本篇整理自 3.19 日 “Large Kernel Makes CNN Great Again” 专题 Meetup 中《MegEngine 大 Kernel 卷积工程优化实践》分享。作者:王彪 | 旷视 MegEngine 异构计算组负责人。
视频回顾 01:10:55 直达
从卷积到矩阵乘
矩阵乘(GEMM)具有计算密度大和易并行等优良特点,传统领域例如芯片产业和高性能计算领域往往将 GEMM 作为 benchmark 并已经将其优化到接近硬件理论峰值。 为了获得更好的性能收益,im2col 算法将 GEMM 带进了卷积神经网络的工程优化领域。Implicit GEMM 算法进一步解决了 im2col 固有的多余显存占用和冗余的前后处理问题,这在存储受限的硬件例如 GPU 上尤为重要,使得 GEMM 在卷积优化中的重要性进一步提升。加之硬件厂商也开始越来越多的对矩阵乘提供硬件支持,例如各种 MMA 指令和 TensorCore 的加入,这些原因共同促使现有很多优化算法库已经将 im2col/Implicit GEMM 作为其默认的卷积优化方案。
im2col 算法
本文中假设卷积的输入 shape 为 (n, ic, ih, iw),kernel 为 (oc, ic, kh, kw),output 为 (n, oc, oh, ow)。im2col 算法的过程如下图所示,简单的将 kernel reshape 一下就得到了一个行 M = oc,列 K = ic*kh*kw 的矩阵记作矩阵 A。用 kernel 大小的立方体在 input 上做滑窗,每次将一个小立方体的数据按照 chw 的顺序展开成一列。从上到下,从左到右滑完整个 input 之后将会得到一个行 K = ic*kh*kw,列 N = n*oh*ow 的矩阵记作矩阵 B。此时我们计算 GEMM(A, B) 就可以得到卷积的结果矩阵 C,其行 M = oc,列 N = n*oh*ow。

在 GEMM 的计算过程中,根据 m, n 和 k 三个维度下标可以推导出数据在卷积的输入输出以及 kernel 中的下标。所以可以将 im2col 和 GEMM 两个过程融合在一起从而达到降低显存占用和性能加速的效果,这其实就是 Implicit GEMM 的原理。本文不过多介绍,感兴趣的可以阅读之前的技术文章。
Implicit Batched GEMM
上一篇文章主要介绍了 MegEngine 大 kernel depthwise 卷积优化的背景和动机,本篇文章将介绍具体的优化思路和工程实践。借助 im2col/Implicit GEMM 算法,GEMM 在传统的针对 dense 卷积的优化中表现出来了优良的性能。所以针对大 kernel depthwise 卷积也应该尝试使用 GEMM 实现。如前文分析,直接使用和 dense 卷积一样的方法将 im2col 算法应用到大 kernel depthwise 卷积将会产生一个 Batched GEMV,这很难达到硬件浮点计算峰值。显然为了将 GEMM 应用在大 kernel depthwise 卷积上,我们应该转变一下思维。如下图所示,dense 卷积一般用 kernel 去卷 input 并算得 output,但当 kernel size 很大甚至可能比 input 还大时,此时其实应该用 input 去卷 kernel 并算得 output。
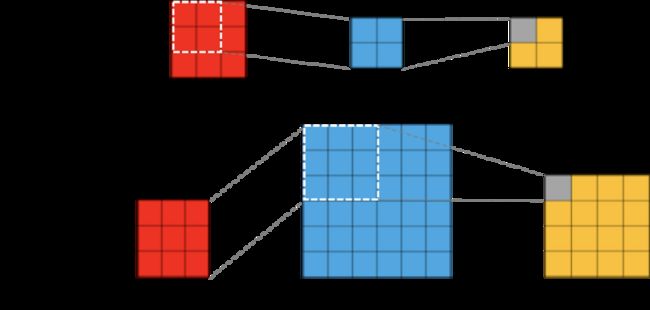
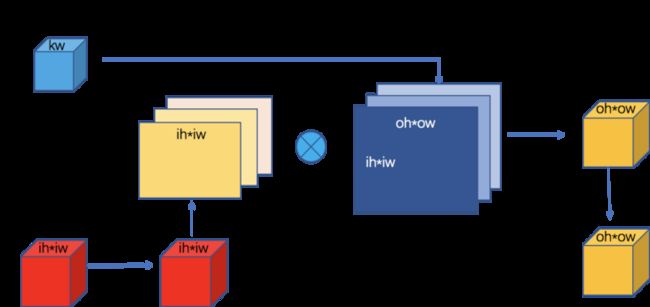
回想一下 dense 卷积用 kernel 去卷 input,对 input 做 im2col 变换。现在大 kernel depthwise 卷积用 input 去卷 kernel,所以此时应该对 kernel 做 im2col 变换。算法过程没有本质区别,只需要在 im2col 中将 kernel 看做 input,将 input 看做 kernel 即可。由于 depthwise 卷积是逐通道做卷积的,因此 im2col 变换也需要逐通道做。如下图所示,每个通道变换之后都会产生一个 M = n, N = oh*ow, K = ih*iw 的 GEMM。根据上一篇文章的分析,Batched GEMM 相比于 Batched GEMV 更容易打满硬件设备的浮点计算峰值。
CUTLASS 是 NVIDIA 的开源模板库,它旨在提供一种用较小的成本写出一个性能不是那么差的 GEMM 的能力。CUTLASS 内置了针对 GEMM 的 meta schedule,能够让计算尽量掩盖访存延迟从而达到不错的性能。旷视早在 CUTLASS 官方开源其卷积实现之前就基于 CUTLASS 做出了自己的卷积实现,时至今日已经打磨出了一个更适合内部业务的旷视版 CUTLASS。此处的 Implicit Batched GEMM 也是基于旷视版 CUTLASS 实现的,代码已经随 MegEngine v1.8.2 开源出来了,实现细节就不过多介绍了。如下图的实验数据显示随着 kernel size 的增加,Implicit Batched GEMM 的性能大致是呈线性增长的,部分情况下可以逼近理论峰值。

