Transformer 中 Decoder 结构解读_by 弘毅
1. Transformer 中解码器;
1.1 Transformer 中编码器与解码器的区别
Transformer 中 编码器与解码器的区别, 如图所示:
-
第一级中: 将self attention 模块改成了 masked self-attention, 用于只考虑解码器的当前输入和当前输入的左侧部分, 不考虑右侧部分; ( 注意,第一级decoder的key, query, value均来自前一层decoder的输出,但加入了Mask操作,即我们只能attend到前面已经翻译过的输出的词语,因为翻译过程我们当前还并不知道下一个输出词语,这是我们之后才会推测到的。);
-
第二级中,引入了 Cross attention 交叉注意力模块: 在 masked self-attention 和 F C FC FC 全连接层 之间加入;
-
Cross attention 交叉注意力模块的输入 Q,K,V 不是来自同一个模块: 而是来自 K , V K,V K,V 来自编码器的输出, Q Q Q解码器的输出;
注意点 : 解码器的输出一个一个产生的,

1.2 解码器中的 Masked self attention
Masked self attention :
只考虑输入向量本身, 和输入向量的之前的向量,即左侧向量;
输出向量 b 1 b^1 b1 的时候, 只考虑了输入向量 a 1 a^1 a1;
输出向量 b 2 b^2 b2 的时候, 只考虑输入向量 a 2 a^2 a2, 以及 a 2 a^2 a2 之前的输入向量 a 1 a^1 a1 ;
输出向量 b 3 b^3 b3 的时候, 只考虑 输入向量 a 3 a^3 a3, 以及 a 3 a^3 a3 之前的输入向量 a 1 a^1 a1 , a 2 a^2 a2;
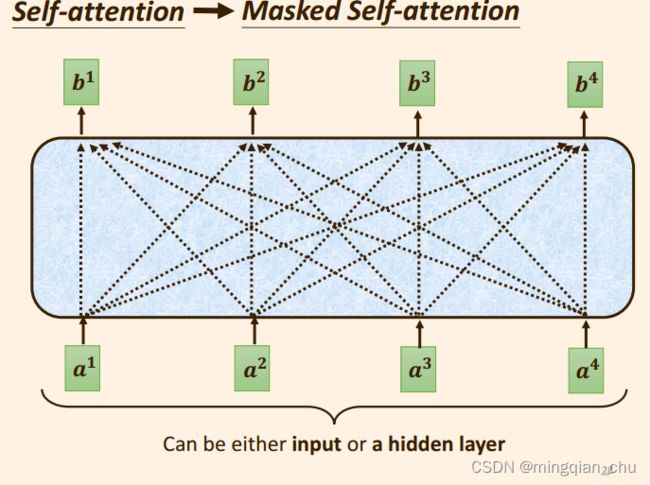
更具体点, 当我们要求输出向量 b 2 b^2 b2 的时候,
我们只会考虑输入向量 a 1 , a 2 a^1, a^2 a1,a2 中的 k 1 , k 2 k^1, k^2 k1,k2,
而不会去考虑输入向量 a 3 , a 4 a^3, a^4 a3,a4 部分。
也就是 求相关性的分数时, q q q , k , v k, v k,v 只会 考虑当前输入向量的左侧向量部分, 而不去考虑输入向量后面的右侧部分;

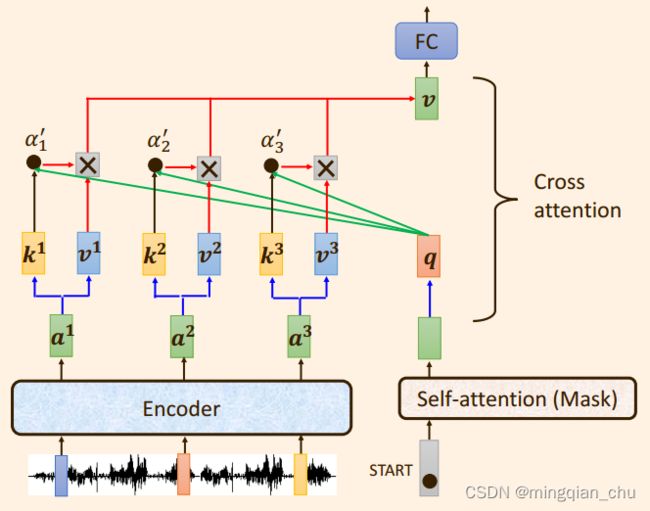
1.3 Transformer 中Cross attetion 交叉注意力
