第9章 数据仓库Hive
数据仓库
数据仓库的定义
专业定义
英文名称为Data Warehouse,可简写为DW。是为企业所有级别的决策制定过程,提供所有类型数据支持的战略集合。它是单个数据存储,出于分析性报告和决策支持目的而创建。为需要业务智能的企业,提供指导业务流程改进、监视时间、成本、质量以及控制。
通俗解释
(1)面向分析的存储系统(面向数据分析的存储系统)
(2)W.H.Inmmon给出的,即“数据仓库(Data Warehouse)是一个面向主题的(Subject Oriented)、集成的(Integrate)、相对稳定的/不可修改的(Non-Volatile)、反映历史变化(Time Variant)的数据集合,用于支持管理决策(数据分析、辅助管理决策)”。
- 面向主题:指数据仓库中的数据是按照一定的主题域进行组织。
主题即用户使用数据仓库进行决策时所关心的重点方面。如商品的推荐系统,它也是基于数据仓库所做出来的系统,其中,我们关心的主题也就是我们商品的信息。
- 集成:指对原有分散的数据库数据经过系统加工, 整理得到的消除源数据中的不一致性。
原来的数据有可能来自Oracle,也有可能来自Mysql,DB2,Redis,MongoDb等数据库,也有可能来自文本文件和其他的操作系统,因此,需要把不同的数据集成起来就组成了数据仓库。
- 不可修改:指一旦某个数据进入数据仓库以后只需要定期的加载、刷新,不会更改。
数据仓库主要是为了决策分析,所提供数据,所以主要涉及的操作是数据查询,因此其中的数据是不可更新的。
- 反映历史变化:指通过这些信息,对企业的发展历程和未来趋势做出定量分析预测。
一般都不会在数据仓库中做更新和删除操作,因为数据仓库就是做查询操作,因此数据仓库中的数据是随着时间的推移而不产生。
企业数据仓库有效集成了来自不同部门、不同地理位置、具有不同格式的数据,为企业管理决策者提供了企业范围内的单一数据视图,从而为综合分析和科学决策奠定了坚实的基础。常见的传统数据仓库工具供应商或产品主要包括Oracle、BusinessObjects、IBM Infomix、Sybase、NCR、Microsoft、SAS等。
数据仓库的体系结构
数据仓库的体系结构通常包含4个层次:数据源、数据存储和管理、数据服务、数据应用。
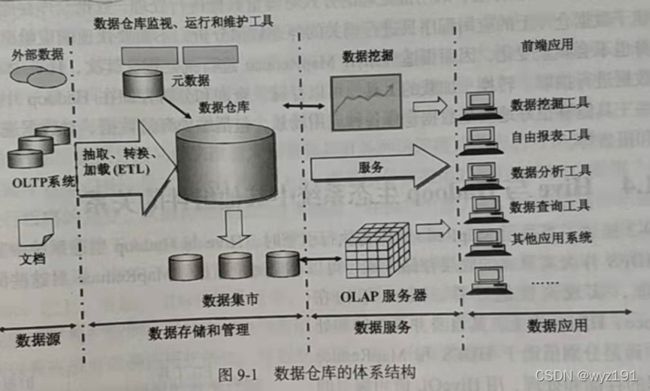
数据源
数据仓库的数据来源,包括外部数据、现有业务(OLTP,联机事务处理)系统和文档资料等。
数据存储和管理
主要涉及对数据的存储和管理,包括数据仓库、数据集市、数据仓库监视、运行与维护工具和元数据管理等。
数据服务
为前端工具和应用提供数据服务,可以直接从数据仓库中获取数据供前端应用使用,也可以通过OLAP(联机分析处理)服务器为前端应用提供更加复杂的数据服务。OLAP服务器提供了不同聚集粒度的多维数据集合,使得应用不需要直接访问数据仓库中的底层细节数据,这大大减少了数据计算量,提高了查询响应速度。OLAP服务器还支持针对多维数据集的上钻、下探、切片和旋转等操作,增强了多维数据分析能力。
数据应用
直接面向最终用户,包括数据查询工具、自由报表工具、数据分析工具、数据挖掘工具和各类应用系统。
数据仓库和数据库对比分析
主要联系
1、两者均是用来存储数据的,即均为数据的存储载体。
2、数据仓库也是数据库,是数据库的一种衍生、延深应用。
3、数库仓库和数据库之间存在数据交互,即你中有我、我中有你。
- 数据库中的在线数据推送到离线的数据仓库用于分析处理
- 数据仓库中分析处理的结果数据也通常推送到关系数据库中,便于前台应用的可视化展现应用。
4、数据仓库的出现,并不是要取代数据库,且当下大部分数据仓库还是用关系数据库管理系统来管理的,即数据库、数据仓库相辅相成、各有千秋。
主要区别
1、数据库是面向事务的设计,数据仓库是面向主题设计的。
