预训练技术在美团到店搜索广告中的应用
搜索广告在优化流量变现效率等商业指标之外,也需要重点优化用户体验,降低不相关广告对用户体验的损害,这样才能保证平台生态的健康发展。本文对预训练技术在广告相关性的落地方案进行了介绍,既包括训练样本上的数据增强、预训练及微调阶段的BERT模型优化等算法探索层面的工作,也包括知识蒸馏、相关性服务链路优化等实践经验。
引言
美团到店搜索广告负责美团、大众点评双平台站内搜索流量的商业变现,服务于到店餐饮、休娱亲子、丽人医美、酒店旅游等众多本地生活服务商家。在美团搜索场景中广告的展示样式非常原生,用户使用美团服务不会明显区分广告和自然结果,而广告用户体验损失则会显著影响搜索流量。因此,搜索广告除了优化流量变现效率等商业指标外,也需要重点优化用户体验,不断降低不相关广告对用户体验的损害,这样才能保证整个平台生态长期健康地发展。
在优化用户体验的目标下,如何正确的衡量用户体验,定义不相关广告是首要解决的问题。在搜索广告中,受结果列表页广告位置偏差、素材创意等因素影响,我们无法单一使用点击率(CTR)等客观性指标来衡量用户体验,尤其首位、首屏等排序靠前广告的相关性问题被认为是影响用户体验的主要因素。因此,我们首先建立了美团场景下的搜索广告相关性标准和评估体系,主要通过例行采样和人工评估的方式对搜索广告结果进行相关、一般和不相关的分档标注,进而驱动我们的广告相关性模型和策略迭代。然后,使用广告排序前五位的Badcase率(即Badcase@5)作为搜索广告的相关性评估指标。
问题与挑战
在定义出广告相关性问题和评估指标后,使用相关性模型进行搜索关键词(Query)和候选广告(Doc)的相关性打分,类似于NLP文本匹配任务,但实际建模中也发现若干困难。美团搜索结果以商户门店(POI)粒度展示,即Doc除了POI文本外,还包含一系列的团单或商品描述,内容非常丰富但也带来较多冗余或歧义,且不同业务的文本表达差异较大,比如结婚类商品“朱颜【出门出阁红色秀禾】,南国【中式婚礼嫁衣红色秀禾】”,给广告内容编码带来挑战。
其次,美团广告商户大多没有选择竞价关键词,且POI和团单标题并未面向搜索优化,Doc内容与Query可能存在文本表达偏差。比如“满月酒”和“嗨派星球宝宝宴·游轮派对,生日宴个性气球拱门”,需要处理这类信息缺失的问题。我们最初采用ESIM[1]交互式模型,但实践中发现该模型对我们复杂广告内容的表征能力有限,正负样本区分能力不足,在过滤不相关广告的同时对相关广告的误伤率较高。自2018年底以来,以BERT[2]为代表的预训练模型在多项NLP任务上都取得了突破,我们也开始探索预训练技术在搜索广告相关性上的应用。
业界及美团的解决方案
针对搜索语义匹配任务,Google[3]和Bing[4]的搜索团队已经基于BERT来编码Query和候选Doc,进而改善相关性的效果。预训练模型在美团内部的NLP场景中也有不少落地实践,美团搜索已经验证了预训练模型在文本相关性任务上的有效性[5]。
而针对预训练在语义匹配任务中的应用,业界也提出不少的解决方案。中科院计算所郭嘉丰等人提出PROP[6]和B-PROP[7]等针对搜索任务的预训练方法,主要思想是引入文档中代表词预测ROP(Representative wOrds Prediction)任务。纽约大学石溪分校曹庆庆等人提出DeFormer[8]分解预训练语言模型来做问答等语义匹配任务,在BERT的低层分别对问题和文档各自编码,再在高层部分拼接问题和文档的表征进行交互编码,让文档和问题在编码阶段尽可能地独立,从而提升模型的整体效率。百度刘璟等人提出RocketQA[9]和RocketQAv2[10]等面向端到端问答的检索模型训练方法,通过跨批次负采样、去噪的强负例采样以及数据增强技术大幅提升了双塔模型的效果。陈丹琦等人提出SimCSE[11],采用自监督来提升模型的句子表示能力,从而提升语义匹配的效果。
