yolov5分割_一文读懂YOLO V5 与 YOLO V4

YOLO之父Joseph Redmon在今年年初宣布退出计算机视觉的研究的时候,很多人都以为目标检测神器YOLO系列就此终结。然而在4月23日,继任者YOLO V4却悄无声息地来了。Alexey Bochkovskiy发表了一篇名为YOLOV4: Optimal Speed and Accuracy of Object Detection的文章。YOLO V4是YOLO系列一个重大的更新,其在COCO数据集上的平均精度(AP)和帧率精度(FPS)分别提高了10% 和12%,并得到了Joseph Redmon的官方认可,被认为是当前最强的实时对象检测模型之一。
正当计算机视觉的从业者们正在努力研究YOLO V4的时候,万万没想到,有牛人不服。6月25日,Ultralytics发布了YOLOV5 的第一个正式版本,其性能与YOLO V4不相伯仲,同样也是现今最先进的对象检测技术,并在推理速度上是目前最强。
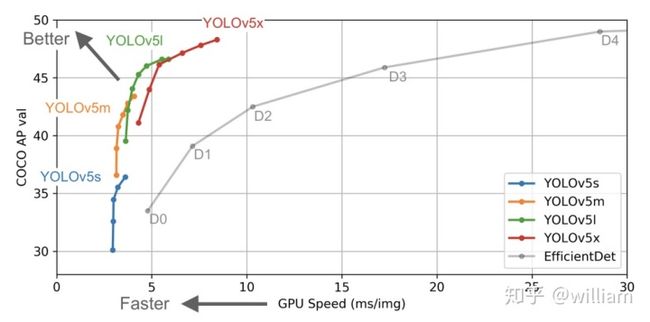
从上图的结果可以看出,YOLO V5确实在对象检测方面的表现非常出色,尤其是YOLO V5s 模型140FPS的推理速度非常惊艳。
YOLO V5和V4集中出现让很多人都感到疑惑,一是YOLO V5真的有资格能被称作新一代YOLO吗?二是YOLO V5的性能与V4相比究竟如何,两者有啥区别及相似之处?
在本文中我会详细介绍YOLO V5和YOLO V4的原理,技术区别及相似之处,最后会从多方面对比两者的性能。
Email: [email protected]
知乎专栏: 自动驾驶全栈工程师
我在我之前的文章中介绍了YOLO V3模型,YOLO是一种快速紧凑的开源对象检测模型,与其它网络相比,同等尺寸下性能更强,并且具有很不错的稳定性,是第一个可以预测对象的类别和边界框的端对端神经网络。
YOLO V3原始模型是基于Darknet网络。Ultralytics将YOLO V3架构迁移到了Pytorch平台上,并对其自行研究和改进。Ultralytics-yolov3 代码库是目前已开源YOLO V3 Pytorch的最佳实现。
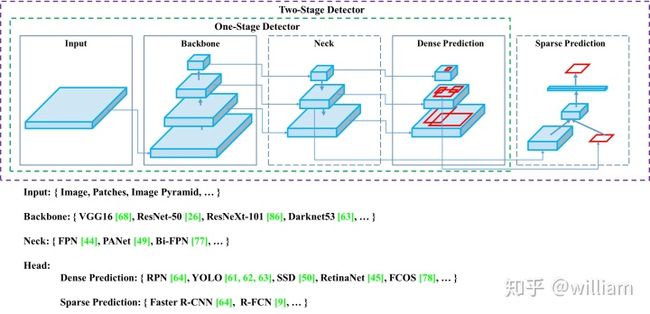
YOLO网络主要由三个主要组件组成。
1)Backbone -在不同图像细粒度上聚合并形成图像特征的卷积神经网络。
2)Neck:一系列混合和组合图像特征的网络层,并将图像特征传递到预测层。
3)Head: 对图像特征进行预测,生成边界框和并预测类别。
下图是对象检测网络的通用架构:
图片引用
我们可以在上述每个主要组件上使用不同的技术或者组合不同的方案来实现属于自己的最佳对象检测框架。
实际上YOLO V5的模型架构是与V4非常相近的。在下文中,我会从下面几个方面对比YOLO V5和V4,并简要阐述它们各自新技术的特点,对比两者的区别和相似之处,评判两者的性能,并做最后总结。
- Data Augmentation
- Auto Learning Bounding Box Anchors
- Backbone
- Network Architecture
- Neck
- Head
- Activation Function
- Optimization Function
- Benchmarks
Data Augmentation
图像增强是从现有的训练数据中创建新的训练样本。我们不可能为每一个现实世界场景捕捉一个图像,因此我们需要调整现有的训练数据以推广到其他情况,从而允许模型适应更广泛的情况。无论是YOLO V5还是V4,多样化的先进数据增强技术是最大限度地利用数据集,使对象检测框架取得性能突破的关键。通过一系列图像增强技术步骤,可以在不增加推理时延的情况下提高模型的性能。
YOLO V4数据增强

