【计算机视觉】局部图像描述子
图像特征匹配与地理标记特征匹配
- 一、图像特征匹配
-
- 1、图像特征点匹配
- 2、Harris角点检测
-
- 2.1角点介绍
- 2.2Harris算法介绍
- 2.3Harris角点响应函数R
- 2.4Harris角点检测代码实现
- 2.5结果
- 2.6实验结论
- 3、SIFT特征提取与检测
-
- 3.1SIFT算子介绍
- 3.2SIFT实现步骤简述
- 3.3SIFT特征提取算法
- 3.4开源工具包VLFeat安装
- 3.5SIFT特征提取与检测代码实现
- 3.6结果
- 3.7实验结论
- 二、地理标记特征匹配
-
- 1、提取特征
-
- 1.1代码
- 2、使用局部描述子匹配
-
- 2.1代码
- 3、可视化连接图像
-
- 3.1GraphViz、pydot安装配置
- 3.2代码
- 4、结果
- 5、分析与结论——SIFT优缺点
- 三、问题
-
- 注意安装顺序
- 报错
一、图像特征匹配
1、图像特征点匹配
(1)同名点
同一目标点在不同像片上的构像点。
(2)同名点匹配
是图像拼接、三维重建、相机标定等应用的关键步骤。
(3)特征匹配的基本流程:
①找点(找到左右边图像中比较显著的关键点)
②为每个关键特征点打上一个标签即一个身份,用向量表示,向量称为特征描述符
③有向量后,我们可以去右边图像中找到特征点看哪里与左边图像接近(找到匹配关系)
2、Harris角点检测
2.1角点介绍
角点:角点可以是两条线的交叉处,也可以是位于相邻的两个主要方向不同的事物上的点,即某方面特别突出的点。角点在保留图像图形重要特征的同时,可以有效地减少信息的数据量,使其信息的含量很高,有效地提高了计算的速度,有利于图像的可靠匹配。
如图不同类型的角点:

角点特征
①局部窗口沿各方面移动,均产生明显变化的点
②图像局部曲率突变的点
角点检测算法如今可以归纳为3类:基于灰度图像的角点检测、基于二值图像的角点检测、基于轮廓曲线的角点检测。
2.2Harris算法介绍
什么是好的角点检测算法?
①检测出图像中“真实的”角点
②准确的定位性能
③很高的稳定性
④具有对噪声的鲁棒性
⑤具有较高的计算效率
Harris角点检测:是特征点检测的基础,提出了应用邻近像素点灰度差值概念,从而进行判断是否为角点、边缘、平滑区域。
Harris角点检测原理:是利用移动的窗口在图像中计算灰度变化值,其中关键流程包括转化为灰度图像、计算差分图像、高斯平滑、计算局部极值、确认角点。
Harris角点检测基本思想:
在窗口任意方向移动角点的图像灰度都会发生明显变化;
边缘区域只有在左右移动时变化明显,上下移动无变化;
平坦区域任意方向移动都无变化。如下图分别为平坦区域,边缘区域和角点时的变化情况。

Harris角点数学表达:
将图像窗口平移[u,v]产生灰度变化E(u,v)

通过一元和二元泰勒产开后:
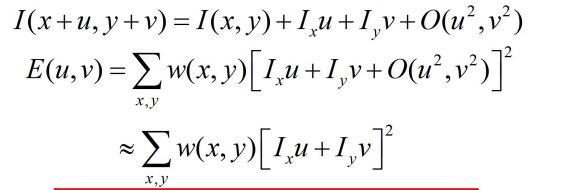
对于局部微小的移动量[u,v],可以近似得到下面的表达:

其中M是2*2的矩阵,可由图像的导数求得:

2.3Harris角点响应函数R
①矩阵M,将其对角化之后,特征值λ1, λ2 分别代表了X 和Y 方向的灰度变化率:

②通过M的两个特征值λ1, λ2的大小对图像点进行分类:

如图所示:
如果λ1, λ2都很小, 图像窗口在所有方向上移动都无明显灰度变化。
如果λ1, λ2都很大, 图像窗口在所有方向上移动都产生明显灰度变化。
③定义:角点响应函数R:

R只与M的特征值有关:

在角点丰富的图中:R值为正值,因为角点丰富的图入1入2值都较大即detM值大,则R值大。
在平坦的图中:R值为小数值,且平坦的图中含有边缘,因此R值也有负数值;因为在平坦的图中,入1入2值都很小,所以R值小。
在边缘丰富的图中:入1和入2的值一方大一方小,所以R值为大值负数。
④角点响应函数R对于旋转具有不变性
对于图像的灰度变化具有部分不变性
对于图像尺度变化不具有不变性
2.4Harris角点检测代码实现
# -*- coding: utf-8 -*-
from pylab import *
from PIL import Image
from PCV.localdescriptors import harris
"""
Example of detecting Harris corner points (Figure 2-1 in the book).
"""
# 读入图像
im = array(Image.open(r'C:\Users\ltt\Documents\Subjects\大三下\计算机视觉(蔡国榕)\第二章\Cap2\1\gq.jpg').convert('L'))
# 检测harris角点
harrisim = harris.compute_harris_response(im)
# Harris响应函数
harrisim1 = 255 - harrisim
figure()
gray()
#画出Harris响应图
subplot(141)
imshow(harrisim1)
print (harrisim1.shape)
axis('off')
axis('equal')
threshold = [0.01, 0.05, 0.1]
for i, thres in enumerate(threshold):
filtered_coords = harris.get_harris_points(harrisim, 6, thres)
subplot(1, 4, i+2)
imshow(im)
print(im.shape)
plot([p[1] for p in filtered_coords], [p[0] for p in filtered_coords], '*')
axis('off')
show()
2.5结果
原图:

实验结果:

结论:
①该代码先代入一幅图像,将其转换成灰度图像,然后计算相响应函数,通过响应值选择角点。最后,将这些检测的角点在原图上显示出来。
②本次实验中,角点较多的区域是目标的轮廓和色彩比较深的区域。
2.6实验结论
增大threshold的值,将减小角点响应值R RR,降低角点检测的灵性,减少被检测角点的数量;减小threshold值,将增大角点响应值R RR,增加角点检测的灵敏性,增加被检测角点的数量。
Harris算法的主要特点是阈值决定检测点数量;
角点检测算子对亮度和对比度的变化不敏感;
具有旋转不变性,不具有尺度不变性;
harris算法中的阈值依赖于实际图像的属性,不具有直观的物理意义,具体值难确定。
3、SIFT特征提取与检测
3.1SIFT算子介绍
在之前的学习中,我们学习了角点的基本知识,并对Harris角点检测算法应用到了图像的角点检测。
当我们在观察图像中的物体时,物体所在的图像不论背景或者角度如何变换,我们依然能很快的识别出图像中的目标物体。对机器来说,则需要定义图像上的关键特征并且能够根据这些特征搜索到一张新的图片。
SIFT,即尺度不变特征变换(Scale-invariant feature transform,SIFT)。是在计算机视觉任务中特征提取算法。
3.2SIFT实现步骤简述
SIFT算法的实质可以归为在不同尺度空间上查找特征点(关键点)的问题。SIFT算法实现特征匹配主要有三个流程:
a.提取关键点;
b.对关键点附加详细的信息(局部特征),即描述符;
c.通过特征点(附带上特征向量的关键点)的两两比较找出相互匹配的若干对特征点,建立景物间的对应关系。
3.3SIFT特征提取算法
①构建尺度空间,检测极值点,获得尺度不变性
-
构建尺度空间——特征点的性质之一就是对尺度的变化保持不变性。因此寻找的特征点要在不同尺度下都能被检测出来.根据文献可知,变换到尺度空间唯一的核函数是高斯函数。因此一个图像的尺度空间定义为:L( x,y,σ)是由可变尺度的高斯函数G(x,y,σ) 与输入图像I(x,y卷积得到
即: L(x,y,σ)=G(x,y,σ)∗I(x,y)
( x , y )是尺度坐标,σ大小决定图像的平滑程度,大尺度对应图像的概括特征,小尺度对应图像的细节特征,大的σ对应粗糙尺度(低分辨率),小σ对应高分辨率。为使计算相对高效,真正使用的是差分高斯尺度空间
D(x,y,σ):
-
高斯模糊——降低图像中的噪点,强调了图像的重要特征。进行高斯模糊之和,纹理和次要细节将从图像中删除,并且保留形状和边缘之类的相关信息。

