基于注意力机制的多层感知机的实现
写作这篇博客的过程中参考了keras教程-n-循环神经网络的注意力机制的理论和实现里面的问题和代码,但是这篇文章中的问题描述不清晰、代码比较冗余,所以按照自己对问题和注意力机制的理解改进了其中的问题描述和代码实现。
1 问题描述
假设有一个6位数字,要求预测其前3位数组成的数字与后3位数组成的数字之差的绝对值。
2 解决思路
我们考虑用深度学习中一个简单的模型——多层感知机来完成这个任务,同时,考虑到两个3位数相减时,不同数位的数字对于结果的重要性是不一样的,比如百位上的数字比个位上的数字对结果影响大,我们引入了注意力机制。注意力机制起源于人类视觉系统,人类视觉系统在查看图像时,会快速扫描全局图像,获取需要重点关注的目标区域,而后对这一区域投入更多资源,以获取更多需要关注的目标的细节,抑制其他无用信息,关于注意力机制的概念可以参考这篇博客:深度学习中的注意力机制概述。基于注意力机制的多层感知机的网络结构如下:
- 首先通过全连接层获取输入数据的注意力分布,即对于该任务而言每个数位的重要程度
- 然后将注意力分布与输入相乘得到输入数据的表示
- 再加入两个全连接层获取输入数据的高层表示
- 使用MSE损失函数和Aadm优化器对模型进行优化
3 代码实现
该部分包含数据仿真、模型构建和注意力机制可视化三部分,下面将以代码加注释的形式讲解。
3.1 数据仿真
首先,我们仿真出10万条数据用于模型的训练、验证和测试。代码如下:
# 创建样本数据
def create_data(n):
"""
:param n: 样本数量
:return: 样本的特征及标签
"""
# 预定义特征
X = np.zeros((n, TIME_STEP), dtype='int32') # np.zeros返回一个给定形状和类型的用0填充的数组
# 预定义标签
Y = np.zeros((n, ), dtype='int32')
for i in range(n):
# 特征
feature = np.random.randint(0, 10, size=TIME_STEP) # 生成仿真数组
x1 = feature[0] * 100 + feature[1] * 10 + feature[2] # 第一个三位数
x2 = feature[3] * 100 + feature[4] * 10 + feature[5] # 第二个三位数
# 标签
label = abs(x1 - x2) # 两个三位数的差的绝对值
X[i] = feature
Y[i] = label
# 返回归一化后的特征和标签
return {
'X': X / 10, # 字典类型
'Y': Y / 1000,
}
SAMPLE_NUM = 300000 # 样本数量
data = create_data(SAMPLE_NUM) # 调用函数生成样本,字典类型
3.2 模型构建
我们使用Keras中的函数模型构建网络结构,函数模型是一个非常灵活且强大的工具,能够完成许多复杂的网络构建任务。我们构建的模型包含相互关联的两块,一个是总模型,输入为特征数组,输出为预测的差值的绝对值;子模型的输入为特征数组,输出为特征的注意力分布,即特征的权重。代码如下:
# 参数定义
BATCH_SIZE = 12800 # 批次大小
TIME_STEP = 6 # 样本特征数量
DEMESION = 10 # 每个特征的维度
OUTPUT_LEN = 3 # 标签的维度
# 构建带有注意力的多层感知机模型
def build_model():
inputs = Input(shape=(TIME_STEP, ))
# 注意力层,计算输入中每个元素的注意力分布
attention_prob = Dense(TIME_STEP, activation='relu')(inputs)
# 根据计算的注意力分布对每个输入元素进行加权
attention_encoding = multiply([inputs, attention_prob]) # 对应位置元素相乘
# 两个全连接层
encoding_a = Dense(TIME_STEP, activation='relu')(attention_encoding)
encoding_b = Dense(int(TIME_STEP / 2), activation='relu')(encoding_a)
# 回归问题,不需要将预测结果进行分类转换,所以输出层不需要设置激活函数,直接输出数值
output = Dense(1)(encoding_b)
# 函数模型
model = Model(inputs=[inputs], output=output) # 总模型
att_model = Model(inputs=inputs, output=attention_prob) # 子模型
# 返回值
return model, att_model
model, att_model = build_model() # 调用函数,返回模型、输出值以及注意力分布
# 编译模型
model.compile(loss='MSE', optimizer='Adam') # 损失函数为MSE
# 训练模型,两个模型同时训练
model.fit([data['X']], data['Y'], epochs=100)
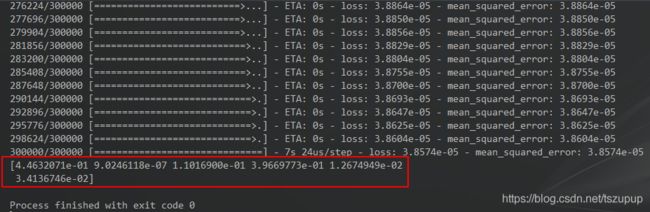
训练过程截图如下:

3.3 注意力机制可视化
我们知道,注意力机制在一定程度上可以增加结果的可解释性,这里,我们通过可视化注意力分布来验证注意力机制是否起到了作用。代码如下:
# 可视化注意力分布
# 调用子模型得到注意力分布
att_dis = att_model.predict(data['X'])
avg_attention = np.mean(att_dis, axis=0)