图片引用
YOLO V4使用了上图中多种数据增强技术的组合,对于单一图片,除了经典的几何畸变与光照畸变外,还创新地使用了图像遮挡(Random Erase,Cutout,Hide and Seek,Grid Mask ,MixUp)技术,对于多图组合,作者混合使用了CutMix与Mosaic 技术。除此之外,作者还使用了Self-Adversarial Training (SAT)来进行数据增强。
在下文中我将简单介绍以上数据增强技术。
图像遮挡
- Random Erase:用随机值或训练集的平均像素值替换图像的区域。

图片引用
- Cutout: 仅对 CNN 第一层的输入使用剪切方块Mask。

图片引用
- Hide and Seek:将图像分割成一个由 SxS 图像补丁组成的网格,根据概率设置随机隐藏一些补丁,从而让模型学习整个对象的样子,而不是单独一块,比如不单独依赖动物的脸做识别。

图片引用
- Grid Mask:将图像的区域隐藏在网格中,作用也是为了让模型学习对象的整个组成部分。

图片引用
- MixUp:图像对及其标签的凸面叠加。

图片引用
多图组合
Cutmix:
- 将另一个图像中的剪切部分粘贴到增强图像。图像的剪切迫使模型学会根据大量的特征进行预测。

图片引用
Mosaic data augmentation:
- 在Cutmix中我们组合了两张图像,而在 Mosaic 中我们使用四张训练图像按一定比例组合成一张图像,使模型学会在更小的范围内识别对象。其次还有助于显著减少对batch-size的需求,毕竟大多数人的GPU显存有限。

图片引用
自对抗训练(SAT)
- Self-Adversarial Training是在一定程度上抵抗对抗攻击的数据增强技术。CNN计算出Loss, 然后通过反向传播改变图片信息,形成图片上没有目标的假象,然后对修改后的图像进行正常的目标检测。需要注意的是在SAT的反向传播的过程中,是不需要改变网络权值的。
使用对抗生成可以改善学习的决策边界中的薄弱环节,提高模型的鲁棒性。因此这种数据增强方式被越来越多的对象检测框架运用。

