Python基于修正余弦相似度的电影推荐引擎
数据集下载地址:MovieLens 最新数据集
数据集包含600 名用户对 9,000 部电影应用了 100,000 个评级和 3,600 个标签应用程序,下载ml-latest-small.zip文件。本文只使用里面的ratings和movies两个.csv文件。
一、推荐引擎
推荐引擎在互联网上的应用非常广泛,在网上购物时,电商平台会根据用户的个人信息和浏览信息为其推荐可能需要的产品;使用抖音、快手、bilibili等视频软件时,系统也会根据用户喜好为其推荐相应的视频内容。
从模型的角度来看,这些推荐行为其实对应着一个分类问题。
(1)站在用户的角度,推荐系统将所有物品分为两类,一类是这个用户感兴趣的,另一类是这个用户不感兴趣的。
(2)反过来,站在物品的角度,推荐系统将用户分为两类,对该物品感兴趣的和对该物品不感兴趣的。
推荐引擎(Recommendation Engine, RE)是主动发现用户当前或潜在需求的定律,并主动推送信息给用户的信息网络。挖掘用户的喜好和需求,主动向用户推荐其感兴趣或者需要的对象。推荐引擎不是被动查找,而是主动推送。
二、推荐引擎的方法
方法主要有基于用户统计学的推荐、基于内容的推荐、基于协同滤波的推荐以及混合推荐机制。这里只介绍基于协同滤波的推荐。
基于协同滤波的推荐:其原理是根据用户对物品或者信息的偏好,发现物品或者内容本身的相关性,或者是发现用户的相关性,然后再基于这些关联性进行推荐。基于协同过滤的推荐可以分为三个子类:基于用户的推荐,基于项目的推荐和基于模型的推荐。
(1)基于用户协同滤波的推荐:其原理是根据所有用户对物品或者信息的偏好,发现与当前用户口味和偏好相似的“邻居”用户群,在一般的应用中是采用计算“K- 邻居”的算法;然后,基于这 K 个邻居的历史偏好信息,为当前用户进行推荐。
(2)基于项目的协同滤波推荐:其原理与基于用户协同滤波的推荐类似,只是它使用所有用户对物品或者信息的偏好,发现物品和物品之间的相似度,然后根据用户的历史偏好信息,将类似的物品推荐给用户。
(3)基于模型的协同过滤推荐:其原理是基于样本的用户喜好信息,训练一个推荐模型,然后根据实时的用户喜好的信息进行预测,计算推荐。
本文将使用基于用户协同滤波的推荐,寻找相似用户,进行电影推荐。下面再介绍下计算用户与用户之间相似度的方法。
三、测量方法
测量方法主要有余弦相似度、基于欧氏距离的相似度、皮尔逊相关系数、修正余弦相似度。
先说余弦相似度,因为还不会插入公式,请看下图。
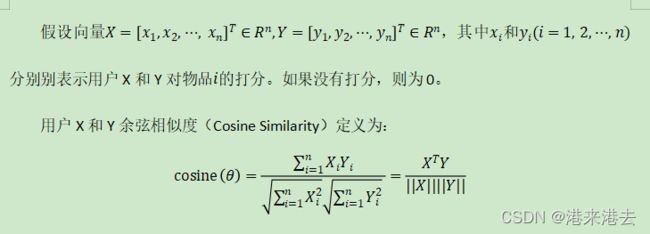
那么在Python里怎么实现呢,scipy里已经有了现成的函数,只需导入就好。
Examples
--------
>>> from scipy.spatial import distance
>>> distance.cosine([1, 0, 0], [0, 1, 0])
1.0
>>> distance.cosine([100, 0, 0], [0, 1, 0])
1.0
>>> distance.cosine([1, 1, 0], [0, 1, 0])
0.29289321881345254
最后,是修正余弦相似度

四、实战
前面啰嗦一大堆都是做理论铺垫,现在进入实战。首先打开数据集大概看看,个人认为熟悉自己的数据集是非常重要的。
这是movies.csv文件,共9742条,是有关电影的信息。

这是ratings.csv文件,共100836条,是用户的打分信息。

为了方便处理,现在把这两张表整合在一起。
import pandas as pd
path1='/content/drive/MyDrive/Colab Notebooks/ratings.csv'
path2='/content/drive/MyDrive/Colab Notebooks/movies.csv'
ratings=pd.read_csv(path1)
movies=pd.read_csv(path2)
ratings = pd.merge(ratings[['userId', 'movieId', 'rating']], movies[['movieId', 'title']],
how = 'left', left_on = 'movieId', right_on = 'movieId')
path3 = '/content/drive/MyDrive/Colab Notebooks/ratings_new.csv'
data = ratings[['userId','movieId', 'rating', 'title']].sort_values('userId')
data.to_csv(path3, index = False)
整合以后,我们以用户id进行排序,显示其评过分的电影id、电影名称,如图。
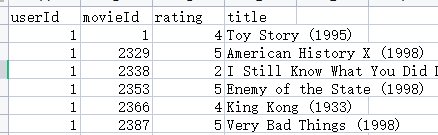
然后用整合后的新表构建一个透视表pivot_table,以用户userId为index,以movieId为columns,以电影评分rating为values。再转为ndarray类型,方便计算。
rp = ratings.pivot_table(columns = ['movieId'], index = ['userId'], values = 'rating')
rp = rp.fillna(0) #没打过分的电影置零分
print(rp.shape)#610*9724
rp_mat = np.matrix(rp)
print(rp_mat.shape) #610*9724,ndarray类型
置零是必要的,因为有的用户打过分的电影很少,有的用户打过分的电影很多。比如某电影A,用户B打过分,用户C没打过分,但也要统计用户C对电影A的打分情况,那么这一项就置零。现在来计算用户与用户之间的修正余弦相似度。
m, n = rp.shape
