在计算机视觉中的单任务学习已经取得了很大的成功。但是许多现实世界的问题本质上是多模态的。例如为了提供个性化的内容,智能广告系统应该能够识别使用的用户并确定他们的性别和年龄,跟踪他们在看什么,等等。多任务学习(Multi-Task Learning, MTL)可以实现这样的系统,其中一个模型在多个任务之间分配权重,并在一次正向传递中产生多个推理。

多任务学习中的优化
因为有多个任务同时运行所以MTL 的优化过程与一般的单任务模型有所不同,为了避免一项或多项任务对网络权重产生主导影响,应该仔细平衡所有任务的联合学习。这里介绍了一种考虑任务平衡问题的方法。
MTL 问题中的优化目标可以表述为
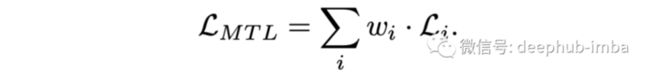
这里‘wi’是特定任务的权重,‘Li’是特定的损失函数,使用随机梯度下降来最小化上述目标,共享层“Wsh”中的网络权重更新为:
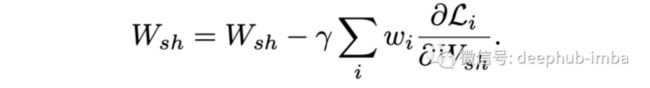
当任务梯度发生冲突时,或者说当一个任务的梯度幅度远高于其他任务时,网络权重更新可能不是最优的。这就需要在损失中设置针对于不同任务的权重,这样才能保证梯度幅度在各个任务间的相对平衡。
梯度归一化
有一种称为梯度归一化 (GradNorm)[1] 的优化方法,通过使不同任务的梯度具有相似大小来控制多任务网络训练的方法。这样可以鼓励网络以相同的速度学习所有任务。在展示这种方法之前,我们将介绍相关的符号。

这里也为每个任务 i 定义了不同的训练率:

GradNorm 旨在在多任务网络的训练过程中平衡两个属性:
1、平衡梯度幅度:平均梯度被用作基线,可以根据该基线计算作业之间的相对梯度大小。
2、在学习不同任务的速度之间找到一个很好的平衡点:使用了loss变化率(inversetrainingrate), 任务 i 的梯度幅度应该随着相对变化率的增加而增加,从而刺激任务更快地训练。GradNorm 通过减少以下损失来实现这些目标。
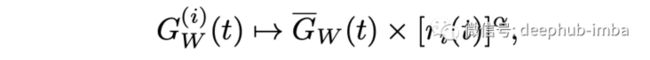
其中 α 是已添加到方程中的附加超参数。α 设置“恢复力”的强度,可以使任务恢复到一个普通的训练速率。在任务复杂性大导致任务之间的学习动态差异大时,应使用更大的 α 值来确保更好的训练率平衡。当问题更加对称时,需要较低的 α 值。
实验
这里使用了 NYUv2 的两种变体数据集。将每个视频的翻转和附加帧添加到标准 NYUv2 数据集中。我们额外添加了 90,000 张照片,每张照片都包含单目深度估计, 表面法线估计, 关键点定位。这些额外的帧没有分段标签。所以就获得两个数据集:NYUv2+seg 和 NYUv2+kpts。这里将交叉熵用于分割,将平方损失用于深度估计,将余弦相似度用于法线估计。