图片引用
类标签平滑
Class label smoothing是一种正则化方法。如果神经网络过度拟合和/或过度自信,我们都可以尝试平滑标签。也就是说在训练时标签可能存在错误,而我们可能“过分”相信训练样本的标签,并且在某种程度上没有审视了其他预测的复杂性。因此为了避免过度相信,更合理的做法是对类标签表示进行编码,以便在一定程度上对不确定性进行评估。YOLO V4使用了类平滑,选择模型的正确预测概率为0.9,例如[0,0,0,0.9,0...,0 ]。
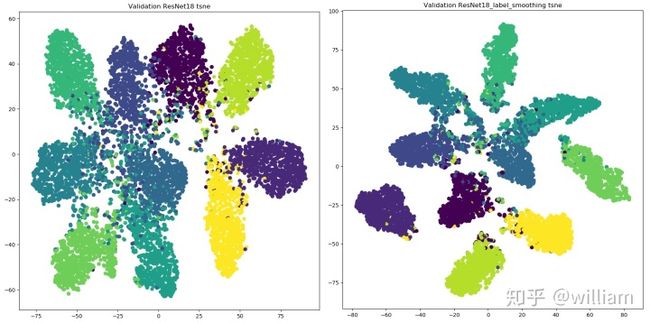
从上图看出,标签平滑为最终的激活产生了更紧密的聚类和更大的类别间的分离,实现更好的泛化。
图片引用
YOLO V5 似乎没有使用类标签平滑。
YOLO V5 数据增强
YOLO V5的作者现在并没有发表论文,因此只能从代码的角度理解它的数据增强管道。
YOLOV5都会通过数据加载器传递每一批训练数据,并同时增强训练数据。数据加载器进行三种数据增强:缩放,色彩空间调整和马赛克增强。
有意思的是,有媒体报道,YOLO V5的作者Glen Jocher正是Mosaic Augmentation的创造者,他认为YOLO V4性能巨大提升很大程度是马赛克数据增强的功劳,也许是不服,他在YOLO V4出来后的仅仅两个月便推出YOLO V5,当然未来是否继续使用YOLO V5的名字或者采用其他名字,首先得看YOLO V5的最终研究成果是否能够真正意义上领先YOLO V4。
但是不可否认的是马赛克数据增强确实能有效解决模型训练中最头疼的“小对象问题”,即小对象不如大对象那样准确地被检测到。
下图是我在训练BDD100K数据时的数据增强结果。我会在我的下篇文章:YOLO V5 Transfer learning 中展示YOLO V5对象检测框架的实测效果。

Auto Learning Bounding Box Anchors-自适应锚定框
在我之前YOLO V3的文章中,我介绍过如何采用 k 均值和遗传学习算法对自定义数据集进行分析,获得适合自定义数据集中对象边界框预测的预设锚定框。
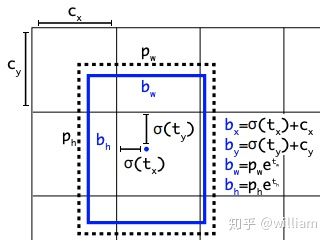
在YOLO V5 中锚定框是基于训练数据自动学习的。
对于COCO数据集来说,YOLO V5 的配置文件*.yaml 中已经预设了640×640图像大小下锚定框的尺寸:
# anchors
anchors:
- [116,90, 156,198, 373,326] # P5/32
- [30,61, 62,45, 59,119] # P4/16
- [10,13, 16,30, 33,23] # P3/8但是对于你的自定义数据集来说,由于目标识别框架往往需要缩放原始图片尺寸,并且数据集中目标对象的大小可能也与COCO数据集不同,因此YOLO V5会重新自动学习锚定框的尺寸。

如在上图中, YOLO V5在进行学习自动锚定框的尺寸。对于BDD100K数据集,模型中的图片缩放到512后,最佳锚定框为:
YOLO V4并没有自适应锚定框。
Backbone-跨阶段局部网络(CSP)
YOLO V5和V4都使用CSPDarknet作为Backbone,从输入图像中提取丰富的信息特征。CSPNet全称是Cross Stage Partial Networks,也就是跨阶段局部网络。CSPNet解决了其他大型卷积神经网络框架Backbone中网络优化的梯度信息重复问题,将梯度的变化从头到尾地集成到特征图中,因此减少了模型的参数量和FLOPS数值,既保证了推理速度和准确率,又减小了模型尺寸。
CSPNet实际上是基于Densnet的思想,复制基础层的特征映射图,通过dense block 发送副本到下一个阶段,从而将基础层的特征映射图分离出来。这样可以有效缓解梯度消失问题(通过非常深的网络很难去反推丢失信号) ,支持特征传播,鼓励网络重用特征,从而减少网络参数数量。

