Tensorflow2.0 医学图像分割(大脑肿瘤识别)
医学图像分割是医学图像处理与分析领域的复杂而关键的步骤,其目的是将医学图像中具有某些特殊含义的部分分割出来,并提取相关特征,为临床诊疗和病理学研究提供可靠的依据,辅助医生作出更为准确的诊断。本次实验使用大脑肿瘤数据集,经过网络训练之后可以将大脑CT图像中的肿瘤区域识别出来。
1.数据集
链接:https://pan.baidu.com/s/1z9zaR6bItUnXFtKDjFmm_g
提取码:9kdn
采用kaggle上的大脑CT分割数据集,里面包括原始大脑CT图像和对应的分割模板
2.代码
2.1 导入相应的库
import os
import random
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import cv2
from tqdm import tqdm_notebook, tnrange
from glob import glob
from itertools import chain
from skimage.io import imread, imshow, concatenate_images
from skimage.transform import resize
from skimage.morphology import label
from sklearn.model_selection import train_test_split
import tensorflow as tf
from skimage.color import rgb2gray
from tensorflow.keras import Input
from tensorflow.keras.models import Model, load_model, save_model
from tensorflow.keras.layers import Input, Activation, BatchNormalization, Dropout, Lambda, Conv2D, Conv2DTranspose, MaxPooling2D, concatenate
from tensorflow.keras.optimizers import Adam
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
from tensorflow.keras import backend as K
from tensorflow.keras.preprocessing.image import ImageDataGenerator
from tensorflow.keras.callbacks import EarlyStopping, ModelCheckpoint
2.2 加载图片和标签
#图片大小
im_width = 256
im_height = 256
#数据集路径
train_files = []
mask_files = glob('../input/lgg-mri-segmentation/kaggle_3m/*/*_mask*')
for i in mask_files:
train_files.append(i.replace('_mask',''))
#打印数据集大小
print(len(train_files))
print(len(mask_files))
结果:
数据集总共有3929张大脑CT图片,3929张分割图片
3929
3929
2.3 数据可视化
#将分割图片和原图片合并到一起显示
rows,cols=3,3
fig=plt.figure(figsize=(10,10))
for i in range(1,rows*cols+1):
fig.add_subplot(rows,cols,i)
img_path=train_files[i]
msk_path=mask_files[i]
img=cv2.imread(img_path)
img=cv2.cvtColor(img,cv2.COLOR_BGR2RGB)
msk=cv2.imread(msk_path)
plt.xticks([])
plt.yticks([])
plt.imshow(img)
plt.imshow(msk,alpha=0.4)
plt.show()
结果:
图中白色区域的是大脑肿瘤区域,如果没有则代表健康大脑

2.4 划分训练集,验证集,测试集
df = pd.DataFrame(data={"filename": train_files, 'mask' : mask_files})
df_train, df_test = train_test_split(df,test_size = 0.1)
df_train, df_val = train_test_split(df_train,test_size = 0.2)
print(df_train.values.shape)
print(df_val.values.shape)
print(df_test.values.shape)
结果:
训练集2828张图片,验证集708张图片,测试集393张图片
(2828, 2)
(708, 2)
(393, 2)
2.5 定义数据预处理函数
#定义数据生成器函数
def train_generator(data_frame, batch_size, aug_dict,
image_color_mode="rgb",
mask_color_mode="grayscale",
image_save_prefix="image",
mask_save_prefix="mask",
save_to_dir=None,
target_size=(256,256),
seed=1):
image_datagen = ImageDataGenerator(**aug_dict)
mask_datagen = ImageDataGenerator(**aug_dict)
image_generator = image_datagen.flow_from_dataframe(
data_frame,
x_col = "filename",
class_mode = None,
color_mode = image_color_mode,
target_size = target_size,
batch_size = batch_size,
save_to_dir = save_to_dir,
save_prefix = image_save_prefix,
seed = seed)
mask_generator = mask_datagen.flow_from_dataframe(
data_frame,
x_col = "mask",
class_mode = None,
color_mode = mask_color_mode,
target_size = target_size,
batch_size = batch_size,
save_to_dir = save_to_dir,
save_prefix = mask_save_prefix,
seed = seed)
train_gen = zip(image_generator, mask_generator)
for (img, mask) in train_gen:
img, mask = adjust_data(img, mask)
yield (img,mask)
#处理数据函数
def adjust_data(img,mask):
img = img / 255
mask = mask / 255
mask[mask > 0.5] = 1
mask[mask <= 0.5] = 0
return (img, mask)
2.6 定义损失函数和指标函数
smooth=100
#定义Dice系数
def dice_coef(y_true, y_pred):
y_truef=K.flatten(y_true)
y_predf=K.flatten(y_pred)
And=K.sum(y_truef* y_predf)
return((2* And + smooth) / (K.sum(y_truef) + K.sum(y_predf) + smooth))
#定义损失函数
def dice_coef_loss(y_true, y_pred):
return -dice_coef(y_true, y_pred)
#定义iou函数
def iou(y_true, y_pred):
intersection = K.sum(y_true * y_pred)
sum_ = K.sum(y_true + y_pred)
jac = (intersection + smooth) / (sum_ - intersection + smooth)
return jac
def jac_distance(y_true, y_pred):
y_truef=K.flatten(y_true)
y_predf=K.flatten(y_pred)
return - iou(y_true, y_pred)
2.7 定义U-Net网络
def unet(input_size=(256,256,3)):
inputs = Input(input_size)
conv1 = Conv2D(64, (3, 3), padding='same')(inputs)
bn1 = Activation('relu')(conv1)
conv1 = Conv2D(64, (3, 3), padding='same')(bn1)
bn1 = BatchNormalization(axis=3)(conv1)
bn1 = Activation('relu')(bn1)
pool1 = MaxPooling2D(pool_size=(2, 2))(bn1)
conv2 = Conv2D(128, (3, 3), padding='same')(pool1)
bn2 = Activation('relu')(conv2)
conv2 = Conv2D(128, (3, 3), padding='same')(bn2)
bn2 = BatchNormalization(axis=3)(conv2)
bn2 = Activation('relu')(bn2)
pool2 = MaxPooling2D(pool_size=(2, 2))(bn2)
conv3 = Conv2D(256, (3, 3), padding='same')(pool2)
bn3 = Activation('relu')(conv3)
conv3 = Conv2D(256, (3, 3), padding='same')(bn3)
bn3 = BatchNormalization(axis=3)(conv3)
bn3 = Activation('relu')(bn3)
pool3 = MaxPooling2D(pool_size=(2, 2))(bn3)
conv4 = Conv2D(512, (3, 3), padding='same')(pool3)
bn4 = Activation('relu')(conv4)
conv4 = Conv2D(512, (3, 3), padding='same')(bn4)
bn4 = BatchNormalization(axis=3)(conv4)
bn4 = Activation('relu')(bn4)
pool4 = MaxPooling2D(pool_size=(2, 2))(bn4)
conv5 = Conv2D(1024, (3, 3), padding='same')(pool4)
bn5 = Activation('relu')(conv5)
conv5 = Conv2D(1024, (3, 3), padding='same')(bn5)
bn5 = BatchNormalization(axis=3)(conv5)
bn5 = Activation('relu')(bn5)
up6 = concatenate([Conv2DTranspose(512, (2, 2), strides=(2, 2), padding='same')(bn5), conv4], axis=3)
conv6 = Conv2D(512, (3, 3), padding='same')(up6)
bn6 = Activation('relu')(conv6)
conv6 = Conv2D(512, (3, 3), padding='same')(bn6)
