原文链接:http://tecdat.cn/?p=26177
GBDT梯度提升模型由多个决策树组成。预测模型的目的是根据输入预测目标值。GBDT使用 已知目标值的_训练数据_来创建模型 ,然后可以将该模型应用于目标未知的观测。如果预测很好地拟合了新数据,则该模型可以 很好地 _推广_。良好的概括是预测任务的主要目标。预测模型可能很好地拟合了训练数据,但泛化性很差。
决策树 是一种预测模型已在统计和人工智能社区自主开发。GRADBOOST通过拟合一组加性树来创建预测模型。
GBDT
梯度提升模型的常见用法是预测抵押贷款申请人是否会拖欠贷款。
本示例使用房屋净值数据表来构建梯度提升模型,该模型用于对数据进行评分,并可用于对有关新贷款申请人的数据进行评分。
表1:房屋净值数据表中的变量

proc print data=myhmeq(obs=10); run;显示了的前10个观察值。
图1:部分数据

图2:显示“模型信息”表。该表显示了前六行中训练参数的值,以及有关增强模型中树的一些基本信息。
图2:模型信息
GRADBOOST
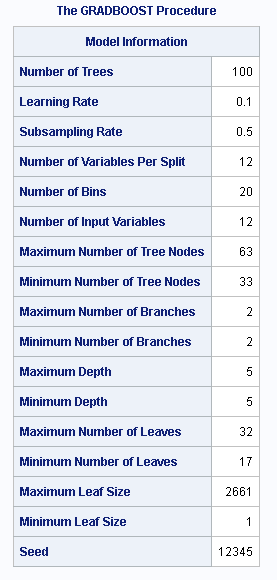
图3显示“观察值数量”表,该表显示读取和使用了多少观察值。
图3:观察数

图4 显示了变量重要性的估计。该图中的行按重要性度量排序。通过对这些数据拟合增强模型得出的结论是, DebtInc 贷款违约率是最重要的预测指标。
图4:变量重要性

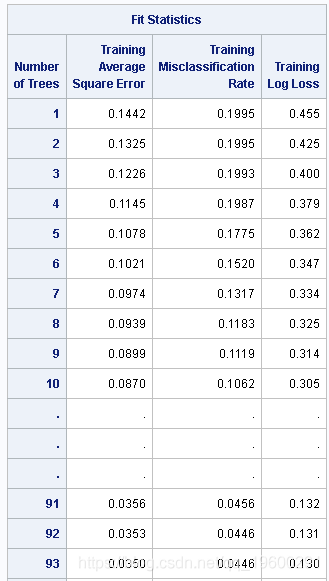
图5 显示了拟合统计量的前10个和最后10个观察值。GRADBOOST以树为单位计算拟合统计信息。随着树数量的增加,拟合统计通常通常会先提高(减少),然后趋于平稳并在很小的范围内波动。
图5:拟合统计
示例:使用先前的提升模型对新数据评分
本示例说明了如何保存模型表,然后再使用模型表对数据表进行评分。
数据集来自一个研究,是否进行分类的电子邮件是垃圾电子邮件(编码为1)或否(编码为0)。数据集包含4,601个观测值和59个变量。因变量是电子邮件是否被视为垃圾邮件的二进制指示符。共有57个预测变量,用于记录电子邮件中某些常用单词和字符的频率以及大写字母的连续序列的长度。
训练一个提升模型并对训练数据表评分。
该表显示了统计信息。
输出1.1:拟合统计信息,在运行时拟合

以下语句使用以前保存的模型对新数据评分:
proc gradboost data=mil inmodel=mycst_model;
output out=mycas.score_later;
ods output FitStatistics=fit_later;
run;如果目标存在于新的得分数据表中,则会看到得分数据的统计信息。在此示例中,计分的数据与训练数据相同。
输出12.1.2:拟合统计,以后拟合

此示例说明,GRADBOOST过程可以使用先前保存的增强模型对输入数据表进行评分,该模型 在先前的过程运行中保存 。如果要正确对新数据表评分,则一定不要修改该表 gradboost_model,因为这样做可能会使构造的提升模型无效。与对新数据进行任何评分一样,必须存在在模型创建中使用的变量,以便为新表评分。
示例:迁移学习
此示例说明了迁移学习。迁移学习通过辅助数据来增强训练数据,并尝试降低不代表原始训练数据的观察结果的影响。原始训练数据通常来自 难以获得数据的 _目标_人群。此示例在不使用迁移学习的情况下运行了GRADBOOST两次:一次包含所有数据,一次不包含辅助观测。所有模型均使用目标人群的数据(不是训练数据的一部分)进行评估。包含迁移学习的模型应该比没有迁移学习的模型更合适,尽管不如去除辅助观测的模型好。
接下来的DATA步骤将生成三个数据集:一个用于训练(包括辅助观测),一个没有训练对象的数据集,以及第三个具有训练结果的数据集。
data main mylien myest;
array x(2) x1 - x2;
do i = 1 to n;
do j = 1 to 2;
x(j) = rand('normal', mu);
end;
select(datarole);
when(-1) output m.test;
when(0,1) output mytrain mynoAlien;
when(2) output myc.train;
end;
if i = nhalf then do;
mu = -mu;
y = -y;首先训练模型,然后再次将模型应用于测试数据和输出拟合统计。当所有观测值的该变量均为零时,将不进行迁移学习。
选项将 向下加权延迟到树11。
proc gradboost data=myst inmodel=mycodel;
output out=my.score;
ods output FitStatistics=&outfit.;
run;将三个模型的平均平方误差合并到一个表中。
通过模型中树的数量绘制每个模型的平均平方误差:
scatterplot y=train_ase
x=trees / markerattrs=(color=blue)
name='with'表明,与迁移学习相比,迁移学习的拟合度更好,尽管不如从数据中删除所有辅助观测值时的拟合度更好。传递学习的拟合与前10棵树没有拟合的情况相同,因为在此示例中,直到树11才开始减权。
输出2.1:三种模型的ASE与树数的比较


最受欢迎的见解
3.python中使用scikit-learn和pandas决策树
7.用机器学习识别不断变化的股市状况——隐马尔可夫模型的应用