图片引用
CSPNet思想可以和ResNet、ResNeXt和DenseNet结合,目前主要有CSPResNext50 and CSPDarknet53两种改造Backbone网络。
Neck-路径聚合网络(PANET)
Neck主要用于生成特征金字塔。特征金字塔会增强模型对于不同缩放尺度对象的检测,从而能够识别不同大小和尺度的同一个物体。在PANET出来之前,FPN一直是对象检测框架特征聚合层的State of the art,直到PANET的出现。在YOLO V4的研究中,PANET被认为是最适合YOLO的特征融合网络,因此YOLO V5和V4都使用PANET作为Neck来聚合特征。
PANET基于 Mask R-CNN 和 FPN 框架,同时加强了信息传播。该网络的特征提取器采用了一种新的增强自下向上路径的 FPN 结构,改善了低层特征的传播。第三条通路的每个阶段都将前一阶段的特征映射作为输入,并用3x3卷积层处理它们。输出通过横向连接被添加到自上而下通路的同一阶段特征图中,这些特征图为下一阶段提供信息。同时使用自适应特征池化(Adaptive feature pooling)恢复每个候选区域和所有特征层次之间被破坏的信息路径,聚合每个特征层次上的每个候选区域,避免被任意分配。
下图中pi 代表 CSP 主干网络中的一个特征层
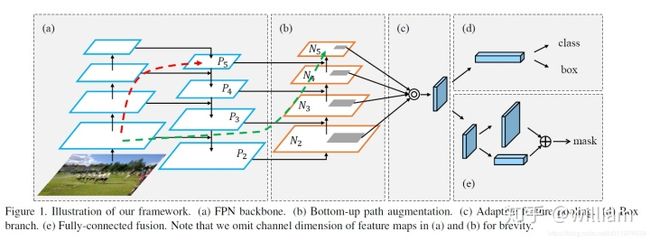
图片引用
Head-YOLO 通用检测层
模型Head主要用于最终检测部分。它在特征图上应用锚定框,并生成带有类概率、对象得分和包围框的最终输出向量。
在 YOLO V5模型中,模型Head与之前的 YOLO V3和 V4版本相同。

图片来源
这些不同缩放尺度的Head被用来检测不同大小的物体,每个Head一共(80个类 + 1个概率 + 4坐标) * 3锚定框,一共255个channels。
Network Architecture
由于YOLO V5的作者并未放出论文,而网络上已经存在大量YOLO V4网络结构分析,因此本文不着重分析YOLO V5与V4的网络结构具体细节,但它们有着相似的网络结构,都使用了CSPDarknet53(跨阶段局部网络)作为Backbone,并且使用了PANET(路径聚合网络)和SPP(空间金字塔池化)作为Neck,而且都使用YOLO V3的Head。
我们可以通过Netron可视化YOLO V5及V4的网络结构,但是你会发现YOLO V5的网络结构非常简洁,而且YOLO V5 s,m,l,x四种模型的网络结构是一样的。原因在于Ultralytics通过depth_multiple,width_multiple两个参数分别控制模型的深度以及卷积核的个数。
# YOLO V5s
# parameters
nc: 80 # number of classes
depth_multiple: 0.33 # model depth multiple
width_multiple: 0.50 # layer channel multiple例如*.yaml文件中,V5s的深度是0.33,而V5x的深度是1.33,也就是说V5x的Bottleneck个数是V5s的四倍。
而V5s的宽度是0.5,而V5x的宽度是1.25,表示V5s的卷积核数量是设置的一半,而V5x是设置的1.25倍,当然你也可以设置到1.5倍,搭建超巨型神经网络。下图中YOLO V5的yaml文件中的backbone的第一层是 [[-1, 1, Focus, [64, 3]],而V5s的宽度是0.5,因此这一层实际上是[[-1, 1, Focus, [32, 3]]。
# YOLOv5 backbone
backbone:
# [from, number, module, args]
[[-1, 1, Focus, [64, 3]], # 0-P1/2
[-1, 1, Conv, [128, 3, 2]], # 1-P2/4
[-1, 3, BottleneckCSP, [128]],
[-1, 1, Conv, [256, 3, 2]], # 3-P3/8
[-1, 9, BottleneckCSP, [256]],
[-1, 1, Conv, [512, 3, 2]], # 5-P4/16
[-1, 9, BottleneckCSP, [512]],
[-1, 1, Conv, [1024, 3, 2]], # 7-P5/32
[-1, 1, SPP, [1024, [5, 9, 13]]],
]下图中左侧为YOLO V5s的模型右侧为YOLO V5x的模型,可以明显看出卷积核数量不一样,因此参数数量也不一样。

