一、数据集解析
1. 数据集格式介绍
该数据集可以在Yann LeCun的官网上查看。官网链接:手写数字识别数据集。他这个数据集保存形式比较特殊,四个文件(训练集、测试集的图片和标签)都是以IDX文件格式保存的。IDX文件格式是各种数值类型的向量和多维矩阵的简单格式。

以官网的train-images.idx3-ubyte为例来说明IDX格式。
- offset是用16进制数表示的,代表偏移量,也就是在该文件中的存放地址。文件按字节存储,比如第一行起始地址为0000H,存储类型为32bit的整数,占4个字节,所以第二行的起始地址就是0004H。
- 图片的存储是在description中,该文件前面四行分别是magic number、number of images、number of rows、number of columns,后三个的value分别是60000、28、28,告诉了我们训练集中图片的数量与尺寸信息。
- 后面的每一行的pixel表示一张图片中一个像素点的大小,因为像素的范围是0-255的(0是白色、255是黑色),也就是\(2^8\),占8bit,1个字节,也就是占一行,offset+0001H。于是我们也可以推算出:
- 0016H~0799H空间内存放了第一张图片的信息,因为一张图片是28*28,占784行;
- train-images.idx3-ubyte整个文件大小为16+784*60000=47040016B≈45937.5KB
2. 数据集处理
为了直观看到图片,我们需要将pixel数据可视化。而且我对IDX文件不是很了解,更倾向于对图片数据进行处理,于是在网上找了下面的程序,用以转化。
2.1 训练集处理
将四个数据集文件放在同一个目录下,运行下面的代码,可以生成mnist_train的文件夹,里面有0-9个子文件,每个子文件都有对应的图片。
理解好上面介绍的文件格式和unpack_from缓存流的用法,就理解了data_file_size要改成什么值以及为什么要改变值。
import numpy as np
import struct
from PIL import Image
import os
data_file = 'train-images.idx3-ubyte'
# It's 47040016B, but we should set to 47040000B
data_file_size = 47040016
data_file_size = str(data_file_size - 16) + 'B'
data_buf = open(data_file, 'rb').read()
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', data_buf, 0)
datas = struct.unpack_from(
'>' + data_file_size, data_buf, struct.calcsize('>IIII'))
datas = np.array(datas).astype(np.uint8).reshape(
numImages, 1, numRows, numColumns)
label_file = 'train-labels.idx1-ubyte'
# It's 60008B, but we should set to 60000B
label_file_size = 60008
label_file_size = str(label_file_size - 8) + 'B'
label_buf = open(label_file, 'rb').read()
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
labels = struct.unpack_from(
'>' + label_file_size, label_buf, struct.calcsize('>II'))
labels = np.array(labels).astype(np.int64)
datas_root = 'mnist_train'
if not os.path.exists(datas_root):
os.mkdir(datas_root)
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
file_name = datas_root + os.sep + str(label) + os.sep + \
'mnist_train_' + str(ii) + '.png'
img.save(file_name)
2.2 测试集处理
与训练集的代码差不多,改了改文件名字和大小而已。
import numpy as np
import struct
from PIL import Image
import os
data_file = 't10k-images.idx3-ubyte'
# It's 7840016B, but we should set to 7840000B
data_file_size = 7840016
data_file_size = str(data_file_size - 16) + 'B'
data_buf = open(data_file, 'rb').read()
magic, numImages, numRows, numColumns = struct.unpack_from(
'>IIII', data_buf, 0)
datas = struct.unpack_from(
'>' + data_file_size, data_buf, struct.calcsize('>IIII'))
datas = np.array(datas).astype(np.uint8).reshape(
numImages, 1, numRows, numColumns)
label_file = 't10k-labels.idx1-ubyte'
# It's 10008B, but we should set to 10000B
label_file_size = 10008
label_file_size = str(label_file_size - 8) + 'B'
label_buf = open(label_file, 'rb').read()
magic, numLabels = struct.unpack_from('>II', label_buf, 0)
labels = struct.unpack_from(
'>' + label_file_size, label_buf, struct.calcsize('>II'))