Implicit Batched GEMM 的优点一方面是可以复用成熟的 GEMM 优化思路和基础设施,还可以方便使用 TensorCore 进行加速;另一方面如果在推理的时候不要求可变 shape 的话,对 kernel 的 im2col 变换可以提前算好进一步加速。当然它的缺点也很明显,比如小 batch 情况下依然会退化成 Bacthed GEMV。如果用 M*N*K*2 来近似 GEMM 的计算量的话,不难发现 Implicit Batched GEMM 的计算量相比 dense 卷积转成的 GEMM 增大了 $\frac{ih*iw}{kh*kw}$ 倍,这意味着 Implicit Batched GEMM 在 input 显著大于 kernel size 时性能不佳。如下图所示的实验结果也显示着当 input 大于 kernel size 时,随着 input 的增加 Implicit Batched GEMM 的性能有明显下滑。需要一种新的优化方法来迎合下游如检测、分割等业务里的大 input size 的需求,这种方法在小 batch size 或者大输入下的性能表现也要足够好。

Direct Conv
由于大 kernel depthwise 卷积的计算密度比较高,所以其实简单实现一版性能基本都能达到峰值性能的 70%-80%。Driect Conv 的写法其实有很多,这里只提供一种写法思路供参考。如下图所示,为了更好的利用 CUDA 的多级存储以最大利用带宽,Direct Conv 采用多级分块策略。每个 Thread Block 负责计算 output 的一个分块,然后每个 Warp 对 Thread Block Tile 按行进一步做分块。为了适应更大的 kernel size,我们在 Thread level 上不仅针对 output 做了分块,还对 kernel 做了分块。

简单举个例子介绍 Thread level 的分块策略。假设 Thread Block size 是 128,Thread 被组织成 32×4 的形式,每一行的 4 个线程负责计算 output 的一行。将 kernel 也切分成四列,每一行的 4 个线程分别负责读取 kernel 的一列。如下图所示,Thread 0 读取 kernel 的第 0 列和 input 的第 0-3 列,计算得到 4 个 output;Thread 1 读取 kernel 的第 2 列和 input 的第 1-4 列,计算得到 4 个 output。Thread 2 和 Thread 3 以此类推。
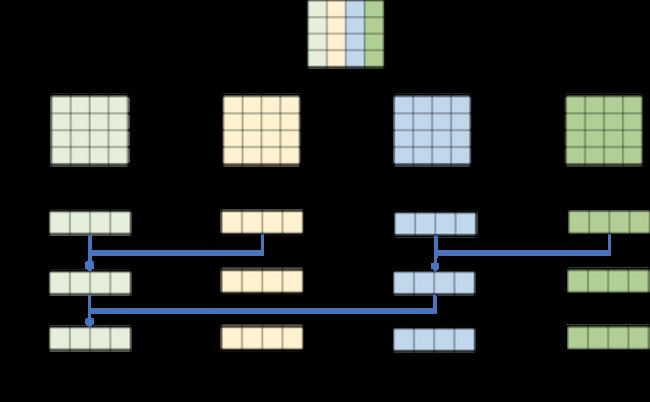
由于对 kernel 做了分块,所以每行的 4 个线程计算完毕之后每个 Thread 持有的是 output 的部分和,需要将 4 个线程各自的结果规约到一起才是最终结果。此处借助了 Warp Shuffle API__shuffle_xor_sync,它实现了一种蝶形规约,其原理如下图所示。由于只需要将每 4 个线程的结果规约到一起就行了,所以只需要进行 2 次 __shuffle_xor_sync 即可,最后将 outupt 写回。

实验数据显示在 input 大小为 48 时 Direct Conv 的性能已经略高于 Implicit Batched GEMM 了,intput 为 64 时 Direct Conv 的性能会显著高于 Implicit Batched GEMM。得益于 MegEngine 的算子自动选择机制,用户使用的时候不用指定具体的实现方式,MegEngine 会自动选择最佳实现。

运行时间
为了衡量算子的优劣,前面的实验都是从算子绝对性能和硬件理论峰值相比的角度设计的。为了让用户有更直观的感受,我们同样测试了大 kernel depthwise 卷积的运行时间。实验环境为 2080Ti @ cuda10.1 + cudnn7.6.3,所用的数据类型为 fp32, batch size 为 64,channel 为 384,用 24 个 layer 进行前向和反向计算。从下图可见 MegEngine 比 PyTorch(with cudnn) 最高快 10 倍以上,优化后的 MegEngine 在 31×31 的 kernel size 上和 PyTorch 9×9 的训练时间相当。

如下图所示,只测试一个 layer 的前向推理,其他的配置和训练保持一致。经过优化后的 MegEngine 比 cudnn 最高快 8 倍多,并且 fp16 相比 fp32 也有 2 倍多加速,欢迎尝试一下混合精度训练。代码已经随着 MegEngine v1.8.2 开源,使用 v1.9 (即将发布)效果更佳~

附
GitHub:MegEngine 天元 (欢迎 star~
欢迎加入 MegEngine 技术交流 QQ 群:1029741705