另一方面,2020年至今,预训练从“大炼模型”迈向了“炼大模型”的阶段,通过设计先进的算法,整合尽可能多的数据,汇聚大量算力,集约化地训练超大模型,持续提升模型效果。不论是公开论文结果还是美团内部实践,均已证明:更大规模的预训练模型能带来更好的下游任务效果。因此,美团广告平台与美团搜索与NLP部进行了合作,尝试利用预训练模型来优化搜索关键词和广告结果的相关性,进一步降低首屏广告Badcase,提升用户体验。
本文分为算法探索、应用实践和总结规划三个部分,对预训练技术在搜索广告相关性的落地方案进行介绍。在算法探索部分介绍了我们在训练样本上的数据增强、预训练(Pre-training)和微调(Fine-tuning)阶段的模型结构优化;在应用实践部分,本文介绍了以知识蒸馏为主的模型压缩方法、相关性服务链路优化方案,以及所取得的业务效果;最后,我们总结了相关性方面的优化方法,并对未来技术探索进行了展望。希望这些经验和思考能够给从事相关研究的同学带来一些帮助或启发。
算法探索
在美团搜索广告场景中,相关性计算可以看做用户搜索意图(Query)和广告商户(POI/Doc)之间的匹配问题,实践中我们采用了能够从多角度衡量匹配程度的集成方法,具体方案为分别基于Query和POI的结构化信息匹配、文本匹配和语义匹配等方法进行打分并且进行分数融合。其中,结构化信息匹配主要是对Query分析结果与POI进行类目、属性等信息的匹配;文本匹配方面借鉴了搜索引擎中的传统相关性方法,包括Query和POI的term共现数、Query term覆盖率、TF-IDF、BM25打分等;语义匹配包括传统的隐语义匹配(如基于LDA或者Word2Vec计算相似度)和深度语义匹配方法。在广告相关性服务中,我们采用学习能力更强的深度语义匹配模型。
深度语义匹配通常分为表示型和交互型两类:表示型模型一般基于双塔结构分别得到两段输入文本的向量表示,最后计算两段文本表示的相似度;该方法的优点是Doc向量可提前离线计算缓存,且匹配阶段计算速度很快,适合线上应用;缺点是只在模型最后阶段进行交互,对文本之间匹配关系学习不足。而交互型模型在初期即对两段输入文本进行交互,匹配阶段可以采用更复杂的网络结构,以学习文本间细粒度匹配关系;这种方法往往可以达到更高的精度,主要挑战在于线上应用的性能瓶颈。
美团搜索广告相关性服务的基线模型采用Transformer+ESIM的交互式模型结构,在满足性能的前提下有效解决了部分相关性问题,但是实际应用中仍然存在一些不足,主要包括:
-
训练数据中存在标签错误、正负样本分布不一致等问题;
-
Doc除了基础门店信息外还关联了大量商品和团单内容,如果直接将这些信息拼接成长文本作为Doc输入,由于模型结构限制往往需要对Doc文本进行截断,因而导致信息丢失;
-
基线模型对于长文本的表征能力有限,相关性判别能力不足,很难在控制变现效率影响的同时解决更多的Badcase。
为了解决这些问题,我们基于BERT在训练数据、特征构造和模型方面进行若干探索和实践。下文将逐一展开介绍。
数据增强
由于BERT模型微调阶段所需数据量相比ESIM模型更少,并且对数据覆盖全面度、标签准确度、数据分布合理性等因素更为敏感,在进行模型结构探索前,我们先按照如下思路产出一份可用性较高的数据。搜索广告涉及的业务众多且差异性大,包含的团单和商品种类多元,我们希望BERT的微调数据尽可能覆盖各个场景和主要服务。如果全部人工标注人力和时间成本较高,而用户点击转化行为能一定程度反映出广告是否相关,所以训练数据主要基于曝光点击日志构造,对于部分困难样本加以规则及人工校验。我们根据业务特性对训练数据的主要优化包括以下几点。
正样本置信加权
正样本主要通过点击数据得到,我们对4个月内的Query-POI点击数据进行统计,并且基于曝光频次和CTR进行数据清洗以减少噪声。实际采样流程中,假设对于某个Query需要取N个POI构造N条正样本,采样过程中令POI被采样的概率与其点击数成正比,这样做主要是基于点击越多相关性越高的认知,既可以进一步保证标签置信,又有利于模型学习到POI之间不同的相关程度。