# 注意力分布的归一化
avg_attention = avg_attention / np.sum(avg_attention, axis=0)
# 以柱状图的形式进行可视化
plt.bar(range(1, 7), avg_attention)
plt.show()
# 打印注意力分布
print(avg_attention)
可视化结果如下:

可以看到,模型对于第1位数字和第4位数字的关注度更高,即第1位数字和第4位数字对结果更重要,说明注意力机制确实起到了作用。
4 完整代码
#-*-coding:utf-8-*-
"""
@author:taoshouzheng
@time:2019/2/14 8:05
@email:[email protected]
"""
import numpy as np
from keras.layers import Input, Dense
from keras.layers import multiply
from keras.models import Model
import matplotlib.pyplot as plt
# 参数定义
BATCH_SIZE = 12800 # 批次大小
TIME_STEP = 6 # 样本特征数量
DEMESION = 10 # 每个特征的维度
OUTPUT_LEN = 3 # 标签的维度
SAMPLE_NUM = 300000 # 样本数量
ONE_HOT = False # 是否独热编码
np.random.seed(1) # 结果重复性设置
# 创建样本数据
def create_data(n):
"""
:param n: 样本数量
:return: 样本的特征及标签以及对应的one-hot编码
"""
# 预定义特征
X = np.zeros((n, TIME_STEP), dtype='int32') # np.zeros返回一个给定形状和类型的用0填充的数组
# 预定义标签
Y = np.zeros((n, ), dtype='int32')
# one_hot编码部分
for i in range(n): # 遍历所有样本
# 特征
feature = np.random.randint(0, 10, size=TIME_STEP) # numpy.random.randint(low, high size=n)返回一个长度为n的每个元素位于low和high之间的整数数组
x1 = feature[0] * 100 + feature[1] * 10 + feature[2] # 第一个三位数
x2 = feature[3] * 100 + feature[4] * 10 + feature[5] # 第二个三位数
# 标签
label = abs(x1 - x2) # 两个三位数的差的绝对值
label_zfill = [int(s) for s in str(label).zfill(OUTPUT_LEN)] # zfill()返回指定长度的字符串,原字符串右端对齐,左端填充0
X[i] = feature
Y[i] = label
return {
'X': X / 10,
'Y': Y / 1000,
}
# 定义带有注意力的多层感知机模型
def build_model():
inputs = Input(shape=(TIME_STEP, ))
# 注意力层,计算输入中每个元素的注意力分布
attention_prob = Dense(TIME_STEP, activation='relu')(inputs)
# 根据计算的注意力分布对每个输入元素进行加权
attention_encoding = multiply([inputs, attention_prob]) # 对应位置元素相乘
print(attention_encoding)
encoding_a = Dense(TIME_STEP, activation='relu')(attention_encoding)
encoding_b = Dense(int(TIME_STEP / 2), activation='relu')(encoding_a)
output = Dense(1)(encoding_b) # 回归问题,不需要将预测结果进行分类转换,所以输出层不需要设置激活函数,直接输出数值
# 函数式模型
model = Model(inputs=[inputs], output=output)
att_model = Model(inputs=inputs, output=attention_prob)
print(attention_prob)
return model, att_model, inputs, output, attention_prob
model, att_model, inputs, outputs, attention_prob = build_model() # 调用函数,返回模型、输出值以及注意力分布
data = create_data(SAMPLE_NUM) # 调用函数生成样本
# 编译模型
model.compile(loss='MSE', optimizer='Adam', metrics=['mse'])
# 训练模型
model.fit([data['X']], data['Y'], epochs=50)
# 可视化注意力分布
att_dis = att_model.predict(data['X'])
avg_attention = np.mean(att_dis, axis=0)
avg_attention = avg_attention / np.sum(avg_attention, axis=0)
# 以柱状图的形式进行可视化
plt.bar(range(1, 7), avg_attention)
plt.show()
print(avg_attention)