-
实现DOG——初始图像与不同σ值的高斯函数卷积,得到一垛模糊后图像,然后将这一垛图像临近两两相减得到对应的DOG。一副图像可以产生几组图像,一组图像包括几层图像。s为每组层数一般为3~5层,最后可以将s和k的关系确立为k=2^(1/s)

-
尺度空间检测极值点——DOG上某个像素要和本尺度的8个像素以及上下相邻尺度各9个相邻像素共26个像素值进行比较,以确定是否为局部最大或最小值。如果它是相邻像素中最高或者最低的像素,则确定该像素点是尺度空间的极值点之一。

②筛选关键点,剔除不稳定的极值点
去掉对比度低的以及处于不理想边缘处的关键点,得到符合要求的特征关键点。
③在特征点处提取特征描述符,为特征点分配方向值
确定关键点的方向采用梯度直方图统计法,统计以关键点为原 点,一定区域内的图像像素点对关键点方向生成所作的贡献。
④生成特征描述符,利用特征描述符寻找匹配特征点
下图是一个SIFT描述子事例。其中描述子由2×2×8维向量表征,也即是
2×2个8方向的方向直方图组成。左图的种子点由8×8单元组成。每一个小格
都代表了特征点邻域所在的尺度空间的一个像素,箭头方向代表了像素梯度方
向,箭头长度代表该像素的幅值。然后在4×4的窗口内计算8个方向的梯度方
向直方图。绘制每个梯度方向的累加可形成一个种子点,如右图所示:一个特
征点由4个种子点的信息所组成。