在实验中我们也尝试了另外两个正样本采样方法:1) 对某个Query随机取N个POI,2) 对某个Query取点击最多的N个POI。实践发现方法1会采样到较多的弱相关样本,而方法2得到的大多为强相关样本,这两种方式均不利于模型拟合真实场景的数据分布。
负采样分层
我们按照模型学习的困难程度,从低到高设计了三种负样本采样方式:
-
全局随机负样本:大多为跨业务的负样本(比如烧烤和密室逃脱),模型学习最容易,可以有效识别跨类目的恶劣Badcase;
-
一级类目内负样本:Query和POI属于相同一级类目(比如美食、丽人等),但是属于不同细化类目(比如祛痘和医学美容),这部分样本可以为模型学习增加一定难度,提高模型判别能力;
-
三级类目内负样本:Query和POI属于相同的细化类目,但是POI并不提供Query相关的服务(比如光子嫩肤和水光针商户),这部分属于困难负样本,可以提升模型对语义相近但服务不相关的Badcase的判别能力,更大程度保障用户体验;但是在三级类目下采样可能取到较多相关样本,所以这部分样本还需要经过基于服务核心词的规则过滤以及人工校验。
采样平滑及分布一致性
-
采样平滑:在正样本构建过程中对Query采样频次做了平滑,避免高频Query采样过多,导致模型忽略对中长尾Query样本的学习。
-
样本分布一致性:在负样本构建中,对于每种负样本均需要保证各Query出现概率与其在正样本中概率相等,避免样本分布不一致性导致模型学习有偏。
文本关键词提取
美团搜索广告场景下,Query中可能包含地址词、品牌词、服务核心词等多种成分,Query文本一般较短,90%以上的Query长度小于10;POI的主要文本特征包括门店名称和商品信息,而广告主的商品数量普遍较多,直接拼接商品标题会导致POI文本过长,有26%的POI文本长度超过240。
由于相关性模型的主要目标是学习Query和POI之间的服务相关性,大量冗余文本信息会影响模型性能和学习效果,我们对Query和POI文本进行如下处理以提取关键文本信息:
-
对于Query文本:基于命名实体识别(NER)和词权重结果过滤掉地址词、分店名等成分,保留服务核心词;
-
对于POI文本:对所有商品标题进行关键词抽取,得到一组能反映商户核心服务的关键词,将其拼接作为POI文本。相比直接拼接原始商品文本,长度大幅下降,仅有5%的POI长度超过240,并且POI文本质量更高,模型学习效果更好。
最终,我们的微调样本包括约50万条数据,涵盖餐饮、休娱、亲子和丽人等20个主要类目,其中正负样本比例为1:5,三种负样本比例为2:2:1。
模型优化
基于多任务学习的多业务模型
由于美团搜索广告涉及餐饮、休娱亲子、丽人医美等大量业务场景,并且不同场景之间差异较大。从过去的实践经验可知,对于某个业务场景下的相关性优化,利用该业务数据训练的子模型相比利用全业务数据训练的通用模型往往效果更佳,但这种方法存在几个问题:1) 多个子模型的维护和迭代成本更高;2) 某些小场景由于训练数据稀疏难以正确学习到文本表示。
受到多业务子模型优缺点的启发,我们尝试了区分业务场景的多任务学习,利用BERT作为共享层学习各个业务的通用特征表达,采用对应不同业务的多个分类器处理BERT输出的中间结果,实际应用中根据多个小场景的业务相似程度划分成N类,亦对应N个分类器,每个样本只经过其对应的分类器。多业务模型的主要优势在于,能够利用所有数据进行全场景联合训练,同时一定程度上保留每个场景的特性,从而解决多业务场景下的相关性问题,模型结构如下图1所示:
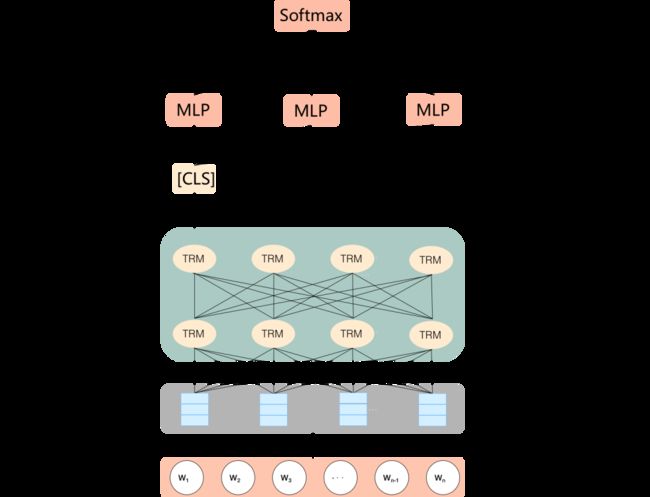
图1 多业务模型结构
引入品类信息的预训练