mat_users = np.zeros((m, m))#二维数组,610*610
print(mat_users.shape)
#用户相似度矩阵(1-修正余弦相似度=修正余弦距离)
for i in range(m):
for j in range(m):
if i != j:
mat_users[i][j] = (1-cosine(rp_mat[i,:]-np.mean(rp_mat[:,j]), rp_mat[j,:]-np.mean(rp_mat[:,j])))
else:
mat_users[i][j] = 0
#得到的矩阵构建dataframe
pd_users = pd.DataFrame(mat_users, index = rp.index, columns = rp.index)
说明一下,rp_mat[i,:]和rp_mat[j,:]是第i和第j个用户的电影评分;np.mean(rp_mat[:,j])就是所有用户对某电影的平均评分,计算时减去它,就能得到修正余弦相似度;而1-修正余弦相似度=修正余弦距离,所以最后得到的相似矩阵,是用户与用户间的修正余弦距离,值越大说明越相似。
进入推荐阶段,定义一个寻找最相似用户的函数。
def topn_simusers(uid, n):
users = pd_users.loc[uid,:].sort_values(ascending = False)
topn_users = users.iloc[:n,]
topn_users = topn_users.rename('score')
print("Similar users as user:", uid)
return pd.DataFrame(topn_users)
假设要给用户id为17的人找十个最相似的用户。
#十个最相似用户
top_sim_users = topn_simusers(uid = 17, n = 10)
print(top_sim_users)
得到结果如下,可见和用户id=17的最相似用户是id=278的用户。
Similar users as user: 17
score
userId
278 0.979909
258 0.977053
315 0.976991
511 0.966432
508 0.953777
225 0.953478
399 0.948358
98 0.940472
124 0.938946
44 0.934057
再定义一个函数输出某用户打分最高的几部电影
#某用户打分最高的几部电影
def topn_movieratings(uid, n_ratings):
uid_ratings = ratings.loc[ratings['userId'] == uid]
uid_ratings = uid_ratings.sort_values(by = 'rating', ascending = [False])
print ("Top", n_ratings, "movie ratings of user:", uid)
return uid_ratings.iloc[:n_ratings,]
看看用户17打分最高的10部电影和用户278打分最高的20部电影
top_movie_ratings1 = topn_movieratings(uid = 17, n_ratings = 10)
print(top_movie_ratings1)
n_ratings = 20
uid = 278
top_movie_ratings2 = topn_movieratings(uid, n_ratings)
print(top_movie_ratings2)
输出:
Top 10 movie ratings of user: 17
userId ... title
1699 17 ... Star Wars: Episode V - The Empire Strikes Back...
1676 17 ... Pulp Fiction (1994)
1748 17 ... Lord of the Rings: The Two Towers, The (2002)
1746 17 ... Spirited Away (Sen to Chihiro no kamikakushi) ...
1753 17 ... Nausicaä of the Valley of the Wind (Kaze no ta...
1722 17 ... Big Lebowski, The (1998)
1678 17 ... Forrest Gump (1994)
1688 17 ... Godfather, The (1972)
1677 17 ... Shawshank Redemption, The (1994)
1674 17 ... Star Wars: Episode IV - A New Hope (1977)
[10 rows x 4 columns]
Top 20 movie ratings of user: 278
userId ... title
41047 278 ... Usual Suspects, The (1995)
41050 278 ... Schindler's List (1993)
41053 278 ... Ice Storm, The (1997)
41066 278 ... Simpsons Movie, The (2007)
41049 278 ... Shawshank Redemption, The (1994)
41056 278 ... Big Chill, The (1983)
41059 278 ... Thin Red Line, The (1998)
41060 278 ... Awakenings (1990)
41048 278 ... To Wong Foo, Thanks for Everything! Julie Newm...