为了方便大家了解YOLO V5与YOLO V4网络结构的区别,我已经用Netron生成了YOLO V5s,YOLO V5x,YOLO V4的网络结构图。对于对YOLO V5s网络结构基于代码理解的具体分析,我会在下篇文章YOLO V5 Transfer learning 中阐述。
点击下方链接可以查看各自的网络结构大图:
YOLO V4: https://1drv.ms/u/s!An7G4eYRvZzthI48WhoNNwWO8ElNfA?e=oG0Afh
YOLO V5s: https://1drv.ms/u/s!An7G4eYRvZzthI49NZcZHEw2Vtf-VA?e=plafXD
YOLO V5x: https://1drv.ms/u/s!An7G4eYRvZzthI47_ohzdWPz1CSrnQ?e=H2OpOO
YOLOV5S.YAML: https://1drv.ms/u/s!An7G4eYRvZzthI5A41VHiA9ncpBBfw?e=3M64Wd
Activation Function
激活函数的选择对于深度学习网络是至关重要的。YOLO V5的作者使用了 Leaky ReLU 和 Sigmoid 激活函数。
在 YOLO V5中,中间/隐藏层使用了 Leaky ReLU 激活函数,最后的检测层使用了 Sigmoid 形激活函数。而YOLO V4使用Mish激活函数。

图片来源
Mish在39个基准测试中击败了Swish,在40个基准测试中击败了ReLU,一些结果显示基准精度提高了3–5%。但是要注意的是,与ReLU和Swish相比,Mish激活在计算上更加昂贵。
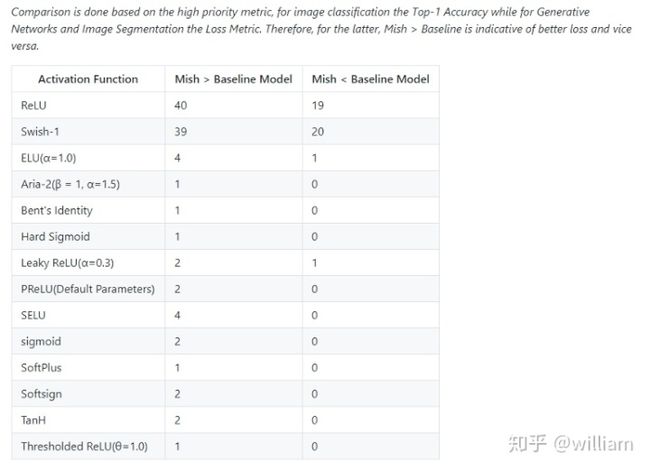
图片来源
Optimization Function
YOLO V5的作者为我们提供了两个优化函数Adam和SGD,并都预设了与之匹配的训练超参数。默认为SGD。
YOLO V4使用SGD。
YOLO V5的作者建议是,如果需要训练较小的自定义数据集,Adam是更合适的选择,尽管Adam的学习率通常比SGD低。但是如果训练大型数据集,对于YOLOV5来说SGD效果比Adam好。
实际上学术界上对于SGD和Adam哪个更好,一直没有统一的定论,取决于实际项目情况。
Cost Function
YOLO 系列的损失计算是基于 objectness score, class probability score,和 bounding box regression score.
YOLO V5使用 GIOU Loss作为bounding box的损失。
YOLO V5使用二进制交叉熵和 Logits 损失函数计算类概率和目标得分的损失。同时我们也可以使用fl _ gamma参数来激活Focal loss计算损失函数。
YOLO V4使用 CIOU Loss作为bounding box的损失,与其他提到的方法相比,CIOU带来了更快的收敛和更好的性能。
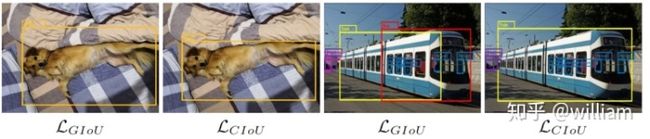
图片来源
上图结果基于Faster R-CNN,可以看出,实际上CIoU 的表现比 GIoU 好。
Benchmarks- YOLO V5 VS YOLO V4
由于Ultralytics公司目前重心都放在尽快推广YOLO V5对象检测框架,YOLO V5也在不停的更新和完善之中,因此作者打算年底在YOLO V5的研究完成之后发表正式论文。在没有论文的详细论述之前,我们只能通过查看作者放出的COCO指标并结合大佬们后续的实例评估来比较两者的性能。
- 官方性能评估