由于美团商户POI和商品标题可能缺乏有效信息表达,有时仅根据Query和POI商品文本很难准确判断两者之间的语义相关性。例如【租车公司,<上水超跑俱乐部;宝马,奥迪>】,Query和POI文本的相关性不高,而该商户的三级品类是“养车-用车租车-租车”,我们认为引入品类信息有助于提高模型效果。
为了更合理的引入品类信息,我们对BERT模型的输入编码部分进行改造,除了与原始BERT一致的Query、Doc两个片段外,还引入了品类文本作为第三个片段,将品类文本作为额外片段的作用是防止品类信息对Query、Doc产生交叉干扰,使模型对于POI文本和品类文本区别学习。
下图2为模型输入示意图,其中红色框内为品类片段的编码情况,Ec为品类片段的片段编码(Segment Embedding)。由于我们改变了BERT输入部分的结构,无法直接基于标准BERT进行相关性微调任务。我们对BERT重新进行预训练,并对预训练方式做了改进,将BERT预训练中用到的NSP(Next Sentence Prediction)任务替换为更适合搜索广告场景的点击预测任务,具体为“给定用户的搜索关键词、商户文本和商户品类信息,判断用户是否点击”。预训练数据采用自然及广告搜索曝光点击数据,大约6千万样本。

模型优化离线效果
为了清晰准确地反映模型迭代的离线效果,我们通过人工标注的方法构建了一份广告相关性任务Benchmark。基线ESIM模型、BERT模型以及本文提到的优化后BERT模型在Benchmark上的评估指标如下表1所示:
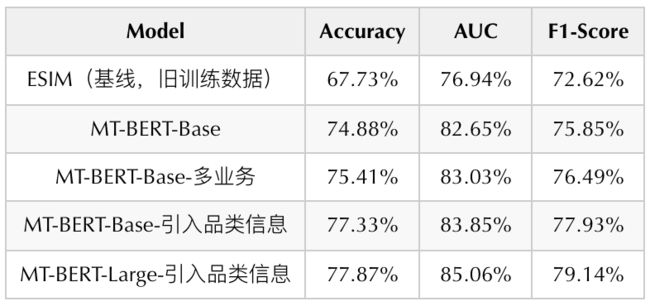
表1 广告相关性任务模型优化迭代指标
我们首先利用上文介绍的数据增强后的训练样本训练了MT-BERT-Base模型(12层768维),与ESIM模型相比,各项指标均显著提升,其中AUC提升6.6PP。在BERT模型优化方面,多任务学习和引入品类信息这两种方式均能进一步提升模型效果,其中引入品类信息的MT-BERT-Base模型效果更佳,相比标准的MT-BERT-Base模型AUC提升1.2PP。
在BERT模型规模方面,实验发现随着其规模增长,模型效果持续提升,但是预训练和部署成本也相应增长,最终我们选取了大约3亿参数量的MT-BERT-Large模型(24层1024维),在同样引入品类信息的条件下,相比MT-BERT-Base模型AUC增长1.21PP,相比ESIM模型AUC增长8.12PP。
应用实践
在模型的实践落地过程中,我们也遇到若干挑战,并且针对性的设计了优化方案。第一个挑战是BERT模型的前向耗时无法满足线上性能要求,我们通过知识蒸馏和低精度量化方法对模型进行压缩,并且采用离线缓存与实时预测结合的方式进一步提升了服务性能。
另一个挑战是,在广告业务场景下,需要综合考虑平台变现效率、用户体验、商户供给及转化等因素,如何使相关性分数在广告整体链路中发挥出更好的作用。我们目前采用了低质量广告过滤、重排阶段考虑相关性因子以及TOP位次广告门槛控制等策略。下文对应用实践方面的具体方案进行介绍。
模型压缩
由于BERT模型的庞大参数量和前向预测耗时,直接部署上线会面临很大的性能挑战,通常需要将训练好的模型压缩为符合一定要求的小模型,业内常用模型压缩方案包括模型裁剪、低精度量化和知识蒸馏等。知识蒸馏[12]旨在有效地从大模型(教师模型)中迁移知识到小模型(学生模型)中,在业内得到了广泛的研究和应用,如HuggingFace提出的DistillBERT[13]和华为提出的TinyBERT[14]等蒸馏方法,均在保证效果的前提下大幅提升了模型性能。
经过在搜索等业务上的探索和迭代,美团NLP团队沉淀了一套基于两阶段知识蒸馏的模型压缩方案,包括通用型知识蒸馏和任务型知识蒸馏,具体过程如下图3所示。在通用型知识蒸馏阶段,使用规模更大的预训练BERT模型作为教师模型,对学生模型在无监督预训练语料上进行通用知识蒸馏,得到通用轻量模型,该模型可用于初始化任务型知识蒸馏里的学生模型或直接对下游任务进行微调。在任务型知识蒸馏阶段,使用在有监督业务语料上微调的BERT模型作为教师模型,对学生模型在业务语料上进行领域知识蒸馏,得到最终的任务轻量模型,用于下游任务。实验证明,这两个阶段对于模型最终效果的提升都至关重要。
