Python语言程序设计笔记(全)
Python语言程序设计
- 源代码人类可理解
- 目标代码 计算机直接执行
文章目录
- Python语言程序设计
-
- 1.编译与解释
- 2.编程语言分类
- 3.python语言简介
- 4. 下载配置python
- 5.编程两种方式
- 6.python基本语法
- 7.【实列】温度转换包含的语法:
-
- 缩进
- 注释
- 变量命名与保留字
- 数据的表现形式
- 字符串的使用
- 数据类型
- 语句与函数
- 输入输出
- 温度转换代码分析
- 练习
- 8.Python基本图形绘制
-
- 0x1 深入理解Python语言
- 0x2 python特点与优势
- 0x3 【实例】python绘制蟒蛇
- 0x4 模块一 turtle
- 0x5 turtle 程序语法元素分析
-
- 库引用与impot
- 库引用
- import用法
- import更多用法
- 基本循环语句与range函数
- 9.python基本数据类型
-
- 0x1数字类型及操作
-
- 整数类型
- 浮点数类型
- round函数
- 科学计数法表示浮点数
- ==复数类型==
- 数值运算操作符
- 数值运算函数
- 数字类型转换函数
- 0x2 【实例】 天天向上的力量
-
- 问题1 千分之一的力量
- 问题2 千分之五和1%
- 问题3 工作日力量
- 问题4 工作日的努力
- 0x3 字符串类型及操作
-
- 字符串
- 字符串有四种表示方法
- 索引 、 切片
- 转义符 \
- 字符串操作符
- 获取星期字符串
- 字符串处理函数
- Unicode编码
- 十二星座
- 字符串处理方法
-
- 方法
- 一些以方法形式提供的字符串处理功能
- 字符串类型的格式化
- 槽
- format()方法的格式控制
- 0x4 time库的使用
-
- time库基本介绍
- 时间获取
- 时间格式化
- 程序计时运用
- 0x5 【实列】 文本进度条
-
- 文本进度条问题要求:
- 文本进度条的单行动态刷新
- 完整文本进度代码
- 举一反三
- 文本进度条的不同设计函数
- 10.程序控制结构
-
- 0x1 程序的分支结构
-
- 二分支结构
- 多分支
- 逻辑保留字
- 0x2 程序的异常处理
-
- 异常处理的基本使用
- 0x3 身体质量指数BMI
-
- 问题分析:body Mass index
- 问题需求:输入体重和身高值
- 多分支组合注意
- 0x4 程序的循环结构
-
- for遍历
- while循环
- 循环控制保留字
- 循环高级用法
- 0x5 random库使用
-
- random库介绍
- 基本随机数函数
- 扩展随机数函数
- 0x6 实例 圆周率计算
-
- 问题分析
- 公式法
- 蒙特卡罗法
- 理解方法思维
- 11.函数和代码复用
-
-
- 问题分析
- 基本思路
- 代码
- 代码优化
- 举一反三
- 0x3 代码复用与函数递归
- 0x4 PyInstaller库的使用
- 0x5 实例 科赫雪花小包裹
-
- 12.组织数据类型
-
- 0x1 集合类型及操作
- 0x2 序列类型及操作
- 0x3 模块 jieba库的使用
-
- 三种模式
- 常用函数
- 0x4 实例 文本词频统计
- 13.文件和数据格式化
-
- 0x1 文件的使用
-
- 一维数据的表示
- 二维数据的表示
- 14.程序设计方法学
-
- 0x1 实例 体育竞技分析
- 0x2 Python程序设计思维
- 计算生态与python语言
- 0x3 Python第三方库安装
- 0x4 模块 os库的基本使用
- 0x5 实例第三方库安装脚本
- 15.Python计算生态概览
-
- 0x2 实例 霍兰德人格分析雷达图
- 0x5 实例 玫瑰花绘制
- 0x5 实例 玫瑰花绘制
1.编译与解释
编译 将源代码在转换为目标代码,转换完知乎不需要源代码参与
解释 每次都需要源代码参与
2.编程语言分类
-
根据执行方式不同,编程语言分为两类
静态语言 使用编译执行的语言 如C、java
脚本语言 使用解释执行的编程语言 如python、JavaScript、php
-
优势
静态语言 编译器一次性生成慕白哦迪阿敏,优化更充分 程序运行速度更快
脚本语言 执行程序时需要源代码,维护更灵活,易跨多个操作系统平台
3.python语言简介
-
input process output
输入是程序的开始
-
python 蟒蛇 PSF拥有 非盈利组织 保护python开放、开源和发展
创始人 guido van rossum
4. 下载配置python
下载配置python https://www.python.org/
pycharm环境:https://www.jetbrains.com/pycharm/
pycharm配置使用:https://blog.csdn.net/ling_mochen/article/details/79314118
5.编程两种方式
- 交互式 对每个输入语句即时运行结果 ,适合语法练习
#示例一:计算圆面积
>>> r = 25
>>> area = 3.1415 * r * r
>>> print(area)
1963.4375000000002
>>> print("{:.2f}".format(area))
1963.44
>>>
#示例二:画同心圆
>>> import turtle
>>> turtle.pensize(2)
>>> turtle.circle(10)
>>> turtle.circle(40)
>>> turtle.circle(80)
>>> turtle.circle(160)
- 文件式 批量执行一组语句并运行结果,编程的主要方法
#示例一:计算圆面积
r = 25
area = 3.1415 * r * r
print(area)
print("{:.2f}".format(area))
==输出===
1963.4375000000002
1963.44
#示例二:画同心圆
import turtle
turtle.pensize(2)
turtle.circle(10)
turtle.circle(40)
turtle.circle(80)
turtle.circle(160)
===输出===
同心圆
6.python基本语法
-
实例1温度转换
-
理解1 直接将温度值进行转换
-
理解2 将温度信息发布的声音或图像形式进行理解和转换
-
理解3 监控温度信息发布渠道,实时获取并转换温度值
-
-
华氏摄氏温度定义,转换公式:
-
摄氏度 以1标准大气压下睡的结冰点为0度,沸点为100度
-
华氏度 以1标准大气压下的水的结冰点为32度,沸点为212度,将温度进行等分刻画
-
C = (F - 32)/1.8
-
F = C*1.8 +32
-
#TempConvert.py
TempStr = input("请输入带有符号的温度值:")
if TempStr[-1] in ['F','f']:
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']:
F = 1.8 *eval(TempStr[0:-1]) + 32
print("转换后的温度是{:.2f}F".format(F))
else:
print("输入格式错误")
7.【实列】温度转换包含的语法:
缩进
缩进表达程序的格式框架
严格明确 :缩进是语法的一部分,缩进不正确程序会运行错误
所属关系: 表达大门键保护和层次关系的唯一手段
长度一致 一般4个空格或一个TAB
注释
不被程序执行的说明
单行注释 以#开头,其后为注释
#TempConvert.py 单行注释
多行注释 以‘“ 开头和结尾
'" 这里是多行注释的第一行
这里是多行注释的第二行 "'
变量命名与保留字
TempStr 、C、F 为变量
命名规则:大小写字母、数字、下划线和汉字等字符及组合
注意事项:首字符不能是数字、不能与保留字相同
保留字(关键字)
被编程语言内部定义并保留使用的标识符

