前言
作为大数据家族中的重要一员,在大数据以及海量数据存储方面,hbase具有重要的地方,本篇将从java对hbase的操作上,进行详细的说明;
HBase 定义
HBase 是一种分布式、可扩展、支持海量数据存储的 NoSQL 数据库;
HBase 数据模型
从逻辑上来说,HBase 数据模型同关系型数据库很类似,数据存储在一张表中,有行有列。但从 HBase 的底层物理存储结构(K-V)来看,HBase 更像是一个 multi-dimensional map;
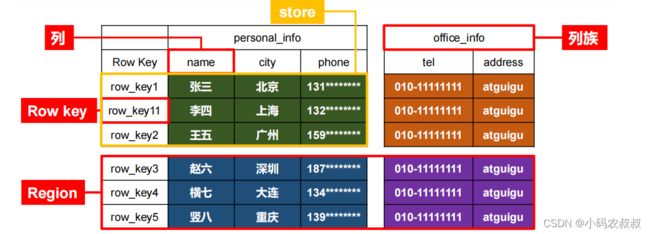
物理存储结构
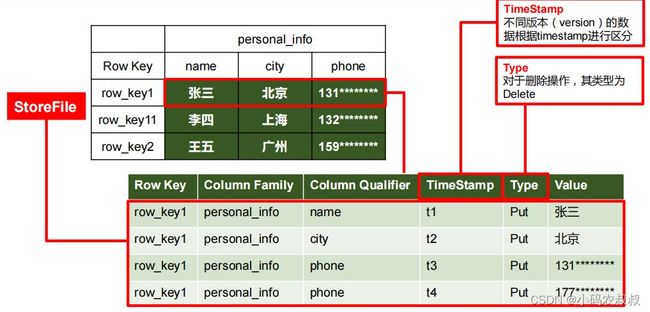
数据模型
hbase中有几个重要的与数据模型相关的术语,有必要做深入的了解;
1、Name Space
- 命名空间,类似于关系型数据库的 DatabBase 概念,每个命名空间下有多个表;
- 自带两个默认的命名空间,分别是 hbase 和 default,hbase 中存放的是 HBase 内置的表,default 表是用户默认使用的命名空间;
2、Region
- Region 类似于关系型数据库的表概念;
- HBase 定义表时只需要声明列族即可,不需要声明具体的列;
- 往 HBase 写入数据时,字段可以动态、按需指定;
因此,和关系型数据库相比,HBase 能够轻松应对字段变更的场景
3、Row
HBase 表中的每行数据都由一个 RowKey 和多个 Column(列)组成,数据是按照 RowKey的字典序存储,且查询数据时只能根据 RowKey 进行检索,所以RowKey 的设计十分重要;
4、Column
- HBase 中的每个列都由 Column Family(列族)和 Column Qualifier(列限定符)进行限定,例如 info:name,info:age;
- 建表时,只需指明列族,而列限定符无需预先定义;
5、Time Stamp
- 用于标识数据的不同版本(version);
- 每条数据写入时,如果不指定时间戳,系统会自动为其加上该字段,其值为写入HBase 的时间;
6、Cell
- 由{rowkey, column Family:column Qualifier, time Stamp} 唯一确定的单元;
- cell 中的数据是没有类型的,全部是字节码形式存储;
window环境下快速搭建 hbase运行环境
在小编之前的某一篇中,分享了基于centos7环境搭建hbase的单机运行环境,本篇为方便演示,在windows下快速搭建一个hbase的运行环境;
搭建步骤
1、官网下载安装包;
hadoop 3.1.0 以及 hbase 1.3.1

![]()
2、配置hadoop环境变量
![]()
并加入到系统path中,
![]()
3、修改 hbase-env.cmd配置文件
进入hbase解压后的onfig目录下,在 hbase-env.cmd 添加如下的配置,即设置hbase依赖的Java环境以及自身的配置目录;
set HBASE_MANAGES_ZK=false set JAVA_HOME=C:\Program Files\Java\jdk1.8.0_171 set HBASE_CLASSPATH=E:\bigData-tool\hbase-1.3.1\conf
4、修改hbase-site.xml 文件
进入hbase解压后的onfig目录下,将下面的配置文件添加到hbase-site.xml 配置中
hbase.rootdir file:///E:/bigData-tool/hbase-1.3.1/root hbase.tmp.dir E:/bigData-tool/hbase-1.3.1/tem hbase.zookeeper.quorum 127.0.0.1 hbase.zookeeper.property.dataDir E:/bigData-tool/hbase-1.3.1/zoo hbase.cluster.distributed false
5、启动hbase服务
进入bin目录下,在cmd窗口中执行下面的启动脚本启动


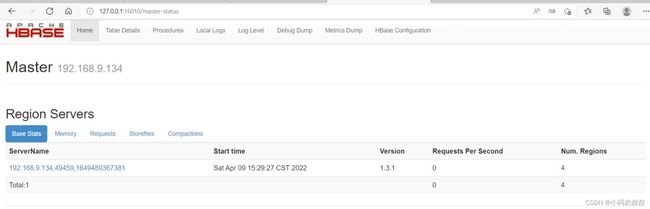
启动成功后,可以通过浏览器控制台查看hbase服务信息
6、hbase客户端测试
服务启动之后,在bin目录下,通过hbase提供的shell客户端操作命令测试下服务,进入bin目录下,直接cmd输入 hbase shell 即可

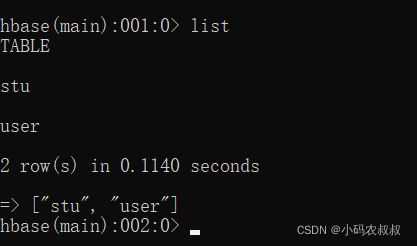
输入 list命令,查看下当前所有的表
到此为主,所有的准备工作就完成了,下面让我们通过hbase提供的Java客户端SDK来看看如何操作habse数据库吧;
Java API详细使用
1、导入客户端依赖
org.apache.hbase hbase-client 1.3.1 org.apache.hbase hbase 1.3.1
2、DDL相关操作
和ddl相关的包括,判断表是否存在,创建表,创建命名空间,删除表,删除命名空间;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.*;
import org.apache.hadoop.hbase.client.Admin;
import org.apache.hadoop.hbase.client.Connection;
import org.apache.hadoop.hbase.client.ConnectionFactory;
import org.apache.hadoop.hbase.client.HBaseAdmin;
import java.io.IOException;
public class DDlTest {