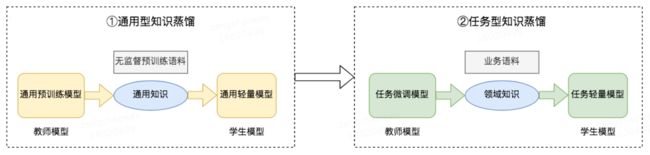 图3 两阶段知识蒸馏
图3 两阶段知识蒸馏
在美团搜索广告场景下,首先我们基于MT-BERT-Large(24层1024维)在大规模无监督广告语料上进行第一阶段通用型知识蒸馏,得到MT-BERT-Medium(6层384维)通用轻量模型,在下游的广告相关性任务上进行微调。MT-BERT-Medium属于单塔交互结构,如图4(a)所示。
目前,每个Query请求会召回上百个POI候选,交互模型需要分别对上百个Query-POI对进行实时推理,复杂度较高,很难满足上线条件。常见解决方案是将交互模型改造成如图4(b)所示的双塔结构,即分别对Query和POI编码后计算相似度。由于大量候选POI编码可以离线完成,线上只需对Query短文本实时编码,使用双塔结构后模型效率大幅提升。我们使用通用型蒸馏得到的MT-BERT-Medium模型对双塔模型中Query和POI的编码网络进行初始化,并且在双塔在微调阶段始终共享参数,因此本文将双塔模型记为Siamese-MT-BERT-Medium(每个塔为6层384维)。双塔结构虽然带来效率的提升,但由于Query和POI的编码完全独立,缺少上下文交互,模型效果会有很大损失,如表2所示,Siamese-MT-BERT-Medium双塔模型相比MT-BERT-Medium交互模型在相关性Benchmark上各项指标都明显下降。
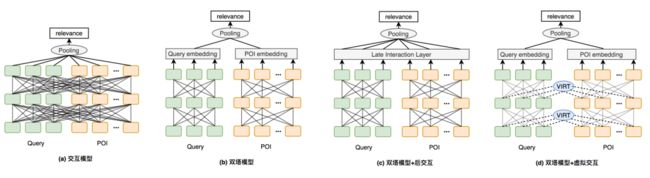
图4 相关性模型结构对比
为了充分结合交互结构效果好和双塔结构效率高的优势,Facebook Poly-encoder[15]、斯坦福大学ColBERT[16]等工作在双塔结构的基础上引入不同复杂程度的后交互层(Late Interaction Layer)以提升模型效果,如图4(c)所示。后交互网络能提升双塔模型效果,但也引入了更多的计算量,在高QPS场景仍然很难满足上线要求。针对上述问题,在第二阶段任务型知识蒸馏过程中,我们提出了虚拟交互机制(Virtual InteRacTion mechanism, VIRT),如图4(d)所示,通过在双塔结构中引入虚拟交互信息,将交互模型中的知识迁移到双塔模型中,从而在保持双塔模型性能的同时提升模型效果。
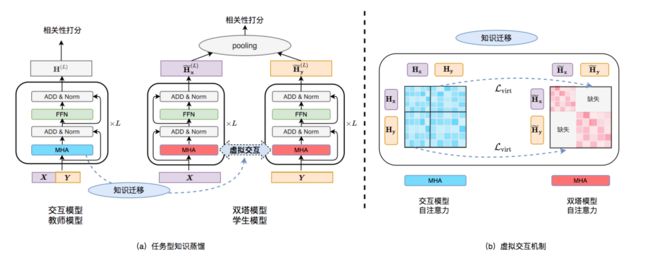 图5 任务型知识蒸馏&虚拟交互
图5 任务型知识蒸馏&虚拟交互
任务型知识蒸馏及虚拟交互的具体过程如上图5所示。在任务型知识蒸馏阶段,我们首先基于MT-BERT-Large交互模型在业务语料上进行微调得到教师模型。由于学生模型Siamese-MT-BERT-Medium缺乏上下文交互,如图5(b)所示,注意力矩阵中的灰色部分代表了2块缺失的交互信息,我们通过虚拟交互机制对缺失部分进行模拟,计算公式如下为:
其中,和分别代表双塔模型中Query和POI表示,和分别是Query和POI进行编码时的模型参数, 代表了到的注意力(即图5(b)右上角缺失部分), 代表了到的注意力(即图5(b)左下角缺失部分)。而交互模型包含了Query和POI的全交互,计算公式为:
其中,是交互模型中Query和POI的融合表示,可以分解为和,分别代表Query和POI,是模型参数。交互模型的自注意力矩阵可以分解为4个部分,其中和则是Query和POI之间的交互,也即双塔模型的缺失部分。我们对交互模型的交互矩阵和双塔模型的虚拟交互矩阵之间的L2距离进行最小化,从而将交互模型中的核心交互知识迁移到双塔模型中,计算过程为:
我们对蒸馏阶段各个模型进行了Benchmark上的效果评估以及线上QPS=50时的性能测试,结果如表2所示。通过虚拟交互进行任务型知识蒸馏得到的任务轻量模型Siamese-MT-BERT-Medium相较于直接对通用轻量模型进行微调得到的同结构的Siamese-MT-BERT-Medium(W/O任务型知识蒸馏)模型,各项效果指标明显提升,其中Accuracy提升1.18PP,AUC提升1.66PP,F1-Score提升1.54PP。最终我们对任务轻量模型Siamese-MT-BERT-Medium进行上线,相较于最初的MT-BERT-Large模型,线上推理速度提升56倍,完全满足线上服务的性能要求。
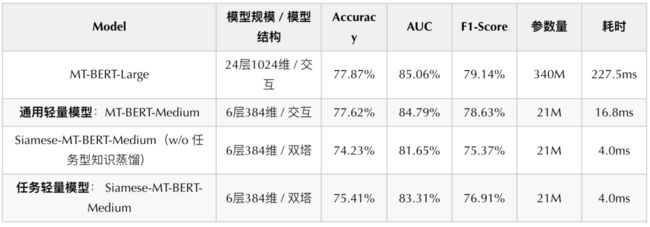
表2 模型效果对比
相关性服务链路优化
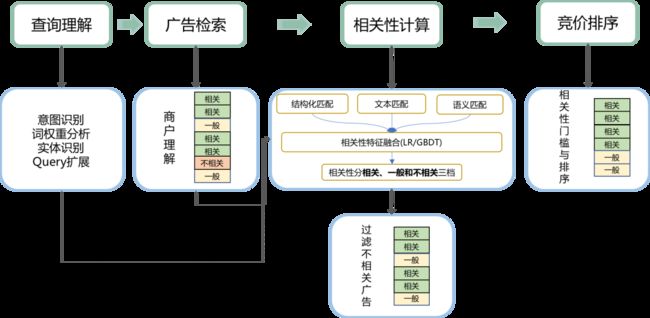
相关性计算
为了更好地衡量广告召回结果的相关程度,除了基于模型得出的语义相关性之外,我们还计算了文本相关性、类目相关性等分数,并对所有分数进行融合得到最终的相关性分数。其中,文本相关性的计算借鉴了搜索引擎场景的检索相关性方法,例如Query和POI的字符串包含关系、短语匹配数和匹配率、以及BM25分等。
另外,文本匹配同时考虑了原串匹配、核心词匹配及同义词匹配等多维度指标;类目相关性主要基于Query意图分类和商户类目信息进行匹配。分数融合模型可以选择LR或者GBDT等复杂度比较低的模型,并基于高质量标注数据集训练得到。
相关性应用
通过模型结构和分数融合策略的迭代优化可以得到更加准确合理的相关性分数,但是在实际的相关性应用中,还需要紧密结合广告业务场景,综合考虑平台变现效率、用户体验、广告主供给及转化等多方面因素。基于“减少低质量的不相关广告”和“相关广告排序应该尽量靠前”两个基本要求,我们设计了几种相关性分数的具体应用方式:
-
过滤低质量广告:完全不相关的广告无疑会严重影响用户体验,需要进行过滤。考虑到不同召回策略和不同业务流量在变现效率及Badcase严重程度等方面存在差异,过滤阈值被设计成召回策略×类目的二维超参矩阵;
-
重排序参考相关性:在广告系统的竞价排序模块,在考虑点击率、转化率、交易额和出价等因素的同时,也需要考虑相关性分数;
-
TOP位次相关性门槛:首位、首屏等排序靠前的广告结果对于用户体验影响更大,因此针对TOP位次设置了相关性门槛,进一步改善用户体验。
模型部署
为了进一步提升服务性能并且能有效利用计算资源,模型部署阶段我们采用高频流量缓存、长尾流量实时计算的方案。对高频Query-POI对进行离线相关性计算并写入缓存,每日对新增或商品信息变化的Query-POI对进行增量计算并更新缓存,线上相关性服务优先取缓存数据,如果失效则基于蒸馏后的任务轻量模型进行实时计算。对于输入相关性服务的Query-POI对,缓存数据的覆盖率达到90%以上,有效缓解了在线计算的性能压力。
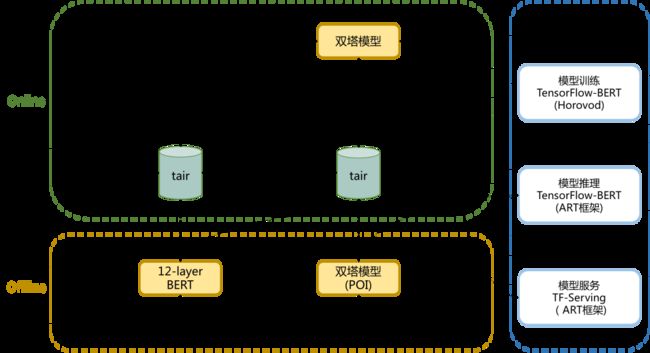 图7 相关性分数离线/在线计算流程图
图7 相关性分数离线/在线计算流程图
线上实时计算的任务轻量模型使用TF-Serving进行部署,TF-Serving预测引擎支持使用美团机器学习平台的模型优化工具—ART框架(基于Faster-Transformer改进)进行加速,在将模型转为FP16精度后,最终加速比可达到5.5,数值平均误差仅为5e-4,在保证精度的同时极大地提高了模型预测的效率。
线上效果
为了更加直接客观地反映线上广告相关性情况,我们建立了美团场景下的搜索广告相关性标准和评估体系,对搜索关键词和广告结果进行相关、一般和不相关的分档标注,采用排序前五位广告的Badcase率(即Badcase@5)作为搜索广告的相关性评估核心指标。