在上面的两个图中,FPS与ms/img的关系是反转的,经过单位转换后我们可以发现,在V100GPU上YOLO V5可以达到250FPS,同时具有较高的mAP。
由于YOLO V4的原始训练是在1080TI上的,远低于V100的性能,并且AP_50与AP_val的对标不同,因此仅凭上述的表格是无法得出两者的Benchmarks。
好在YOLO V4的第二作者WongKinYiu使用V100的GPU提供了可以对比的Benchmarks。
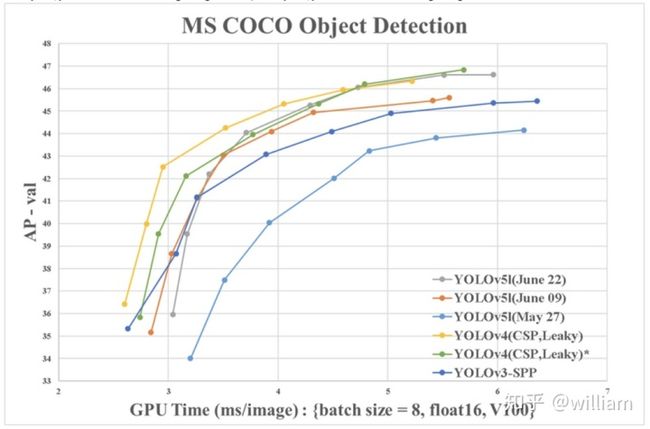
图片引用
从图表中可以看出,两者性能其实很接近,但是从数据上看YOLO V4仍然是最佳对象检测框架。YOLO V4的可定制化程度很高,如果不惧怕更多自定义配置,那么基于Darknet的YOLO V4仍然是最准确的。值得注意的是YOLO V4其实使用了大量Ultralytics YOLOv3代码库中的数据增强技术,这些技术在YOLO V5中也被运行,数据增强技术对于结果的影响到底有多大,还得等作者的论文分析。
- 训练时间
根据Roboflow的研究表明,YOLO V5的训练非常迅速,在训练速度上远超YOLO V4。对于Roboflow的自定义数据集,YOLO V4达到最大验证评估花了14个小时,而YOLO V5仅仅花了3.5个小时。

图片来源
而在我自己的数据训练过程中,YOLO V5s训练速度远超YOLO V4 。我会在我的下篇文章:YOLO V5 Transfer learning 中展示YOLO V5s的实测训练速度。
- 模型大小

