PyTorch学习笔记(1)nn.Sequential、nn.Conv2d、nn.BatchNorm2d、nn.ReLU和nn.MaxPool2d
文章目录
- 一、nn.Sequential
- 二、nn.Conv2d
- 三、nn.BatchNorm2d
- 四、nn.ReLU
- 五、nn.MaxPool2d
一、nn.Sequential
torch.nn.Sequential是一个Sequential容器,模块将按照构造函数中传递的顺序添加到模块中。
使用方式:
- 一个有序的容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,
- 以神经网络模块为元素的有序字典(OrderedDict)也可以作为传入参数。
- 也可以利用add_module函数将特定的神经网络模块插入到计算图中。
官方给出案例(上面所提的方式1 和 方式2的列子):
# Sequential使用实例
model = nn.Sequential(
nn.Conv2d(1,20,5),
nn.ReLU(),
nn.Conv2d(20,64,5),
nn.ReLU()
)
# Sequential with OrderedDict使用实例
model = nn.Sequential(OrderedDict([
('conv1', nn.Conv2d(1,20,5)),
('relu1', nn.ReLU()),
('conv2', nn.Conv2d(20,64,5)),
('relu2', nn.ReLU())
]))
以上两种形式为一致。一种自动命名,一种指定名字。
验证:
需要在pytorch环境下运行。
先添加:
import torch.nn as nn
from collections import OrderedDict
打印模型输出:
print(model)
---------------------------------------------------------
Sequential(
(0): Conv2d(1, 20, kernel_size=(5, 5), stride=(1, 1))
(1): ReLU()
(2): Conv2d(20, 64, kernel_size=(5, 5), stride=(1, 1))
(3): ReLU()
)
使用torch.nn.Sequential可以快速的搭建一个神经网络
为比较,先用普通方法搭建一个神经网络来对比
class Net(torch.nn.Module):
def __init__(self, n_feature, n_hidden, n_output):
super(Net, self).__init__()
self.hidden = torch.nn.Linear(n_feature, n_hidden)
self.predict = torch.nn.Linear(n_hidden, n_output)
def forward(self, x):
x = F.relu(self.hidden(x))
x = self.predict(x)
return x
net1 = Net(1, 10, 1)
上面class继承了一个torch中的神经网络结构, 然后对其进行了修改;
接下来我们来使用torch.nn.Sequential来快速搭建一个神经网络。
net2 = torch.nn.Sequential(
torch.nn.Linear(1, 10),
torch.nn.ReLU(),
torch.nn.Linear(10, 1)
)
打印输出上面2个神经网络数据,查看区别:
print(net1)
---------------------------------------------------------
Net (
(hidden): Linear (1 -> 10)
(predict): Linear (10 -> 1)
)
---------------------------------------------------------
print(net2)
---------------------------------------------------------
Sequential (
(0): Linear (1 -> 10)
(1): ReLU ()
(2): Linear (10 -> 1)
)
---------------------------------------------------------
我们可以发现,使用torch.nn.Sequential会自动加入激励函数, 但是 net1 中, 激励函数实际上是在 forward() 功能中才被调用的.
torch.nn.Sequential与torch.nn.Module区别与选择
- 使用torch.nn.Module,我们可以根据自己的需求改变传播过程,如RNN等
- 如果你需要快速构建或者不需要过多的过程,直接使用torch.nn.Sequential即可。
- nn.Sequentialt使对于加入其中的子模块在forward中可以通过循环实现调用
- Module 里面也可以使用 Sequential,同时 Module 非常灵活
二、nn.Conv2d
源自:https://pytorch.org/docs/1.2.0/nn.html#conv2d
nn.Conv2d是二维卷积方法,相对应的还有一维卷积方法nn.Conv1d,常用于文本数据的处理,而nn.Conv2d一般用于二维图像。