除此之外,由于CTR能够通过用户行为间接反映广告的相关程度,并且便于在线上进行AB实验评估,而NDCG可以反映相关性分数用于广告列表排序的准确性,所以我们选取CTR和NDCG作为间接指标来辅助验证相关性模型迭代的有效性。我们对本文的优化进行了线上小流量实验,结果显示,实验组CTR提升1.0%,覆盖率降低1.0%,变现效率基本没有损失。并且经过人工评测,Badcase@5降低2.2PP,NDCG提升2.0PP,说明优化后的相关性模型能够对召回广告列表进行更加准确的校验,有效提升了广告相关性,从而给用户带来更好的搜索体验。
下面列举了两个Badcase解决示例,图8(a)和8(b)分别包含了搜索“登记照”和“头皮SPA”时的基线返回结果(左侧截图)和实验组返回结果(右侧截图),截图第一位是广告结果。在这两个示例中,实验组相关性模型将不相关结果“麻朵新生儿摄影”和“莲琪科技美肤抗衰中心”检测出来并过滤掉,让相关广告得以首位展示曝光。
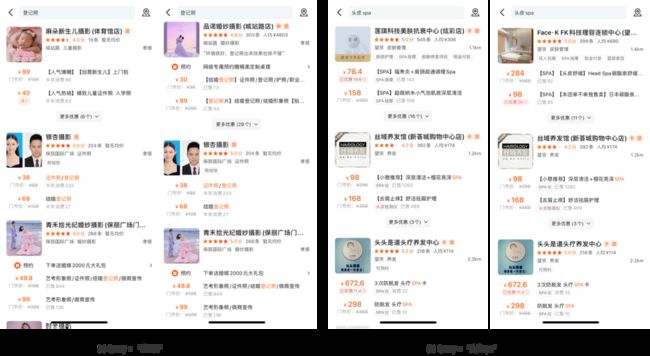 图8 Badcase解决示例
图8 Badcase解决示例
总结与展望
本文介绍了预训练技术在美团到店搜索广告相关性上的应用,主要包括样本数据增强、模型结构优化、模型轻量化及线上部署等优化方案。在数据增强方面,为了基于曝光点击数据构造出适合美团广告场景下相关性任务的训练数据,我们构造了多种类型负样本,在采样时考虑正样本置信度、关键词频率平滑、正负样本均衡等因素,另外也对POI和团单商品文本进行关键词抽取得到更加简短有效的文本特征。
在模型结构优化方面,我们尝试了对不同业务场景做多任务学习,以及在BERT输入中引入品类文本片段这两种方案使模型更好地拟合美团搜索广告业务数据,并利用规模更大的预训练模型进一步提升了模型的表达能力。
在实践应用中,为了同时满足模型效果和线上性能要求,我们对中高频流量进行离线打分和缓存,并且利用MT-BERT-Large蒸馏得到的双塔模型进行线上实时预测以覆盖长尾流量。最终,在保证广告平台收入的前提下,有效降低了搜索广告Badcase率,提升了用户在平台的搜索体验。
目前,广告相关性打分主要应用于阈值门槛,目的是端到端的过滤掉不相关广告,从而快速降低广告Badcase。在此基础上,我们期望相关性模型继续提升区分相关和一般相关广告的能力,从而在重排序中作为排序因子更好的平衡变现效率和用户体验指标,更准确的度量用户体验损失和变现效率提升的兑换关系。此外,在本地搜索类场景下,局部供给经常比较匮乏,实际召回效果对比全局供给的情况更依赖相关性打分的能力,所以我们依然需要在相关性模型上持续深入迭代,并支撑广告召回模型和策略的进一步优化。
在具体技术方向上,相关性门槛阈值设置、广告长文本表达和业务知识融合等方面依然存在优化和提升空间:
-
阈值搜索:目前的阈值策略需要对每个类目分别调参,缺乏整体性且难以达到全局优化效果。我们正在实验将阈值搜索看作可变现流量上的最优化问题,在限定消耗损失及其他业务约束的条件下,找到一组门槛阈值使得整体Badcase解决最大化,并已经取得初步的效果。
-
特征表达:目前广告Doc特征主要采用团单商品标题的关键词抽取结果,但是Doc文本仍然较长并且存在一些冗余信息,有必要对Doc信息抽取方法继续探索,比如融合外部知识进行信息抽取,或者通过优化Transformer注意力机制使模型在相关性打分时更加关注某些重要词项或者行业相关的关键词。
-
联合优化:Query和POI文本中的蕴含的类目信息、实体成分等对于判断相关性很有帮助,我们计划将相关性任务与搜索广告场景下其他任务联合优化,比如命名实体识别、Query类目识别等,期望通过引入辅助任务增强模型的学习能力,更全面准确的学习语义相关性。
参考资料
[1] Chen, Qian, et al. "Enhanced lstm for natural language inference." arXiv preprint arXiv:1609.06038 (2016).