public static Connection connection = null;
public static Admin admin = null;
static {
Configuration conf = HBaseConfiguration.create();
//使用 HBaseConfiguration 的单例方法实例化
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "127.0.0.1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) {
}
/**
* 判断表是否存在
* @param tableName
* @return
* @throws Exception
*/
public static boolean isTableExistV1(String tableName) throws Exception {
HBaseConfiguration conf = new HBaseConfiguration();
conf.set("hbase.zookeeper.quorum", "127.0.0.1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
HBaseAdmin admin = new HBaseAdmin(conf);
boolean tableExists = admin.tableExists(tableName);
admin.close();
return tableExists;
}
/**
* 判断表是否存在
* @param tableName
* @return
* @throws Exception
*/
public static boolean isTableExistV2(String tableName) throws Exception {
Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "127.0.0.1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
Connection connection = ConnectionFactory.createConnection(conf);
Admin admin = connection.getAdmin();
boolean result = admin.tableExists(TableName.valueOf(tableName));
admin.close();
return result;
}
public static boolean isTableExistV3(String tableName) throws Exception {
boolean result = admin.tableExists(TableName.valueOf(tableName));
return result;
}
/**
* 创建表
* @param tableName 表名
* @param columnFamily 列簇名
* @throws Exception
*/
public static void createTable(String tableName, String... columnFamily) throws Exception {
if (columnFamily.length <= 0) {
System.out.println("请传入列簇信息");
}
//判断表是否存在
if (isTableExistV3(tableName)) {
System.out.println("表" + tableName + "已存在");
close();
return;
}
//创建表属性对象,表名需要转字节
HTableDescriptor descriptor = new HTableDescriptor(TableName.valueOf(tableName));
//创建多个列族
for (String cf : columnFamily) {
descriptor.addFamily(new HColumnDescriptor(cf));
}
//根据对表的配置,创建表
admin.createTable(descriptor);
System.out.println("表" + tableName + "创建成功!");
close();
}
/**
* 删除表
* @param tableName
*/
public static void dropTable(String tableName) throws Exception{
if (!isTableExistV3(tableName)) {
System.out.println(tableName + ": 不存在 !" );
return;
}
//1、下线表
admin.disableTable(TableName.valueOf(tableName));
//2、删除表
admin.deleteTable(TableName.valueOf(tableName));
System.out.println("删除表成功");
close();
}
/**
* 创建命名空间
* @param nameSpace
*/
public static void createNameSpace(String nameSpace){
if(nameSpace == null){
System.out.println(nameSpace + ": 不存在 !" );
return;
}
NamespaceDescriptor namespaceDescriptor = NamespaceDescriptor.create(nameSpace).build();
try {