bn6 = BatchNormalization(axis=3)(conv6)
bn6 = Activation('relu')(bn6)
up7 = concatenate([Conv2DTranspose(256, (2, 2), strides=(2, 2), padding='same')(bn6), conv3], axis=3)
conv7 = Conv2D(256, (3, 3), padding='same')(up7)
bn7 = Activation('relu')(conv7)
conv7 = Conv2D(256, (3, 3), padding='same')(bn7)
bn7 = BatchNormalization(axis=3)(conv7)
bn7 = Activation('relu')(bn7)
up8 = concatenate([Conv2DTranspose(128, (2, 2), strides=(2, 2), padding='same')(bn7), conv2], axis=3)
conv8 = Conv2D(128, (3, 3), padding='same')(up8)
bn8 = Activation('relu')(conv8)
conv8 = Conv2D(128, (3, 3), padding='same')(bn8)
bn8 = BatchNormalization(axis=3)(conv8)
bn8 = Activation('relu')(bn8)
up9 = concatenate([Conv2DTranspose(64, (2, 2), strides=(2, 2), padding='same')(bn8), conv1], axis=3)
conv9 = Conv2D(64, (3, 3), padding='same')(up9)
bn9 = Activation('relu')(conv9)
conv9 = Conv2D(64, (3, 3), padding='same')(bn9)
bn9 = BatchNormalization(axis=3)(conv9)
bn9 = Activation('relu')(bn9)
conv10 = Conv2D(1, (1, 1), activation='sigmoid')(bn9)
return Model(inputs=[inputs], outputs=[conv10])
model = unet()
#打印模型参数
model.summary()
结果:
Model: "model"
__________________________________________________________________________________________________
Layer (type) Output Shape Param # Connected to
==================================================================================================
input_1 (InputLayer) [(None, 256, 256, 3) 0
__________________________________________________________________________________________________
conv2d (Conv2D) (None, 256, 256, 64) 1792 input_1[0][0]
__________________________________________________________________________________________________
activation (Activation) (None, 256, 256, 64) 0 conv2d[0][0]
__________________________________________________________________________________________________
conv2d_1 (Conv2D) (None, 256, 256, 64) 36928 activation[0][0]
__________________________________________________________________________________________________
batch_normalization (BatchNorma (None, 256, 256, 64) 256 conv2d_1[0][0]
__________________________________________________________________________________________________
activation_1 (Activation) (None, 256, 256, 64) 0 batch_normalization[0][0]
__________________________________________________________________________________________________
max_pooling2d (MaxPooling2D) (None, 128, 128, 64) 0 activation_1[0][0]
__________________________________________________________________________________________________
conv2d_2 (Conv2D) (None, 128, 128, 128 73856 max_pooling2d[0][0]
__________________________________________________________________________________________________
activation_2 (Activation) (None, 128, 128, 128 0 conv2d_2[0][0]
__________________________________________________________________________________________________
conv2d_3 (Conv2D) (None, 128, 128, 128 147584 activation_2[0][0]
__________________________________________________________________________________________________
batch_normalization_1 (BatchNor (None, 128, 128, 128 512 conv2d_3[0][0]
__________________________________________________________________________________________________
activation_3 (Activation) (None, 128, 128, 128 0 batch_normalization_1[0][0]
__________________________________________________________________________________________________
max_pooling2d_1 (MaxPooling2D) (None, 64, 64, 128) 0 activation_3[0][0]
__________________________________________________________________________________________________
conv2d_4 (Conv2D) (None, 64, 64, 256) 295168 max_pooling2d_1[0][0]
__________________________________________________________________________________________________
activation_4 (Activation) (None, 64, 64, 256) 0 conv2d_4[0][0]
__________________________________________________________________________________________________
conv2d_5 (Conv2D) (None, 64, 64, 256) 590080 activation_4[0][0]
__________________________________________________________________________________________________
batch_normalization_2 (BatchNor (None, 64, 64, 256) 1024 conv2d_5[0][0]
__________________________________________________________________________________________________
activation_5 (Activation) (None, 64, 64, 256) 0 batch_normalization_2[0][0]
__________________________________________________________________________________________________
max_pooling2d_2 (MaxPooling2D) (None, 32, 32, 256) 0 activation_5[0][0]
__________________________________________________________________________________________________
conv2d_6 (Conv2D) (None, 32, 32, 512) 1180160 max_pooling2d_2[0][0]
__________________________________________________________________________________________________
activation_6 (Activation) (None, 32, 32, 512) 0 conv2d_6[0][0]
__________________________________________________________________________________________________
conv2d_7 (Conv2D) (None, 32, 32, 512) 2359808 activation_6[0][0]
__________________________________________________________________________________________________
batch_normalization_3 (BatchNor (None, 32, 32, 512) 2048 conv2d_7[0][0]
__________________________________________________________________________________________________
activation_7 (Activation) (None, 32, 32, 512) 0 batch_normalization_3[0][0]
__________________________________________________________________________________________________
max_pooling2d_3 (MaxPooling2D) (None, 16, 16, 512) 0 activation_7[0][0]