[2] Devlin, Jacob, et al. "BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding." arXiv preprint arXiv: 1810.04805 (2018).
[3] Pandu Nayak, "Understanding searches better than ever before." Google blog (2019).
[4] Wenhao Lu, et al. "TwinBERT: Distilling Knowledge to Twin-Structured BERT Models for Efficient Retrieval." arXiv preprint arXiv: 2002.06275 (2020).
[5] 李勇, 佳昊, 杨扬等. BERT在美团搜索核心排序的探索和实践.
[6] Ma, Xinyu, et al. "PROP: Pre-training with Representative Words Prediction for Ad-hoc Retrieval." Proceedings of the 14th ACM International Conference on Web Search and Data Mining (2021).
[7] Ma, Xinyu, et al. "B-PROP: Bootstrapped Pre-training with Representative Words Prediction for Ad-hoc Retrieval." arXiv preprint arXiv: 2104.09791 (2021).
[8] Cao, Qingqing, et al. "DeFormer: Decomposing Pre-trained Transformers for Faster Question Answering." arXiv preprint arXiv:2005.00697 (2020).
[9] Qu, Yingqi, et al. "RocketQA: An Optimized Training Approach to Dense Passage Retrieval for Open-Domain Question Answering." arXiv preprint arXiv: 2010.08191 (2021).
[10] Ren, Ruiyang, et al. "RocketQAv2: A Joint Training Method for Dense Passage Retrieval and Passage Re-ranking." arXiv preprint arXiv: 2110.07367 (2021).
[11] Gao, Tianyu, et al. "SimCSE: Simple Contrastive Learning of Sentence Embeddings." arXiv preprint arXiv: 2104.08821 (2021).
[12] Hinton, Geoffrey, Oriol Vinyals, and Jeff Dean. "Distilling the knowledge in a neural network." arXiv preprint arXiv:1503.02531 (2015).
[13] Sanh, Victor, et al. "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter." arXiv preprint arXiv:1910.01108 (2019).
[14] Jiao, Xiaoqi, et al. "Tinybert: Distilling bert for natural language understanding." arXiv preprint arXiv:1909.10351 (2019).
[15] Humeau, Samuel, et al. "Poly-encoders: Transformer architectures and pre-training strategies for fast and accurate multi-sentence scoring." arXiv preprint arXiv:1905.01969 (2019).
[16] Khattab, Omar, and Matei Zaharia. "Colbert: Efficient and effective passage search via contextualized late interaction over bert." Proceedings of the 43rd International ACM SIGIR conference on research and development in Information Retrieval. (2020).
作者简介
-
邵雯、春喜、晓俊、程佳、雷军等,来自美团广告平台技术部。
-
杨扬、任磊、金刚、武威等,来自美团平台/搜索与NLP部。
---------- END ----------
招聘信息
美团到店广告平台广告算法团队立足广告场景,探索深度学习、强化学习、人工智能、大数据、知识图谱、NLP和计算机视觉前沿的技术发展,探索本地生活服务电商的价值。主要工作方向包括:
| 触发策略:用户意图识别、广告商家数据理解,Query改写,深度匹配,相关性建模。
| 质量预估:广告质量度建模。点击率、转化率、客单价、交易额预估。
| 机制设计:广告排序机制、竞价机制、出价建议、流量预估、预算分配。
| 创意优化:智能创意设计。广告图片、文字、团单、优惠信息等展示创意的优化。
岗位要求
| 有三年以上相关工作经验,对CTR/CVR预估、NLP、图像理解,机制设计至少一方面有应用经验。
| 熟悉常用的机器学习、深度学习、强化学习模型。
| 具有优秀的逻辑思维能力,对解决挑战性问题充满热情,对数据敏感,善于分析/解决问题。
| 计算机、数学相关专业硕士及以上学历。
具备以下条件优先:
| 有广告/搜索/推荐等相关业务经验。
| 有大规模机器学习相关经验。
感兴趣的同学可投递简历至:[email protected](邮件标题请注明:美团广平算法团队)。
美团科研合作
美团科研合作致力于搭建美团各部门与高校、科研机构、智库的合作桥梁和平台,依托美团丰富的业务场景、数据资源和真实的产业问题,开放创新,汇聚向上的力量,围绕人工智能、大数据、物联网、无人驾驶、运筹优化、数字经济、公共事务等领域,共同探索前沿科技和产业焦点宏观问题,促进产学研合作交流和成果转化,推动优秀人才培养。面向未来,我们期待能与更多高校和科研院所的老师和同学们进行合作。欢迎老师和同学们发送邮件至:[email protected] 。
也许你还想看
| 美团BERT的探索和实践
| Transformer 在美团搜索排序中的实践
| 常识性概念图谱建设以及在美团场景中的应用
阅读更多
---
前端 | 算法 | 后端 | 数据
安全 | Android | iOS | 运维 | 测试