接口定义:
class torch.nn.Conv2d(in_channels, out_channels, kernel_size, stride=1, padding=0, dilation=1, groups=1, bias=True,padding_mode='zeros')
参数解释:
- in_channels(int):输入图像的channel(通道数),例如,RGB图像通道数为3
- out_channels(int): 输出图像(特征层)的channel
- kernel_size(int or tuple):kernel(卷积核)的大小,kennel_size=5,意味着卷积大小(5,5)/5×5,kennel_size=(2,3),意味着卷积大小(2,3)/2×3 ,即非正方形卷积
- stride(int or tuple,optional): 卷积的步长,默认为1,stride=2,意味着步长上下左右扫描皆为2, stride=(2,3),左右扫描步长为2、上下为3
- padding(int or tuple,optional):四周pad的大小,默认为0,在卷积之前补0,四周都补0,
- dilation(int or tuple,optional): kernel元素间的距离,默认为1(dilation翻译为扩张,有时候也称为“空洞”1)
- groups(int ,optional):将原始输入channel划分成的组数,默认为1
- bias(bool,optional):如果是True,则输出的bias可学,默认为True。卷积后是否加偏移量
- padding_mode:默认为“zeros”,填充0
channel:通道数。
一般的RGB图片,channels 数量是 3 (红、绿、蓝);而单色/灰度图片,channels 数量是 1。
channels 一般分为三种:
- 最初输入的图片样本的 channels ,取决于图片类型,比如RGB;
- 卷积操作完成后输出的 out_channels ,取决于卷积核的数量。此时的 out_channels 也会作为下一次卷积时的卷积核的 in_channels;
- 卷积核中的 in_channels ,刚刚2中已经说了,就是上一次卷积的 out_channels ,如果是第一次做卷积,就是1中样本图片的 channels
dilation:空洞卷积,控制 kernel 点之间的空间距离,实际在上采样上有利用(在FCN、U-net等网络结构中),看下图有助于理解


groups:分组卷积
Convolution 层的参数中有一个group参数,其意思是将对应的输入通道与输出通道数进行分组, 默认值为1, 也就是说默认输出输入的所有通道各为一组。
比如:输入数据大小为90x100x100x32,通道数32,要经过一个3x3x48的卷积,group默认是1,就是全连接的卷积层。
如果group是2,那么对应要将输入的32个通道分成2个16的通道,将输出的48个通道分成2个24的通道。对输出的2个24的通道,第一个24通道与输入的第一个16通道进行全卷积,第二个24通道与输入的第二个16通道进行全卷积。
极端情况下,输入输出通道数相同,比如为24,group大小也为24,那么每个输出卷积核,只与输入的对应的通道进行卷积。
三、nn.BatchNorm2d
源自:https://pytorch.org/docs/1.2.0/nn.html#batchnorm2d
BatchNorm(批规范化)主要是为了加速神经网络的收敛过程以及提高训练过程中的稳定性。通常用于解决多层神经网络中间层的协方差偏移(Internal Covariate Shift)问题,类似于网络输入进行零均值化和方差归一化的操作,不过是在中间层的输入中操作而已。使一批(Batch)feature map满足均值为0,方差为1的分布规律。这样不仅数据分布一致,而且避免发生梯度消失。
接口定义:
torch.nn.BatchNorm2d(num_features, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
参数解释:
- num_features: 一般输入参数为batch_size num_features (height*width),即为其中特征的数量,为输入BN层的通道数;
- eps: 分母中添加的一个值,目的是为了计算的稳定性,默认为:1e-05,避免分母为0;为公式中的 ε \ ε\, ε
- momentum:动态均值和动态方差所使用的动量。默认为0.1。一个用于运行过程中均值和方差的一个估计参数(我的理解是一个稳定系数,类似于SGD中的momentum的系数);
- affine: 当设为true时,会给定可以学习的系数矩阵 γ \ γ\, γ和 β \ β\, β。布尔值,当设为true,给该层添加可学习的仿射变换参数。
- track_running_stats:布尔值,当设为true,记录训练过程中的均值和方差;
公式:
y = γ × ( x − E [ x ] V a r [ x ] + ε ) + β \ y=γ×({x-E[x] \over \sqrt{Var[x]+ε} \quad })+β\, y=γ×(Var[x]+εx−E[x])+β
( γ \ γ\, γ 和 β \ β\, β在反向传播过程中训练得到,是对像素在BN的基础上进行的调整,具体数值是模型学习出来的,初始化 γ = 1 \ γ=1\, γ=1用来调整方差, β = 0 \ β=0\, β=0用来调整均值。