2、数据库一般存储在线交易数据,实时性强存储空间有限,数据仓库存储的一般是历史数据,实时性弱但存储空间庞大。
3、数据库设计是尽量避免冗余,数据仓库在设计是有意引入冗余。
4、数据库是为捕获数据而设计,即实时性强吞吐量弱,数据仓库是为分析数据而设计,即吞吐量强实时性弱。
传统数据仓库面临的挑战
随着大数据时代的全面到来,传统数据仓库面临的挑战主要包括以下几个方面:
1、无法满足快速增长的海量数据存储需求
企业数据增长的速度已经大大超出了传统数据仓库的处理能力。这是因为传统数据仓库大都基于关系数据库,关系数据库横向扩展性较差,纵向扩展性有限。
2、无法有效处理不同类型的数据
传统数据仓库只能存储和处理结构化数据,当前企业数据源的数据格式越来越丰富,传统数据仓库无法处理众多的数据类型。
3、计算和处理能力不足
由于传统数据仓库建立在关系数据库基础之上,因此,会存在一个很大的痛点,即计算和处理能力不足,当数据量达到TB量级后,传统数据仓库基本无法获得很好的性能。
数据仓库中的数据模型
我们在搭建一个数据仓库的时候通常会使用以下两种模式:
第一种星型模型,星型模型是搭建数据仓库最基本的一种数据模型。
第二种雪花模式,是在星型模型的基础之上发展起来的一种新的模型,雪花模型使用于更复杂的应用场景。
星型模型
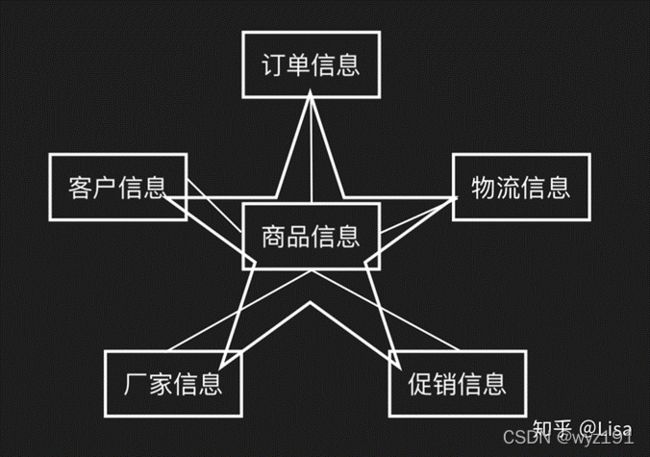
由商品信息可以与客户信息、订单信息、厂家信息、物流信息、促销信息产生关联(以商品信息为主题)
是以面向商品信息为核心的星型模型。
雪花模型
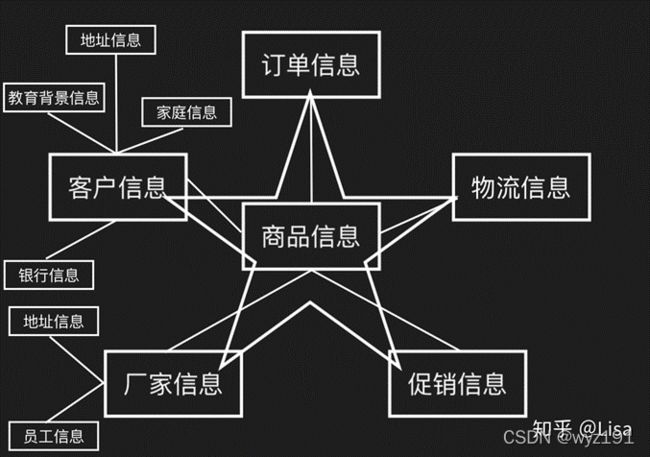
基于星型模型发展起来的雪花模型
由客户信息可以与家庭信息、地址信息、教育背景信息、银行信息产生关联(面向客户信息)
由厂家信息可以与地址信息、员工信息产生关联(面向厂家信息)
数据仓库的结构和建立过程
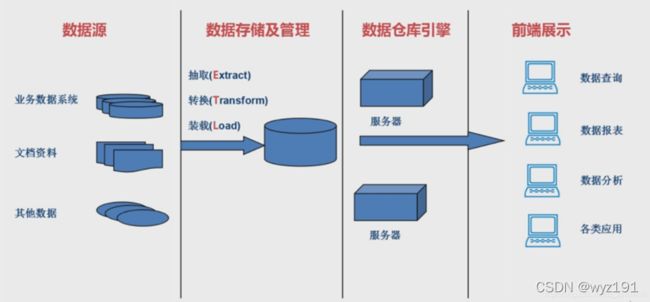
数据源
业务系统的数据:Oracle、Mysql等关系型数据库,Redis、MongoDB等非关系型数据库
文档资料:CSV、TXT
其他数据:其他系统的数据
数据存储及管理
进行ETL,并单独存放在一个数据库中,这个数据库就叫做数据仓库。
抽取(Extract):把数据源的数据按照一定的方式读取出来,然后进行格式转换
转换(Transform):将抽取出来的数据按照一定的格式进行转换,然后进行装载。
因为不同数据源的数据格式不同,可能不能满足我们对存储格式的要求,因此,我们需要按照一定的规则对读取到的数据进行转换,只有转换完符合要求的数据才能进行装载。
装载(Load):将满足格式的数据存入数据库中,最终,便建立了数据仓库
数据仓库引擎
通过数据仓库引擎,使数据仓库对外提供服务,不同的服务器提供不同的服务,如数据操作、数据报表、数据分析、各类应用
前端展示
进行前端展示,前端展示的数据均来源于数据仓库引擎中的各个对外服务,而各个服务又读取数据仓库中的数据,这样就完成了整个数据仓库的建立。
Hive
Hive简介
Hive是一个构建在Hadoop之上的数据仓库工具,在2008年8月开源。Hive在某种程度上可以看作用户编程接口,其本身并不存储和处理数据,而是依赖HDFS来存储数据,依赖MapReduce(或者Tez、Spark)来处理数据。Hive定义了简单的类似SQL的查询语言----HiveQL,它与大部分SQL语法兼容。
Hive作为Hadoop平台上的数据仓库工具,应用十分广泛,主要是因为它具有如下特点:
1、当采用MapReduce作为执行引擎时,Hive把HiveQL语句转换成MapReduce任务后,采用批处理的方式对海量数据进行处理。数据仓库存储的是静态数据,构建于数据仓库上的应用程序只进行相关的静态数据分析,不需要快速响应给出结果,而且数据本身也不会频繁变化,因而很适合采用MapReduce进行批处理。
2、Hive本身提供了一系列对数据进行抽取、转换、加载的工具,可以存储、查询和分析存储在Hadoop中的大规模数据。这些工具能够很好地满足数据仓库各种应用场景,包括维护海量数据、对数据进行挖掘、形成意见和报告等。
Hive的定义
Hive也是一种数据仓库,但与传统的数据仓库又有些区别。
Hive是建立在Hadoop HDFS上的数据仓库基础架构,在某种程度上可以看作用户编程接口,其本身并不存储和处理数据,而是依赖HDFS来存储数据,依赖MapReduce(或者Tez、Spark)来处理数据。
一般的传统数据仓库可以用Oracle、Mysql进行搭建,这时的数据库是存在Oracle、Mysql数据中,而Hive中的数据是存储在HDFS上的,这就Hive最基本的概念。
Hive可以用来进行数据提取转化加载(ETL)
Hive定义了简单的类似SQL的查询语句,称为HiveQL(HQL),它允许熟悉SQL的用户查询数据
Hive允许熟悉MapReduce开发者的开发自定义的mapper和reducer来处理内建的mapper和reducer无法完成的复杂的分析工作
Hive是SQL解析引擎,他将SQL语句转换成M/R Job,然后在Hadoop中执行
Hive的表其实就是HDFS的目录/文件夹;Hive中的数据其实就是HDFS中的文件
Hive架构支持拿来即用,亦支持灵活的参数和计算引擎的变更
Hive在Hadoop生态圈地位
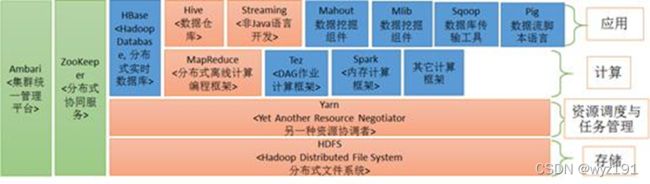

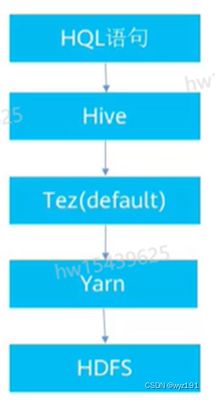
当采用MapReduce作为执行引擎时,Hive与Hadoop生态系统中其他组件的关系。HDFS作为高可靠的底层存储方式,可以存储海量数据。MapReduce对这些海量数据进行批处理,实现高性能计算。Hive架构在MapReduce、HDFS之上,其自身并不存储和处理数据,而是分别借助于HDFS和MapReduce实现数据的存储和处理,用HiveQL语句编写的片逻辑,最终都转换成MapReduce任务来运行。
Pig可以作为Hive的替代工具,它是一种数据流语言和运行环境,适用于在Hadoop平台上查询半结构化数据集,常用于ETL过程的一部分,即将外部数据装载到Hadoop集群中,然后转换为用户需要的数据格式。HBase是一个面向列的、分布式的、可伸缩的数据库,它可以提供数据的实时访问功能,而Hive只能处理静态数据,主要是BI报表数据。
就设计初衷而言,在Hadoop之上设计Hive,是为了减少复杂MapReduce应用程序的编写工作,在Hadoop上设计HBase则是为了实现对数据的实时访问,所以,HBase与Hive的功能是互补的,它实现了Hive不能提供的功能。
Hive优缺点
1、优点
(1)高可靠、高容错
- HiveServer采用集群模式
- 双MetaStore
- 超时重试机制
(2)类SQL
- 类似SQL语法:操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
- 内置大量函数:避免了去写 MapReduce,减少开发人员的学习成本。
(3)可扩展
- 自定义存储格式
- 自定义函数:Hive支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
(4)多接口
- Beeline
- JDBC
- Thrift
- Python
- ODBC
2、缺点
(1)Hive 的 HQL 表达能力有限
1)迭代式算法无法表达
2)数据挖掘方面不擅长
(2)Hive 的效率比较低
1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
2)Hive 调优比较困难,粒度较粗
(3)Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
(4)Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
Hive与传统数据库的对比
| 对比内容 |
Hive |
传统数据库 |
| 查询语言 |
HQL |
SQL |
| 数据存储 |
HDFS |
Raw Device 或本地文件系统 |
| 数据插入 |
执行批量导入/单条插入 |
支持批量或单条导入 |
| 数据更新 |
不支持 |
支持 |
| 索引 |
支持有限索引 |
支持复杂索引 |
| 分区 |
支持 |
支持 |
| 执行引擎 |
MapReduce、Tez、Spark |
自身的执行引擎 |
| 执行延迟 |
高 |
低 |
| 扩展性 |
高 |
有限 |
| 数据规模 |
大 |
小 |
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将Hive 理解为数据库。其实从结构上来看,Hive和数据库除了拥有类似的查询语言,再无类似之处。数据库可以用在Online的应用中,但是Hive是为数据仓库而设计的。
Hive具有SQL数据库的外表,但应用场景完全不同, Hive只适合用来做批量海量数据统计分析,也就是数据仓库。
1、查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
2、数据存储位置
Hive 是建立在 Hadoop 之上的,所有 Hive 的数据都是存储在 HDFS 中的。而数据库则可以将数据保存在块设备或者本地文件系统中。
3、数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
4、索引
Hive 在加载数据的过程中不会对数据进行任何处理,甚至不会对数据进行扫描,因此也没有对数据中的某些 Key 建立索引。Hive 要访问数据中满足条件的特定值时,需要暴力扫描整个数据,因此访问延迟较高。由于 MapReduce 的引入, Hive 可以并行访问数据,因此即使没有索引,对于大数据量的访问,Hive 仍然可以体现出优势。数据库中,通常会针对一个或者几个列建立索引,因此对于少量的特定条件的数据的访问,数据库可以有很高的效率,较低的延迟。由于数据的访问延迟较高,决定了 Hive 不适合在线数据查询。
5、执行
Hive 中大多数查询的执行是通过 Hadoop 提供的 MapReduce 来实现的。而数据库通常有自己的执行引擎。
6、执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
7、可扩展性
由于 Hive 是建立在 Hadoop 之上的,因此 Hive 的可扩展性是和 Hadoop 的可扩展性是一致的(世界上最大的 Hadoop 集群在 Yahoo!,2009 年的规模在 4000 台节点左右)。而数据库由于 ACID 语义的严格限制,扩展行非常有限。目前最先进的并行数据库 Oracle 在理论上的扩展能力也只有 100 台左右。
8、数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive系统架构
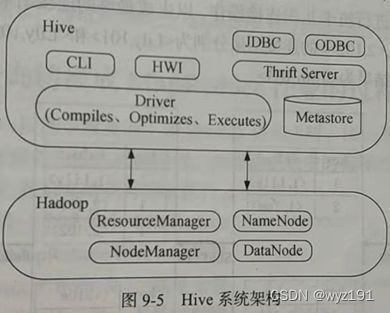
Hive主要由以下3个模块组成,其系统架构如图所示:用户接口模块、驱动模块以及元数据存储模块。
1、用户接口模块
用户接口模块包括CLI、Hive网页接口(Hive Web Interface,HWI)、JDBC、ODBC、Thrift Server等,用来实现外部应用对Hive的访问。
CLI是Hive自带的一个命令行客户端工具,是一个和Hive通过命令行交互的接口。Hive还提供了另外一个命令行客户端工具Beeline,在Hive 3.0以上版本中,Beeline取代了CLI。
HWI是Hive的一个简单网页,Web接口,可以通过浏览器访问Hive。
JDBC、ODBC和Thrift Server提供了可以从不同编程语言编写的客户端访问Hive的接口,支持身份验证和多用户并发访问。其中,Thrift Server基于Thrift软件框架开发的,它提供Hive的RPC通信接口。
2、驱动模块(Driver)
驱动模块(Driver)包括编译器、优化器、执行器等,所采用的执行引擎可以是MapReduce、Tez或Spark等。当采用MapReduce作为执行引擎时,驱动模块负责把HiveQL语句转换成一系列MapReduce作业,所有命令和查询都会进入驱动模块,通过该模块对输入进行解析编译,对计算过程进行优化,然后按照指定的步骤执行。
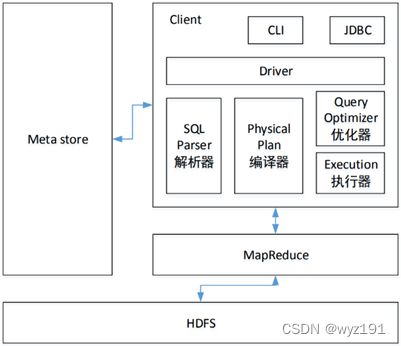
解释器、编译器、优化器、执行器这四大组件完成 HQL 查询语句从词法分析、语法分析、编译、优化以及生成查询计划的生成。生成的查询计划存储在 HDFS 中,并随后由 MapReduce 调用执行。
用户提交SQL给Hive,由Driver负责解析SQL,在解析时会加载相关的元数据信息,生成执行计划,然后生成Job交给Hadoop运行,然后Driver将结果返回给用户。
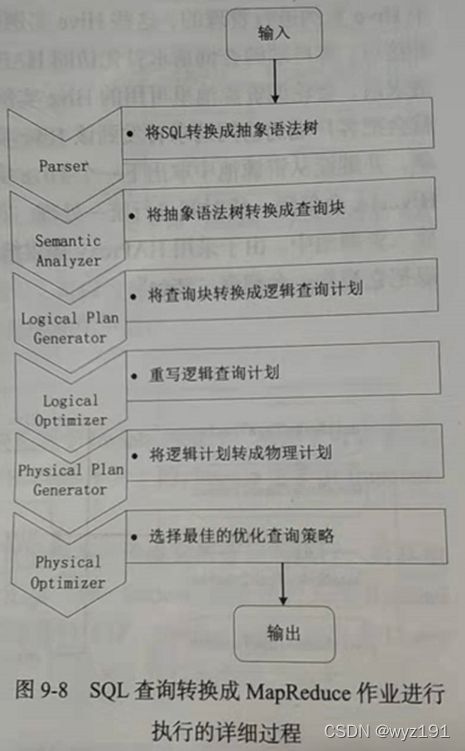
(1)解析器(SQL Parser)
将SQL字符串转换成抽象语法树AST,这一步一般都用第三方工具库完成,比如antlr;对AST进行语法分析,比如表是否存在、字段是否存在、SQL 语义是否有误。
(2)编译器(Physical Plan)
将AST编译生成逻辑执行计划。
Hive的核心,负责SQL语句的语法、语义解析,生成查询计划。
1)语义解析器(ParseDriver),将查询字符串转换成解析树表达式;
2)语法解析器(SemanticAnalyzer),将解析树转换成基于语句块的内部查询表达式;
3)逻辑计划生成器(Logical Plan Generator),将内部查询表达式转换为逻辑计划,这些计划由逻辑操作树组成,操作符是Hive的最小处理单元,每个操作符处理代表一道HDFS操作或者是MR作业;
4)查询计划生成器(QueryPlan Generator),将逻辑计划转化成物理计划(MR Job)。
生成的查询计划存储在 HDFS 中,并在随后由 MapReduce 调用执行。
(3)优化器(Query Optimizer)
对逻辑执行计划进行优化。优化器是一个演化组件,当前它的规则是:列修剪,谓词下压。
(4)执行器(Execution)
把逻辑执行计划转换成可以运行的物理计划。对于Hive来说,就是 MR/Spark。编译器将操作树切分成一个Job链(DAG),执行器会顺序执行其中所有的Job;如果Task链不存在依赖关系,可以采用并发执行的方式进行Job的执行。
3、元数据存储模块(Metastore)
元数据存储模块(Metastore)是一个独立的关系数据库,通常是与MySQL数据库连接后创建的一个MySQL实例,也可以是Hive自带的derby数据库实例。元数据存储模块中主要保存表模式和其他系统元数据,如表的名称、表的列及其属性、表的分区及其属性、表的属性、表中数据所在位置信息等。
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;
默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore。
1)元数据是什么?
存储在Hive中的数据的描述信息
2)有哪些?
表的名、表的列和分区以及属性(内部表和外部表)、表的数据所在目录
3)存在哪儿?
自带Derby。缺点:不适合多用户操作,并且数据存储目录不确定
4)解决方案
存在自己创建的MySQL中(本地或远程)
4、Hadoop
使用HDFS进行存储,使用MapReduce进行计算。
Hive执行流程
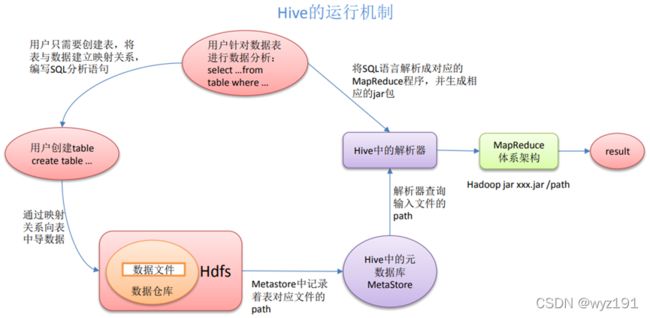
HiveQL 通过命令行或者客户端提交,经过Compiler编译器,运用MetaStore中的元数据进行类型检测和语法分析,生成一个逻辑方案(logical plan),然后通过的优化处理,产生一个 MapReduce 任务。
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
Hive工作原理
在Hive中,用户通过命令行CLI或其他Hive访问工具,向Hive输入一段命令或查询以后,SQL查询被Hive自动转换成MapReduce作业,具体步骤如下。
(1)由Hive驱动模块中的编译器 – Antlr语言识别工具,对用户输入的SQL进行词法和语法解析,将SQL语句转化为抽象语法树(Abstrct Syntax Tree,AST)的形式。
(2)对该抽象语法树进行遍历,进一步转化成查询块(QueryBlock)。因为抽象语法树的结构仍很复杂,不方便直接翻译为MapReduce算法程序,所以,Hive把抽象语法树进一步转化为查询块。查询块是一个最基本的SQL语法组成单元,包括输入源、计算过程和输出3个部分。
(3)再对查询块进行遍历,生成操作树(Operator Tree)。其中,操作树由很多逻辑操作符组成,如TableScanOperator、SelectOperatro、JoinOperator、GroupByOperator和ReduceSinkOperator等。这些逻辑操作符可以在Map阶段和Reduce阶段完成某一特定操作。
(4)通过Hive驱动模块中的逻辑优化器对操作树进行优化,变换操作树的形式,合并多余的操作符,从而减少MapReduce作业数量以及Shuffle阶段的数据量。
(5)对优化后的操作树进行遍历,根据操作树中的逻辑操作符生成需要执行的MapReduce作业。
(6)启动Hive驱动模块中的物理优化器,对生成的MapReduce作业进行优化,生成最终的MapReduce作业执行计划。
(7)最后由Hive驱动模块中的执行器,对最终的MapReduce作业进行执行输出。
Hive HA基本原理
在Hive HA中,在Hadoop集群上构建的数据仓库是由多个Hive实例进行管理的,这些Hive实例被纳入一个资源池中,并由HAProxy提供一个统一的地外接口。客户端的查询请求首先访问HAProxy,由HAProxy对访问请求进行转发。HAProxy收到请求后,会轮询资源池里可用的Hive实例,执行逻辑可用性测试。如果某个Hive实例逻辑可用,就会把客户端的访问请求转发到该Hive实例上,如果该Hive实例逻辑不可用,就把它放入黑名单,并继续从资源池中取出下一个Hive实例进行可用性测试。对于黑名单中的Hive实例,Hive HA会每隔一段时间进行统一处理,首先尝试重启该Hive实例,如果重启成功,就再次把它放入资源池中。由于采用HAProxy提供统一的对外访问接口,因此,对于程序开发人员来说,可以把它当作一台超强“Hive”。

Hive在企业中的部署与应用
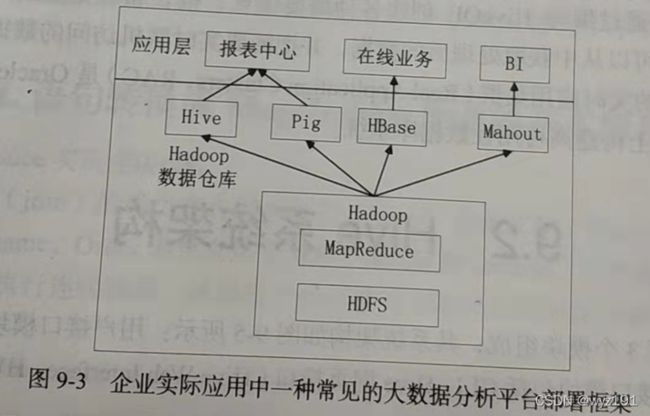
Hive运行流程
(1)Client提交HQL命令
(2)Tez执行查询
(3)YARN为集群中的应用程序分配资源,并为YARN队列中的Hive作业启用授权
(4)Hive根据表类型更新HDFS或Hive仓库中的数据。
(5)Hive通过JDBC连接返回查询结果。
Hive数据存储模型

1 、数据存储格式
可支持 TextFile、SequenceFile、 ParquetFile、RCFILE 等
2 、解析数据
只需要在创建表的时候告诉 Hive 数据中的列分隔符和行分隔符
3、 数据模型
(1)db(数据库)
在 HDFS 中表现为${hive.metastore.warehouse.dir}目录下一个文件夹
(2)table(表)
在 HDFS 中表现所属 db 目录下一个文件夹
(3)External table(外部表)
与 table 类似,不过其数据存放位置可以在任意指定路径
(4)partition(分区)
在 HDFS 中表现为 table 目录下的子目录
(5)bucket(桶表)
在 hdfs 中表现为同一个表目录下根据 hash 散列之后的多个文件
Hive数据存储模型 – 分区和分桶
(1)分区:数据表可以按照某个字段的值划分分区。
1)每个分区是一个目录。
2)分区数量不固定。
3)分区下可再有分区或者桶。
(2)桶:数据可以根据桶的方式将不同数据放入不同的桶中。
1)每个桶是一个文件。
2)建表时指定桶个数,桶内可排序。
3)在数据按照某个字段的值Hash后放入某个桶中。
Hive数据存储模型 – 托管表和外部表
Hive可以创建托管表和外部表
- 默认创建托管表,Hive会将数据移动到数据仓库目录。
- 创建外部表,这时Hive会到仓库目录以外的位置访问数据。
- 如果所有处理都由Hive完成,建议使用托管表。
- 如果要用Hive和其它工具来处理同一个数据集,建议使用外部表。

Hive使用方式
Running HiveServer2 and Beeline
$ $HIVE_ HOME/bin/hiveserver2
$ $HIVE HOME/bin/beeline -u jdbc:hive2://$HS2_ HOST:$HS2_ PORT
Running Hcatalog
$ $HIVE HOME/hcatalog/sbin/hcat server.sh
Running WebHCat (Templeton)
$ $HIVE_ HOME/hcatalog/sbin/webhcat server.sh
Impala
由于Hive采用MapReduce来完成批量数据处理,因此,实时性不好,查询延迟较高。Impala作为开源大数据分析引擎,支持实时计算,它提供了与Hive类似的功能,并在性能上比Hive高出3~30倍。
Impala简介
| ODBC Driver |
|
| Impala |
Metastore(Hive) |
| HDFS |
HBase |
Impala是由Cloudera开发的查询系统,它提供了SQL语义,能查询存储在Hadoop的HDFS和HBase上的PB级海量数据。由于MapReduce是一个面向批处理的非实时计算框架,当Hive采用MapReduce作为执行引擎时,不能满足查询的实时交互性。Impala最初是参照Dremel系统进行设计的,Dermel系统是Google开发的交互式数据分析系统,可以在2~3秒内分析PB级别的海量数据。所以,Impala也可以实现大数据的快速查询。
Impala的目的是提供一个统一的平台用于实时查询。
Impala也可以直接与HDFS和HBase进行交互。当采用MapReduce作为执行引擎时,Hive底层执行使用的是MapReduce,所以主要用于处理长时间运行的批处理任务,例如批量抽取、转换、加载任务。而Impala采用了与商用 MPP并行关系数据库类似的分布式查询引擎,可以直接从HDFS或者HBase中用SQL语句查询数据,而不需要把SQL语句转换成MapReduce作业执行,从而大大降低了延迟,可以很好地满足实时查询的要求。另外,Impala和Hive采用相同的SQL语法、ODBC驱动程序和用户接口。
Impala系统架构
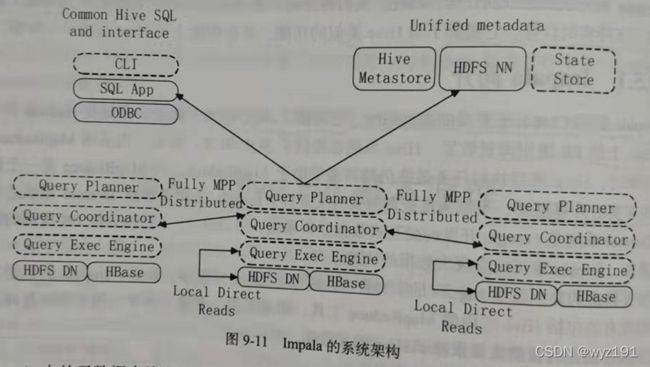
图中虚线模块是属于Impala的组件。从图中可以看出,Impala和Hive、HDFS、HBase等工具是统一部署在一个Hadoop平台上的。Impala主要由Impalad、State Store和CLI三部分组成。具体如下:
(1)Impalad:Impalad是Impala的一个进程,负责协调客户端提交的查询的执行,给其他Impalad分配任务以及收集其他Impalad的执行结果进行汇总。另外,Impalad也会执行其他Impalad给其分配的任务,主要对本地HDFS和HBase里的部分数据进行操作。Impalad进行主要包含Query Planner、Query Coordinator和Query Exec Engine3个模块,与HDFS的数据节点(HDFS DataNode)运行在同一节点上,并且完全分布运行在MPP架构上。
(2)State Store:负责收集分布在集群中各个Impalad进程的资源信息,用于查询的调度。State Store会创建一个statestored进程,来跟踪集群中的Impalad的健康状态及位置信息。Statestored进程通过创建多个线程来处理Impalad的注册订阅以及与各个Impalad保持心跳连接。另外,各Impalad都会缓存一份State Store中的信息。当State Store离线后,Impalad一旦发现State Store处于离线状态时,就会进入恢复模式,并进行反复注册。当State Store重新加入集群后,自动恢复正常,更新缓存数据。
(3)CLI:CLI给用户提供了执行查询的命令行工具,同时,Impalad提供了Hue、JDBC及ODBC使用接口。
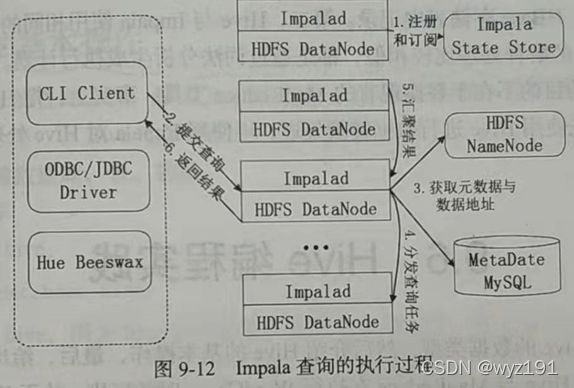
Impala查询执行过程
Impala查询执行过程具体如下:
(1)注册和订阅
当用户提交查询前,Impala先创建一个Impalad进程来具体负责协调客户端提交的查询,该进程会向State Store提交注册订阅信息,State Store会创建一个statestored进程,statestored进程通过创建多个线程来处理Impalad的注册订阅信息。
(2)提交查询
用户通过CLI客户端提交一个查询到Impalad进程,Impalad的Query Planner对SQL语句进行解析,生成解析树。然后,Planner把这个查询的解析树变成若干PlanFragment,发送到Query Coordinator。其中,PlanFragment由PlanNode组成的,能被分发到单独的节点上执行。每个PlanNode表示一个关系操作和对其执行优化需要的信息。
(3)获取元数据与数据地址
Query Coordinator从MySQL元数据中获取元数据(即查询需要用到哪些数据),从HDFS的名称节点中获取数据地址(即数据被保存在哪个数据节点上),从而得到存储这个查询相关数据的所有数据节点。
(4)分发查询任务
Query Coordinator初始化相应Impalad上的任务,即把查询任务分配给所有存储这个查询相关数据的数据节点。
(5)汇聚结果
Query Executor通过流式交换中间输出,并由Query Coordinator汇聚来自各个Impalad的结果。
(6)返回结果
Query Coordinator把汇总后的结果返回给CLI客户端。
Impala与Hive的比较
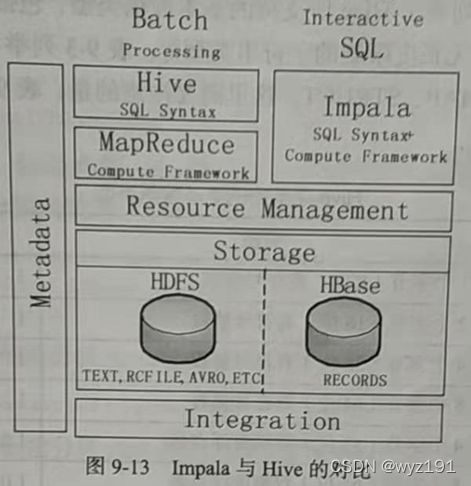
(1)相同点
1)Hive与Impala使用相同的存储数据池,都支持把数据存储于HDFS和HBase中,其中,HDFS支持存储TEXT、RCFILE、PARQUET、AVRO、ETC等格式的数据,HBase存储表中记录。
2)Hive与Impala使用相同的元数据。
3)Hive与Impala中对SQL的解释处理比较相似,都是通过词法与分析生成执行计划。
(2)不同点
1)Hive适合进行长时间的批处理查询分析,Impala适合进行实时交互式查询。
这是Hive架构在Hadoop之上继承了其批处理的方式,在作业提交和调度的时候会涉及大量的开销,这就意味着Hive不能在大规模数据集上实现低延迟的快速查询。
2)当采用MapReduce作为执行引擎时,Hive依赖于MapReduce计算框架,执行计划组合成管道型的MapReduce任务模式进行执行,Impala则把执行计划表现为一棵完整的执行计划树,可以更自然地分发执行计划到各个Impalad执行查询。
3)Hive在执行过程中,如果内存放不下所有数据,则会使用外存,以保证查询能顺序执行完成,而Impala在遇到内存放不下数据时,不会利用外存。所以,Impala目前处理查询时会受到一定的限制,使得Impala更适合处理输出数据较小的查询请求,而对于大数据量的批处理,Hive依然是更好的选择。
总之,Impala的目的不在于替换现有的MapReduce工具。事实上,把Hive与Impala配合使用效果最佳,可以先使用Hive进行数据转换处理,再使用Impala对Hive处理后的结果数据集进行快速的数据分析。