labels = np.array(labels).astype(np.int64)
datas_root = 'mnist_test'
if not os.path.exists(datas_root):
os.mkdir(datas_root)
for i in range(10):
file_name = datas_root + os.sep + str(i)
if not os.path.exists(file_name):
os.mkdir(file_name)
for ii in range(numLabels):
img = Image.fromarray(datas[ii, 0, 0:28, 0:28])
label = labels[ii]
file_name = datas_root + os.sep + str(label) + os.sep + \
'mnist_test_' + str(ii) + '.png'
img.save(file_name)
二、接口load设计
对于我这个阶段,模型什么的往往都只是套用即可,而data_loader是实现过程中的难点,也是最需要编程的地方,小白应该训练的基本功。
- 函数data_load就是将图片和对应的标签以矩阵的形式存放,再分别加入列表中。如果是训练就要将列表随机shuffle,如果是测试我觉得就不用了。
- yield的生成器这一块需要好好理解,菜鸟教程上面写的很详细了。释放出去时应该是要将列表转换成array,释放的列表的大小基本都是Batchsize,除了最后一批次
- 因为本案例只是做了0和1的二分类,所以就没有将标签为2-9的文件存进去,因此直接列了0和1的读取,没有把它写出一个函数,代码看上去稍微冗杂了点。
def data_load(mode='train'):
data_list = []
# 分别读取
if mode == 'train':
dir = 'mnist_train\\0'
for filename in os.listdir(dir):
img_path = dir + '\\' + filename
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
img = np.reshape(img, [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.array([0]).astype('int64')
data_list.append((img, label))
dir = 'mnist_train\\1'
for filename in os.listdir(dir):
img_path = dir + '\\' + filename
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
img = np.reshape(img, [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.array([1]).astype('int64')
data_list.append((img, label))
# 打乱
random.shuffle(data_list)
if mode == 'eval':
dir = 'mnist_test\\0'
for filename in os.listdir(dir):
img_path = dir + '\\' + filename
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
img = np.reshape(img, [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.array([0]).astype('int64')
data_list.append((img, label))
dir = 'mnist_test\\1'
for filename in os.listdir(dir):
img_path = dir + '\\' + filename
img = cv2.imread(img_path, cv2.IMREAD_GRAYSCALE)
img = np.reshape(img, [1, IMG_ROWS, IMG_COLS]).astype('float32')
label = np.array([1]).astype('int64')
data_list.append((img, label))
imgs_list = []
labels_list = []
for data in data_list:
imgs_list.append(data[0])
labels_list.append(data[1])
if len(imgs_list) == BATCHSIZE:
yield np.array(imgs_list), np.array(labels_list)
imgs_list = []
labels_list = []
if len(imgs_list) > 0:
yield np.array(imgs_list), np.array(labels_list)
return data_load
可以先来测试一下:
# 声明数据读取函数,从训练集中读取数据
train_loader = data_load
# 以迭代的形式读取数据
for batch_id, data in enumerate(train_loader()):
image_data, label_data = data
if batch_id == 0:
# 打印数据shape和类型
print("打印第一个batch数据的维度,以及数据的类型:")
print("图像维度: {}, 标签维度: {}, 图像数据类型: {}, 标签数据类型: {}".format(image_data.shape, label_data.shape, type(image_data), type(label_data)))
break
# 打印第一个batch数据的维度,以及数据的类型:
# 图像维度: (100, 1, 28, 28), 标签维度: (100, 1), 图像数据类型: , 标签数据类型:
三、模型选用
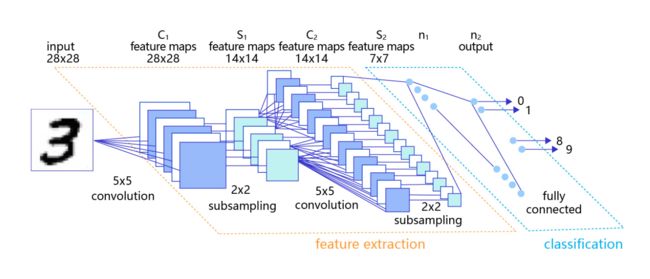 这一块直接用经典的卷积神经网络就行了,选用paddle2.2作为深度学习的框架。值得注意的是,模型选用与data_load是密切联系的,因为希望用卷积神经网络,所以采用NCWH的格式, 即上面的(100, 1, 28, 28)。如果不采用卷积神经网络,而用BP网络,格式就应该是(100, 1, 784)。注意这里的N就是Batchsize,我自己开始设定的是100。 至于为什么前向计算的地方又加了一个if,这个是用在后面测试的时候;当然也可以选择去掉这块,放在测试那块。 至于网络中的参数,直接代卷积公式、池化公式就好了。 下面是一张图片的尺寸变化: - conv1后的尺寸:(28-5+2*2)/1+1=28 - pool1以后的尺寸:28/2=14 - conv2后的尺寸(14-5+2*2)/1+1=14 - pool2以后的尺寸:14/2=7 - reshape后,全链接前的维度 7\*7\*20=980
这一块直接用经典的卷积神经网络就行了,选用paddle2.2作为深度学习的框架。值得注意的是,模型选用与data_load是密切联系的,因为希望用卷积神经网络,所以采用NCWH的格式, 即上面的(100, 1, 28, 28)。如果不采用卷积神经网络,而用BP网络,格式就应该是(100, 1, 784)。注意这里的N就是Batchsize,我自己开始设定的是100。 至于为什么前向计算的地方又加了一个if,这个是用在后面测试的时候;当然也可以选择去掉这块,放在测试那块。 至于网络中的参数,直接代卷积公式、池化公式就好了。 下面是一张图片的尺寸变化: - conv1后的尺寸:(28-5+2*2)/1+1=28 - pool1以后的尺寸:28/2=14 - conv2后的尺寸(14-5+2*2)/1+1=14 - pool2以后的尺寸:14/2=7 - reshape后,全链接前的维度 7\*7\*20=980
class MNIST(paddle.nn.Layer):
def __init__(self):
super(MNIST, self).__init__()
self.conv1 = nn.Conv2D(in_channels=1, out_channels=20, kernel_size=5, stride=1, padding=2)
self.max_pool1 = nn.MaxPool2D(kernel_size=2, stride=2)
self.conv2 = nn.Conv2D(in_channels=20, out_channels=20, kernel_size=5, stride=1, padding=2)
self.max_pool2 = nn.MaxPool2D(kernel_size=2, stride=2)
self.fc = nn.Linear(in_features=980, out_features=10)
def forward(self, inputs, label=None):
x = self.conv1(inputs)
x = F.relu(x)
x = self.max_pool1(x)
x = self.conv2(x)
x = F.relu(x)
x = self.max_pool2(x)
x = paddle.reshape(x, [x.shape[0], -1])
x = self.fc(x)
if label is not None:
acc = paddle.metric.accuracy(input=x, label=label)
return x, acc
else:
return x
四、开始训练
训练的部分就不是很复杂了,我直接搬的网上的代码,最多改改设定的事情。
def train(model):
model.train()
train_loader = data_load
opt = paddle.optimizer.SGD(learning_rate=0.001, parameters=model.parameters())
EPOCH_NUM = 10
for epoch_id in range(EPOCH_NUM):
for batch_id, data in enumerate(train_loader()):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
predicts = model(images)
loss = F.cross_entropy(predicts, labels)
avg_loss = paddle.mean(loss)
if batch_id % 100 == 0:
print("epoch: {}, batch: {}, loss is: {}".format(epoch_id, batch_id, avg_loss.numpy()))
avg_loss.backward()
opt.step()
opt.clear_grad()
paddle.save(model.state_dict(), 'mnist2.pdparams')
model = MNIST()
#启动训练过程
train(model)
五、测试评价
def evaluation(model):
print('start evaluation .......')
# 定义预测过程
params_file_path = 'mnist2.pdparams'
# 加载模型参数
param_dict = paddle.load(params_file_path)
model.load_dict(param_dict)
model.eval()
eval_loader = data_load
acc_set = []
avg_loss_set = []
for batch_id, data in enumerate(eval_loader('eval')):
images, labels = data
images = paddle.to_tensor(images)
labels = paddle.to_tensor(labels)
predicts, acc = model(images, labels)
loss = F.cross_entropy(input=predicts, label=labels)
avg_loss = paddle.mean(loss)
acc_set.append(float(acc.numpy()))
avg_loss_set.append(float(avg_loss.numpy()))
#计算多个batch的平均损失和准确率
acc_val_mean = np.array(acc_set).mean()
avg_loss_val_mean = np.array(avg_loss_set).mean()
print('loss={}, acc={}'.format(avg_loss_val_mean, acc_val_mean))
model = MNIST()
evaluation(model)
想要可视化,可以改进四、五两节的函数,return返回值,绘图。