图片来源
上图中不同模型的大小分别为: V5x: 367MB,V5l: 192MB,V5m: 84MB,V5s: 27MB,YOLOV4: 245 MB
YOLO V5s 模型尺寸非常小,降低部署成本,有利于模型的快速部署。
- 推理时间

在单个图像(批大小为1)上,YOLOV4推断在22毫秒内,YOLOV5s推断在20毫秒内。而YOLOV5实现默认为批处理推理(批大小36),并将批处理时间除以批处理中的图像数量,单一图片的推理时间能够达到7ms,也就是140FPS,这是目前对象检测领域的State-of-the-art。我使用我训练的模型对10000张测试图片进行实时推理,YOLOV5s 的推理速度非常惊艳,每张图只需要7ms的推理时间,再加上20多兆的模型大小,在灵活性上堪称无敌。但是其实这对于YOLO V4并不公平,由于YOLO V4没有实现默认批处理推理,因此在对比上呈现劣势,接下来应该会有很多关于这两个对象检测框架在同一基准下的测试。其次YOLO V4最新推出了tiny版本,YOLO V5s 与V4 tiny 的性能速度对比还需要更多实例分析。
Summary
总的来说,YOLO V4 在性能上优于YOLO V5,但是在灵活性与速度上弱于YOLO V5。由于YOLO V5仍然在快速更新,因此YOLO V5的最终研究成果如何,还有待分析。我个人觉得对于这些对象检测框架,特征融合层的性能非常重要,目前两者都是使用PANET,但是根据谷歌大脑的研究,BiFPN才是特征融合层的最佳选择。谁能整合这项技术,很有可能取得性能大幅超越。

图片引用
尽管YOLO V5目前仍然计逊一筹,但是YOLO V5仍然具有以下显著的优点:
- 使用Pytorch框架,对用户非常友好,能够方便地训练自己的数据集,相对于YOLO V4采用的Darknet框架,Pytorch框架更容易投入生产
- 代码易读,整合了大量的计算机视觉技术,非常有利于学习和借鉴
- 不仅易于配置环境,模型训练也非常快速,并且批处理推理产生实时结果
- 能够直接对单个图像,批处理图像,视频甚至网络摄像头端口输入进行有效推理
- 能够轻松的将Pytorch权重文件转化为安卓使用的ONXX格式,然后可以转换为OPENCV的使用格式,或者通过CoreML转化为IOS格式,直接部署到手机应用端
- 最后YOLO V5s高达140FPS的对象识别速度令人印象非常深刻,使用体验非常棒
写在结尾:
其实很多人都觉得YOLO V4和YOLO V5实际上没有什么耳目一新创新,而是大量整合了计算机视觉领域的State-of-the-art,从而显著改善YOLO对象检测的性能。其实我觉得有的时候工程应用的能力同样也很重要,能有两个这么优秀的技术整合实例供我们免费使用和学习研究,已经不能奢求更多了,毕竟活雷锋还是少啊。先别管别人谁更强,自己能学到更多才是最重要的,毕竟讨论别人谁强,还不如自己强。
最后想说的是,技术发展如此之快,究竟谁能最后拿下最佳对象检测框架的头衔尤未可知,而我们处在最好的时代,让我们且行且学且珍惜。
备注:
我已经更新了:
使用YOLO V5训练自动驾驶目标检测网络zhuanlan.zhihu.com
这篇文章详细介绍YOLO V5的网络结构及组成模块,并使用YOLO V5s在BDD100K自动驾驶数据集上进行迁移学习,搭建属于自己的自动驾驶交通物体对象识别网络。
后续我也会分享新的目标检测技术,欢迎大家订阅~
如果有什么疑问,可以随时联系我的个人邮箱,文章下评论可能回复不及时。
如果你觉得我的文章对你有帮助,请帮忙点个赞~\(≧▽≦)/~
转载请私信作者!
引用:
Responding to the Controversy about YOLOV5
Data Augmentation in YOLOV4
YOLO V5 — Explained and Demystified