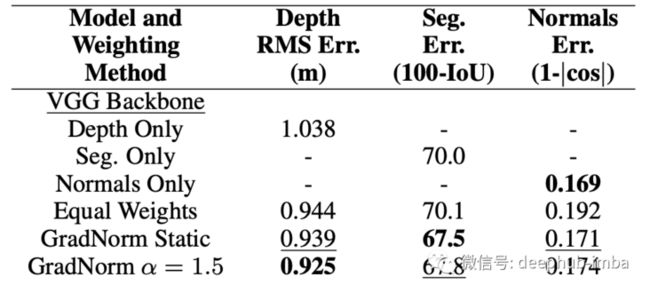
上表中看到 GradNorm α = 1.5 提高了所有三个任务相对于等权基线的性能,并且超过或匹配每个任务的单个网络的最佳性能。
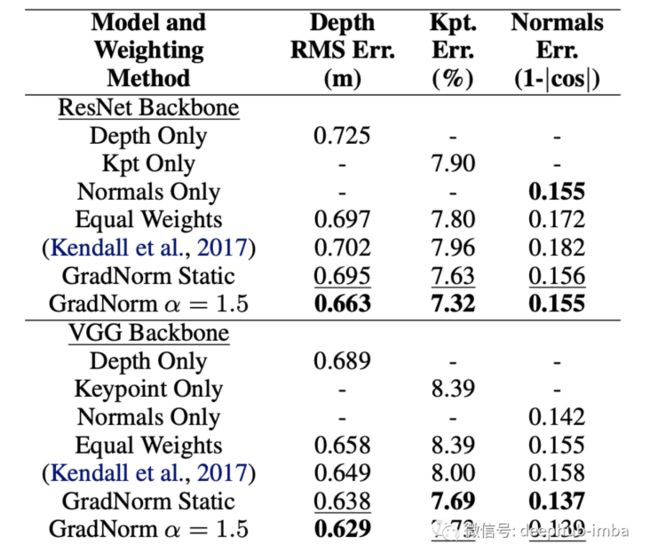
为了展示 GradNorm 如何在更大数据集的情况下执行,还在 NYUv2+kpts 数据集上进行了广泛的实验。

尽管训练损失更高了,但GradNorm 通过对网络进行速率平衡将深度估计的测试误差减少5%。并最终将深度的权重抑制到了低于 0.10,并且关键点的误差也出现了通向的趋势,这就是网络正则化的明显趋势。
实验表明:对于各种网络架构例如回归和分类任务,与单任务网络、固定比例的基线和其他自适应多任务损失平衡技术相比,GradNorm 提高了准确性并减少了跨多个任务的过度拟合。
深度多任务学习架构
本节将讨论能够同时学习[2]多个任务的网络架构。我们将关注两种类型的深层多任务架构:以编码器为中心的架构和以解码器为中心的架构。
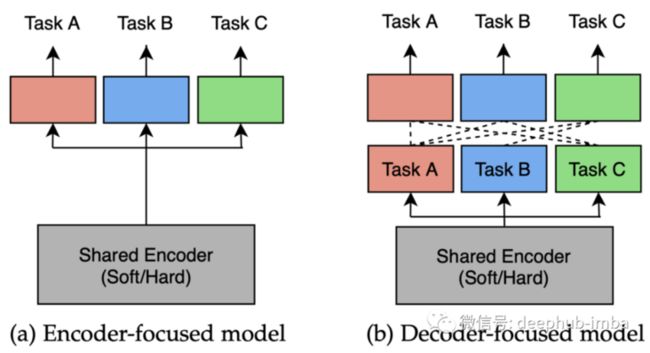
以编码器为中心的架构在编码阶段共享任务特征,然后用一组独立的特定任务头处理它们。他们在一个处理周期中直接预测来自相同输入的所有任务输出。
但是以编码器为中心的架构无法捕捉任务之间的共性和差异,最近的一些研究工作发现:首先使用多任务网络来进行初始任务预测,然后利用这些初始预测的特性来进一步改进每个任务的输出。这些MTL方法也在解码阶段共享或交换信息,这里将它们称为以解码器为中心的体系结构。
实验
这里使用两个数据集(NYUD-v2 数据集和 PASCAL 数据集)对不同多任务架构的性能进行实验。
NYUD-v2 数据集考虑了室内场景理解。这里专注于语义分割和深度估计任务,mIoU (mean intersection over union)和rmse (root mean square error)来分别评估语义分割和深度估计任务。
PASCAL 数据集是密集预测任务的流行基准。F-measure (odsF) 用于评估边缘检测任务。语义分割、和人体部分分割任务使用mIoU (mean intersection over union)进行评估。使用预测角度中的平均误差 (mErr) 来评估表面法线。
将多任务性能 ΔMTL 定义为每个任务的平均性能下降:
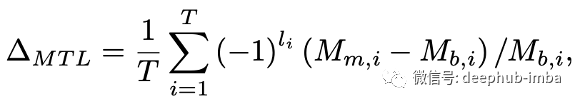
li = 1,如果值越低意味着度量Mi的性能越好。
结果如下:
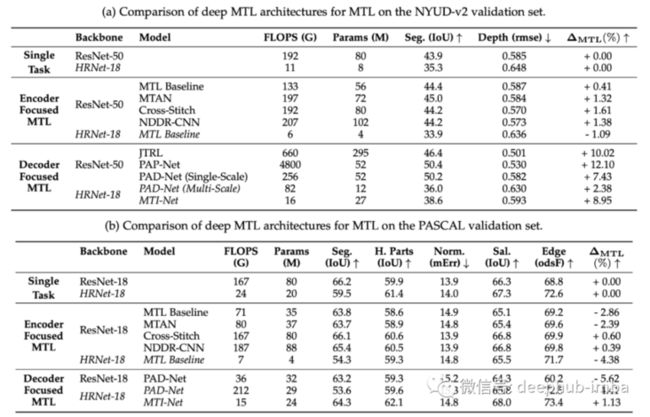
单任务与多任务:首先,将专注于编码器和专注于解码器的 MTL 模型与它们在 NYUD-v2 和 PASCAL 上的单任务对应进行比较。相对于单任务学习,MTL 可以提供几个优点,即更小的内存占用、减少的计算次数和更高的性能。
在 NYUD-v2 上,MTL 证明了一种联合处理分割和深度估计是有效策略。并且大多数 MTL 模型优于单任务网络集。
在 PASCAL 上,使用 MTL 基线时处理效率更高,但性能也会下降。大多数模型在 PASCAL 上的表现都没有优于它们的单任务模型,这是可能因为多任务的相关性的影响。在 NYUD-v2 上是语义分割和深度估计的任务,这对任务密切相关的,语义分割和深度估计都揭示了场景的相似特征,例如布局和对象形状或边界。但是PASCAL 包含一个更大、更多样化的任务类型。
在比较以编码器和以解码器为中心的模型时,我们发现以解码器为中心的架构通常优于以编码器为中心的架构。我们认为这是因为每种架构范式都有不同的用途。以编码器为中心的架构旨在通过在编码过程中共享信息来学习更丰富的图像特征表示。以解码器为中心的那些专注于通过跨任务交互反复细化预测来改进密集预测任务。因为交互发生在网络输出附近,因此它们可以更好地对齐常见的跨任务模式,并大大提升性能。
以编码器为中心和以解码器为中心都具有优势。所以在未来,我们可以尝试将这两种范式整合在一起。
深入研究
第一篇论文讨论了使用 GradNorm 进行自适应损失平衡以提高深度多任务网络的性能。不同的任务有不同的训练率和数据规模。Normal 方法可能会导致梯度不平衡,并自动专注于某一项任务而忽略其他任务。论文提出的一种梯度归一化,用于深度多任务网络中的自适应损失平衡来解决这个问题。
第二篇论文比较了编码器和解码器架构在不同数据集中的性能。结果表明,相关任务比使用多任务学习的不相关任务执行得更好,并且以解码器为中心的架构通常优于以编码器为中心的架构。
从这两篇论文中,我们可以看到:使用多任务学习,相关任务比不相关任务表现更好;以解码器为中心的架构通常优于以编码器为中心的架构;这些论文关注的是 MTL 模型的优化器,而不是损失函数的定义。
总之,多任务学习有助于提高 AUC 分数的性能并减少损失,对于不同类型的任务,特定的 MTL 模型会表现得更好。因此为特定的任务场景选择或构建模型可能是目前最好的选择。
引用
[1] GradNorm: Gradient Normalization for Adaptive Loss Balancing in Deep Multitask Networks, arxiv 1711.02257
[2] Multi-Task Learning for Dense Prediction Tasks: A Survey, arxiv 2004.13379
https://www.overfit.cn/post/5a90e7982e254a0580ab3eeeec728714
作者:Huaizhi Ge