admin.createNamespace(namespaceDescriptor);
} catch (NamespaceExistException e){
System.out.println("命名空间已存在");
}
catch (IOException e) {
e.printStackTrace();
}
System.out.println(nameSpace + ": 命名空间创建成功");
}
public static void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
我们选取其中一个判断表是否存在的方法做一下测试,观察控制台输出结果,其他的方法有兴趣的同学可以依次做测试即可;
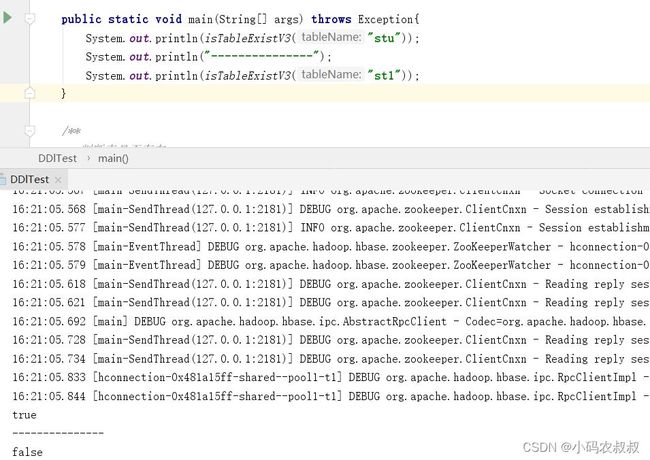
3、DML相关操作
和DML操作相关的主要包括表数据的增删改查,相对来说,在实际开发中,DML的操作,尤其是数据查询,可能使用的更加频繁,因此关于DML的操作务必要掌握;
package com.congge.test;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import java.io.IOException;
public class DMLTest {
public static Connection connection = null;
public static Admin admin = null;
static {
Configuration conf = HBaseConfiguration.create();
//使用 HBaseConfiguration 的单例方法实例化
conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "127.0.0.1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
e.printStackTrace();
}
}
public static void main(String[] args) throws Exception {
//System.out.println(isTableExistV1("user"));
//System.out.println(isTableExistV3("user"));
//createTable("stu","info1","info2");
//给表put数据
//putData("stu","1005","info1","name","wangwu");
//putData("stu","1003","info1","name","q7");
//获取表数据
//System.out.println("----------");
//getData("stu","1005","","");
//获取数据【scan的方式】
//getDataFromScan("stu");
//dropTable("stu");
//createNameSpace("0409");
deleteData("stu","1005","","");
close();
}
public static boolean isTableExistV3(String tableName) throws Exception {
boolean result = admin.tableExists(TableName.valueOf(tableName));
return result;
}
/**
*
* @param tableName 表名
* @param rowKey rowKey
* @param cf columnFamily
* @param cn columnName
* @param value columnValue
*/
public static void putData(String tableName,String rowKey,String cf,String cn,String value) throws Exception{
//1、获取表对象
Table table = connection.getTable(TableName.valueOf(tableName));
//2、拼接 put对象
Put put = new Put(Bytes.toBytes(rowKey));
//3、添加 字段信息 column
put.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn),Bytes.toBytes(value));
//4、执行数据插入
table.put(put);
System.out.println("数据插入成功");
}
/**
* 获取数据
* @param tableName
* @param rowKey
* @param cf
* @param cn
*/
public static void getData(String tableName,String rowKey,String cf,String cn) throws Exception{
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
//添加 cf【也可以不添加】
//get.addFamily(Bytes.toBytes(cf));
// 同时传入 cf 和 cn
if(StringUtils.isNotEmpty(cf) && StringUtils.isNotEmpty(cn)){
get.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn));
}
Result result = table.get(get);
//解析结果
