【Pytorch学习笔记】1.Python的yield和next是什么?为什么常用来读取数据(DataLoader)?
初学Pytorch,先讲讲我在代码中遇到的在Python本身用的不太多的知识点,比如yield和next。
文章目录
-
- 定义数据读取的函数时常用yield
- 什么是yield
- iterable(可迭代对象)、iterator(迭代器)、generator(生成器)
- Pytorch的DataLoader()是一个 iterable
- 使用yield的函数定义是一个generator(生成器)
定义数据读取的函数时常用yield
学线性回归时,会碰到以下关于数据读取的代码,展示了数据读取的常用方法:
(源码链接:动手学深度学习Pytorch-线性回归)
(features是样本特征集合,每个样本由一个n维向量表示,构成一个Tensor。
labels表示样本的标签集合,构成一个一维Tensor。)
def data_iter(batch_size, features, labels):
num_examples = len(features) # 样本数量
indices = list(range(num_examples))
# indices表示从0到 num_examples(样本数量)-1 的数组成的列表
random.shuffle(indices) # 样本的读取顺序是随机的
for i in range(0, num_examples, batch_size):
j = torch.LongTensor(indices[i: min(i + batch_size, num_examples)])
# 建立一个LongTensor(整形Tensor)用来表示索引。最后一次可能不足一个batch,所以用min
yield features.index_select(0, j), labels.index_select(0, j)
之后我们就可以用
batch_size = 10
data_iter = data_iter(batch_size, features, labels)
next(data_iter)
# 会显示:
(tensor([[-1.2638, -1.4877],
[-0.1879, -0.2892],
[ 1.5612, -0.4944],
[ 0.7337, -1.0936],
[-0.2300, 0.7310],
[-0.1306, -0.8963],
[-1.7656, 1.3523],
[-1.2173, 3.2634],
[ 0.4237, 0.4772],
[-1.4817, -0.6735]]),
tensor([ 6.7253, 4.8145, 9.0083, 9.3764, 1.2536, 6.9746, -3.9365, -9.3228,
3.4225, 3.5481]))
来获取一个批次的数据,一次next获取一批batch_size的数据。
什么是yield
我们看到上面定义函数data_iter时用了yield,读取数据时用了next调用函数获得一个批次,再调用一次next会获取下个批次。
可以先这么理解:
- 把 yield 理解成 return,即函数的返回值
- 理解成return后发现,for循环中就循环了一次return。那么这个yield其实就是个断点续传的return,每次续传的指令由 next(函数名) 来发出。
每发出一次next指令就会寻找下一句yield的返回值。
到这里已经可以理解数据读取的方式了。
那么这背后的原理是什么呢?这么读取会有什么优点?
iterable(可迭代对象)、iterator(迭代器)、generator(生成器)
在Python中,我们常用for循环来遍历一个容器,比如一个列表List:
x = [1, 2, 3]
for item in x:
print(item)
# 会显示:
1
2
3
这里List就是一个可迭代对象iterable,它可以通过for循环取到里面的元素。
在Python中,通过for循环取到容器里的元素,背后是通过将 iterable(可迭代对象) 生成一个 iterator(迭代器) 来进行迭代遍历的。所有可迭代对象都有一个魔法方法__iter__(),用于以自己为蓝本生成一个迭代器。
迭代器内部又有__next__()方法,按顺序依次取到下一个元素,取完一轮后迭代完毕,失去作用。for循环作用于迭代器就相当于就自动执行一轮next。
这样做有什么好处呢?看个例子:
我们使用 iter() 方法手工将List转换成迭代器。使用sys.getsizeof()方法查看对象的内存占用情况。
x = [x for x in range(100000)]
for item in x:
pass
x_iter = iter(x)
for item in x1:
pass
for item in x1:
print('do it again')
# 因为第一次循环已经跑完一轮迭代,再来一次循环将不会有任何迭代
import sys
print(sys.getsizeof(x)) # 查看List的内存占用
print(sys.getsizeof(x1)) # 查看迭代器的内存占用