用于抵消部分标准化带来的影响,因为有时候可能标准化了不好,这个时候这两个变量就有足够的弹性来学习修整这种标准化了。)
在训练时,该层计算每次输入的均值和方差,进行移动平均。移动平均momentum 默认的动量值为0.1
在验证时,训练求得的均值和方差将用于标准化验证数据。
参数详解:
在BN操作中,最重要的无非是这四个式子:
- 输入: B = ( x 1 , x 2 , . . . , x m ) \ Β = (x_1,x_2,...,x_m )\, B=(x1,x2,...,xm),为m个样本组成的一个batch数据
- 输出:需要学习到的是 γ \ γ\, γ和 β \ β\, β,在框架中一般表述成weight和bias
更新过程:

注意到这里的最后一步也称之为仿射(affine),引入这一步的目的主要是设计一个通道,使得输出output至少能够回到输入input的状态(当 γ = 1 \ γ=1\, γ=1, β = 0 \ β=0\, β=0时)使得BN的引入至少不至于降低模型的表现,这是深度网络设计的一个套路。
一般来说pytorch中的模型都是继承nn.Module类的,都有一个属性trainning指定是否是训练状态,训练状态与否将会影响到某些层的参数是否是固定的,比如BN层或者Dropout层。通常用model.train()指定当前模型model为训练状态,model.eval()指定当前模型为测试/验证状态。
同时,BN的API中有几个参数需要比较关心的,一个是affine指定是否需要仿射,还有个是track_running_stats指定是否跟踪当前batch的统计特性。容易出现问题也正好是这三个参数:trainning,affine,track_running_stats。
- 其中的affine指定是否需要仿射,也就是是否需要上面算式的第四个,如果affine=False,则 γ = 1 \ γ=1\, γ=1, β = 0 \ β=0\, β=0,并且不能学习被更新。一般都会设置成affine=True
- trainning和track_running_stats,track_running_stats=True表示跟踪整个训练过程中的batch的统计特性,得到方差和均值,而不只是仅仅依赖与当前输入的batch的统计特性。相反的,如果track_running_stats=False那么就只是计算当前输入的batch的统计特性中的均值和方差了。当在推理阶段的时候,如果track_running_stats=False,此时如果batch_size比较小,那么其统计特性就会和全局统计特性有着较大偏差,可能导致糟糕的效果。
神经网络中有各种归一化算法:Batch Normalization (BN)、Layer Normalization (LN)、Instance Normalization (IN)、Group Normalization (GN)。
从公式看它们都差不多:无非是减去均值,除以标准差,再施以线性映射。
y = γ ( x − μ ( x ) σ ( x ) ) + β \ y=γ({x-μ(x) \overσ (x)})+β\, y=γ(σ(x)x−μ(x))+β这些归一化算法的主要区别在于操作的 feature map 维度不同。
- BatchNorm(BN):batch方向做归一化,算NHW的均值,对小batchsize效果不好;BN主要缺点是对batchsize的大小比较敏感,由于每次计算均值和方差是在一个batch上,所以如果batchsize太小,则计算的均值、方差不足以代表整个数据分布
- LayerNorm (LN):channel方向做归一化,算CHW的均值,主要对RNN作用明显;
- InstanceNorm(IN):一个channel内做归一化,算H*W的均值,用在风格化迁移;因为在图像风格化中,生成结果主要依赖于某个图像实例,所以对整个batch归一化不适合图像风格化中,因而对HW做归一化。可以加速模型收敛,并且保持每个图像实例之间的独立。
- GroupNorm(GN):将channel方向分group,然后每个group内做归一化,算(C//G)HW的均值;这样与batchsize无关,不受其约束。
- SwitchableNorm是将BN、LN、IN结合,赋予权重,让网络自己去学习归一化层应该使用什么方法。
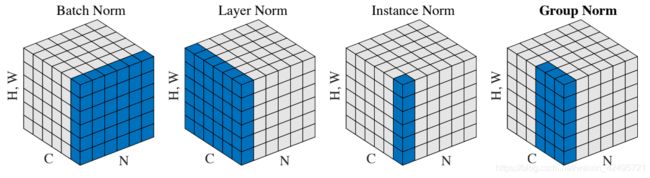
Batch Normalization (BN) 是最早出现的,也通常是效果最好的归一化方式。feature map: x ∈ R N × C × H × W . \ x∈R^{N×C×H×W} \,. x∈RN×C×H×W.包含 N 个样本,每个样本通道数为 C,高为 H,宽为 W。对其求均值和方差时,将在 N、H、W上操作,而保留通道 C 的维度。
具体来说,就是把第1个样本的第1个通道,加上第2个样本第1个通道 … 加上第 N 个样本第1个通道,求平均,得到通道 1 的均值(注意是除以 N×H×W 而不是单纯除以 N,最后得到的是一个代表这个 batch 第1个通道平均值的数字,而不是一个 H×W 的矩阵)。求通道 1 的方差也是同理。对所有通道都施加一遍这个操作,就得到了所有通道的均值和方差。具体公式为:

这里有个特别好的比喻,便于理解:
如果把 x ∈ R N × C × H × W . \ x∈R^{N×C×H×W} \,. x∈RN×C×H×W.类比为一摞书,这摞书总共有 N 本,每本有 C 页,每页有 H 行,每行 W 个字符。BN 求均值时,相当于把这些书按页码一一对应地加起来(例如第1本书第36页,第2本书第36页…),再除以每个页码下的字符总数: N × H × W . \ N×H×W \,. N×H×W.,因此可以把 BN 看成求“平均书”的操作(注意这个“平均书”每页只有一个字),求标准差时也是同理。
详细区别和参数细节建议参考:知乎,CSDN。
四、nn.ReLU
源自:https://pytorch.org/docs/1.2.0/nn.html#relu
nn.ReLU() 是封装好的类,继承nn.Module
接口定义:
class torch.nn.ReLU(inplace: bool = False)
参数定义:
inplace: can optionally do the operation in=plase. Default: False
inplace:默认为false(选择是否进行覆盖运算,意思是:是否将得到的值计算得到的值覆盖之前的值)
inplace=True,会改变输入数据,inplace=False,不会改变输入数据,只会产生新的输出
注:产生的计算结果不会有影响。利用in-place计算可以节省内(显)存,同时还可以省去反复申请和释放内存的时间。但是会对原变量覆盖,只要不带来错误就用。
对于ReLU非线性激励函数,其公式为:
R e L U ( x ) = m a x ( 0 , x ) \ ReLU(x)=max(0, x)\, ReLU(x)=max(0,x)
nn.ReLU() 与 F.relu()的区别
nn.ReLU() :
import torch.nn as nn
'''
nn.RuLU()
F.relu():
import torch.nn.functional as F
'''
out = F.relu(input)
其实这两种方法都是使用relu激活,只是使用的场景不一样,F.relu()是函数调用,一般使用在foreward函数里。而nn.ReLU()是模块调用,一般在定义网络层的时候使用,作为一个层结构,必须添加到nn.Module容器中才能使用。
1.为什么引入非线性激励函数?
如果不适用激励函数,那么在这种情况下每一层的输出都是上层输入的线性函数,很容易验证,无论你神经网络有多少层,输出都是输入的线性组合,与没有隐藏层效果相当,这种情况就是最原始的感知机(perceptron)了。正因为上面的原因,我们决定引入非线性函数作为激励函数,这样深层神经网络就有意义了,不再是输入的线性组合,可以逼近任意函数,最早的想法是用sigmoid函数或者tanh函数,输出有界,很容易充当下一层的输入
2.为什么引入Relu?
- 采用sigmoid等函数,算激活函数时候(指数运算),计算量大,反向传播求误差梯度时,求导涉及除法,计算量相当大,而采用Relu激活函数,整个过程的计算量节省很多。
- 对于深层网络,sigmoid函数反向传播时,很容易就出现梯度消失的情况(在sigmoid函数接近饱和区时,变换太缓慢,导数趋于0,这种情况会造成信息丢失),从而无法完成深层网络的训练。
- Relu会使一部分神经元的输出为0,这样就造成了网络的稀疏性,并且减少了参数的相互依存关系,缓解了过拟合问题的发生。
其实,relu函数的作用就是增加了神经网络各层之间的非线性关系,否则,如果没有激活函数,层与层之间是简单的线性关系,每层都相当于矩阵相乘,这样怎么能够完成我们需要神经网络完成的复杂任务,
五、nn.MaxPool2d
源自:https://pytorch.org/docs/1.2.0/nn.html#torch.nn.MaxPool2d
接口定义:
class torch.nn.MaxPool2d(kernel_size, stride=None, padding=0, dilation=1, return_indices=False, ceil_mode=False)
参数定义:
- kernel_size(int or tuple):取最大值(max pooling)的窗口大小,如果是一个值单int,高度和宽度都使用相同的值;如果是tuple两个整数,第一个是height ,第二个是height 。(最大池化的方法就是取这个窗口覆盖元素中的最大值。)
- stride(int or tuple, optional):窗口移动的步长。默认值为kernel_size(上一个参数我们确定了滑动窗口的大小,现在我们来确定这个窗口如何进行滑动。如果不指定这个参数,那么默认步长跟最大池化窗口大小一致。如果指定了参数,那么将按照我们指定的参数进行滑动。)
- padding (int or tuple, optional):输入的每一条边补充0的层数
- dilation (int or tuple, optional):控制窗口中元素步长的参数
- return_indices:如果为True,会返回输出最大值的位置索引,对于上采样(torch.nn.MaxUnpool2d)操作会有帮助。
- ceil_mode: 如果等于True,计算输出信号大小的时候,会使用向上取整,代替默认的向下取整的操作。(关于 ceil_mode 的详解:建议参考CSDN)
如果padding 不是0,会在输入的每一边添加相应数目0,如padding=1,则在每一边分别补0,其实最后的结果补出来是bias
最大池化的方法示意图:
