 I/O 队列长度;
await: 平均每次设备 I/O 操作的等待时间 (毫秒);
svctm: 平均每次设备 I/O 操作的服务时间 (毫秒);
%util: 一秒中有百分之多少的时间用于 I/O 操作,即被 I/O 消耗的 CPU 百分比
若 %util 接近 100%,说明产生的 I/O 请求太多,I/O 系统已经满负荷,该磁盘可能存在瓶颈;若 svctm 比较接近 await,说明 I/O 几乎不需要等待;若 await 远大于 svctm,说明 I/O 队列太长,I/O 响应太慢,则需要进行必要优化;若 avgqu-sz 比较大,也表示有大量 IO 在等待。
(2) iotop
iotop -oP

通过输出结果,我们可以清晰地了解当前哪些进程在读写磁盘,以及读写速率和 IO 使用占比。
综上,通过 MySQL 指标及机器运行指标分析当前 MySQL 的 IO 健康状态,以及 IO 负载过高时的慢 SQL,我们再从慢 SQL 来分析其执行计划,从而根据具体业务场景来制定优化方案。
三、解决方案
当我们业务中遇到IO问题时,我们可以从以下几个方面考虑:SQL优化、配置优化、存储优化和硬件升级优化。
1. 硬件升级
硬件升级,可以说是解决常规性能问题的最有效且快速的方法。不管代码层面、 SQL 层面是多么低效,高配或者超配的硬件规格都能规避性能问题。在一些线上紧急问题处理场景中,不失为一种最优的快速止血方案。
比如上述的业务背景,IOPS 触发了机器的限制,那么我们将RDS升配至中等配置,IOPS 上限提高到 9000,便可以快速解决。问题是是否真的紧急和必要,其实 90% 业务场景的紧急程度并没有那么高,硬件升级也不是最合适的方案。
2. 存储优化
我一般将存储优化理解成分库分表、数据归档两个方面。何时进行数据归档,何时进行分库分表,也是老生常谈的问题。
数据归档:一般适用于历史数据几乎没有访问场景,比如说上一个赛季的金币记录、半年前的领取的活动津贴。这些历史数据的归档对于当前业务没有任何影响,数据量又增长得比较快。归档后只作为算法优化的底层数据,对业务接口的性能是非常有帮助的。
分库分表:历史数据有使用场景。比如说某个用户的历史订单,或者就是用户数据本身。这些数据不知什么时候用到,但又必须支持提供的。很长一段时间内都是很大量级存在的业务数据,建议分库分表。
那么做了以上两个优化后,对 IO 的正向影响就是减少了数据量,一些慢 SQL 扫描的行数自然下降。
3. SQL优化
SQL 优化又分为两个方向,既有索引下 SQL 语句的优化和索引调整层面的优化。根据具体业务场景及数据调整索引策略,这个方面没什么好说的,尽可能使得扫描的行数降低。
4. 配置优化
针对读操作场景,我们可以使用 innodb_buffer_pool_size 来减少 I/O 负载。
innodb_buffer_pool_size
我们可以通过此参数指定缓冲池的大小。如果缓冲池很小并且有足够的内存,那么通过减少查询访问InnoDB表所需的磁盘 I/O 量可以提高缓冲池的性能,从而提高性能。innodb_buffer_pool_size 选项是动态的,允许在不重新启动服务器的情况下配置缓冲池大小。
#设置大小 set global innodb_buffer_pool_size = 26843545600
针对写操作频繁的场景,我们可以利用 undo/redo log 和 binlog 的写入磁盘机制,来分析和配置这些参数:
innodb_flush_log_at_trx_commit
此项配置用来针对 undo/redo log 的磁盘写入配置。有3个取值:
-
0:会每隔1秒把缓存中的 undo/redo log 写入到磁盘;
1:每次提交事务(一般的 insert 和 update 都有事务)写入到磁盘,该方案最安全,也是最慢的;
2:写入系统的缓存,但会每隔一秒才调用文件系统的“flush”将缓存刷新到磁盘上去。这样 MySQL 即使崩了,系统缓存还在,比 0 的方案优。
如果我们可以在数据库服务器宕机的时候,允许有 1 秒的数据丢失,其实用设置为 2 是最优的方案,可以提高性能。
#查看当前配置 show variables like 'innodb_flush_log_at_trx_commit'; #设置生效 set global innodb_flush_log_at_trx_commit=2;
sync_binlog
此项配置用来针对 binlog 的磁盘写入配置,可以用来配置合并多少条 binlog 一次性写入磁盘。
-
0:代表依赖系统执行合并写入;
1:代表每次提交事务后都需要写入,方案最安全,也是最慢的;
N(一般100-1000):代表每N条后,合并写入磁盘。
针对sync_binlog,同样允许数据库服务器宕机的情况下能接受丢失N条数据的, 可以配置为N,能提高性能。
#查看当前配置 show variables like 'sync_binlog'; #设置生效 set global sync_binlog=100;
四、总结
最后简单总结一下 IO 问题分析,上面主要分析的是我们现在的活动业务,也就是随机读写频繁的场景,这时候 IOPS 是最为关键的衡量指标。另一个重要指标是数据吞吐量 (Throughput),指单位时间内可以成功传输的数据数量。对于大量顺序读写的应用,我们可以关注吞吐量指标。
通常我们可以通过硬件升级、SQL 优化、表结构优化、分库分表、数据归档等方向去做优化策略,适当地采用一种或几种协同是比较好的解决方案。
参考目录
https://developer.aliyun.com/article/603735
https://www.modb.pro/db/45779
https://cloud.tencent.com/developer/article/1748024
到此这篇关于MySQL中IO问题的深入分析与优化的文章就介绍到这了,更多相关MySQL中IO问题分析内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!