⑤关键点匹配
为了对这些特征点进行匹配,需要对这些特征点运用适当的比较方法来找到相应关系。
特征点的匹配可以采用穷举法来完成,但是这样耗费的时间太多,一 般都采用kd树的数据结构来完成搜索。搜索的内容是以目标图像的特征点为基准,搜索与目标图像的特征点最邻近的原图像特征点和次邻 近的原图像特征点。
3.4开源工具包VLFeat安装
为了计算图像的SIFT特征,我们用开源工具包VLFeat。用Python重新实现SIFT特征提取的全过程不会很高效。VLFeat可以在www.vlfeat.org上下载,它的二进制文件可以用于一些主要的平台。这个库是用C写的,不过我们可以利用它的命令行接口。此外,它还有Matlab接口。
3.5SIFT特征提取与检测代码实现
from pylab import *
from PIL import Image
from numpy import *
import os
def process_image(imagename, resultname, params="--edge-thresh 10 --peak-thresh 5"):
"""处理一幅图像,然后将结果保存在文件中"""
if imagename[-3:] != 'pgm':
# 创建一个pgm文件
im = Image.open(imagename).convert('L')
im.save('tmp.pgm')
imagename = 'tmp.pgm'
cmmd = str(r"C:\Users\ltt\Documents\Subjects\大三下\计算机视觉(蔡国榕)\win64vlfeat\sift.exe " + imagename + " --output=" + resultname + " " + params)
os.system(cmmd)
print('processed', imagename, 'to', resultname)
def read_features_from_file(filename):
"""读取特征值属性值,然后将其以矩阵形式返回"""
f = loadtxt(filename)
return f[:, :4], f[:, 4:] # 特征位置,描述子
def plot_features(im, locs, circle=False):
"""显示带有特征的图像
输入:im(数组图像),locs(每个特征的行、列、尺度和方向角度)"""
def draw_circle(c,r):
t = arange(0,1.01,.01)*2*pi
x = r*cos(t) + c[0]
y = r*sin(t) + c[1]
plot(x,y,'b',linewidth=2)
imshow(im)
if circle:
for p in locs:
draw_circle(p[:2],p[2])
else:
plot(locs[:,0],locs[:,1],'ob')
axis('off')
return
def match(desc1, desc2):
"""对于第一幅图像的每个描述子,选取其在第二幅图像中的匹配
输入:desc1(第一幅图像中的描述子),desc2(第二幅图像中的描述子)"""
desc1 = array([d/linalg.norm(d) for d in desc1])
desc2 = array([d/linalg.norm(d) for d in desc2])
dist_ratio = 0.6
desc1_size = desc1.shape
matchscores = zeros((desc1_size[0],1), 'int')
desc2t = desc2.T #预先计算矩阵转置
for i in range(desc1_size[0]):
dotprods = dot(desc1[i,:], desc2t) #向量点乘
dotprods = 0.9999*dotprods
# 反余弦和反排序,返回第二幅图像中特征的索引
index = argsort(arccos(dotprods))
# 检查最近邻的角度是否小于dist_ratio乘以第二近邻的角度
if arccos(dotprods)[index[0]] < dist_ratio * arccos(dotprods)[index[1]]:
matchscores[i] = int(index[0])
return matchscores
def match_twosided(desc1,decs2):
"""双向对称版本的match"""
matches_12 = match(desc1, decs2)
matches_21 = match(decs2, decs2)
ndx_12 = matches_12.nonzero()[0]
# 去除不对称匹配
for n in ndx_12:
if matches_21[int(matches_12[n])] != n:
matches_12[n] = 0
return matches_12
def appendimages(im1, im2):
"""返回将两幅图像并排拼接成的一幅新图像"""
# 选取具有最少行数的图像,然后填充足够的空行
row1 = im1.shape[0]
row2 = im2.shape[0]
if row1 < row2:
im1 = concatenate((im1,zeros((row2-row1,im1.shape[1]))), axis=0)
elif row1 > row2:
im2 = concatenate((im2,zeros((row1-row2,im2.shape[1]))), axis=0)
# 如果这些情况都没有,那么他们的行数相同,不需要进行填充
return concatenate((im1,im2), axis=1)
def plot_matches(im1, im2, locs1, locs2, matchscores, show_below=True):
"""显示一幅带有连接匹配之间连线的图片
输入:im1,im2(数组图像),locs1,locs2(特征位置),matchscores(match的输出),
show_below(如果图像应该显示再匹配下方)"""
im3 = appendimages(im1,im2)
if show_below:
im3 = vstack((im3,im3))
imshow(im3)
cols1 = im1.shape[1]
for i in range(len(matchscores)):
if matchscores[i] > 0:
plot([locs1[i, 0], locs2[matchscores[i, 0], 0] + cols1], [locs1[i, 1], locs2[matchscores[i, 0], 1]], 'c')
axis('off')
if __name__ == '__main__':
# imname = 'raccoon.jpg'
# im1 = array(Image.open(imname).convert('L'))
# process_image(imname, 'raccoon.sift')
# l1, d1 = read_features_from_file('raccoon.sift')
#
# figure()
# gray()
# plot_features(im1, l1, circle=True)
# show()
im1f = r'C:/Users/ltt/Documents/Subjects/大三下/计算机视觉(蔡国榕)/第二章/Cap2/1/gq.jpg'
im2f = r'C:/Users/ltt/Documents/Subjects/大三下/计算机视觉(蔡国榕)/第二章/Cap2/1/gq.jpg'
im1 = array(Image.open(im1f))
im2 = array(Image.open(im2f))
process_image(im1f, 'out_sift_1.txt')
l1, d1 = read_features_from_file('out_sift_1.txt')
figure()
gray()
subplot(121)
plot_features(im1, l1, circle=False)
process_image(im2f, 'out_sift_2.txt')
l2, d2 = read_features_from_file('out_sift_2.txt')
subplot(122)
plot_features(im2, l2, circle=False)
matches = match_twosided(d1, d2)
print('{} matches'.format(len(matches.nonzero()[0])))
figure()
gray()
plot_matches(im1, im2, l1, l2, matches, show_below=True)
show()
3.6结果
原图:
library1:
library2:

实验结果:


结论:
- 通过实验发现Harris角点的匹配数很多,SIFT匹配点数量少一些。
- SIFT匹配点因为有通过当两幅图像的SIFT特征向量生成后,下一步我们采用关键点特征向量的欧式距离来作为两幅图像中关键点的相似性判定度量。取图像1中的某个关键点,并找出其与图像2中欧式距离最近的前两个关键点,在这两个关键点中,如果最近的距离除以次近的距离少于某个比例阈值,则接受这一对匹配点。降低这个比例阈值,SIFT匹配点数目会减少,但更加稳定。
3.7实验结论
- SIFT特征检索是基于内容的图像检索技术是基于图像自身的内容特征来检索图像,这免去人为标注图像的过程。基于内容的图像检索技术是采用某种算法来提取图像中的特征(SIFT,SURF,CNN等),并将特征存储起来,组成图像特征数据库。当需要检索图像时,采用相同的特征提取技术提取出待检索图像的特征,并根据某种相似性准则计算得到特征数据库中图像与待检索图像的相关度,最后通过由大到小排序,得到与待检索图像最相关的图像,实现图像检索。
- SIFT算法是提取特征的一个重要算法,该算法对图像的扭曲,光照变化,视角变化,尺度旋转都具有不变性。
二、地理标记特征匹配
1、提取特征
先对图像使用SIFT特征提取代码进行处理,并且将特征保存在和图像同名(但文件名是.sift,而不是.jpg)的文件路径下。
1.1代码
download_path = r"C:\Users\ltt\Documents\Subjects\大三下\计算机视觉(蔡国榕)\第二章\data"
path = r"C:\Users\ltt\Documents\Subjects\大三下\计算机视觉(蔡国榕)\第二章\data"
imlist = imtools.get_imlist(download_path)
nbr_images = len(imlist)
featlist = [imname[:-3] + 'sift' for imname in imlist]
for i, imname in enumerate(imlist):
sift.process_image(imname, featlist[i])
2、使用局部描述子匹配
我们可以对所有的组合图像进行逐个匹配,我们将每对图像间的匹配特征数保存在matchscores数组中。
2.1代码
matchscores = zeros((nbr_images, nbr_images))
for i in range(nbr_images):
for j in range(i, nbr_images): # only compute upper triangle
print('comparing ', imlist[i], imlist[j])
l1, d1 = sift.read_features_from_file(featlist[i])
l2, d2 = sift.read_features_from_file(featlist[j])
matches = sift.match_twosided(d1, d2)
nbr_matches = sum(matches > 0)
print('number of matches = ', nbr_matches)
matchscores[i, j] = nbr_matches
# copy values
for i in range(nbr_images):
for j in range(i + 1, nbr_images): # no need to copy diagonal
matchscores[j, i] = matchscores[i, j]
3、可视化连接图像
我们会用到pydot工具包,该工具包要需要用到GraphViz,先去官网下载安装即可graphviz。注意记得安装路径,下载后需要添加环境变量。配置后在命令行输入dot -version,查看graphviz是否安装成功。
3.1GraphViz、pydot安装配置
可视化连接图像需要构建线条对图片进行相连操作,而pydot工具包提供了GraphViz graphing库的Python接口,可以实现连接可视化。
在Windows系统上安装配置Graphviz:
-
首先下载安装包graphviz-2.38.msi,下载地址为https://graphviz.gitlab.io/_pages/Download/Download_windows.html
-
双击msi文件,然后一直选择next(默认安装路径为C:\Program Files(x86)\Graphviz2.38\),安装完成之后,会在windows开始菜单创建快捷信息。
-
配置环境变量:计算机→属性→高级系统设置→高级→环境变量→系统变量→path,在path中加入路径:C:\Program Files(x86)\Graphviz2.38\bin
-
验证:在windows命令行界面,输入dot
-version,然后按回车,如果显示如下图所示的graphviz相关版本信息,则安装配置成功。
成功后直接在命令行中pip pydot和graphviz
pip install graphviz
pip install pydot
3.2代码
# 可视化
threshold = 2 # min number of matches needed to create link
g = pydot.Dot(graph_type='graph') # don't want the default directed graph
for i in range(nbr_images):
for j in range(i + 1, nbr_images):
if matchscores[i, j] > threshold:
# first image in pair
im = Image.open(imlist[i])
im.thumbnail((100, 100))
filename = path + str(i) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(i), fontcolor='transparent', shape='rectangle', image=filename))
# second image in pair
im = Image.open(imlist[j])
im.thumbnail((100, 100))
filename = path + str(j) + '.jpg'
im.save(filename) # need temporary files of the right size
g.add_node(pydot.Node(str(j), fontcolor='transparent', shape='rectangle', image=filename))
g.add_edge(pydot.Edge(str(i), str(j)))
g.write_jpg('tt.jpg')
4、结果
原图:

运行结果:
(图片过大容易发生过多索引的错误,并且过大也会运行很久,建议图像都压缩一下)

5、分析与结论——SIFT优缺点
- 实验放置了三组图像:尚大楼,延奎图书馆,亭子,皆为不同视角所拍摄。
- 实验测试了13张图片,最终只有9张图片可以被匹配出来。这是因为在代码中,我们设置了阈值theshhod=2,但是有些图片的特征点匹配数量不超过2个,因此无法匹配显示出来。
- 此图中library3.jpg为较远视角时所拍摄,且有其他建筑物影响,但是SIFT算法依旧可以进行准确的匹配,说明SIFT算法在地理建筑匹配中的确有很大的优势。【优点】
- 尽管SIFT算法进行地理特征匹配有很大优势,且对于不同的视角的图像用SIFT算法可以进行很好的匹配,但是图中的jmu04.jpg依旧没有被识别匹配出来,所以SIFT并不是完美的,角度旋转过多,导致目标匹配的特征点消失,因此无法被识别从而匹配。【缺点】
三、问题
注意安装顺序
1.我们需要先下载安装graphviz
2.配置环境变量
3.在cmd后输入pip install pydot进行pydot的安装下载。
报错
1.OSError: XXXX.sift not found
此时需要检查系统中各个包是否导入,路径是否正确。
- 检查PCV的sift.py文件中cmmd处路径是否已经换成自己项目中的【sift.exe】文件路径。注意路径末尾(引号前)留一个空格
- 检查pydot和graphviz是否导入且路径是否正确,可以直接在pycharm的左下角terminal处dot
-version看是否导入成功或者查看pycharm->file->settings->Project->Project Interpreter看pydot等是否存在。 - 若检查发现问题依旧解决不了,点开pycharm->file->settings->Project->Project
Interpreter,点击右侧加号,搜索pydot等进行安装。 - 如果发现代码没错,配置也都没错,但是结果始终报错,那就是玄学问题了,博主只能说听天由命吧!(一开始pycharm始终查不到错,便抱着试试的心态在命令行运行了代码,结果成功运行出来之后,本人的pycharm居然奇迹般地自己好了,运行也可以运行,错误也不报了!)
2.too many indices for array
- 同(1)中解决办法,一切都配置确认无误之后,检查图片大小,如果图片太大,索引太多会超出范围且运行速度也会十分的慢,可以修改每张图片的大小进行压缩。