__________________________________________________________________________________________________
conv2d_8 (Conv2D) (None, 16, 16, 1024) 4719616 max_pooling2d_3[0][0]
__________________________________________________________________________________________________
activation_8 (Activation) (None, 16, 16, 1024) 0 conv2d_8[0][0]
__________________________________________________________________________________________________
conv2d_9 (Conv2D) (None, 16, 16, 1024) 9438208 activation_8[0][0]
__________________________________________________________________________________________________
batch_normalization_4 (BatchNor (None, 16, 16, 1024) 4096 conv2d_9[0][0]
__________________________________________________________________________________________________
activation_9 (Activation) (None, 16, 16, 1024) 0 batch_normalization_4[0][0]
__________________________________________________________________________________________________
conv2d_transpose (Conv2DTranspo (None, 32, 32, 512) 2097664 activation_9[0][0]
__________________________________________________________________________________________________
concatenate (Concatenate) (None, 32, 32, 1024) 0 conv2d_transpose[0][0]
conv2d_7[0][0]
__________________________________________________________________________________________________
conv2d_10 (Conv2D) (None, 32, 32, 512) 4719104 concatenate[0][0]
__________________________________________________________________________________________________
activation_10 (Activation) (None, 32, 32, 512) 0 conv2d_10[0][0]
__________________________________________________________________________________________________
conv2d_11 (Conv2D) (None, 32, 32, 512) 2359808 activation_10[0][0]
__________________________________________________________________________________________________
batch_normalization_5 (BatchNor (None, 32, 32, 512) 2048 conv2d_11[0][0]
__________________________________________________________________________________________________
activation_11 (Activation) (None, 32, 32, 512) 0 batch_normalization_5[0][0]
__________________________________________________________________________________________________
conv2d_transpose_1 (Conv2DTrans (None, 64, 64, 256) 524544 activation_11[0][0]
__________________________________________________________________________________________________
concatenate_1 (Concatenate) (None, 64, 64, 512) 0 conv2d_transpose_1[0][0]
conv2d_5[0][0]
__________________________________________________________________________________________________
conv2d_12 (Conv2D) (None, 64, 64, 256) 1179904 concatenate_1[0][0]
__________________________________________________________________________________________________
activation_12 (Activation) (None, 64, 64, 256) 0 conv2d_12[0][0]
__________________________________________________________________________________________________
conv2d_13 (Conv2D) (None, 64, 64, 256) 590080 activation_12[0][0]
__________________________________________________________________________________________________
batch_normalization_6 (BatchNor (None, 64, 64, 256) 1024 conv2d_13[0][0]
__________________________________________________________________________________________________
activation_13 (Activation) (None, 64, 64, 256) 0 batch_normalization_6[0][0]
__________________________________________________________________________________________________
conv2d_transpose_2 (Conv2DTrans (None, 128, 128, 128 131200 activation_13[0][0]
__________________________________________________________________________________________________
concatenate_2 (Concatenate) (None, 128, 128, 256 0 conv2d_transpose_2[0][0]
conv2d_3[0][0]
__________________________________________________________________________________________________
conv2d_14 (Conv2D) (None, 128, 128, 128 295040 concatenate_2[0][0]
__________________________________________________________________________________________________
activation_14 (Activation) (None, 128, 128, 128 0 conv2d_14[0][0]
__________________________________________________________________________________________________
conv2d_15 (Conv2D) (None, 128, 128, 128 147584 activation_14[0][0]
__________________________________________________________________________________________________
batch_normalization_7 (BatchNor (None, 128, 128, 128 512 conv2d_15[0][0]
__________________________________________________________________________________________________
activation_15 (Activation) (None, 128, 128, 128 0 batch_normalization_7[0][0]
__________________________________________________________________________________________________
conv2d_transpose_3 (Conv2DTrans (None, 256, 256, 64) 32832 activation_15[0][0]
__________________________________________________________________________________________________
concatenate_3 (Concatenate) (None, 256, 256, 128 0 conv2d_transpose_3[0][0]
conv2d_1[0][0]
__________________________________________________________________________________________________
conv2d_16 (Conv2D) (None, 256, 256, 64) 73792 concatenate_3[0][0]
__________________________________________________________________________________________________
activation_16 (Activation) (None, 256, 256, 64) 0 conv2d_16[0][0]
__________________________________________________________________________________________________
conv2d_17 (Conv2D) (None, 256, 256, 64) 36928 activation_16[0][0]
__________________________________________________________________________________________________
batch_normalization_8 (BatchNor (None, 256, 256, 64) 256 conv2d_17[0][0]