数据的表现形式
供计算机理解数据的形式
-
整数类型 10011101
-
字符串类型 “10,011,101” 单引号和双引号相同
-
列表类型 [10,011,101] 表达的是三个数字
“请输入”的“请”是第0个字符
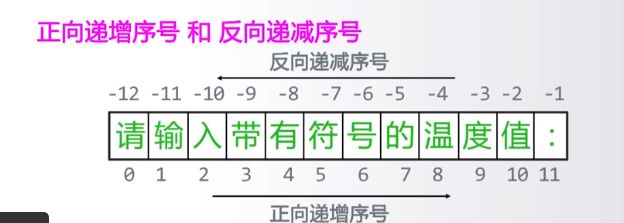
字符串的使用
使用[]获取字符串中的一个或多个字符
- 索引:返回字符串中单个字符 <字符串>[M]
“请输入带有符号的温度值:”[0] 或者 TemStr[-1]
- 切片:返回字符串中一段字符子串 <字符串>[M:N]
TempStr = "请输入带有符号的温度值:"
TempStr[-1]
':'
"请输入带有符号的温度值:"[0]
'请'
"请输入带有符号的温度值:"[0:4] #不到第四个字符“ 0 1 2 3
'请输入带'
- 列表类型 [10,011,101]
数据类型
整数、浮点数、列表类型
[‘F’,’f’] 表示两个元素’F‘和’f‘
if TempStr[-1] in ['F','f']: #in 判断一个元素是否在列表中
#TempConvert.py
TempStr = input("请输入带有符号的温度值:")
if TempStr[-1] in ['F','f']:
分析:
>>> TempStr = input("请输入带有符号的温度值:")
请输入带有符号的温度值:20F
>>> TempStr[-1]
'F'
>>> TempStr[-2]
'0'
>>> TempStr[-3]
'2'
语句与函数
-
赋值语句(右边的数据类型影响左边,相当于用数据来定义变量)
-
分支语句 如条件判断语句
语法结构:
if 条件判断内容 : #如果条件为True则执行冒号后的语句
执行语句 #如果条件为false则跳过冒号后的语句
示例:
if TempStr[-1] in ['F','f']:
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
-
冒号及后续缩进用来表示后续语句与条件的所属关系,千万不能少
-
函数
python类似数学中的函数,y=f(x)
>>> print("输入格式错误")
>>> "输入格式错误"
函数采用 <函数名>(<参数>) 方式使用
eval(TempStr[0:-1]) #TempStr[0:-1]是参数
回顾
#TempConvert.py
TempStr = input("请输入带有符号的温度值:")
if TempStr[-1] in ['F','f']:
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']:
F = 1.8 *eval(TempStr[0:-1]) + 32
print("转换后的温度是{:.2f}F".format(F))
else:
print("输入格式错误")
输入输出
- input()函数的使用格式:
<变量> = input(<提示信息字符串>)
TempStr = input("请输入带有符号的温度值:")
#TempStr保存用户输入的信息,以 字符串 的形式保存到变量中
- print函数的格式化使用方法
print("转换后的温度是{:.2f}C".format(C)) #暂且记忆
{} 表示槽,后续遍历填充到槽中
{:.2f}表示将变量C填充到这个位置时取小数点后2位
- eval() 去掉参数最外侧引号并执行余下语句的函数
>>> eval("1")
1
>>> eval("1 + 2") #去掉双引号,变成python了可理解的语句,固结果为3
3
>>> eval('"1 + 2"') #去掉双引号,输出一个单引号的字符串
'1 + 2'
>>> eval('print("Hello")')
Hello
>>> TempStr = input("请输入带有符号的温度值:")
请输入带有符号的温度值:200
>>> eval(TempStr[0:4])
200
>>> print(TempStr[0:4])
200
>>> eval("12.3")
12.3
温度转换代码分析
#TempConvert.py #注释,此行不运行
TempStr = input("请输入带有符号的温度值:") #用户输入的字符串将保存在TempStr中,input内为提示信息
if TempStr[-1] in ['F','f']: #判断TempStr的最后一个字符是否为列表类型F和f中的一个,为true则执行4、5行语句
C = (eval(TempStr[0:-1]) - 32)/1.8
print("转换后的温度是{:.2f}C".format(C))
elif TempStr[-1] in ['C','c']: #判断TempStr的最后以一个字符是否为C和c中的一个,为true则执行7、8行语句
F = 1.8 *eval(TempStr[0:-1]) + 32
print("转换后的温度是{:.2f}F".format(F))
else: #默认执行:后的语句
print("输入格式错误")
===============================================================================
#如果输入82F,则为什么eval(TempStr[0:-1])的结果是不包含F,为82?
因为TempStr[0:-1]表示从0号元素开始,且不到-1号元素的字符串,这里-1号元素就是F
=================================================================================
>>> TempStr[0:-1]
'300'
>>> eval(TempStr[0:-1])
300
template = "零一二三四五六七八九"
s = input()
for c in s:
print(template[eval(c)], end="")
练习
#获得用户输入的一个正整数输入,输出该数字对应的中文字符表示。
#0到9对应的中文字符分别是:零一二三四五六七八九
输入示例1
123
输出示例1
一二三
输入示例2
9876543210
输出示例2
九八七六五四三二一零
#代码:
template = "零一二三四五六七八九"
s = input()
for c in s:
print(template[eval(c)], end="")
8.Python基本图形绘制
0x1 深入理解Python语言
-
计算机技术演进
1946 - 1981 计算机系统结构时代 计算能力
1981 - 2008 个人pc计算机时代 交互问题 视窗、网络
2008 - 2016 复杂信息系统时代 数据问题
2017 - 人工智能时代 人类的问题
新计算时代
-
不同编程语言的初心和适用对象
C 理解计算机系统结构 关注性能 底层
JAVA 理解主客体关系 跨平台 软件类
C++ 理解主客体关系 大规模程序 核心软件
VB 理解交互逻辑 桌面应用
Python 理解问题求解 各类问题
python 是一个通用语言
0x2 python特点与优势
-
C的10%的代码量
强制可读性
较少的底层语法元素
多种编程方式
支持中文字符
-
强大的第三方库
快速增长的计算生态
避免重复造轮子
开放共享
跨操作系统平台
-
各语言的面向对象
C/C++: Python归Python ,C归C
Java : 针对待定开发和岗位需求
HTML/CSS/JS:不可替代的前端技术,全栈能力
-
超级语言的诞生
粘性整合已有程序,形成庞大的生态
具有庞大的计算生态,可以很容易利用已有代码功能
编程思维是集成开发
完成2+3功能的高级语言
Python是唯一的超级语言
0x3 【实例】python绘制蟒蛇
#PythonDraw.py
import turtle #引入了一个turtle绘图库
turtle.setup(650,350,200,200)
turtle.penup()
turtle.fd(-250)
turtle.pendown()
turtle.pensize(25)
turtle.pencolor("purple")
turtle.seth(-40)
for i in range(4):
turtle.circle(40,80)
turtle.circle(-40,80)
turrle.circle(40,80/2)
turtle.fd(40)
turtle.circle(16,180)
turtle.fd(40*2/3)
turtle.done()
-
举一反三
Python语法元素理解
程序参数的改变 颜色 长度 方向
0x4 模块一 turtle
-
Python函数库之一
turtle库是入门级图形绘制函数库
-
python计算生态 = 标准库 + 第三方库
标准库 :随解释器直接安装到操作系统中的功能模块
第三方库:需要经过安装才能使用的功能模块
库Library、包Package、模块Module ,统称模块
-
turtle的原理
有一直海龟,其实在窗体的正中心
在画布上游走,走过的轨迹形成了绘制的图形
海龟由程序控制,可以变换颜色、改变宽度等
-
模块1 turtle库的使用
turtle的绘图窗体
最小单位是像素
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ShYQ2GgZ-1615378667824)(https://s3.ax1x.com/2021/01/07/smQs6s.png)]
#设置启动窗体的位置和大小
turtle.setup(width,height,startx,starty)
示例:
>>> import turtle
>>> turtle.setup(800,400,0,0) #在左上角显示
>>> import turtle
>>> turtle.setup(800,400) #默认在屏幕中央显示
-
turtle空间坐标体系
绝对坐标 以海龟在中心为原点,做平面坐标系
#示例1:
import turtle
turtle.goto(100,100)
turtle.goto(100,-100)
turtle.goto(-100,-100)
turtle.goto(-100,100)
turtle.goto(0,0)
海龟坐标
turtle.fd(d) #向海龟的正前方向运行
turtle.bk(d) #向海龟的反方向运行
turtle.circle(r,angle) #以海龟左侧某一点为圆心,做曲线运行
r 半径 angle 角度
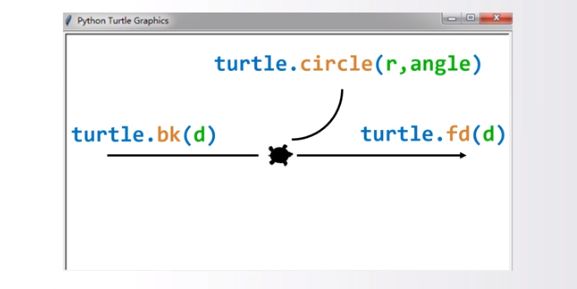
import turtle
turtle.circle(100,1)
turtle.circle(250,80)
turtle.circle(150,45)
turtle.circle(120,45)
turtle.circle(150,30)
turtle.circle(150,30)
turtle.circle(130,10)
turtle.circle(130,5)
turtle.circle(130,5)
turtle.circle(15,50)
turtle.circle(15,170)
turtle.circle(130,5)
turtle.circle(130,5)
turtle.circle(130,10)
turtle.circle(150,30)
turtle.circle(150,30)
turtle.circle(120,45)
turtle.circle(150,45)
turtle.circle(250,80)
turtle.circle(100,10)
turtle.circle(100,1)
#心形
绝对角度坐标体系,x轴为0度
turtle.seth(angle) #-seth()改变海龟行进方向,但不行进,angle为绝对度数
turtle.left(angle) #改变运行方向
turtle.right(angle) #改变运行方向
-
RGB色彩体系
红黄蓝三通道
RGB小数值、整数值
turtle.colormode(mode) #确定是用小数值还是整数值
1.0 表示小数值模式
255 表示整数值模式
0x5 turtle 程序语法元素分析
库引用与impot
#PythonDraw.py
import turtle #引入了一个turtle绘图库
turtle.setup(650,350,200,200)
turtle.penup()
turtle.fd(-250)
turtle.pendown()
turtle.pensize(25)
turtle.pencolor("purple")
turtle.seth(-40)
for i in range(4):
turtle.circle(40,80)
turtle.circle(-40,80)
turrle.circle(40,80/2)
turtle.fd(40)
turtle.circle(16,180)
turtle.fd(40*2/3)
turtle.done()
turtle. . 的编程风格
库引用
扩充Python程序功能的方式
使用import保留字完成,采用.()编码风格
import <库名>
#PythonDraw.py
import<库名>
<库名> . <函数名>(<函数参数>)
import用法
使用from和import保留字共同完成
#PythonDraw.py
from <库名> import <函数名>
from <库名> import*
<函数名>(函数参数)
使用上述方式可以不用turtle. 直接函数名加函数参数,如下
#PythonDraw.py
from turtle import* #引入了一个turtle绘图库
setup(650,350,200,200)
penup()
fd(-250)
pendown()
pensize(25)
pencolor("purple")
seth(-40)
for i in range(4):
circle(40,80)
circle(-40,80) #注意缩进,缩进不统一也会报错
circle(40,80/2)
fd(40)
circle(16,180)
fd(40*2/3)
done()
- 两种方法比较
<库名> . <函数名>(<函数参数>)
<函数名>(函数参数)
第一种方法不会出现函数重名问题
第二种方法会出现
import更多用法
使用import和as保留字共同完成
#PythonDraw.py
import <库名> as <库别名> # 相当于自定义了一个简便的名字
<库别名> . <函数名>(<函数参数>)
- turtle画笔控制函数
turtle.penup() #抬起画笔,海龟在飞行
turtle.pendown() #落下画笔,海龟在爬行
turtle.pensize(25) # 设置画笔宽度 别名 turtle.width(width)
turtle.pencolor("purple") #修改画笔颜色,参数字符串小写
#pencolor(color)的参数可以有三种形式
颜色字符串 turtle.pencolor("purple")
RGB的小数值 turtle.pencolor(0.62,0.42,0.13)
RGB的元组值 turtle.pencolor((0.62,0.42,0.13))
将海龟想象为画笔
画笔操作后一直有效,一般成对出现
turtle运动控制函数
控制海龟行进方向:走直线或者曲线
#向前进,走直线
turtle.forward(d) 别名 turtle.fd(d)
d :行进距离,可以为负数,倒退行进
#根据半径r绘制extent角度的弧形
turtle.circle(r,extent=None)
r:默认圆心在海龟左侧r距离的位置
extent :绘制角度,默认是360度整圆
turtle方向控制函数
控制海龟面对方向:绝对角度和海龟角度
#当前海龟方向,改变为某一角度方向
turtle.setheading(angle) 别名 turtle.seth(angle)
angle:改变行进绝对方向,海龟走角度
#控制海龟向左转或向右转
turtle.left(angle)
turtle.right(angle)
angle: 在海归当前行进方向上旋转的角度
基本循环语句与range函数
循环语句
for<执行次数> in range(<要执行多少次>):
<被循环执行的语句>
#range的参数是循环的次数
#for in 之间的变量是每次执行的计数,0到<执行次数> - 1
示例:
for i in range(5):
print(i)
输出:
0
1
2
3
4
#输出print("Hello:",i) 中的逗号在输出时显示为空格
range函数
#产生循环计数序列
range(N) 即产生0到N-1的整数序列,共N个
如:range(5),则产生0,1,2,3,4
range(M,N) 即产生M到N-1的整数序列,共N-M个
如:range(2,5),则产生2,3,4
- python蟒蛇绘制代码分析
#PythonDraw.py
import turtle #引入了一个turtle绘图库
turtle.setup(650,350,200,200) #设立了一个窗体
turtle.penup() #将画笔抬起
turtle.fd(-250) #海龟倒退250
turtle.pendown() #放下画笔
turtle.pensize(25) #设置画笔宽度
turtle.pencolor("purple") #设置画笔颜色
turtle.seth(-40) #设置画笔起始角度为-40度
for i in range(4): #利用循环绘制路径,循环4次
turtle.circle(40,80) #先以半径为40像素,绘制80度