之所以称为交叉注意力,是因为 向量 q , k , v q, k ,v q,k,v 不是来自同一个模块。
而是将:
来自解码器的输出向量 q q q 与 来自编码器的输出向量 k , v k,v k,v 运算。
具体讲来:
向量 q q q 与向量 k k k 之间相乘求出注意力分数: α 1 , {\alpha_1}^, α1,
注意力分数: α 1 , {\alpha_1}^, α1, 在与向量 v v v 相乘求和,
得出向量 b b b (图中表示为向量 v v v ) ;
1.4 Transformer 中Decoder 的运作流程
Decoder 的运作流程是:
-
经过 Masked self attention:
解码器之前的输出, 作为当前解码器的输入,
并且训练过程中, 真实标签的也会输入到 解码器中,
此时这些输入, 通过一个 Masked self-attention ,
得到输出 q q q向量, 注意到这里的 q q q 是由解码器产生的; -
经过 Cross attention:
将向量 q q q 与 来自编码器的输出向量 k , v k,v k,v 运算。
具体点: 向量 q q q 与向量 k k k 之间相乘求出注意力分数: α 1 , {\alpha_1}^, α1, ;
注意力分数 α 1 , {\alpha_1}^, α1, 在与向量 v v v 相乘求和,
得出向量 b b b (前面图中表示为向量 v v v ); -
经过全连接层:
之后向量 b b b 便被输入到 f e e d − f o r w a r d feed- forward feed−forward 层, 也即全连接层, 得到最终输出;
1.5 Transformer的训练过程
训练启动时,
会输入一个 启动标志向量 start;
输出结束时, 也会输出一个 结束标志向量 end;
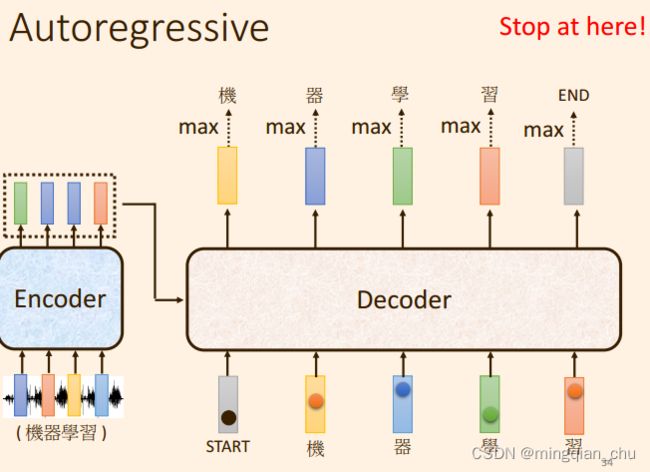
- decoder 会将自己的输出当做接下来的输入;
- 训练的时候误差采用 minize cross entropy;
- 测试的时候 的 误差 BLUe score
解决 :
decoder 先前的输出 错误, 然后使用该 错误 作为decoder 当前的输入, 会导致后面的输出全部错误;
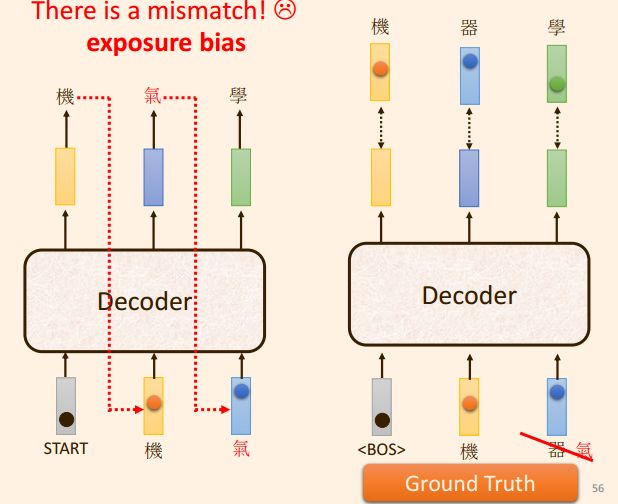
解决方法:
Ground truth 中 加入 部分 错误, schedule sample , 这样会导致 transformer 的平行化能力;