__________________________________________________________________________________________________
activation_17 (Activation) (None, 256, 256, 64) 0 batch_normalization_8[0][0]
__________________________________________________________________________________________________
conv2d_18 (Conv2D) (None, 256, 256, 1) 65 activation_17[0][0]
==================================================================================================
Total params: 31,043,521
Trainable params: 31,037,633
Non-trainable params: 5,888
__________________________________________________________________________________________________
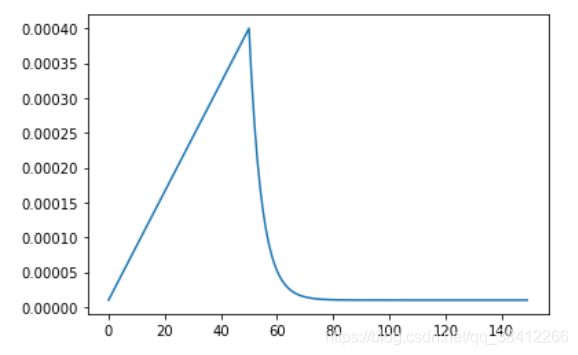
2.8 设置学习率
EPOCHS = 150
BATCH_SIZE = 32
def lrfn(epoch):
LR_START = 0.00001
LR_MAX = 0.0004
LR_MIN = 0.00001
LR_RAMPUP_EPOCHS = 50
LR_SUSTAIN_EPOCHS = 0
LR_EXP_DECAY = .8
if epoch < LR_RAMPUP_EPOCHS:
lr = (LR_MAX - LR_START) / LR_RAMPUP_EPOCHS * epoch + LR_START
elif epoch < LR_RAMPUP_EPOCHS + LR_SUSTAIN_EPOCHS:
lr = LR_MAX
else:
lr = (LR_MAX - LR_MIN) * LR_EXP_DECAY**(epoch - LR_RAMPUP_EPOCHS - LR_SUSTAIN_EPOCHS) + LR_MIN
return lr
rng = [i for i in range(EPOCHS)]
y = [lrfn(x) for x in rng]
plt.plot(rng, y)
print("Learning rate schedule: {:.3g} to {:.3g} to {:.3g}".format(y[0], max(y), y[-1]))
lr_schedule = tf.keras.callbacks.LearningRateScheduler(lrfn, verbose=1)
结果:
采用余弦退火学习率,先线性上升再指数下降
2.9 开始训练
#训练集图片做数据增强
train_generator_args = dict(rotation_range=0.2,
width_shift_range=0.05,
height_shift_range=0.05,
shear_range=0.05,
zoom_range=0.05,
horizontal_flip=True,
fill_mode='nearest')
#生成训练数据
train_gen = train_generator(df_train, BATCH_SIZE,
train_generator_args,
target_size=(im_height, im_width))
#生成验证数据
test_gener = train_generator(df_val, BATCH_SIZE,
dict(),
target_size=(im_height, im_width))
model = unet(input_size=(im_height, im_width, 3))
checkpoint = ModelCheckpoint(
filepath='./save_weights/myUnet.ckpt',
monitor='val_acc',
save_weights_only=False,
save_best_only=True,
mode='auto',
period=1
)
#编译模型
model.compile(optimizer='adam', loss=dice_coef_loss, metrics=["binary_accuracy", iou, dice_coef])
#开始训练
history = model.fit(train_gen,
steps_per_epoch=len(df_train) / BATCH_SIZE,
epochs=EPOCHS,
validation_data = test_gener,
validation_steps=len(df_val) / BATCH_SIZE,
callbacks=[lr_schedule,checkpoint])
结果:
经过150轮训练后,验证集的iou为0.8180,dice系数为0.8988
Epoch 100/150
89/88 [==============================] - 95s 1s/step - loss: -0.9131 - binary_accuracy: 0.9983 - iou: 0.8431 - dice_coef: 0.9134 - val_loss: -0.8907 - val_binary_accuracy: 0.9981 - val_iou: 0.8105 - val_dice_coef: 0.8935 - lr: 1.0007e-05
Epoch 00101: LearningRateScheduler reducing learning rate to 1.0005566266001554e-05.
Epoch 101/150
89/88 [==============================] - 96s 1s/step - loss: -0.9125 - binary_accuracy: 0.9983 - iou: 0.8414 - dice_coef: 0.9120 - val_loss: -0.8917 - val_binary_accuracy: 0.9979 - val_iou: 0.8085 - val_dice_coef: 0.8927 - lr: 1.0006e-05
Epoch 00102: LearningRateScheduler reducing learning rate to 1.0004453012801243e-05.
Epoch 102/150
89/88 [==============================] - 94s 1s/step - loss: -0.9095 - binary_accuracy: 0.9982 - iou: 0.8398 - dice_coef: 0.9092 - val_loss: -0.8965 - val_binary_accuracy: 0.9982 - val_iou: 0.8171 - val_dice_coef: 0.8980 - lr: 1.0004e-05
Epoch 00103: LearningRateScheduler reducing learning rate to 1.0003562410240995e-05.
Epoch 103/150
89/88 [==============================] - 96s 1s/step - loss: -0.9115 - binary_accuracy: 0.9983 - iou: 0.8406 - dice_coef: 0.9116 - val_loss: -0.8836 - val_binary_accuracy: 0.9981 - val_iou: 0.7700 - val_dice_coef: 0.8533 - lr: 1.0004e-05
Epoch 00104: LearningRateScheduler reducing learning rate to 1.0002849928192796e-05.
Epoch 104/150
89/88 [==============================] - 96s 1s/step - loss: -0.9100 - binary_accuracy: 0.9982 - iou: 0.8428 - dice_coef: 0.9104 - val_loss: -0.8972 - val_binary_accuracy: 0.9980 - val_iou: 0.7991 - val_dice_coef: 0.8830 - lr: 1.0003e-05
Epoch 00105: LearningRateScheduler reducing learning rate to 1.0002279942554237e-05.
Epoch 105/150
89/88 [==============================] - 95s 1s/step - loss: -0.9125 - binary_accuracy: 0.9982 - iou: 0.8430 - dice_coef: 0.9128 - val_loss: -0.8924 - val_binary_accuracy: 0.9980 - val_iou: 0.8098 - val_dice_coef: 0.8934 - lr: 1.0002e-05
Epoch 00106: LearningRateScheduler reducing learning rate to 1.000182395404339e-05.
Epoch 106/150
89/88 [==============================] - 96s 1s/step - loss: -0.9113 - binary_accuracy: 0.9982 - iou: 0.8403 - dice_coef: 0.9112 - val_loss: -0.8943 - val_binary_accuracy: 0.9981 - val_iou: 0.8114 - val_dice_coef: 0.8941 - lr: 1.0002e-05
Epoch 00107: LearningRateScheduler reducing learning rate to 1.0001459163234711e-05.
Epoch 107/150
89/88 [==============================] - 95s 1s/step - loss: -0.9125 - binary_accuracy: 0.9981 - iou: 0.8434 - dice_coef: 0.9127 - val_loss: -0.8873 - val_binary_accuracy: 0.9980 - val_iou: 0.8017 - val_dice_coef: 0.8887 - lr: 1.0001e-05
Epoch 00108: LearningRateScheduler reducing learning rate to 1.000116733058777e-05.
Epoch 108/150
89/88 [==============================] - 95s 1s/step - loss: -0.9125 - binary_accuracy: 0.9982 - iou: 0.8433 - dice_coef: 0.9126 - val_loss: -0.8990 - val_binary_accuracy: 0.9980 - val_iou: 0.8217 - val_dice_coef: 0.9011 - lr: 1.0001e-05
Epoch 00109: LearningRateScheduler reducing learning rate to 1.0000933864470216e-05.
Epoch 109/150
89/88 [==============================] - 96s 1s/step - loss: -0.2042 - binary_accuracy: 0.9835 - iou: 0.1310 - dice_coef: 0.2030 - val_loss: -0.8974 - val_binary_accuracy: 0.9980 - val_iou: 0.8171 - val_dice_coef: 0.8984 - lr: 1.0001e-05
Epoch 00110: LearningRateScheduler reducing learning rate to 1.0000747091576173e-05.
Epoch 110/150
89/88 [==============================] - 97s 1s/step - loss: -0.9100 - binary_accuracy: 0.9982 - iou: 0.8351 - dice_coef: 0.9043 - val_loss: -0.8950 - val_binary_accuracy: 0.9981 - val_iou: 0.8075 - val_dice_coef: 0.8921 - lr: 1.0001e-05
Epoch 00111: LearningRateScheduler reducing learning rate to 1.0000597673260939e-05.
Epoch 111/150
89/88 [==============================] - 96s 1s/step - loss: -0.9169 - binary_accuracy: 0.9983 - iou: 0.8487 - dice_coef: 0.9171 - val_loss: -0.8948 - val_binary_accuracy: 0.9980 - val_iou: 0.8003 - val_dice_coef: 0.8858 - lr: 1.0001e-05
Epoch 00112: LearningRateScheduler reducing learning rate to 1.0000478138608751e-05.
Epoch 112/150
89/88 [==============================] - 94s 1s/step - loss: -0.9146 - binary_accuracy: 0.9982 - iou: 0.8452 - dice_coef: 0.9146 - val_loss: -0.8917 - val_binary_accuracy: 0.9980 - val_iou: 0.7973 - val_dice_coef: 0.8852 - lr: 1.0000e-05
Epoch 00113: LearningRateScheduler reducing learning rate to 1.0000382510887001e-05.
Epoch 113/150
89/88 [==============================] - 94s 1s/step - loss: -0.9109 - binary_accuracy: 0.9982 - iou: 0.8397 - dice_coef: 0.9110 - val_loss: -0.8956 - val_binary_accuracy: 0.9980 - val_iou: 0.8122 - val_dice_coef: 0.8947 - lr: 1.0000e-05
Epoch 00114: LearningRateScheduler reducing learning rate to 1.00003060087096e-05.
Epoch 114/150
89/88 [==============================] - 94s 1s/step - loss: -0.9150 - binary_accuracy: 0.9983 - iou: 0.8452 - dice_coef: 0.9150 - val_loss: -0.8938 - val_binary_accuracy: 0.9981 - val_iou: 0.8125 - val_dice_coef: 0.8955 - lr: 1.0000e-05
Epoch 00115: LearningRateScheduler reducing learning rate to 1.000024480696768e-05.
Epoch 115/150
89/88 [==============================] - 93s 1s/step - loss: -0.9133 - binary_accuracy: 0.9983 - iou: 0.8437 - dice_coef: 0.9133 - val_loss: -0.8961 - val_binary_accuracy: 0.9981 - val_iou: 0.8111 - val_dice_coef: 0.8942 - lr: 1.0000e-05
Epoch 00116: LearningRateScheduler reducing learning rate to 1.0000195845574146e-05.
Epoch 116/150
89/88 [==============================] - 94s 1s/step - loss: -0.0509 - binary_accuracy: 0.9800 - iou: 0.0281 - dice_coef: 0.0506 - val_loss: -0.8910 - val_binary_accuracy: 0.9980 - val_iou: 0.8131 - val_dice_coef: 0.8939 - lr: 1.0000e-05
Epoch 00117: LearningRateScheduler reducing learning rate to 1.0000156676459317e-05.
Epoch 117/150
89/88 [==============================] - 93s 1s/step - loss: -0.0473 - binary_accuracy: 0.9796 - iou: 0.0260 - dice_coef: 0.0470 - val_loss: -0.8964 - val_binary_accuracy: 0.9979 - val_iou: 0.8132 - val_dice_coef: 0.8959 - lr: 1.0000e-05
Epoch 00118: LearningRateScheduler reducing learning rate to 1.0000125341167454e-05.
Epoch 118/150
89/88 [==============================] - 93s 1s/step - loss: -0.2219 - binary_accuracy: 0.9833 - iou: 0.1436 - dice_coef: 0.2204 - val_loss: -0.8901 - val_binary_accuracy: 0.9980 - val_iou: 0.8010 - val_dice_coef: 0.8880 - lr: 1.0000e-05
Epoch 00119: LearningRateScheduler reducing learning rate to 1.0000100272933963e-05.
Epoch 119/150
89/88 [==============================] - 93s 1s/step - loss: -0.9146 - binary_accuracy: 0.9983 - iou: 0.8454 - dice_coef: 0.9149 - val_loss: -0.8975 - val_binary_accuracy: 0.9981 - val_iou: 0.8094 - val_dice_coef: 0.8926 - lr: 1.0000e-05
Epoch 00120: LearningRateScheduler reducing learning rate to 1.000008021834717e-05.
Epoch 120/150
89/88 [==============================] - 93s 1s/step - loss: -0.2489 - binary_accuracy: 0.9841 - iou: 0.1643 - dice_coef: 0.2472 - val_loss: -0.8958 - val_binary_accuracy: 0.9980 - val_iou: 0.8156 - val_dice_coef: 0.8972 - lr: 1.0000e-05
Epoch 00121: LearningRateScheduler reducing learning rate to 1.0000064174677736e-05.
Epoch 121/150
89/88 [==============================] - 93s 1s/step - loss: -0.9160 - binary_accuracy: 0.9982 - iou: 0.8479 - dice_coef: 0.9163 - val_loss: -0.8908 - val_binary_accuracy: 0.9980 - val_iou: 0.8054 - val_dice_coef: 0.8914 - lr: 1.0000e-05
Epoch 00122: LearningRateScheduler reducing learning rate to 1.000005133974219e-05.
Epoch 122/150
89/88 [==============================] - 92s 1s/step - loss: -0.9143 - binary_accuracy: 0.9983 - iou: 0.8451 - dice_coef: 0.9145 - val_loss: -0.8896 - val_binary_accuracy: 0.9981 - val_iou: 0.8038 - val_dice_coef: 0.8896 - lr: 1.0000e-05
Epoch 00123: LearningRateScheduler reducing learning rate to 1.0000041071793752e-05.
Epoch 123/150
89/88 [==============================] - 94s 1s/step - loss: -0.9097 - binary_accuracy: 0.9982 - iou: 0.8408 - dice_coef: 0.9100 - val_loss: -0.8982 - val_binary_accuracy: 0.9981 - val_iou: 0.8157 - val_dice_coef: 0.8976 - lr: 1.0000e-05
Epoch 00124: LearningRateScheduler reducing learning rate to 1.0000032857435001e-05.
Epoch 124/150
89/88 [==============================] - 92s 1s/step - loss: -0.9194 - binary_accuracy: 0.9984 - iou: 0.8524 - dice_coef: 0.9196 - val_loss: -0.8868 - val_binary_accuracy: 0.9979 - val_iou: 0.8036 - val_dice_coef: 0.8893 - lr: 1.0000e-05
Epoch 00125: LearningRateScheduler reducing learning rate to 1.0000026285948001e-05.
Epoch 125/150
89/88 [==============================] - 93s 1s/step - loss: -0.9145 - binary_accuracy: 0.9983 - iou: 0.8457 - dice_coef: 0.9142 - val_loss: -0.9036 - val_binary_accuracy: 0.9983 - val_iou: 0.8180 - val_dice_coef: 0.8974 - lr: 1.0000e-05
Epoch 00126: LearningRateScheduler reducing learning rate to 1.0000021028758402e-05.
Epoch 126/150
89/88 [==============================] - 92s 1s/step - loss: -0.9119 - binary_accuracy: 0.9982 - iou: 0.8430 - dice_coef: 0.9123 - val_loss: -0.8966 - val_binary_accuracy: 0.9979 - val_iou: 0.8199 - val_dice_coef: 0.8994 - lr: 1.0000e-05
Epoch 00127: LearningRateScheduler reducing learning rate to 1.0000016823006722e-05.
Epoch 127/150
89/88 [==============================] - 93s 1s/step - loss: -0.9160 - binary_accuracy: 0.9983 - iou: 0.8477 - dice_coef: 0.9160 - val_loss: -0.8914 - val_binary_accuracy: 0.9981 - val_iou: 0.8128 - val_dice_coef: 0.8944 - lr: 1.0000e-05
Epoch 00128: LearningRateScheduler reducing learning rate to 1.0000013458405378e-05.
Epoch 128/150
89/88 [==============================] - 91s 1s/step - loss: -0.9145 - binary_accuracy: 0.9982 - iou: 0.8468 - dice_coef: 0.9146 - val_loss: -0.9012 - val_binary_accuracy: 0.9980 - val_iou: 0.8191 - val_dice_coef: 0.8996 - lr: 1.0000e-05
Epoch 00129: LearningRateScheduler reducing learning rate to 1.0000010766724302e-05.
Epoch 129/150
89/88 [==============================] - 91s 1s/step - loss: -0.9147 - binary_accuracy: 0.9983 - iou: 0.8468 - dice_coef: 0.9147 - val_loss: -0.8948 - val_binary_accuracy: 0.9983 - val_iou: 0.8077 - val_dice_coef: 0.8923 - lr: 1.0000e-05
Epoch 00130: LearningRateScheduler reducing learning rate to 1.0000008613379442e-05.
Epoch 130/150
89/88 [==============================] - 92s 1s/step - loss: -0.9147 - binary_accuracy: 0.9983 - iou: 0.8464 - dice_coef: 0.9146 - val_loss: -0.8946 - val_binary_accuracy: 0.9979 - val_iou: 0.7974 - val_dice_coef: 0.8808 - lr: 1.0000e-05
Epoch 00131: LearningRateScheduler reducing learning rate to 1.0000006890703554e-05.
Epoch 131/150
89/88 [==============================] - 92s 1s/step - loss: -0.9130 - binary_accuracy: 0.9983 - iou: 0.8439 - dice_coef: 0.9126 - val_loss: -0.9028 - val_binary_accuracy: 0.9981 - val_iou: 0.8242 - val_dice_coef: 0.9029 - lr: 1.0000e-05
Epoch 00132: LearningRateScheduler reducing learning rate to 1.0000005512562843e-05.
Epoch 132/150
89/88 [==============================] - 91s 1s/step - loss: -0.9147 - binary_accuracy: 0.9983 - iou: 0.8468 - dice_coef: 0.9149 - val_loss: -0.8858 - val_binary_accuracy: 0.9980 - val_iou: 0.8056 - val_dice_coef: 0.8891 - lr: 1.0000e-05
Epoch 00133: LearningRateScheduler reducing learning rate to 1.0000004410050274e-05.
Epoch 133/150
89/88 [==============================] - 91s 1s/step - loss: -0.9153 - binary_accuracy: 0.9982 - iou: 0.8471 - dice_coef: 0.9153 - val_loss: -0.8942 - val_binary_accuracy: 0.9982 - val_iou: 0.7957 - val_dice_coef: 0.8810 - lr: 1.0000e-05
Epoch 00134: LearningRateScheduler reducing learning rate to 1.000000352804022e-05.
Epoch 134/150
89/88 [==============================] - 92s 1s/step - loss: -0.9117 - binary_accuracy: 0.9982 - iou: 0.8433 - dice_coef: 0.9112 - val_loss: -0.8985 - val_binary_accuracy: 0.9982 - val_iou: 0.8201 - val_dice_coef: 0.9002 - lr: 1.0000e-05
Epoch 00135: LearningRateScheduler reducing learning rate to 1.0000002822432176e-05.
Epoch 135/150
89/88 [==============================] - 91s 1s/step - loss: -0.4844 - binary_accuracy: 0.9892 - iou: 0.3683 - dice_coef: 0.4814 - val_loss: -0.8955 - val_binary_accuracy: 0.9979 - val_iou: 0.8153 - val_dice_coef: 0.8973 - lr: 1.0000e-05
Epoch 00136: LearningRateScheduler reducing learning rate to 1.000000225794574e-05.
Epoch 136/150
89/88 [==============================] - 92s 1s/step - loss: -0.9179 - binary_accuracy: 0.9983 - iou: 0.8506 - dice_coef: 0.9179 - val_loss: -0.8943 - val_binary_accuracy: 0.9981 - val_iou: 0.8152 - val_dice_coef: 0.8966 - lr: 1.0000e-05
Epoch 00137: LearningRateScheduler reducing learning rate to 1.0000001806356592e-05.