turtle.circle(-40,80) #再以反向40像素为半径,绘制80度
turrle.circle(40,80/2) #最后以40像素为半径,绘制40度
turtle.fd(40) #再向前走40像素
turtle.circle(16,180) #以16像素为半径,画180度
turtle.fd(40*2/3) #当前方向向前走80/3像素
turtle.done() #手动退出,删掉即自动退出
9.python基本数据类型
0x1数字类型及操作
整数类型
与数学整数概念一致
pow(x,y) 计算x的y次方,想算多大算多大
四种进制表示:
十进制:1010、99、-217
二进制:0b或0B开头 : 0b0101,-0B1010
八进制:以0o或0O开头: 0o123,0O456
十六进制:以0x或0X开头:0x9a,- 0X89
浮点数类型
与数学实数概念一致
浮点数取值范围和小鼠精度都存在限制
取值范围数量级约±10的308次方,精度数量约10的-16
浮点数之间的运算存在不确定尾数,不是bug
>>> 0.1 +0.2
0.30000000000000004
-
存在不确定尾数的原因
计算机中是二进制存储的,二进制表示小数可以无限接近0.1,但永远不完全相同
所以十进制表示的0.1加0.2结果无限接近0.3,但可能存在尾数
round函数
round(x,d): 对x四舍五入,d是小数截取位数
示例:
>>> round(0.1 + 0.2,1) == 0.3
True
#浮点数间运算及比较用round()函数辅助
#不确定位数一般在10的-16次方左右,固该函数有效
科学计数法表示浮点数
格式 e 表示 a*10的b次方
例如:4.3e-3 值为0.0043
复数类型
x的平方 = -1 ,那么x的值是?
定义 : j = ( − 1 ) j=\sqrt{(-1)} j=(−1)
a + bj 被称为复数,其中a为实部,b是虚部
>>> z = 10 + 10j #复数类型
>>> print(z)
(10+10j)
>>> a = 10
>>> print(a)
10
数值运算操作符
- 加减乘除与C相同
#特别注意
x / y #结果是浮点数除法
x // y #结果是整数无小数除法,直接约去小数,不四舍五入
示例:
>>> 3 // 4
0
>>> 7/2
3.5
>>> 7//2
3
>>> 19 / 5
3.8
>>> 19//5
3
- 模运算(取余运算)与C相同
x % y
- 幂运算
x ** y #表示x的y次幂,当y是小数时,做开方运算
示例:
>>> 2 ** 10
1024
>>> 49 ** 0.5
7.0
- 二元操作符对应的增强赋值操作
x op=y 相当于 x = x op y
#op 表示二元操作符,如 +、 -、 *、 /、 //、%、**
#与C中的 += 意思相同
不同数据类型间可以混合运算,生成结果为“最宽”类型
注意可能会产生不确定的尾数
数值运算函数
| 函数及使用 | 描述 |
|---|---|
| abs(x) | 绝对值,x的绝对值 |
| divmod(x,y) | 商余,(x//y,x%y),同时输出商和余数 |
| pow(x,y,z) | 幂余运算,(x**y)%z,参数z可省略 |
| round(x,d) | 四舍五入,d是保留小数位数,默认为零 |
| max(a,b,c,…) | 返回数字序列中最大值 |
| min(a,b,c,…) | 返回数字序列最小值 |
>>> abs(-1)
1
>>> divmod(10,3)
(3, 1)
>>> pow(2,10,10)
4
>>> pow(2,10)
1024
>>> round(10.12345,4)
10.1235
>>> max(1,9,5,2,6)
9
>>> min(3,2,4,5,1,23)
1
数字类型转换函数
| 函数及使用 | 描述 |
|---|---|
| int(x) | 转变为整型,取整数部分 |
| float(x) | 转变为浮点数,增加小数部分 |
| complex(x) | 将x变成复数,增加虚数部分 |
>>> int(4.35)
4
>>> float(1.23)
1.23
>>> float(1)
1.0
>>> complex(5)
(5+0j)
0x2 【实例】 天天向上的力量
基本问题,持续价值
1.01的365次方
0.99的365次方
问题1 千分之一的力量
1.001的365次方
0.999的365次方
#DaydayupQ1.py
x = pow(1.001,365)
y = pow(0.999,365)
print("向上:{:.2f},向下:{:.2f}".format(x,y))
输出:
向上:1.44,向下:0.69
问题2 千分之五和1%
#DaydayupQ1.py
dayfactor = 0.005
dayup = pow(1 + dayfactor,365)
daydown = pow(1 - dayfactor,365)
print("向上:{:.2f},向下:{:.2f}".format(dayup,daydown))
输出:
向上:6.17,向下:0.16
#DaydayupQ1.py
dayfactor = 0.01
dayup = pow(1 + dayfactor,365)
daydown = pow(1 - dayfactor,365)
print("向上:{:.2f},向下:{:.2f}".format(dayup,daydown))
输出:
向上:37.78,向下:0.03
问题3 工作日力量
一周 5天工作日每天提升1%,休息日2天每天退步1%
#DaydayupQ3.py
dayup = 1.0
dayfactor = 0.01
for i in range(365):
if i % 7 in [6,0]:
dayup = dayup *(1-dayfactor)
else:
dayup = dayup *(1+dayfactor)
print("一年后的成长:{:.2f}倍".format(dayup))
输出:
一年后的成长:4.63倍
结论:问题3的结果4.63倍介于,问题1的365天每天千分之一的1.44倍和问题2的365每天千分之五6.17倍之间。
问题4 工作日的努力
A 每天1%
B 工作日提升x,休息日下降1%
问当x为多少时,A与B的提升相等?
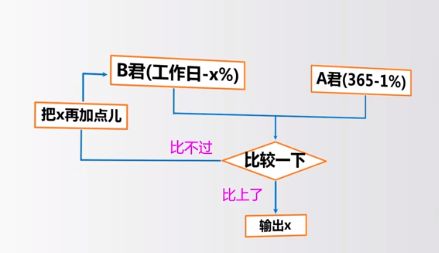
#DaydayupQ4.py
#def用来定义函数,占位符df是dayfactor的简写。
def dayUP(df): #函数dayUP
dayup = 1
for i in range(365):
if i % 7 in[6,0]:
dayup = dayup*(1 - 0.01)
else:
dayup = dayup * (1 + df)
return dayup
#根据df参数不同,函数内部会返回对应的结果,返回dayup
dayfactor = 0.01
while dayUP(dayfactor) < 37.78: #调用了上述函数
dayfactor += 0.001
print("工作日的努力参数是:{:.3f}".format(dayfactor)) #输出比上的结果
输出:
工作日的努力参数是:0.019
结论:工作日要努力约2%,才能跟不休息每天学1%的人相同
0x3 字符串类型及操作
字符串
由一对 ‘ ’ 或 ” “ 包含的一连串字符
可以索引” “[ ]
字符串有四种表示方法
前两种
"请输如带有符号的温度值" 或者 'C'
后两种
''' Python
语言 '''
或者
""" Python
语言 """
#注释也是''' ''',是因为没有被作用的字符串则被认为是注释
如果要在字符串内部表示 “ 则用 ‘ 构成字符串
如果要在字符串内部表示 ’ 则用 “ 构成字符串
如果 ‘ 和 ” 都要在字符串内部表示,则用 ’‘’ 构成字符串
索引 、 切片
切片高级用法
<字符串>[M:N] ,M缺失变送至开头,缺失表示至结尾
>>> "这是一个字符串"[:3]
'这是一'
<字符串>[M:N:K],使用[M:N:K]根据步长对字符串切片,k表示每移几位进行切片
>>> "123456789"[1:7:2]
'246'
>>> "123456789"[::-1] #可实现逆序的效果
'987654321'
更多测试
>>> "123456789"[2::-1]
'321'
>>> "123456789"[0::-1]
'1'
>>> "123456789"[:5:-1]
'987'
转义符 \
转义符表达特定字符的本意
>>>"这里有个双引号\" "
'这里有个双引号" '
\b 回退 \n换行 \r回车
字符串操作符
| 操作符及使用 | 描述 |
|---|---|
| x + y | 连接两个字符串x和y |
| n *x | 复制n次字符串x |
| x in s | 如果x是s的子串,返回true,否则返回False |
获取星期字符串
#WeekNamePrintV1.py
weekStr = "星期一星期二星期三星期四星期五星期六星期日"
weekID = eval(input("请输入星期数字(1-7):"))
pos = (weekId - 1) * 3
print(weekStr[pos:pos+3])
改进版
#WeekNamePrintV1.py
weekStr = "一二三四五六日"
weekID = eval(input("请输入星期数字(1-7):"))
print("星期"+weekStr[weekID])
字符串处理函数
| 函数及使用 | 描述 |
|---|---|
| len(x) | 返回字符串的长度 |
| str(x) | 返回任意类型x对应的字符串形式,与eval()相对应 |
| hen(x) 或oct(x) | 整数x的十六进制或八进制小写形式字符串 |
| chr(u) | u为Unicode编码,返回其对应的字符 |
| ord(x) | x为字符,返回其对应的Unicode编码 |
Unicode编码
python字符串的编码方式,适用于各国语言
从0到1114111(0x10FFFF)空间,每个编码对应一个字符
#示例1
>>> "1 + 1 = 2 " + chr(10004)
'1 + 1 = 2 ✔'
#示例2
>>> chr(9801)
'♉'
>>> str(ord("♉"))
'9801'
十二星座
>>> for i in range(12):
print(chr(9800 +i)) #无end参数时换行
♈
♉
♊
♋
♌
♍
♎
♏
♐
♑
♒
♓
>>> for i in range(12):
print(chr(9800 +i), end = "") #end参数 = 空时,不换行
♈♉♊♋♌♍♎♏♐♑♒♓
字符串处理方法
方法
“方法”在编程中是专有名词
方法特指 a . b( ) 风格中的函数b( )
方法本身也是函数,但与a有关,b是a提供的函数
-
面向对象中
a为对象,b为对象能够提供的功能
方法必用 . 的方式执行
一些以方法形式提供的字符串处理功能
| 方法及使用 | 描述 |
|---|---|
| str . lower()或str.upper() | 返回字符串的副本,全部字符小写/大写 |
| str . split(sep) | 返回一个列表,由str根据sep被分隔的部分组成 |
| str . count(sub) | 返回子串sub在str中出现的次数 |
| str.replace(old,new) | 返回字符串str副本,所有old子串被替换为new |
| str.center(width[,fillchar]) | 字符串str根据宽度with居中,fillchar可选,宽度是新的整个字符串的宽度 |
| str.strip(chars) | 从str中去掉在其左侧和右侧chars中列出的字符 |
| str.join(iter) | 在iter变量除最后元素外每个元素后增加一个str |
>>> "abcdefg".upper()
'ABCDEFG'
>>> "a,b,c,d,e,f,g".split(",") #默认是空格
['a', 'b', 'c', 'd', 'e', 'f', 'g']
>>> "an apple is bad".count("a")
3
>>> "abcdefg".split("c")
['ab', 'defg']
>>> "python".replace("n","n123.io")
'python123.io'
>>> "an".center(10,"=")
'====an===='
>>> "=python =".strip(" =np")
'ytho'
>>> ",".join("12345")
'1,2,3,4,5'
字符串类型的格式化
格式化是对字符串进行格式表达的方式
<模板字符串>.format(<逗号分隔的参数>)
槽
一对 { } 表示槽
不同的对应位置有不同的输出
示例:
“{}:计算机{}的CPU占用率为{}%”.format("2018-10-10","C",10) #其中有三个槽,与C中输出的位置对应相同,默认按顺序一一对应
“{0}:计算机{1}的CPU占用率为{2}%”.format("2018-10-10","C",10) #对应位置
>>> print("{0}:计算机{1}的CPU占用率为{2}%".format("2018-10-10","C",10))
2018-10-10:计算机C的CPU占用率为10%
>>> print("{1}:计算机{0}的CPU占用率为{2}%".format("2018-10-10","C",10)) #交换后,输出也交换
C:计算机2018-10-10的CPU占用率为10%
>>> print("{}:计算机{}的CPU占用率为{}%".format("2018-10-10","C",10)) #默认按顺序对应
2018-10-10:计算机C的CPU占用率为10%
format()方法的格式控制
类似于C输出的格式控制
| : | <填充> | <对齐> | <宽度> | <,> | < . 精度> | <类型> |
|---|---|---|---|---|---|---|
| 引导符号 | 用于填充的单个字符 | < 左对齐 ,> 右对齐,^ 居中对齐 | 槽设定的输出宽度 | 数字的千位分隔符 | 浮点数小数精度或字符串最大输出长度 | 整数类型b,c,d,o,x,X浮点数类型e,E,f,% |
示例:
>>> "{0:=^20}".format("PYTHON")
'=======PYTHON======='
>>> "{1:=^20}".format("PYTHON","ABC")
'========ABC========='
>>> "{1:=<20}".format("PYTHON","ABC")
'ABC================='
>>> "{1:20}".format("PYTHON","ABC")
'ABC ' #默认填充空格
>>> "{0:,.2f}".format(1234567.8910)
'1,234,567.89'
>>> "{0:b},{0:c},{0:d},{0:o},{0:x},{0:X}".format(425) #不同进制表示
'110101001,Ʃ,425,651,1a9,1A9'
>>> "{0:e},{0:E},{0:f},{0:%}".format(3.14)
'3.140000e+00,3.140000E+00,3.140000,314.000000%'
中文可以放到字符串中,不能在语法中出现
0x4 time库的使用
time库基本介绍
python中的标准库
计算机时间的表达
提供获取系统时间并格式化输出功能
提供系统级精确计时功能没用于程序性能分析
import time
time.<b>()
#包括三类函数
#时间获取: time() ctime() gmtime()
#时间格式化: strftime() strtime()
#程序计时: sleep(), perf_counter()
时间获取
| 函数 | 描述 |
|---|---|
| time() | 获取当前时间戳,即计算机内部时间值 |
| ctime() | 获取当前时间,格式是,星期、‘月、日、时间、年份’ |
| gmtime() | 获取当前时间,表示为计算机程序可编程利用的时间格式 |
>>> time.time()
1610244498.6032174 #表示从1970年1月1日0:00 开始至现在时刻的以秒为单位的数值
>>> time.ctime()
'Sun Jan 10 10:11:36 2021'
>>> time.gmtime()
time.struct_time(tm_year=2021, tm_mon=1, tm_mday=10, tm_hour=2, tm_min=29, tm_sec=12, tm_wday=6, tm_yday=10, tm_isdst=0)
时间格式化
类似字符串格式化,需要展示模板
| 函数 | 描述 |
|---|---|
| strftime(tpl,ts) | tpl是格式化模板字符串,用来定义输出效果,ts是计算机内部时间类型变量 |
| %Y | 年份 0000~9999 |
| %m | 月份 01~12 |
| %B | 月份名称 January ~December |
| %b | 月份名称缩写 Jan ~ Dec |
| %d | 日期 01~31 |
| %A | 星期 Monday ~ Sunday |
| %a | 星期缩写 Mon ~ Sun |
| %H | 小时 00 ~ 23 |
| %I | 小时 01 ~ 12 |