# 显示:
824464
56
可看到迭代器占用内存极小。
当我们处理大批量数据时,由于计算机内存有限,如果使用普通的可迭代对象进行遍历是不现实的,需要通过生成迭代器来读取一批批的数据。
生成了迭代器后,我们就可以使用next(迭代器)方法来手工获取迭代数据了:
x = [x for x in range(100000)]
x_iter = iter(x)
print(next(x_iter))
print(next(x_iter))
print(next(x_iter))
# 显示:
0
1
2
总结:
iterator 能取next 和 进行for循环,只能迭代一遍。
iterable是数据源,不能next取批量,通过生成iterator进行for循环迭代或者next。
iter(iterable) 方法生成 iterator
图示:
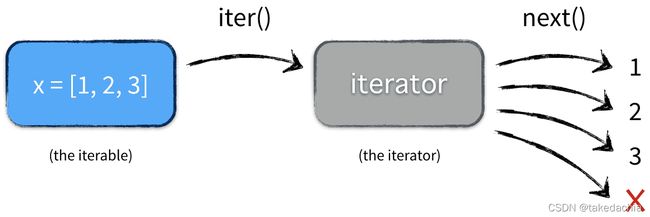
Pytorch的DataLoader()是一个 iterable
我们常用torch.utils.data.DataLoader读取数据,本质上是一个可迭代对象iterable。
我们引入Python的collections类来判断DataLoader的类型:
import torch.utils.data as Data
data_iter = Data.DataLoader(dataset, batch_size, shuffle=True)
from collections import Iterable, Iterator, Generator
print(isinstance(data_iter, Iterable))
print(isinstance(data_iter, Generator))
print(isinstance(data_iter, Iterator))
# 显示:
True
False
False
我们使用DataLoader()读取数据后,用next(iter(data_iter))来返回批量数据,而不能使用 next(data_iter),原理就在这儿。
使用迭代器来返回批量数据,可在大量数据情况下,实现小批量循环迭代式的读取,避免了内存不足的问题。
使用yield的函数定义是一个generator(生成器)
一开始的例子中,我们定义data_iter函数时使用了yield返回数据,这样定义的函数称为一个generator(生成器)。
生成器顾名思义就是用来生成迭代器用的。
扩展一下上上节的代码:
我们再定义一个generator,并判断是否属于 Iterator、Iterable、Generator
import sys
from collections import Iterable, Iterator, Generator
x = [x for x in range(100000)]
for item in x:
pass
x_iter = iter(x)
print(sys.getsizeof(x)) # 查看List的内存占用
print(sys.getsizeof(x_iter)) # 查看迭代器的内存占用
print(next(x_iter)) # 迭代器使用next 获得迭代对象
print(isinstance(x_iter, Iterable))
print(isinstance(x_iter, Generator))
print(isinstance(x_iter, Iterator))
# 显示:
824464
56
0
True
False
True
# 定义生成器generator
def show_x(x):
for item in x:
yield item
x_iter2 = show_x(x) # 实例化generator
print(next(x_iter2)) # 生成器可直接使用 next 获得迭代对象
print(sys.getsizeof(x_iter2)) # 查看生成器的内存占用
print(isinstance(x_iter2, Iterable))
print(isinstance(x_iter2, Generator))
print(isinstance(x_iter2, Iterator))
# 显示:
0
88
True
True
True
我们可以看到使用yield定义的函数是一个generator,它也有next的迭代方法用以批量读取数据。
关于生成器我们可以参考这张图:
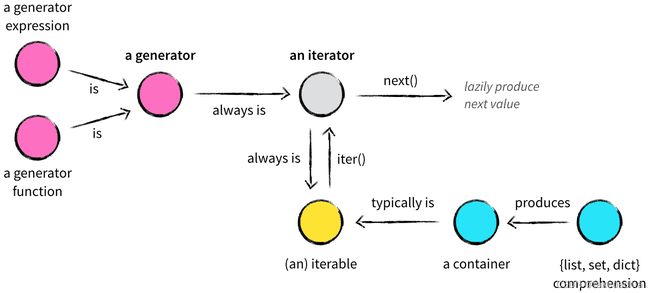
总结一下:
- generator生成器可以理解为一个普通函数,只是定义的时候使用了 yield 这一高级“return”;
- 生成器本身就是一个迭代器,是迭代器的高级封装,使用yield语句后可使代码逻辑非常清晰,方便我们使用迭代器。
- 生成器和迭代器一样,调用next方法获得 下一个yield/下一个元素 的内容
- 迭代完成后停止。
- 在大量数据情况下,实现小批量循环迭代式的读取,可避免内存不足的问题。
参考文献:
https://nvie.com/posts/iterators-vs-generators/