Epoch 137/150
89/88 [==============================] - 92s 1s/step - loss: -0.9158 - binary_accuracy: 0.9984 - iou: 0.8474 - dice_coef: 0.9159 - val_loss: -0.8973 - val_binary_accuracy: 0.9981 - val_iou: 0.8190 - val_dice_coef: 0.8995 - lr: 1.0000e-05
Epoch 00138: LearningRateScheduler reducing learning rate to 1.0000001445085275e-05.
Epoch 138/150
89/88 [==============================] - 93s 1s/step - loss: -0.0522 - binary_accuracy: 0.9800 - iou: 0.0291 - dice_coef: 0.0528 - val_loss: -0.8901 - val_binary_accuracy: 0.9979 - val_iou: 0.7992 - val_dice_coef: 0.8868 - lr: 1.0000e-05
Epoch 00139: LearningRateScheduler reducing learning rate to 1.000000115606822e-05.
Epoch 139/150
89/88 [==============================] - 94s 1s/step - loss: -0.9144 - binary_accuracy: 0.9982 - iou: 0.8473 - dice_coef: 0.9146 - val_loss: -0.8980 - val_binary_accuracy: 0.9981 - val_iou: 0.8181 - val_dice_coef: 0.8990 - lr: 1.0000e-05
Epoch 00140: LearningRateScheduler reducing learning rate to 1.0000000924854576e-05.
Epoch 140/150
89/88 [==============================] - 94s 1s/step - loss: -0.9131 - binary_accuracy: 0.9982 - iou: 0.8453 - dice_coef: 0.9132 - val_loss: -0.8954 - val_binary_accuracy: 0.9980 - val_iou: 0.8093 - val_dice_coef: 0.8936 - lr: 1.0000e-05
Epoch 00141: LearningRateScheduler reducing learning rate to 1.0000000739883661e-05.
Epoch 141/150
89/88 [==============================] - 93s 1s/step - loss: -0.9177 - binary_accuracy: 0.9983 - iou: 0.8512 - dice_coef: 0.9178 - val_loss: -0.8975 - val_binary_accuracy: 0.9981 - val_iou: 0.8141 - val_dice_coef: 0.8957 - lr: 1.0000e-05
Epoch 00142: LearningRateScheduler reducing learning rate to 1.000000059190693e-05.
Epoch 142/150
89/88 [==============================] - 93s 1s/step - loss: -0.9140 - binary_accuracy: 0.9983 - iou: 0.8469 - dice_coef: 0.9142 - val_loss: -0.8964 - val_binary_accuracy: 0.9981 - val_iou: 0.8186 - val_dice_coef: 0.8987 - lr: 1.0000e-05
Epoch 00143: LearningRateScheduler reducing learning rate to 1.0000000473525544e-05.
Epoch 143/150
89/88 [==============================] - 94s 1s/step - loss: -0.9159 - binary_accuracy: 0.9984 - iou: 0.8500 - dice_coef: 0.9158 - val_loss: -0.8960 - val_binary_accuracy: 0.9981 - val_iou: 0.8193 - val_dice_coef: 0.8991 - lr: 1.0000e-05
Epoch 00144: LearningRateScheduler reducing learning rate to 1.0000000378820435e-05.
Epoch 144/150
89/88 [==============================] - 93s 1s/step - loss: -0.9138 - binary_accuracy: 0.9983 - iou: 0.8464 - dice_coef: 0.9141 - val_loss: -0.8992 - val_binary_accuracy: 0.9982 - val_iou: 0.8077 - val_dice_coef: 0.8823 - lr: 1.0000e-05
Epoch 00145: LearningRateScheduler reducing learning rate to 1.0000000303056348e-05.
Epoch 145/150
89/88 [==============================] - 94s 1s/step - loss: -0.0561 - binary_accuracy: 0.9800 - iou: 0.0308 - dice_coef: 0.0558 - val_loss: -0.8901 - val_binary_accuracy: 0.9978 - val_iou: 0.7995 - val_dice_coef: 0.8876 - lr: 1.0000e-05
Epoch 00146: LearningRateScheduler reducing learning rate to 1.000000024244508e-05.
Epoch 146/150
89/88 [==============================] - 95s 1s/step - loss: -0.9168 - binary_accuracy: 0.9983 - iou: 0.8498 - dice_coef: 0.9165 - val_loss: -0.8983 - val_binary_accuracy: 0.9981 - val_iou: 0.8081 - val_dice_coef: 0.8908 - lr: 1.0000e-05
Epoch 00147: LearningRateScheduler reducing learning rate to 1.0000000193956063e-05.
Epoch 147/150
89/88 [==============================] - 93s 1s/step - loss: -0.9190 - binary_accuracy: 0.9983 - iou: 0.8523 - dice_coef: 0.9190 - val_loss: -0.8916 - val_binary_accuracy: 0.9981 - val_iou: 0.8040 - val_dice_coef: 0.8899 - lr: 1.0000e-05
Epoch 00148: LearningRateScheduler reducing learning rate to 1.0000000155164851e-05.
Epoch 148/150
89/88 [==============================] - 94s 1s/step - loss: -0.9194 - binary_accuracy: 0.9983 - iou: 0.8522 - dice_coef: 0.9189 - val_loss: -0.8860 - val_binary_accuracy: 0.9981 - val_iou: 0.8061 - val_dice_coef: 0.8895 - lr: 1.0000e-05
Epoch 00149: LearningRateScheduler reducing learning rate to 1.0000000124131881e-05.
Epoch 149/150
89/88 [==============================] - 93s 1s/step - loss: -0.9174 - binary_accuracy: 0.9982 - iou: 0.8508 - dice_coef: 0.9176 - val_loss: -0.8866 - val_binary_accuracy: 0.9980 - val_iou: 0.8029 - val_dice_coef: 0.8886 - lr: 1.0000e-05
Epoch 00150: LearningRateScheduler reducing learning rate to 1.0000000099305505e-05.
