大并发大吞吐系统优化的共性和法门
大规模并发优化的不二法门就是最高效利用资源的每一部分。
将固定的资源按业务处理流程的步骤分配,而不是按照业务本身分配,便会让每一部分都动起来。或质变的优化,或进化成新的技术。
流水线最后说,先举几个例子。
电路交换 & 分组交换
- 每个业务占用一条线路,直到业务结束,这就是电路交换。
- 颠倒一下,将所有业务切割成片,将线路时间片分配给这些业务片,这就是分组交换。
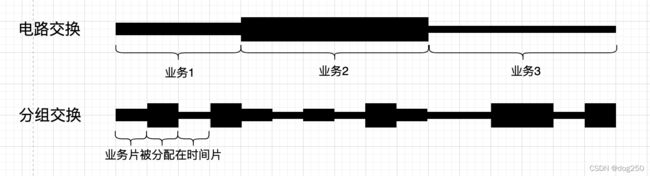
效果就是所有用户宏观上在同时使用线路。
正是这个简单的颠倒转换,促进了互联网的形成和发展,繁荣。
为什么分组交换容量大,因为电路交换时,对于单路线路,每一个特定时刻只有很少一部分资源被使用,其它的资源都因空闲而被浪费了
接着看别的。
批处理系统 & 分时系统
这几乎和上面电路交换和分组交换的关系一样:

计算机资源被所有用户充分利用,每一个用户可能在使用计算机不同的资源,于是这些用户彷佛在同时使用计算机。用户无需排队等待很久便可一起共享计算机。
以上这些都是计算机网络,计算机操作系统教材上第一章,第二章必讲的内容,但很少有人将它们联系起来。但实际上它们确实是一回事。
有趣的是,正是分时系统影响了分组交换网络,而不是反过来。分组交换的思想早在1920年代古已有之,只是那时没有成功的案例,这个思想也就只能留在纸上。
计算机系统技术的发展,分组交换便有了模版可效仿,既然多个用户彷佛在同时使用同一台计算机,那该计算机传输到远端的各个用户的数据也就可以彷佛在同时使用网络线路。
下面的案例依然循着这个思路。
柔性帧传输
这个其实也是一回事,看下图:

再进一步解释一下:

打个比方,10帧延时100ms,可以把这10帧每一帧固定部分打成一个包,一共打成N个数据包,将这N个数据包在100ms内随机顺序发出,接收端在固定时间内收到几个算几个,然后解码拼接,就可以播放了。就算丢包,由于N个数据包是打乱顺序随机发的,也就是模糊一些罢了。
是不是很有趣?这就是柔性有损传输。
为什么比直接传帧吞吐好,因为直接传帧涉及FEC或ARQ,这部分冗余或重传的部分是解码的必须,不得已浪费了带宽资源,而柔性有损传输则避免了资源浪费。
接着走。
Apache & Nginx
老掉牙的话题了,当时做传输优化涉及到业务层时就分析过:
https://blog.csdn.net/dog250/article/details/78994710
把它和上面聊到的这些统一起来看:

是不是一回事?流水线?
接着看,还有。
wireguard-go & boringtun
相关wireguard-go,性能很差,无论如何优化,各种指标依然拉胯,但boringtun就相当好。这不是什么黑科技优化,而是架构的改变。
boringtun不再每一个peer生成一个goroutine,而只生成CPU个线程,处理所有peer。wireguard-go很像Apache,boringtun就是Nginx。
请求也好,peer也罢,都有可扩展难题,不能作为切割资源的粒度,如果是,那便注定失去了可扩展性,最终包括调度在内的管理开销将压垮系统。
记住,一定要认识到,资源是固定的,不要让不固定的请求去调度资源,而要让资源去调度请求。大规模并发问题本质上就是一个查找,要让这个查找可优化,可观测,查找是业务自身数据面的事,不要交给作为控制面的系统。
换句话说,你要查找的是请求,而不是甩锅给系统去查找进程或协程。
接着看,还有。
iptables & ipset & nf-HiPAC
iptbales饱受诟病,大家都知道它在海量规则下性能差却不知怎么优化。其实很简单,预处理一下规则就可以了。
如何预处理规则不细说,最简单的就是把IP地址放入ipset中,而不是写多条规则,复杂的一点的,详见:
https://blog.csdn.net/dog250/article/details/77618319
还有个nf-HiPAC,我在多年前玩过,它和iptables之间的对比正如同上面所列的一系列对比:

有意思吧。
都是一回事,还是颠倒个顺序。
作坊 & 流水线
若没有流水线,仅凭着那些个作坊,大机器工业很难展开,人们也就无法进入消费时代。
作坊是来一个活儿干一个活儿,干完再干下一个。而流水线则是把每一个活儿分成固定的N个步骤,N个步骤接力干。虽然单个产品的生产周期没有变化,但总吞吐却可以扩大N倍,这得益于充分利用了资源。这个和分时系统以及分组交换如出一辙。

下面是流水线为什么吞吐高的解释:
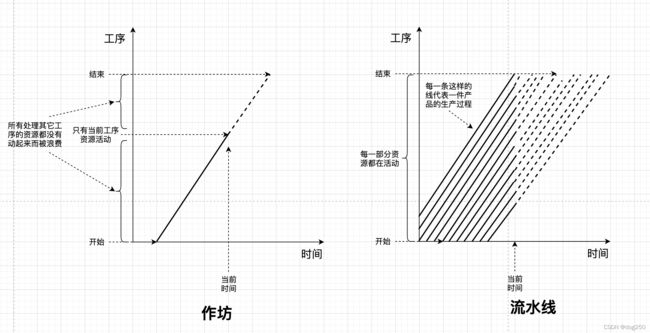
仍以Web服务器为例,Apache就像个作坊,来个请求就分配一个工人全程服务,Nginx就像个工厂,排期到固定的流水线。事实上,本文以上的所有例子均可以套用。
总之,资源就是那么多,要让它们全部动起来。
让你的每一部分代码在固定的时间周期内运行到的次数越多,越高效,如果代码没有跑到,以Apache,wireguard-go为例,这就是所谓的调度开销:系统调度你了,你却大量的代码都没跑。
最近在思考一些共性的东西,抽了点时间总结一下。谈到奢侈品和大众消费品,后者的生产关注的就是大吞吐高并发,比如温州皮鞋。但对于奢侈品,则更适合作坊的模式,专人全力量身定制,比如经理的西裤。
浙江温州皮鞋湿,下雨进水不会胖。