| %p | 上下午 AM,PM |
| %M | 分钟 00 ~ 59 |
| %S | 秒钟 00 ~ 59 |
| strptime(str,tpl) | str是字符串形式的时间值,tpl是格式化模板字符串,用来定义输入效果 |
>>> time.strftime("%Y-%m-%d %H:%M:%S",t)
'2021-01-10 02:37:19'
>>> time.strptime('2021-01-10 02:37:19',"%Y-%m-%d %H:%M:%S")
time.struct_time(tm_year=2021, tm_mon=1, tm_mday=10, tm_hour=2, tm_min=37, tm_sec=19, tm_wday=6, tm_yday=10, tm_isdst=-1)
程序计时运用
测量起止动作所经历的时间
测量时间函数:perf_counter()
产生时间函数:sleep()
| 函数 | 描述 |
|---|---|
| perf_counter() | 返回一个CPU级别的精确时间计数值,单位为秒。由于这个计数值起点不确定,连续调用差值才有意义 |
| sleep(s) | s 拟休眠时间,单位是秒,可以是浮点数 |
示例:
import time
>>> start = time.perf_counter()
>>> end = time.perf_counter()
>>> end - start
21.654742400000032
>>> def wait():
time.sleep(3.3)
>>> wait() # 这里则表示调用函数wait,使程序等待3.3秒再结束
0x5 【实列】 文本进度条
文本进度条问题要求:
采用字符串方式打印可以动态变化的文本进度条
进度条需要能在一行中逐渐变化
采用sleep()模拟一个持续进度
####初步结构
#TExtPorBarV1.py
import time
scale = 10
print("------执行开始------")
for i in range(scale +1):
a = '*' * i
b = '.' * (scale - i)
c = (i/scale)*100
print("{:^3.0f}%[{}->{}]".format(c,a,b))
time.sleep(0.1)
print("------执行结束------")
输出
文本进度条的单行动态刷新
刷新的本质是:用后打印的字符覆盖之前的字符
不能换行:print()需要被控制
要能回退:打印后光标退回到之前的位置\r
#TextProBarV1.py
import time
for i in range(101):
print("\r{:3}%".format(i),end="")
time.sleep(0.1)
输出:
IDLE输出会将每一个结果输出,用cmd命令提示符运行即可看到效果
完整文本进度代码
#TExtPorBarV1.py
import time
scale = 50
print("执行开始".center(scale//2))
start = time.perf_counter()
for i in range(scale +1):
a = '*' * i
b = '.' * (scale - i)
c = (i/scale)*100
dur = time.perf_counter() - start
print("\r{:^3.0f}%[{}->{}]{:.2f}s".format(c,a,b,dur),end="")
time.sleep(0.1)
print("\n"+"执行结束".center(scale//2,'-'))
time.sleep(1)
输出:
cmd输出
举一反三
比较不同排序方法的时间
进图条扩展
在任何运行时间需要较长的程序中增加进度条
在任何希望提高用户体验的应用中增加进度条
进度条是人机交互的纽带之一
文本进度条的不同设计函数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-oBrzKKut-1615378667829)(https://s3.ax1x.com/2021/01/10/slD9at.png)]
结论:开始慢,后来速度随着进度增加的函数更符合人的心理期望
10.程序控制结构
0x1 程序的分支结构
####单分支结构
if <条件>:
<语句块>
二分支结构
if <条件>:
<语句块1>
else:
<语句块2>
#示例:
guess = eval(input())
if guess == 99:
print("猜{}了".format("对"))
else:
print("猜{}了".format("错"))
#紧凑形式:
<表达式1> if <条件> else <表达式2>
guess = eval(input())
print("猜{}了".format("对" if guess == 99 else "错"))
紧凑形式中,if,else所对应的不是语句,而是表达式,不能赋值,只能放在类似上述的执行语句中
多分支
if <条件> :
<语句块1>
elif:
<语句块2>
else:
<语句块3>
条件判断操作符与C相同
逻辑保留字
and(&&)、or(||)、not(!)
if A > B or B < A :
<执行语句>
0x2 程序的异常处理
abc = eval(input("请输入数字"))
print(num**2)
请输入数字0.2
Traceback (most recent call last):
File "E:\python_item\text1.py", line 2, in <module>
print(num**2)
NameError: name 'num' is not defined
NameError 是python内部预定义的错误名称,可以作为错误类型进行判断
类似的python内部有许多错误名称,都可以用来判断
异常处理的基本使用
#执行出错执行下方操作
try:
<语句块1>
except:
<语句块2>
#判断是否属于某种错误,该错误再执行下方操作
try:
<语句块1>
except <异常名称>:
<语句块2>
#异常处理的高级使用
try:
<语句块1>
except: #发生异常时执行
<语句块2>
else: #不发生异常时执行
<语句块3>
finally: #finally对应语句块4一定执行
<语句块4>
0x3 身体质量指数BMI
问题分析:body Mass index
定义:BMI = 体重(kg)/身高^2 (m^2)
国际标准:世界卫生组织 国内:国家卫生健康委员会
| 分类 | 国际BMI(kg/m^2) | 国内BMI值(kg/m^2) |
|---|---|---|
| 偏瘦 | < 18.5 | < 18.5 |
| 正常 | 18.5~25 | 18.5~24 |
| 偏胖 | 25~30 | 24~28 |
| 肥胖 | ≥30 | ≥28 |
问题需求:输入体重和身高值
#CalBMIv1.py
height,weight = eval(input("请输入身高(米)和体重\(公斤)[逗号隔开]"))
bmi = weight / pow(height,2)
print("BMI 数值为:{:.2f}".format(bmi))
who = ''
if bmi < 18.5:
who = "偏瘦"
elif 18.5 <= bmi <25 :
who = "正常"
elif 25 <= bmi < 30:
who = "偏胖"
else:
who = "肥胖"
print("BMI 指标为:国际'{0}'".format(who))
#输出:
请输入身高(米)和体重\(公斤)[逗号隔开]1.8,73
BMI 数值为:22.53
BMI 指标为:国际'正常'
#CalBMIv2.py
height,weight = eval(input("请输入身高(米)和体重\(公斤)[逗号隔开]"))
bmi = weight / pow(height,2)
print("BMI 数值为:{:.2f}".format(bmi))
who,nat = "",""
if bmi < 18.5:
who,nat = "偏瘦","偏瘦"
elif 18.5 <= bmi <24 :
who,nat= "正常","正常"
elif 24 <= bmi < 25:
who,nat= "正常","偏胖"
elif 25 <= bmi < 28:
who,nat= "偏胖", "偏胖"
elif 28 <= bmi < 30:
who,nat= "偏胖","肥胖"
else:
who,nat= "肥胖","肥胖"
print("BMI 指标为:国际'{0}',国内'{1}'".format(who,nat))
#输出:
请输入身高(米)和体重\(公斤)[逗号隔开]1.8,73
BMI 数值为:22.53
BMI 指标为:国际'正常',国内'正常'
多分支组合注意
多分支条件之间的覆盖要分析清除
程序可运行,但不正确要注意多分支
阅读代码时,先看分支
0x4 程序的循环结构
for遍历
for <循环变量> in <遍历结构>:
<语句块>
for i in range(N): # range(N)产生数字序列,包含N个元素 0 到 N-1.
<语句块>
for i in range(M,N,K): #产生以M开始不到N的以K为步长取数的序列
for c in s : #字符串遍历,s是字符串,取出s中每个字符到循环变量中,执行语句
for item in ls : #对列表进行遍历,取出每个列表元素遍历 [123,"PY",456]
for line in fi : #文件遍历循环,fi文件标识符,遍历文件每一行,
print(line) #打印每行
还可以对元组等遍历循环,只要是多个元素组成的数据结构,都可以用for in 遍历
逐一从遍历结构中提取元素到循环变量中,然后执行语句块
while循环
while <条件判断> :
<语句块>
循环控制保留字
break 和 continue 与 C 含义相同
for c in "PYTHON" :
if c =="T":
break #或者写continue
print(c , end ='')
循环高级用法
#else没有被break退出时,循环正常完成,则执行else语句
#for循环加else
for <循环变量> in <遍历结构> :
<语句块1>
else:
<语句块2>
#while循环加else
while <条件> :
<语句块1>
else:
<语句块2>
0x5 random库使用
random库介绍
random库时使用随机数的python标准库,主要用于生成随机数
伪随机数:采用梅森旋转算法生成的伪随机序列中元素
import random
基本随机数函数:seed(),random()
扩展随机数函数:randint(),getrandbits(),uniform(),randrange(),choice(),shuffle()
基本随机数函数
随机数种子:用来通过梅森旋转算法产生随机序列,随机序列中的数就是随机数
| 函数 | 描述 |
|---|---|
| seed(a = None) | 初始化给定的随机数种子,默认为当前系统时间(精确到微妙) |
| random() | 生成一个[0.0 ,1.0)之间的随机小数 |
>>> import random
>>> random.seed(1)
>>> random.random()
0.13436424411240122
>>> random.random()
0.8474337369372327
#设定seed(10),在不同设备上产生的随机数时一致的,为了再现随机程序,再次设定后调用产生的随机数结果也是一样的
扩展随机数函数
| 函数 | 描述 |
|---|---|
| randint(a,b) | 生成一个[a,b]之间的随机整数 |
| randrange(m,n[,k]) | 生成一个[m,n]之间以k为步长的随机整数 |
| getrandbits(k) | 生成一个k比特长度随机整数 |
| uniform(a,b) | 生成一个[a,b]之间的随机小数,16位精度 |
| choice(seq) | 从序列seq中随机选择一个元素 |
| shuffle(seq) | 将序列seq中元素随机排列,返回打乱后的序列 |
>>> random.randint(1,100)
98
>>> random.randrange(0,100,10)
40
>>> random.getrandbits(8)
126
>>> random.getrandbits(32)
3268308804
>>> random.uniform(1,10)
5.045419583098643
>>> s = [1,2,3,4,5,6,7,8,9,0]
>>> random.choice(s)
7
>>> random.shuffle(s)
>>> print(s)
[5, 9, 3, 7, 6, 0, 1, 8, 2, 4]
>>> random.shuffle(s)
>>> print(s)
[8, 2, 1, 4, 0, 5, 3, 9, 7, 6]
>>> import random;s=[1,2,3,4,5];random.shuffle(s);print(s) #可以用分号;将语句放到一行
[3, 1, 5, 2, 4]
0x6 实例 圆周率计算
问题分析
圆周率的近似计算公式
]") 无限求和公式
无限求和公式
蒙特卡罗方法
对正方形随机撒点,撒点数量的比值
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-PZEV3Jtk-1615378667830)(https://s3.ax1x.com/2021/01/11/s3tylj.png)]
公式法
#CalPiv1.py
pi = 0
N = 100
for k in range(N):
pi += 1/pow(16,k)*( \ # \ 可用于换行,不影响程序运行可以多次使用,提高可读性
4/(8*k +1) - 2/(8*k +4) - \
1/(8*k +5) - 1/(8*k+6))
print("圆周率值是:{}".format(pi))
输出:
圆周率值是:3.141592653589793
蒙特卡罗法
#CalPiv1.py
from random import random
from time import perf_counter
DARTS = 10000*10000
hits = 0.0
start = perf_counter()
for i in range(1,DARTS+1):
x,y = random(),random()
dist = pow(x**2+y**2,0.5)
if dist <= 1.0:
hits = hits + 1
pi = 4 *(hits/DARTS)
print("圆周率值是:{}".format(pi))
print("运行时间是:{:.5f}s".format(perf_counter()-start))
圆周率值是:3.143908
运行时间是:0.71663s
圆周率值是:3.14156908
运行时间是:59.99088s
理解方法思维
数学思维
计算思维
四色定理
-
程序运行时间分析
程序运行80%的时间消耗在不到10%的循环代码上
用于求解某个特定图形的面积
11.函数和代码复用
###0x1 函数的定义及使用
####函数的理解与定义
是一种抽象
定义的时候可以没有参数,但必须有括号
def <函数名>(参数):
<函数体>
return <返回值>
示例:
def dayUP(df): #函数dayUP
dayup = 1
for i in range(365):
if i % 7 in[6,0]:
dayup = dayup*(1 - 0.01)
else:
dayup = dayup * (1 + df)
return dayup
####函数的使用及调用过程
函数调用是,用实际值替换函数中参数
####函数的参数传递
可选参数传递
#调用参数时,必须有必选参数。可选参数可以没有,如果没有,则使用定义的默认值
def <函数体>(<必选参数>,<可选参数>):
<函数体>
return <返回值>
示例:
#1
def fact(n,m=1):
s = 1
for i in range(1,n+1):
s *= i
return s//m
print(fact(10))
3628800
#2计算n的阶乘,m = 1是默认的参数,不给指定参数则默认为1
def fact(n,m=1):
s = 1
for i in range(1,n+1):
s *= i
return s//m
print(fact(10,5))
725760
可变参数传递
#多个可变参数调用
def fact(n,*b): # *b表示可变参数
s = 1
for i in range(1,n+1):
s *= i
for item in b : #如果b是一个列表, in b 将依次调用 b 中的值赋给item
s *= item
return s
示例:n!乘数
def fact(n,*b): # *b表示可变参数
s = 1
for i in range(1,n+1):
s *= i
for item in b : #如果b是一个列表, in b 将依次调用 b 中的值赋给item
s *= item
return s
print(fact(10,11,12,13))
print(fact(13))
6227020800
6227020800
函数调用时,参数可以按照位置或名称方式传递(代表地址)
位置传递
名称传递