Cell[] cells = result.rawCells();
for(Cell cell : cells){
System.out.println("cf : " + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("cn : " + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("value : " + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
/**
* 通过扫描的方式获取数据
* @param tableName
*/
public static void getDataFromScan(String tableName) throws Exception{
Table table = connection.getTable(TableName.valueOf(tableName));
//拿到扫描器对象
//Scan scan = new Scan();
//可以根据 rowkey继续获取【非必须】
Scan scan = new Scan(Bytes.toBytes("1001"),Bytes.toBytes("1003"));
ResultScanner resultScanner = table.getScanner(scan);
//结果解析
for(Result result : resultScanner){
Cell[] cells = result.rawCells();
for(Cell cell : cells){
System.out.println("rowkey : " + Bytes.toString(CellUtil.cloneRow(cell)));
System.out.println("cf : " + Bytes.toString(CellUtil.cloneFamily(cell)));
System.out.println("cn : " + Bytes.toString(CellUtil.cloneQualifier(cell)));
System.out.println("value : " + Bytes.toString(CellUtil.cloneValue(cell)));
}
}
}
/**
* 删除数据
* @param tableName
* @param rowKey
* @param cf
* @param cn
* @throws Exception
*/
public static void deleteData(String tableName,String rowKey,String cf,String cn) throws Exception{
Table table = connection.getTable(TableName.valueOf(tableName));
Delete delete = new Delete(Bytes.toBytes(rowKey));
//还可以传入列簇,以及字段名【非必须】
if(StringUtils.isNotEmpty(cf) && StringUtils.isNotEmpty(cn)){
delete.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn));
}
table.delete(delete);
System.out.println("数据删除成功");
}
public static void close() {
if (admin != null) {
try {
admin.close();
} catch (IOException e) {
e.printStackTrace();
}
}
if (connection != null) {
try {
connection.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
}
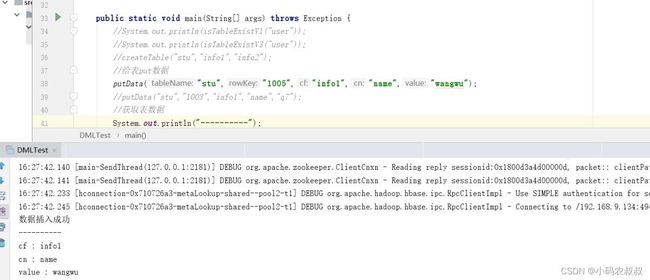
下面选择几个方法做一下测试,观察下效果如何,
插入数据与查询数据
其中关于查询数据,其API很灵活,可以只传入 rowKey,也可以进一步传入 列簇以及指定字段名称查询;
删除数据测试

更多的方法有兴趣的同学可以一一测试,限于篇幅,这里就不继续展开了;
Hbase与springboot整合
下面演示下在web应用中,与springboot的整合过程
1、导入springboot依赖
org.springframework.boot spring-boot-starter-web
2、添加一个工具类
使用该工具类,完成对hbase的一系列的增删查改
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.hbase.Cell;
import org.apache.hadoop.hbase.CellUtil;
import org.apache.hadoop.hbase.TableName;
import org.apache.hadoop.hbase.client.*;
import org.apache.hadoop.hbase.util.Bytes;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
import java.io.IOException;
import java.util.HashMap;
import java.util.Map;
public class HBaseService {
private Logger log = LoggerFactory.getLogger(HBaseService.class);