Epoch 150/150
89/88 [==============================] - 94s 1s/step - loss: -0.9174 - binary_accuracy: 0.9984 - iou: 0.8504 - dice_coef: 0.9173 - val_loss: -0.8979 - val_binary_accuracy: 0.9981 - val_iou: 0.8180 - val_dice_coef: 0.8988 - lr: 1.0000e-05
2.10 保存模型
model.save_weights('./save_weights/myUnet.ckpt',save_format='tf')
2.11 绘制损失值和准确率曲线
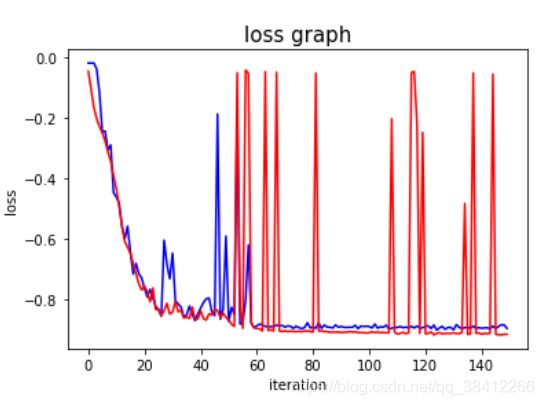
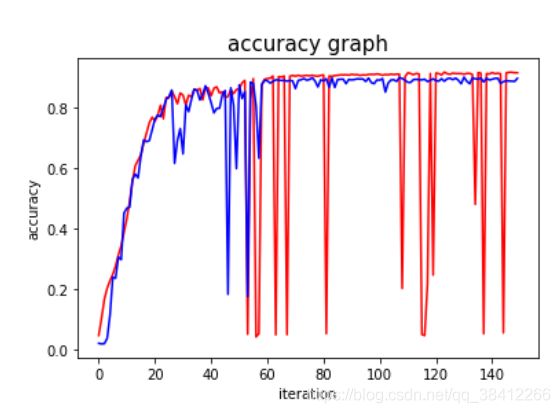
dice系数作为准确率,损失值由定义的损失函数确定
a = history.history
list_traindice = a['dice_coef']
list_testdice = a['val_dice_coef']
list_trainjaccard = a['iou']
list_testjaccard = a['val_iou']
list_trainloss = a['loss']
list_testloss = a['val_loss']
plt.figure(1)
plt.plot(list_testloss, 'b-')
plt.plot(list_trainloss,'r-')
plt.xlabel('iteration')
plt.ylabel('loss')
plt.title('loss graph', fontsize = 15)
plt.figure(2)
plt.plot(list_traindice, 'r-')
plt.plot(list_testdice, 'b-')
plt.xlabel('iteration')
plt.ylabel('accuracy')
plt.title('accuracy graph', fontsize = 15)
plt.show()
结果:
1.损失值
2.准确率
2.12 测试集准确率
test_gen = train_generator(df_test, BATCH_SIZE,
dict(),
target_size=(im_height, im_width))
results = model.evaluate(test_gen, steps=len(df_test) / BATCH_SIZE)
print("Test lost: ",results[0])
print("Test IOU: ",results[1])
print("Test Dice Coefficent: ",results[2])
结果:
Found 393 validated image filenames.
Found 393 validated image filenames.
13/12 [===============================] - 4s 289ms/step - loss: -0.8985 - binary_accuracy: 0.9981 - iou: 0.8231 - dice_coef: 0.9019
Test lost: -0.8985306620597839
Test IOU: 0.9980723261833191
Test Dice Coefficent: 0.8231154680252075
2.13 将测试结果可视化
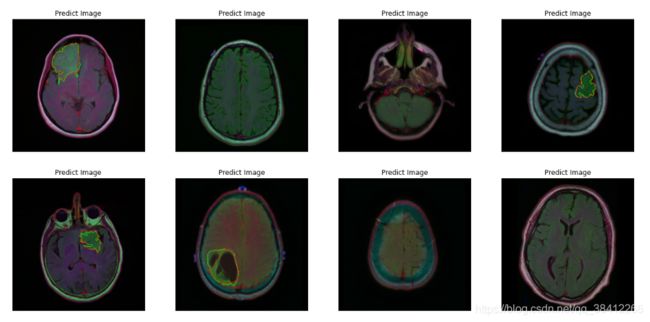
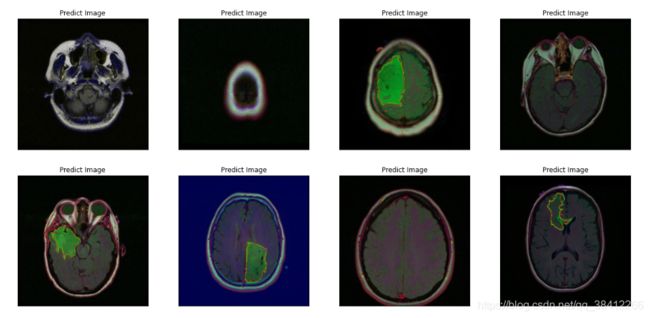
prediction_overlap = []
for i in range(16):
index=np.random.randint(1,len(df_test.index))
img1 = cv2.imread(df_test['filename'].iloc[index])
img1 = cv2.resize(img1 ,(im_height, im_width))
img = img1 / 255
img = img[np.newaxis, :, :, :]
prediction=model.predict(img)
prediction = np.squeeze(prediction)
ground_truth = cv2.resize(cv2.imread(df_test['mask'].iloc[index]),(256,256)).astype("uint8")
ground_truth = cv2.cvtColor(ground_truth,cv2.COLOR_BGR2GRAY)
_, thresh_gt = cv2.threshold(ground_truth, 127, 255, 0)
contours_gt, _ = cv2.findContours(thresh_gt, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
overlap_img = cv2.drawContours(img1, contours_gt, 0, (0, 255, 0),1)
prediction[np.nonzero(prediction < 0.3)] = 0.0
prediction[np.nonzero(prediction >= 0.3)] = 255.
prediction = prediction.astype("uint8")
_, thresh_p = cv2.threshold(prediction, 127, 255, 0)
contours_p, _ = cv2.findContours(thresh_p, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
overlap_img = cv2.drawContours(img1, contours_p, 0, (255,36,0),1)
prediction_overlap.append(overlap_img)
plt.figure(figsize=(20,20))
for i in range(len(prediction_overlap)):
plt.subplot(4,4,i+1)
plt.imshow(prediction_overlap[i])
plt.title('Predict Image')
plt.xticks([])
plt.yticks([])
结果:
绿色轮廓为测试集原始分割图像轮廓,红色轮廓为预测分割图像轮廓