####函数的返回值
return,和c类似,不一定有返回值,或者传多个
但是返回的语法不同

多个返回的是 元组数据类型
>>> def fact(n,m=1) :
s = 1
for i in range(1,n+1):
s *= i
return s//m,n,m
>>> a,b,c = fact(10,5) #元组类型赋值,输出
>>> print(a,b,c)
725760 10 5
>>>
####局部变量和全局变量
函数定义,就属于全局变量
#####规则1 局部变量与全局变量不同
函数定义的函数体中的是局部变量
函数运算结束后,局部变量会释放
函数内部的局部变量可以可以和外部的变量重名,但不同
全局变量的函数调用
#使用 global 保留字在函数内部使用全局变量
n,s = 10 , 100
def fact(n):
s = 1
for i in range(1, n+1):
s *= i
return s
print(fact(n),s) #此处s 是全局变量s
——————————————————————————————————————————
n,s = 10 , 100
def fact(n):
global s #此处表示使用的是全局变量S
for i in range(1, n+1):
s *= i
return s #此处是指全局变量s的运算结果
print(fact(n),s) #此处s 是全局变量s,但是被函数运算修改了
#####规则2
局部变量为组合数据类型且在函数内部未创建时,且它的名字和全局变量同名,则该函数内部的变量等同于全局变量,即全局变量会发生改变
#ls在函数内部为全局变量
ls = ["F","f"] #通过使用[]“真实"创建了一个全局变量列表ls
def func(a) :
ls.append(a) #此处ls是列表类型,未真实创建则等同于全局变量
return
fun("C") #全局变量ls被修改
print(ls)
运行结果
['F','f','C']
-------------------------------
#ls在函数内部为局部变量
ls = ["F","f"] #通过使用[]“真实"创建了一个全局变量列表ls
def func(a) :
ls = [] #此处在函数内部被真实创建,此时则为局部变量
ls.append(a) #此处ls是列表类型
return
fun("C")
print(ls)
运行结果
['F','f','C']
此处组合数据类型与C语言中的指针相对应,如果在函数内部没有创建,则以指针的方式调用外部变量
规则总结
基本数据类型,无论是否重名,局部变量与全局变量不同,可以通过global保留字在函数内部声明全局变量
组合数据类型,如果局部百年来未真实创建,则是全局变量
####lambda函数
返回一个函数名,是一种匿名函数
用于定义简单的、能够在一行内表示的函数
<函数名> = lambda <参数>:<表达式>
等价于def,区别是,内容只能是表达式,不能是函数体
>>> f = lambda x,y: x+y
>>> f(10,15)
25
>>> f = lambda : "lambda函数"
>>> print(f())
lambda函数
建议使用def定义函数,特殊情况使用lambda
###0x2 实例七段数码管绘制
问题分析
七段不同的数码管的亮暗,可以显示数字,字母
用程序绘制七段数码管
效果
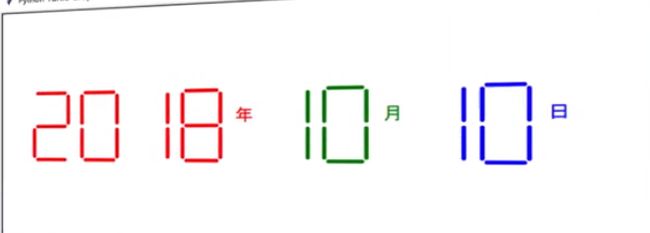
基本思路
绘制单个数字,对应数码管
获得一串数字,一一表示
获得系统时间,表示出来
代码
第一步,绘制单个数字,对应数码管
import turtle
def drawLine(draw): #单段数码管,函数绘制一条线,并且判断该线是越过还是画
turtle.pendown()if draw else turtle.penup()
turtle.fd(40)
turtle.right(90)
def drawDight(digit): #根据数字绘制七段数码管
drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,6,8] else drawLine(False)
turtle.left(90)
drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180)
turtle.penup() #为绘制后续数字确定位置
turtle.fd(20) #为绘制后续数字确定位置
第二步,获得一串数字,一一表示
def drawDate(date): #获得要输出的数字
for i in date:
drawDight(eval(i)) #通过eval()函数将数字变成整数
def main():
turtle.setup(800,350,200,200)
turtle.penup()
turtle.fd(-300)
turtle.pensize(5)
drawDate('20181010')
turtle.hideturtle()
turtle.done()
main()
第三步,获得系统时间,表示出来
import turtle
import time
def drawLine(draw): #单段数码管,函数绘制一条线,并且判断该线是越过还是画
turtle.pendown()if draw else turtle.penup()
turtle.fd(40)
turtle.right(90)
def drawDight(digit): #根据数字绘制七段数码管
drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,6,8] else drawLine(False)
turtle.left(90)
drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180)
turtle.penup() #为绘制后续数字确定位置
turtle.fd(20) #为绘制后续数字确定位置
def drawDate(date): #获得要输出的数字
for i in date:
drawDight(eval(i)) #通过eval()函数将数字变成整数
def main():
turtle.setup(800,350,200,200)
turtle.penup()
turtle.fd(-300)
turtle.pensize(5)
drawDate(time.strftime("%H%M%S"))
turtle.hideturtle()
turtle.done()
main()
代码优化
增加绘制间的距离
增加绘制年月日
获取时间
import turtle
import time
def drawGap():
turtle.penup()
turtle.fd(5)
def drawLine(draw): #单段数码管,函数绘制一条线,并且判断该线是越过还是画
drawGap()
turtle.pendown()if draw else turtle.penup()
turtle.fd(40)
drawGap()
turtle.right(90)
def drawDight(digit): #根据数字绘制七段数码管
drawLine(True) if digit in [2,3,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,3,4,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,6,8] else drawLine(False)
turtle.left(90)
drawLine(True) if digit in [0,4,5,6,8,9] else drawLine(False)
drawLine(True) if digit in [0,2,3,5,6,7,8,9] else drawLine(False)
drawLine(True) if digit in [0,1,2,3,4,7,8,9] else drawLine(False)
turtle.left(180)
turtle.penup() #为绘制后续数字确定位置
turtle.fd(20) #为绘制后续数字确定位置
def drawDate(date): #改获得日期格式为,'%Y-%m=%d+',判断符号进行替换
turtle.pencolor("red")
for i in date:
if i == '-':
turtle.write('年',font=("Arial",30,"normal"))
turtle.pencolor("green")
turtle.fd(40)
elif i == '=' :
turtle.write('月',font=("Arial",30,"normal"))
turtle.pencolor("blue")
turtle.fd(40)
elif i == '+' :
turtle.write('日',font=("Arial",30,"normal"))
else:
drawDight(eval(i)) #通过eval()函数将数字变成整数
def main():
turtle.setup(800,350,200,200)
turtle.penup()
turtle.fd(-300)
turtle.pensize(5)
drawDate(time.strftime('%Y-%m=%d+',time.gmtime()))
turtle.hideturtle()
turtle.done()
main()
举一反三
理解模块化方法思维:确定模块接口,封装功能
规则化思维:抽象过程为规则,
化繁为简:分治
####扩展
到小数点
倒计时时刷新
14段的数码管
数码管有更多段
0x3 代码复用与函数递归
####代码复用与模块化设计
代码资源化:程序代码是一种用来表达计算的”资源“
代码抽象化:使用函数等方法对代码赋予更高级别的定义
代码复用:函数和对象
函数:将代码命名,在代码层面建立了初步抽象
对象:属性和方法,在函数之上再次组织进行抽象
<a>.<b> 和 <a>.<b>()
####分而治之
通过函数或对象分装将程序划分为模块及模块间的表达
具体包括:主程序、子程序、和子程序的关系
紧耦合 交流多无法独立
松耦合 交流少可以独立
函数内部要紧耦合,模块之间要松耦合
函数递归的理解
函数中调用自身
####函数递归的调用过程
def fact(n):
if n == 0:
return 1
else :
return n*fact(n-1)
fact(5)
####函数递归实例解析
#####字符串反转
将字符串s反转后输出
s[::-1]
函数 +分支结构
递归链条
递归基例
>>> def rvs(s):
if s == "" :
return s
else :
return rvs(s[1:])+s[0]
>>> s = '这是一个字符串'
>>> rvs('这是一个字符串')
'串符字个一是这'
#####斐波那契数列
def f(n):
if n==1 or n==2 :
return 1
else :
return f(n-1) + f(n-2)
#####汉诺塔问题
思考n-1和n的关系
count = 0
def hanoi(n,src,dst,mid):
global count
if n == 1:
print("{}:{}->{}".format(1,src,dst))
count += 1
else :
hanoi(n-1,src,mid,dst)
print("{}:{}->{}".format(n,src,dst))
count += 1
hanoi(n-1,mid,dst,src)
hanoi(3,"A","C","B")
print(count)
输出
1:A->C
2:A->B
1:C->B
3:A->C
1:B->A
2:B->C
1:A->C
7
0x4 PyInstaller库的使用
####基本介绍
将.py源代码转换为无需源代码的可执行程序文件
windows(exe)、linux、macos均可
它是一个第三方库
需要额外安装
使用pip工具安装
在cmd中输入
pip install pyinstaller
####使用说明
(cmd命令执行) pyinstaller -F <文件名.py>
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-TNRDLB6q-1615378667833)(https://s3.ax1x.com/2021/01/20/sR5VBD.png)]
帮助显示命令
(cmd命令执行) pyistaller -h
更多常用参数
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-5Q1D6tKU-1615378667834)(https://s3.ax1x.com/2021/01/20/sRopS1.png)]
####实例
产生有图标的文件

0x5 实例 科赫雪花小包裹
####科赫曲线
分形几何
有迭代关系的几何图形
用python绘制科赫曲线
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-jh6ZHr1F-1615378667838)(https://s3.ax1x.com/2021/01/20/sRTFcq.png)]
绘制不同阶数的科赫曲线
import turtle
def koch(size,n) : #确定大小和阶数
if n == 0: #当n=0时,画直线
turtle.fd(size)
else:
for angle in [0,60,-120,60]: #一阶曲线
turtle.left(angle)
koch(size/3,n-1)
def main():
turtle.setup(800,400)
turtle.penup()
turtle.goto(-300,-50)
turtle.pendown()
turtle.pensize(2)
koch(600,3) #3阶科赫曲线,阶数
turtlw.hideturtle
连成雪花
import turtle
def koch(size,n) : #确定大小和阶数
if n == 0: #当n=0时,画直线
turtle.fd(size)
else:
for angle in [0,60,-120,60]: #一阶曲线
turtle.left(angle)
koch(size/3,n-1)
def main():
turtle.setup(600,600)
turtle.penup()
turtle.goto(-200,100)
turtle.pendown()
turtle.pensize(2)
level = 4
koch(400,level) #3阶科赫曲线,阶数
turtle.right(120)
koch(400,level)
turtle.right(120)
koch(400,level)
turtlw.hideturtle()
main()
####科赫雪花小包裹
用pylnstaller打包
####绘制条件的扩展
修改阶数
修改科赫曲线的基本定义及旋转角度
修改绘制科赫雪花的基础框架图形
分形几何很多
康托尔集
谢尔宾斯基三角形
门格海绵,龙形曲线,空间填充曲线
12.组织数据类型
一个数据表达一个含义
一组数据表达多个含义
类型结构:
集合类型、序列类型、字典类型
0x1 集合类型及操作
####集合类型定义
多个元素的无需组合
与数学概念一致
集合元素之间无序,每个元素唯一,不存在相同元素
集合元素不可更改,不能是可变数据类型
####建立集合
集合用{ } 建立或set(),元素用逗号分隔
建立空集合必须用set(),相同元素合并
>>> A = {"python",123,("python",123)}
>>> print(A)
{123, 'python', ('python', 123)}
>>> B = set("pupu123")
>>> print(B)
{'3', 'p', '2', '1', 'u'}
元素唯一,无序,{}表示逗号分隔
####集合操作符
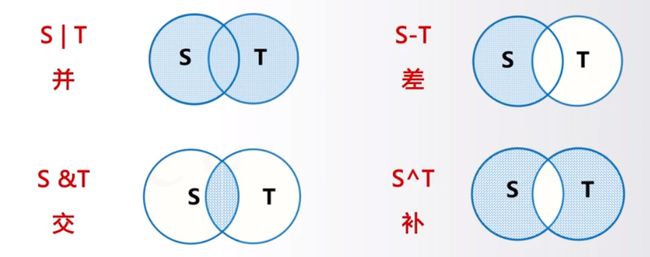

关系操作符返回true或false
####增强操作符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-W1rQlniq-1615378667839)(https://s3.ax1x.com/2021/01/20/sW38QU.png)]
>>> A = {"p","y",123}
>>> B = set("pypy123")
>>> print(B)
{'1', 'y', '3', '2', 'p'}
>>> print(A)
{'p', 123, 'y'}
>>> A - B
{123}
>>> A | B
{'1', 'y', '3', '2', 'p', 123}
>>> A & B
{'p', 'y'}
>>> A ^ B
{'3', '1', '2', 123}
####集合处理方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-wzesiL5w-1615378667840)(https://s3.ax1x.com/2021/01/20/sWtqJA.png)]