41061 278 ... Cider House Rules, The (1999)
41062 278 ... Fast Times at Ridgemont High (1982)
41064 278 ... Planes, Trains & Automobiles (1987)
41051 278 ... Island of Dr. Moreau, The (1996)
41055 278 ... Sixteen Candles (1984)
41052 278 ... Nightmare on Elm Street, A (1984)
41058 278 ... Fletch (1985)
41063 278 ... Muppet Movie, The (1979)
41065 278 ... City Slickers (1991)
41057 278 ... Desperately Seeking Susan (1985)
41054 278 ... Jerk, The (1979)
[20 rows x 4 columns]
最后,从用户278打分最高的20部电影中挑选其中用户17未看过的电影(也就是没有打过分的电影)为其推荐。
recommend_movies = [] # 推荐电影,基于用户-用户相似度
for i in range(n_ratings):
rt = top_movie_ratings2['movieId'].iloc[i]
movie_title = top_movie_ratings2['title'].iloc[i]
if uid_ratings1.loc[uid_ratings1.movieId == rt].rating.values.size == 0:
recommend_movies.append(movie_title)
print('Recommended movies for the user 17 is:', recommend_movies)
输出:
Recommended movies for the user 17 is: ['Ice Storm, The (1997)', 'Simpsons Movie, The (2007)',
'Big Chill, The (1983)', 'Thin Red Line, The (1998)', 'Awakenings (1990)',
'To Wong Foo, Thanks for Everything! Julie Newmar (1995)', 'Cider House Rules, The (1999)',
'Fast Times at Ridgemont High (1982)', 'Planes, Trains & Automobiles (1987)',
'Island of Dr. Moreau, The (1996)', 'Sixteen Candles (1984)',
'Nightmare on Elm Street, A (1984)', 'Fletch (1985)','Muppet Movie, The (1979)',
'City Slickers (1991)', 'Desperately Seeking Susan (1985)', 'Jerk, The (1979)']
本篇文章到此结束了,如果有错欢迎指正,赐教。
完整代码:
import pandas as pd
import numpy as np
from scipy.spatial.distance import cosine
path1='/content/drive/MyDrive/Colab Notebooks/ratings.csv'
path2='/content/drive/MyDrive/Colab Notebooks/movies.csv'
ratings=pd.read_csv(path1)
movies=pd.read_csv(path2)
print(ratings.info())
print(movies.info())
ratings = pd.merge(ratings[['userId', 'movieId', 'rating']], movies[['movieId', 'title']],
how = 'left', left_on = 'movieId', right_on = 'movieId')
path3 = '/content/drive/MyDrive/Colab Notebooks/ratings_new.csv'
data = ratings[['userId','movieId', 'rating', 'title']].sort_values('userId')
data.to_csv(path3, index = False)
rp = ratings.pivot_table(columns = ['movieId'], index = ['userId'], values = 'rating')
rp = rp.fillna(0) #610*9724
print(rp.shape)
rp_mat = np.matrix(rp) #610*9724,ndarray类型
print(rp_mat.shape)
print(rp_mat)
m, n = rp.shape
mat_users = np.zeros((m, m))#二维数组,610*610
print(mat_users.shape)
#用户相似度矩阵(修正余弦相似度)
for i in range(m):
for j in range(m):
if i != j:
mat_users[i][j] = (1-cosine(rp_mat[i,:]-np.mean(rp_mat[:,j]), rp_mat[j,:]-np.mean(rp_mat[:,j])))
else:
mat_users[i][j] = 0
#得到的矩阵构建dataframe
pd_users = pd.DataFrame(mat_users, index = rp.index, columns = rp.index)
# 寻找相似用户
def topn_simusers(uid, n):
users = pd_users.loc[uid,:].sort_values(ascending = False)
topn_users = users.iloc[:n,]
topn_users = topn_users.rename('score')
print("Similar users as user:", uid)
return pd.DataFrame(topn_users)
#十个最相似用户
top_sim_users = topn_simusers(uid = 17, n = 10)
print(top_sim_users)
#某用户打分最高的几部电影
def topn_movieratings(uid, n_ratings):
uid_ratings = ratings.loc[ratings['userId'] == uid]
uid_ratings = uid_ratings.sort_values(by = 'rating', ascending = [False])
print ("Top", n_ratings, "movie ratings of user:", uid)
return uid_ratings.iloc[:n_ratings,]
top_movie_ratings1 = topn_movieratings(uid = 17, n_ratings = 10)
print(top_movie_ratings1)
uid = 17
uid_ratings1 = ratings.loc[ratings['userId'] == uid]
n_ratings = 20
uid = 278
top_movie_ratings2 = topn_movieratings(uid, n_ratings)
print(top_movie_ratings2)
recommend_movies = [] # 推荐电影,基于用户-用户相似度
for i in range(n_ratings):
rt = top_movie_ratings2['movieId'].iloc[i]
movie_title = top_movie_ratings2['title'].iloc[i]
if uid_ratings1.loc[uid_ratings1.movieId == rt].rating.values.size == 0:
recommend_movies.append(movie_title)
print('Recommended movies for the user 17 is:', recommend_movies)