private Admin admin = null;
private Connection connection = null;
public HBaseService(Configuration conf) {
try {
connection = ConnectionFactory.createConnection(conf);
admin = connection.getAdmin();
} catch (IOException e) {
log.error("获取HBase连接失败!");
}
}
public Map getData(String tableName,String rowKey,String cf,String cn) throws Exception{
Map resultMap = new HashMap<>();
Table table = connection.getTable(TableName.valueOf(tableName));
Get get = new Get(Bytes.toBytes(rowKey));
//添加 cf【也可以不添加】
//get.addFamily(Bytes.toBytes(cf));
// 同时传入 cf 和 cn
//get.addColumn(Bytes.toBytes(cf),Bytes.toBytes(cn));
Result result = table.get(get);
//解析结果
Cell[] cells = result.rawCells();
for(Cell cell : cells){
String columnFamilyName = Bytes.toString(CellUtil.cloneFamily(cell));
System.out.println("columnFamilyName : " + columnFamilyName);
String colName = Bytes.toString(CellUtil.cloneQualifier(cell));
System.out.println("colName : " + colName);
String colValue = Bytes.toString(CellUtil.cloneValue(cell));
System.out.println("colValue : " + colValue);
resultMap.put(colName,colValue);
}
return resultMap;
}
}
将该类添加到spring容器中,方便后续其他类注入
import com.congge.service.HBaseService;
import org.apache.hadoop.hbase.HBaseConfiguration;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
@Configuration
public class HBaseConfig {
@Bean
public HBaseService getHbaseService() {
//设置临时的hadoop环境变量,之后程序会去这个目录下的\bin目录下找winutils.exe工具,windows连接hadoop时会用到
//System.setProperty("hadoop.home.dir", "D:\\Program Files\\Hadoop");
//执行此步时,会去resources目录下找相应的配置文件,例如hbase-site.xml
org.apache.hadoop.conf.Configuration conf = HBaseConfiguration.create();
conf.set("hbase.zookeeper.quorum", "127.0.0.1");
conf.set("hbase.zookeeper.property.clientPort", "2181");
return new HBaseService(conf);
}
}
注意,在实际开发中,连接zk的信息可以通过外部配置文件读取进来;
3、编写一个测试使用的controller类
import com.congge.service.HBaseService;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.GetMapping;
import org.springframework.web.bind.annotation.RestController;
import java.util.Map;
@RestController
public class HbaseController {
@Autowired
private HBaseService hBaseService;
@GetMapping("/getData")
public Map getData(String tableName, String rowKey, String cf, String cn) throws Exception{
return hBaseService.getData(tableName,rowKey,cf,cn);
}
}
在该类中,有一个获取单行数据的方法,启动工程,浏览器访问接口:
http://localhost:8087/getData?tableName=stu&rowKey=1002

本篇详细总结了hbase的Java客户端的使用,在实际开发过程中,还需要结合自身的情况做更加细致的整合与优化,本篇到此结束,感谢观看!
到此这篇关于springboot 整合hbase的示例代码的文章就介绍到这了,更多相关springboot 整合hbase内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!