输出全部元素实例
#方法1 遍历
A = {"p","y",123}
for item in A:
print(item,end="")
y123p
#方法2 使用pop函数
try:
while True:
print(A.pop(),end="")
except:
pass
y123p
python存储元素与实际计算机存储的元素顺序不相符,固输出顺序不同
####集合类型应用场景
包含关系比较
>>> "p" in {"p","y",123}
True
>>> {'p','y'} >= {"p","y",123}
False
####数据去重
利用集合元素无序且唯一的特点对数据去重
ls = ["p","p","y","y",123]
s =set(ls) #此处将列表类型转换为集合类型
{'p','y',123}
lt = list(s) #此处为集合类型转换为列表类型
['p','y',123]
#程序运行
>>> ls = ["p","p","y","y",123]
>>> s =set(ls)
>>> lt = list(s)
>>> print(lt)
['y', 123, 'p']
0x2 序列类型及操作
序列类型定义
序列具有先后关系的一组元素
序列是一维元素向量,元素类型可以不同
类似数学元素序列:S0,S1,…,Sn-1
元素间由序号引导,通过下标访问序列的特定元素
序列是一个基类类型
序列类型,衍生出字符串类型、元组类型、列表类型
####序号的定义
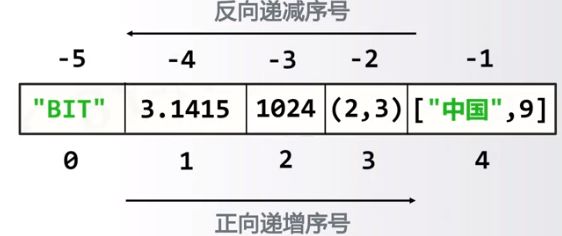
####序列处理函数及方法
6个操作符
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9toS4WHT-1615378667841)(https://s3.ax1x.com/2021/01/20/sWO1yj.png)]
实例
>>> ls = ["python",123,".io"]
>>> ls[::-1]
['.io', 123, 'python']
>>> s = "python123.io"
>>> s[::-1]
'oi.321nohtyp'
####五个函数和方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-a5bmreuL-1615378667842)(https://s3.ax1x.com/2021/01/20/sfSTBQ.png)]
例子
>>> ls = ["python",123,".io"]
>>> len(ls)
3
>>> s = "python123.io"
>>> max(s)
'y' #根据字母排序得出
>>> t = "a987b" #字母大于数字
>>> max(t)
'b'
>>> t = "0987341"
>>> max(t)
'9'
####元组类型及操作
序列类型的扩展
一旦创建不能被修改
使用小括号()或者tuple创建,元素间用逗号分隔
可以不适用或使用小括号
返回的实际上是一个值,返回的数据类型是元组类型
def func():
return 1,2
#####元组类型定义
>>> create = "cat","dog","tiger","human"
>>> create
('cat', 'dog', 'tiger', 'human')
>>> color = (0x001100,"blue",create)
>>> color
(4352, 'blue', ('cat', 'dog', 'tiger', 'human'))
继承序列的全部通用操作
####列表类型及操作
列表是一种序列类型,创建后可以随意被修改
使用方括号[]或list()创建,元素间用逗号,分隔
列表中类型可以不同,没有长度限制
#####列表类型定义
此处并没有真正的将ls列表内的值赋给lt,而是将该列表新定义了一个名字
这里使用了内存和指针的概念
['cat', 'dog', 'tiger', 'human', 1024]
>>> lt = ls
>>> lt
['cat', 'dog', 'tiger', 'human', 1024]
####列表类型的操作函数和方法
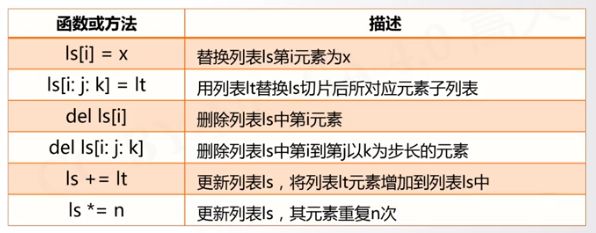
实例
切片替换
>>> ls = ['cat', 'dog', 'tiger', 'human',1024]
>>> ls[1:2]
['dog']
>>> ls[1:2] = [1,2,3,4]
>>> ls
['cat', 1, 2, 3, 4, 'tiger', 'human', 1024]
删除
['cat', 1, 2, 3, 4, 'tiger', 'human', 1024]
>>> del ls[::3]
>>> ls
[1, 2, 4, 'tiger', 1024]
#####更多方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-y4quAOAx-1615378667842)(https://s3.ax1x.com/2021/01/20/sfmHMj.png)]
####序列类型应用场景
用于数据表示
元组用于元素不改变的应用场景,更多用于固定搭配场景
列表更灵活,是最常用的序列类型
表示一组有序数据,进而操作它们
元素遍历
for item in ls :
<语句块>
for item in tp :
<语句块>
数据保护
将列表类型转换为元组类型,从而达到保护数据的目的
>>> ls = ["cat","dog","tiger",1024]
>>> lt = tuple(ls) #用于将列表类型转换为元组类型
>>> lt
('cat', 'dog', 'tiger', 1024)
元组类型数据不会修改数据,在多人写程序的情况,接口的传递
####实例 基本统计值计算
基本统计值
总个数、求和、平均值、方差、中位数
总个数:len()
求和:for …in
平均值:求和/总个数
方差:各数据与平均数差的平方的和的平均数
中位数:排序,然后…奇数找最中间的1个,偶数找中间2个取平均
通过函数,完成不同的功能
假定数据是用户输入,数量不确定
用户输入和输入结束函数
def getNum():
nums =[]
iNumStr = input("请输入数字(回车退出):")
while iNumStr != "": #当输入为空是退出
nums.append(eval(iNumStr))
iNumStr =input("请输入数字(回车退出):")
return nums
求和
def mean(numbers): #计算平均值
s = 0.0
for num in numbers:
s = s + num
return s / len(numbers)
计算方差
def dev(numbers,mean): #输入numbers列表,mean是平均值
sdev = 0.0
for num in numbers :
sdev = sdev + (num - mean)**2 #取出每个数与平均值做差求平方,累加
return pow(sdev/(len(numbers)-1),0.5) #对中位数开方返回
计算中位数
def median(numbers):
sorted(numbers)
size = len(numbers)
if size % 2 == 0:
med = (numbers[size//2-1] + numbers[size//2])/2
else:
med = numbers[size//2]
return med
调用
n = getNum()
m = mean(n)
print("平均值:{},方差:{:.2},中位数:{}.".format(m,dev(n,m),median(n)))
举一反三
获取多个用户输入的方法
分隔多个函数,模块化
####字典类型及操作
字典类型定义
映射
索引和数据的对应关系,键和值
属性和值,一种属性对应一个值
例如
"streetAddr":"中关村南大街5号"
"zipcode": "100081"
比较序列类型和映射类型
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-9Tl4Mf0b-1615378667843)(https://s3.ax1x.com/2021/01/21/shi7Cj.png)]
字典类型是映射的体现
键相当于值的标签,找到标签就可获得值
键值对:键是数据索引的扩展
字典是键值对的集合,键值对之间无序
采用大括号{}和dict创建,键值对用冒号:表示
{<键1>:<值1>,<键2>:<值2>,...,<键n>:<值n>}
字典变量作用
在字典变量中,通过键获得值
<字典变量> = {<键1>:<值1>,<键2>:<值2>,...,<键n>:<值n>}
<值1> = <字典变量>[<键1>]
<字典变量>[<键1>] = <值1>
>>> d = {"first" : 1 ,"second":2,"third":3}
>>> d["first"]
1
生成空字典
空的集合类型定义不用{},将 {} 留给字典类型
>>> de = {} ; type(de) #检测变量类型
<class 'dict'>
字典处理函数及方法

>>> d = {"first":1,"second":2,"third":3}
>>> d.keys()
dict_keys(['first', 'second', 'third'])
>>> d.values()
dict_values([1, 2, 3])
返回字典的key类型,可以用for in 遍历,不能像列表一样操作
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-EuZ0jLe8-1615378667844)(https://s3.ax1x.com/2021/01/21/shOQ6e.png)]
示例
>>> d.get("first","forth")
1
>>> d.get("fifth","forth") #此时forth是错误时返回的值
'forth'
>>> d.popitem()
('third', 3)
字典类型应用场景
对映射的表达
表达键值对数据,进而操作它们
元素遍历
for k in d :
<语句块>
0x3 模块 jieba库的使用
中文分词第三方库,需额外安装
(cmd命令行) pip install jieba
jieba提供三种分词模式
一般掌握一种足以
jieba通过中文词库方式识别分词
利用一个中文词库,确定汉字之间的关联概率
汉字间概率大的组成自促,形成分词结果
除了分词,用户还可以添加自定义的词组
三种模式
精确模式、全模式、搜索引擎模式
精确模式 : 把文本精确的切分开,不存在冗余单词
全模式: 把文本中所有可能的词语都扫描出来,由冗余
搜索引擎模式: 在精确模式基础上,对长词再次切分
常用函数

>>> import jieba
>>> jieba.lcut("我今天去美国找了特朗普总统谈话")
['我', '今天', '去', '美国', '找', '了', '特朗普', '总统', '谈话']

0x4 实例 文本词频统计
英文文本:Hamlet
中文文本:三国演义
####Hamet英文词频统计实例讲解
#CalHamletV1.py
def getText():
txt = open("hamlet.txt","r").read() #打开文件
txt = txt.lower() #将英文变成小写
for ch in '!"#$%&()*+,-./:;<=>?@[\\]^_‘{|}~': #逐一选取特殊符号
txt = txt.replace(ch," ") #将特殊符号替换为空格
return txt #返回替换后的文本
hamletTxt = getText() #将返回的文本赋给hamlettxt
words = hamletTxt.split() #文本分隔方法,以空格分隔
counts = {} #根据映射关系,定义一个空字典
for word in words:
counts[word] = counts.get(word,0) + 1
#形成键值对,get得到该词键对应的值+1,然后将新+1的值映射给该词键
#遍历了文本字符串内的所有元素
items = list(counts.items()) #将字典类型转换为列表类型
items.sort(key=lambda x:x[1],reverse=True) #将一个列表按照键值对的两个元素中的第二个元素进行排序,从大到小
for i in range(10): #打印前十个,词和对应出现的次数
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
####三国演义
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
else:
counts[word] = counts.get(word,0) + 1
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(15):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
曹操 953
孔明 836
将军 772
却说 656
玄德 585
关公 510
丞相 491
二人 469
不可 440
荆州 425
玄德曰 390
孔明曰 390
不能 384
如此 378
张飞 358
####深入讲解
将词频与人物相关联,面向问题
词频统计 人物统计
去除排名靠前但不是人物的词语
import jieba
txt = open("threekingdoms.txt","r",encoding="utf-8").read()
excludes = {"将军","却说","荆州","二人","不可","不能","如此","如何","商议","军士","左右","军马","引兵","次日","大喜","天下","东吴","于是","今日","不敢","魏兵"}
words = jieba.lcut(txt)
counts = {}
for word in words:
if len(word) == 1:
continue
elif word == "诸葛亮" or word == "孔明曰":
rword = "孔明"
elif word == "关公" or word == "云长":
rword = "关羽"
elif word == "玄德" or word == "玄德曰":
rword = "刘备"
elif word == "孟德" or word == "丞相":
rword = "曹操"
else:
rword = word
counts[rword] = counts.get(rword,0) + 1
for word in excludes:
del counts[word]
items = list(counts.items())
items.sort(key=lambda x:x[1],reverse=True)
for i in range(8):
word,count = items[i]
print("{0:<10}{1:>5}".format(word,count))
####应用问题的扩展
绘制词云
对红楼梦、西游记、水浒传分析
政府工作报告、科研论文、新闻报道等
13.文件和数据格式化
格式化
将字符串按照样式规范
数据格式化
将一组数据按照一定规格和样式进行规范:表示、存储、运算等
方法论 从python角度理解文件和数据表示
0x1 文件的使用
####文件的类型
文件 文件时数据的抽象和集合
文件时存储在辅助存储器上的数据序列
文件时数据存储的一种形式
文件展现形态:文本文件和二进制文件
所有文件都是二进制形式存储的,只是表现形式不同
文本文件
由单一特定编码组成的文件
也可以理解为字符串
二进制文件
直接由0和1组成,没有编码
两种形式都可以二进制形式打开
文本形式打开文件
tf = open("f,txt","rt")
print(tf.readline())
tf.close()
this is a word 123abc
#当文件中有中文时,读取文件内容会报如下错误
UnicodeDecodeError: 'gbk' codec can't decode byte 0xb9 in position 35: illegal multibyte sequence
二进制形式打开文件
bf = open("f.txt","rb")
print(bf.readline())
bf.close()
b'this is a word 123abc\xef\xbc\x8c\xe4\xb8\xad\xe6\x96\x87\xe5\x86\x85\xe5\xae\xb9\r\n'
####文件的打开和关闭
打开-操作-关闭
存储状态、占用状态
a = open(,)
a.close()
读写文件方法
#读文件
a.read(size)
a.readline(size)
a.realines(hint)
#写文件
a.write(s)
a.writelines(lines)
a.seek(offset)
文件打开
<变量名> = open(<文件名>,<打开模式>)
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-xtTfaNJM-1615378667845)(https://s3.ax1x.com/2021/01/23/sTpBMn.png)]
文件路径:
绝对路径
\ 表示转义符,所以路径要写成
D:/PYE/f.txt
或
D:\\PYE\\f.txt
相对路径
./PYE/f.txt
在同一文件夹下直接用文件名
"f.txt"
文件打开模式

默认时文本形式,只读模式
文件关闭
<变量名>.close()
程序结束后自动关闭
####文件的内容的读取
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-LGBFU55p-1615378667846)(https://s3.ax1x.com/2021/01/23/sTZs1K.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8cTnAGe2-1615378667846)(https://s3.ax1x.com/2021/01/23/sTZ4ht.png)]
一次读入,统一处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read()
#对全文txt进行处理
fo.close()
#采用一次读入,统一处理,文件过大不适用
按数量读入,逐步处理
适合大文件
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
txt = fo.read(2)
while txt !="":
#对txt进行处理
txt = fo.read(2)
fo.close()
逐行遍历
一次读入,分行处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo.readlines():
print(line)
fo.close()
分行读入、逐行处理
fname = input("请输入要打开的文件名称:")
fo = open(fname,"r")
for line in fo:
print(line)
fo.close()
####数据的文件写入
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-8WWi6nCl-1615378667847)(https://s3.ax1x.com/2021/01/23/sTmKGq.png)]
writelines直接将文字拼接写入文件,没有空格换行
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-l6HZqd5O-1615378667847)(https://s3.ax1x.com/2021/01/23/sTmrLD.png)]
输入位置指针,描述了当前在文件内写入的具体内存位置
fo = open("output.txt","w+")
ls = ["中国","法国","美国"]
fo.writelines(ls)
for line in fo:
print(line)
fo.close()
#此时输入指针在输入的末尾,之后是没有内容的,固没有输出
#修改如下,使用seek方法
fo = open("output.txt","w+")
ls = ["中国","法国","美国"]
fo.writelines(ls)
fo.seek(0) #将输入指针返回到最开始
for line in fo:
print(line)
fo.close()
###0x2 实例:自动轨迹绘制
自动轨迹绘制
根据脚本来绘制图形
写数据绘制图形
是自动化程序的重要内容
####基本思路
定义数据文件格式(接口)
根据文件接口解析参数绘制图形
编制数据文件
####数据接口定义
根据个人需求

####编写对应程序
map函数,将第一个参数对应的函数作用于一个列表或集合的每个元素
import turtle as t
t.title('自动轨迹绘制')
t.setup(800,600,0,0)
t.pencolor("red")
t.pensize(5)
#数据读取
datals = []
f = open("data.txt")
for line in f:
line = line.replace("\n","")
datals.append(list(map(eval,line.split(","))))
f.close()
#自动绘制
for i in range(len(datals)):
t.pencolor(datals[i][3],datals[i][4],datals[i][5])
#找到第i个参数,获取第3个值、第4个值,第5个值,即RGB参数
t.fd(datals[i][0]) #读取0位数据,获得绘制长度
if datals[i][1]: #根据判断是否转向,选择左右转的角度
t.right(datals[i][2])
else:
t.left(datals[i][2])
####理解方法思维
自动化思维
接口化设计
二维数据应用
拓展
增加更多接口
增加功能
增加应用动画绘制
###0x3 一维数据的格式化和处理
####数据组织的维度
线性方式组织
二维方式组织
多维、高维
一维数据
由对等关系的有序或无序数据构成,采用线性方式组织
对应列表数组和集合等概念
二维数据
由多个一维数据构成,是一维数据的组合形式
仅利用最基本的二元关系展示数据间的复杂结构
例如 键值对定义
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-ggAVn1uD-1615378667848)(https://s3.ax1x.com/2021/01/23/sThLpF.png)]
数据的操作周期
存储、表示、操作
存储格式、数据类型、操作方式
一维数据的表示
如何用程序类型表达一维数据
如果数据间有序:使用列表类型
可以用for循环遍历
数据无序:使用集合类型
可以使用for循环遍历
####一维数据的存储
存储方式
空格分隔 即存储的数据之间需要空格
但数据中不能由空格
逗号分隔 也如空格存在缺点
一般用特殊符号分隔
####一维数据的处理
读入
从空格分隔的文件中读入数据
txt = open(fname).read()
ls = txt.split()
f.close()
从特殊分隔的文件中读入数据
txt = open(fname).read()
ls = txt.split("$")
f.close()
写入
采用空格方式写入数据文件
ls = ['中国','美国','日本']
f = open(fname,'w')
f.write(''.join(ls)) #将' '作为分隔放到ls数据之间
f.close()
特殊分隔的方式写入数据文件
ls = ['中国','美国','日本']
f = open(fname,'w')
f.write('$'.join(ls)) #将'$'作为分隔放到ls数据之间
f.close()
###0x4 二维数据的格式化和处理
二维数据的表示
使用表格形式,使用二维列表
类似于C语言中的二维数组
使用列表类型
遍历需要两层for循环
数据维度是数据的组织形式
一维数据:列表和集合类型
有序用列表,无序用集合
####CSV数据存储格式
CSV Comma-Separated Values
用逗号来分隔值的一种存储方式
是国际通用的一二维数据存储格式,一般.CSV扩展名
每行一个一维数据,采用逗号分隔,无空行
Excel和一般编辑软件都可以读入或另存为CSV文件
####二维数据的存储
如果某个元素缺失,逗号仍要保留
二维数据的表头可以作为数据存储,也可以另行存储
逗号为英文半角逗号,逗号与数据至今无额外空格
数据中的逗号可以用引号标识,也可加转义符
数据如何存的,按行存或者按列存都可以,具体由程序决定
一般索引习惯:
ls [row][column]
####二维数据的处理
二维数据的读入处理
从CSV格式的文件读入数据
fo = open(fname)
ls = []
for line in fo:
line = line.replace("\n","")
ls.append(line.split(","))
fo.close()
将数据写入CSV格式的文件
ls = [[],[],[]] #二维列表
f = open(fname,'w')
for item in ls:
f.write(','.join(item) + '\n')
f.close()
遍历
采用二层循环
ls = [[1,2],[3,4],[5,6]] #二维列表
for row in ls:
for column in row:
print(column)
###0x5 模块:wordcloud库的使用
wordcloud是优秀的词云展示第三方库
将词语用可视化的方式,艺术的展示的文本
安装
(cmd命令行) pip install wordcloud
如果安装失败,报错查阅 https://www.jb51.net/article/198751.htm
使用说明
wordcloud库把词云当作一个WordClloud对象
wordcloud.WordCloud()代理一个文本对应的词云
绘制词云的形状、尺寸和颜色都可以设定
w = wordcloud.WordCloud()
以WordCloud对象为基础
配置参数、加载文本、输出文件

常规方法
配置对象参数
加载词云文本
输出词云文件
import wordcloud
c = wordcloud.WordCloud()
c.generate("Wordcloud by Python")
c.to_file("pyworcloud.png")
最后生成图片宽400高200像素
操作过程
以空格分隔单词
单词出现次数并过滤
根据统计配置字号
颜色环境尺寸
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-VUoeverh-1615378667849)(https://s3.ax1x.com/2021/01/23/s74oLj.png)]
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-FaPGXrDw-1615378667850)(https://s3.ax1x.com/2021/01/23/s7o7eH.png)]

[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-6JTC4alS-1615378667850)(C:\Users\71041\Desktop\Snipaste_2021-01-23_21-18-36.png)]
import wordcloud
txt = "life is short,you need python"
w = wordcloud.WordCloud(\
background_color = "white")
w.generate(txt)
w.to_file("pywcloud.png")
中文构成词云
import jieba
import wordcloud
txt = "程序设计语言是计算机能够理解和\
失败用户操作意图的一种交互体系,它按照\
特定规则组织计算机指令,使计算机能够自\
动进行各种运算处理。"
w = wordcloud.WordCloud(width=1000,\
font_path="msyh.ttc",height=700) #此处msyh为字体微软雅黑文件路径
w.generate(" ".join(jieba.lcut(txt))) #先变成列表,然后用join方法加空格
w.to_file("pywcloud.png") #输出为图片
###0x6 实例:政府工作报告词云
直观理解政策文件
《决胜全面建成小康社会 夺取新时代中国特色社会主义伟大胜利》
《中共中央关于乡村振兴的战略》
基本思路
读取文件
输出词云
观察结果、迭代
第一本
import jieba
import wordcloud
f = open("xjp.txt","r",encoding="utf-8") #打开文本
t = f.read() #将文本内容一次性读入t
f.close()
ls = jieba.lcut(t) #对文本进行分词,将分词结果保存为列表类型
txt = " ".join(ls) #词云需要长文本输入,用空格将列表元素链接起来
w = wordcloud.WordCloud(font_path = "msyh.ttc",\
width = 1000,height = 700,background_color = "white")
w.generate(txt)
w.to_file("grwordcloud.png")
限制文字输出量
import jieba
import wordcloud
f = open("xjp.txt","r",encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud(font_path = "msyh.ttc",\
width = 1000,height = 700,background_color = "white",\
max_words = 15) #限制显示的词
w.generate(txt)
w.to_file("grwordcloud.png")
词云形状
import jieba
import wordcloud
from scipy.misc import imread #引入库,用来读取图片文件,形成图片变量
mask = imread(" ")
f = open("xjp.txt","r",encoding="utf-8")
t = f.read()
f.close()
ls = jieba.lcut(t)
txt = " ".join(ls)
w = wordcloud.WordCloud(font_path = "msyh.ttc",mask = mask\ #将mask赋给mask参数
width = 1000,height = 700,background_color = "white",\
max_words = 15) #限制显示的词
w.generate(txt)
w.to_file("grwordcloud.png")
14.程序设计方法学
理解掌握Python程序设计思维
编写更有设计感的程序
0x1 实例 体育竞技分析
需求:毫厘是多少,如何可选分析体育竞技比赛
模拟N场比赛
计算思维 :抽象 + 自动化
模拟:抽象比赛过程+自动化执行N场比赛
N越大时,比赛结果分析会越科学
问题分析
比赛规则
双人击球比赛:A&B,回合制,5局3胜
开始时一方先发球,直至判分,接下来胜者发球
球员只能在发球局得分,15分胜一局
自顶向下
将总问题表达为若干小问题的分析方法
是解决复杂问日的有效方法
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-RWGvXaIV-1615378667851)(https://s3.ax1x.com/2021/01/27/sziYzd.png)]
第一阶段
介绍内容,提高用户体验
def printIntro():
print("这个程序模拟两个选手A和B的某种竞技比赛")
print("程序运行需要A和B的能力值(以0到1之间的小数表示)")
def getInputs():
a = eval(input("请输入选手A的能力值(0-1):"))
b = eval(input("请输入选手B的能力值(0-1):"))
n = eval(input("模拟比赛场次:"))
return a,b,n
def printSummary(winsA,winsB):
n = winsA + winsB
print("竞技开始分析,共模拟{}场比赛".format(n))
print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA,winsA/n))
print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB,winsB/n))
第二阶段
N次比赛,
def simNGames(n,probA,probB):
winsA,winsB = 0, 0
for i in range(n):
scoreA,scoreB = simOneGame(probA,probB)
if scoreA > scoreB:
winsA += 1
else:
winsB += 1
return winsA, winsB
def sim0neGame(probA,probB):
scoreA,scoreB = 0, 0
serving = "A"
while not gameOver(scoreA,scoreB):
if serving == "A":
if random() < probA:
scoreA += 1
else:
serving = "B"
else:
if random() < probB:
scoreB += 1
else:
serving = "A"
return scoreA,scoreB
def gameOver(a,b):
return a==15 or b==15
def main():
printIntro()
probA,probB, n = getInputs()
winsA,winsB = simNGames(n,probA,probB)
printSummary(winsA,winsB)
最终代码
from random import random
def printIntro():
print("这个程序模拟两个选手A和B的某种竞技比赛")
print("程序运行需要A和B的能力值(以0到1之间的小数表示)")
def getInputs():
a = eval(input("请输入选手A的能力值(0-1):"))
b = eval(input("请输入选手B的能力值(0-1):"))
n = eval(input("模拟比赛场次:"))
return a,b,n
def printSummary(winsA,winsB):
n = winsA + winsB
print("竞技开始分析,共模拟{}场比赛".format(n))
print("选手A获胜{}场比赛,占比{:0.1%}".format(winsA,winsA/n))
print("选手B获胜{}场比赛,占比{:0.1%}".format(winsB,winsB/n))
def simOneGame(probA,probB):
scoreA,scoreB = 0, 0
serving = "A"
while not gameOver(scoreA,scoreB):
if serving == "A":
if random() < probA:
scoreA += 1
else:
serving = "B"
else:
if random() < probB:
scoreB += 1
else:
serving = "A"
return scoreA,scoreB
def gameOver(a,b):
return a==15 or b==15
def simNGames(n,probA,probB):
winsA,winsB = 0, 0
for i in range(n):
scoreA,scoreB = simOneGame(probA,probB)
if scoreA > scoreB:
winsA += 1
else:
winsB += 1
return winsA, winsB
def main():
printIntro()
probA,probB, n = getInputs()
winsA,winsB = simNGames(n,probA,probB)
printSummary(winsA,winsB)
main()
运行结果:
这个程序模拟两个选手A和B的某种竞技比赛
程序运行需要A和B的能力值(以0到1之间的小数表示)
请输入选手A的能力值(0-1):0.45
请输入选手B的能力值(0-1):0.5
模拟比赛场次:1000
竞技开始分析,共模拟1000场比赛
选手A获胜381场比赛,占比38.1%
选手B获胜619场比赛,占比61.9%
举一反三
理解自顶向下和自底向上
分而治之、模块化集成
自顶向下是系统思维
应用问题的扩展
增加其他能力值
通过胜率反推能力
0x2 Python程序设计思维
###计算思维与程序设计
计算思维
第三种人类思维特征
逻辑思维:推理演绎
实证思维:实验和验证
计算思维:设计和构造
特征
抽象问题和自动化求解
天气预报MM5模型,超算计算,进行预测天气
量化分析 股票
抽象计算过程,关注设计过程
计算生态与python语言
计算生态
先是科学装置
后来开源运动GUN
通用许可协议,自由软件时代到来
linux内核开源
网景浏览器开源,商业软件开源
开源思想深入演化和发展
没有顶层设计、以功能为单位
python语言
大量第三方库
库有竞争发展压力
爬虫requests库的简单易用,使过去的库被淘汰
库之间有广泛联系
Numpy库底层是C语言编写,接口是python
社区庞大
API 不等于 生态,API是由人设计的
计算生态价值
加速科技类应用创新的重要支撑
发展科技产品商业价值的重要模式
国家科技体系安全和稳固的基础
编程的起点
学会站在巨人的肩膀上
编程的起点不是算法而是系统
以计算生态为主要运用
优质计算生态 http://python123.io
###用户体验与软件产品
用户体验值用户对产品建立的主观感受和认识
提高用户体验的方法
增加进度展示 在程序需等待时,或者有若干步时、存在大量循环时
异常处理 判段输入合理性,当读写文件时,当需输入输出时
打印输出 输出程序过程,使用户了解自己的操作效果
###基本的程序设计模式
IPO
确定IPO:明确计算部分及功能边界
编写程序:将计算求解的计划变成现实
调试程序:确保程序按照正确逻辑能过正确运行
自顶向下设计
模块设计
主程序和子程序、分治
紧耦合、松耦合
配置化设计
程序引擎 + 数据配置文件
程序和参数分离,只改变参数,即可
应用开发
产品定义、系统架构、设计与实现、用户体验
定义产品
应用需求充分理解和明确定义
产品定义,而不是功能定义,要考虑商业模式
系统架构
以系统方式思考产品的技术实现
系统架构,关注数据留、模块化、体系架构
设计与实现
结合架构完成关键设计及系统实现
结合可扩展性、灵活性等进行设计优化
用户体验
从用户角度思考,改善用户体验
0x3 Python第三方库安装
####python第三方库获得
全球第三方库社区 https://pypi.org/
PyPI : Python Package Index
PSF维护的展示全球的Python计算生态的主站
实例 开发与区块链相关
搜索 blockchain
挑选 适合开发目标的第三方库作为基础
完成 自己需要的功能
####第三方库的安装
####pip安装方法
使用pip安装工具,最常用
需联网
三方平台均可
cmd 命令行
常用pip指令
pip install -U 第三方库名
//-使用—U标签更新已安装的指定第三方库
pip uninstall <第三方库名>
//卸载指定第三方库
pip dounload <第三方库名>
//下载但不安装指定的第三方库
pip show <第三方库名>
//列出某个指定第三方库的详细信息
pip search <关键词>
//根据关键词在名称和介绍中搜索第三方库
如 :pip search blockchain
出现错误一般与网络环境有关们可以换个网络连接,或者换个时间
####集成安装方法
Anaconda 开发环境
https://www.continuum.io
支持近800个第三方库
包含多个主流工具
适合数据计算领域开发
####文件安装方法
有些第三方库pip下载后,需要编译再安装
如果没有编译环境则只能下载不能安装
UCI页面 http://www.lfd.uci.edu/~gohlke/pythonlibs/
编译过的安装包
下载在指定文件夹后,pip 安装
0x4 模块 os库的基本使用
os库的基本介绍
与操作系统相关
Python标准函数、几百个函数
基本功能
路径操作:os.path子库,处理文件路径及信息
进程管理:启动系统中其他信息
环境参数:获得系统软硬件信息等环境参数
路径操作
import os.path
或者
import os.path as op #op 子库设置别名



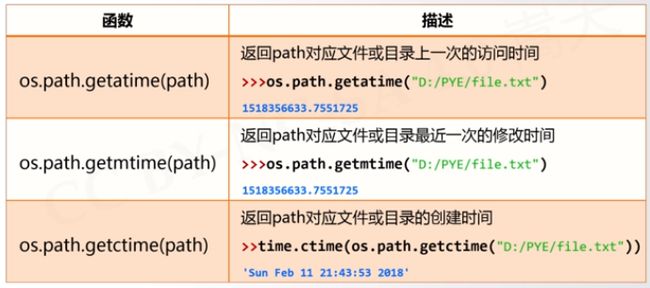

进程管理
os.system(command)
执行程序或命令command
在windows系统中,返回值为cmd的调用返回信息
实例 打开计算器程序
import os
os.system("C:\\Windows\\System32\\calc.exe")
返回0,计算器被打开
环境参数
获取或改变操作系统中的环境信息



0x5 实例第三方库安装脚本
第三方自动安装脚本
需求 自动执行pip,逐一安装第三方库
问题假设
将要安装20个第三方库
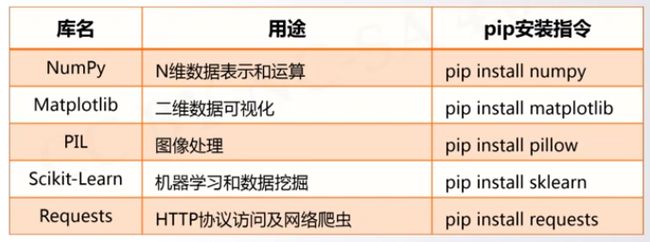
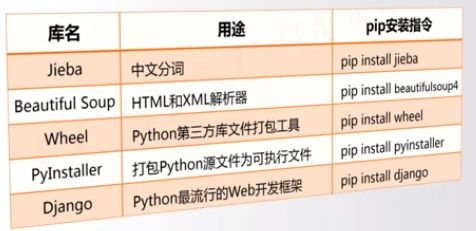
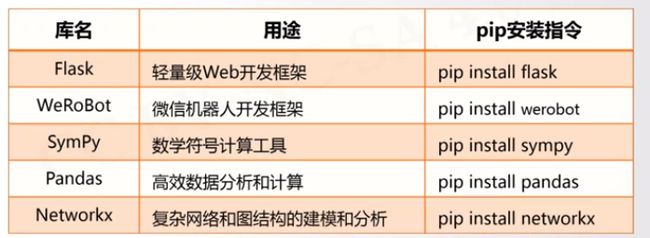
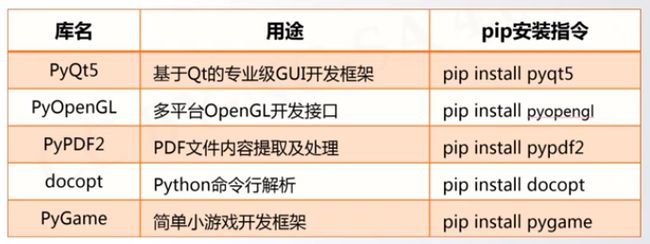
代码
import os
libs = {"numpy","matplotlib","pillow","sklearn","requests",\
"jieba","beautifulsoup4","wheel","networkx","sympy",\
"pyinstaller","django","flask","werobot","pyqt5",
"pandas","pypopengl","pypdf2","docopt","pygame"}
try:
for lib in libs:
os.system("pip install" + lib)
print("Successful")
except:
print("Failed Somehow")
举一反三
自动化脚本 +
编写各类自动执行程序的脚本
扩展应用为引擎配置文件
识别失败信息
15.Python计算生态概览
展示为主
###0x1 从数据处理到人工智能
数据表示、数据清洗、数据统计、数据可视化、数据挖掘、人工智能
数据表示 采用合适方式用程序表达数据
数据清洗 数据归一化、数据转换、异常值处理
数据统计 数据的概要理解、数量、分布、中位数等
数据可视化 直观展示数据内涵的方式
数据挖掘 从数据分析获得知识,产生数据外的价值
人工智能 数据/语言/图像/视觉等方面升读分析与决策
####Python库之数据分析
#####Numpy
Numpy:表达N维数组的最基础库
Python接口使用、C语言实现,计算速度优异
Python数据分析及科学设计的基础库,支撑pandas等
提供直接的矩阵运算、广播函数、线性代数等功能

www.numpy.org
#####Pandas
Pandas:Python数据分析高层次应用库
提供了简单易用的数据结构和数据分析工具
理解数据类型与索引的关系。操作索引即操作数据
Python最主要的数据分析功能库,基于Numpy开发
核心
Series = 索引 + 一维数据
DataFrame = 行列索引 + 二维数据
http://pandas.pydata.org
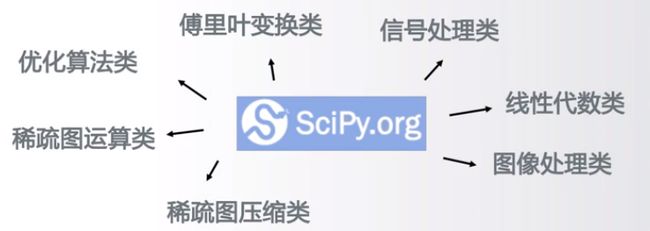
#####SciPy
SciPy数学科学和工程计算功能库
提供了一批数学算法及工程数据运算功能
类似Matlab,可用于傅里叶变换、信号处理等应用
Python最主要用于科学计算的功能库,基于Numpy开发
####Python库之数据可视化
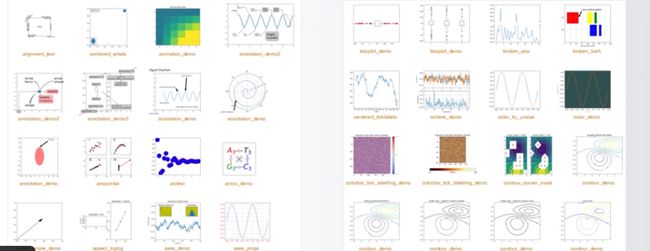
#####Matplotlib
高质量的二维数据可视化功能库
提供了超过100种数据可视化展示效果
通过matplotlib.pyplot子库调用各可视化效果
http://matplotlib.org
#####Seaborn
统计类数据可视化功能库
提供了一批高层次的统计类数据可视化展示效果
主要展示数据间分布、分类和线性关系等内容
基于Matplotlib开发,支持Numpy和Pandas

http://seaborn.pydata.org/
#####Mayavi
三维科学数据可视化功能库
提供了一批简单易用的3D科学计算数据可视化展示效果
三维可视化最主要的第三方库
支持Numpy、TVTK、Traits、Envisage等第三方库
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-XWTktE5w-1615378667851)(https://s3.ax1x.com/2021/01/29/yCgD6s.png)]
http://docs.enthought.com/mayavi/mayavi/
####Python库之文本处理
#####PyPDF2
提供了一批处理PDF文件的计算功能
支持获取信息、分隔/整合文件、加密解密等
完全Python语言实现,不需要额外依赖,功能稳定

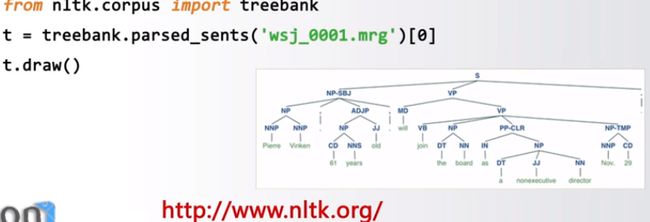
#####NLTK
自然语言文本处理第三方库
支持语言文本分类、标记、语法句法、语义分析等
最优秀的自然语言处理库
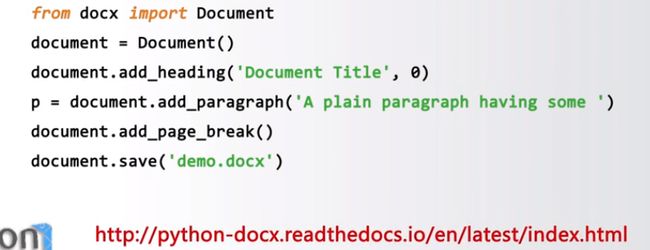
#####Python-docx
创建或更新Microsoft Word文件的第三方库
提供创建或更新.doc.docx等文件的计算功能
增加并配置段落、图片、表格、文字等,功能全面
####Python库之机器学习
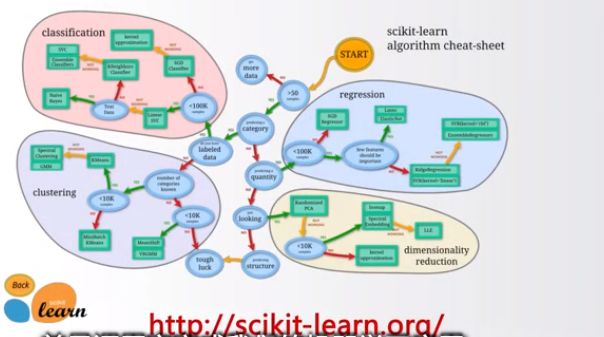
#####Scikit-learn
机器学习方法工具集
提供一批统一化的机器学习方法功能接口
提供聚类、分类、回归、强化学习等计算功能
机器学习基本和优秀的第三方库
#####TensorFlow
AlphaGo背后机器学习计算框架
谷歌公司推动的开源机器学习框架
将数据流图作为基础,图节点代表运算,边代表张量
应用机器学习方法的方式之一,支撑谷歌人工智能应用

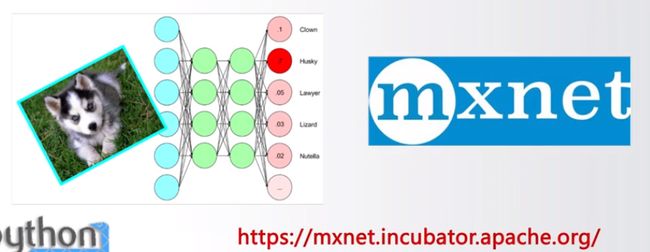
#####MXNet
基于神经网络的深度学习计算框架
提供可扩展的神经网络及深度学习计算功能
可用于自动驾驶、机器翻译、语音识别等众多领域
Python最重要的深度学习框架
0x2 实例 霍兰德人格分析雷达图
雷达图
Radar Chart
多特性直观展示的重要方式
霍兰德人格分析
霍兰德认为:人格兴趣与职业之间应有一种内在的对应关系
人格分类:研究型、艺术型、社会型、企业型、传统型、现实型
职业:工程师、实验员、艺术家、推销员、记事员、社会工作者
需求用雷达库方式验证霍兰德人格分析
各职业人群结合兴趣的调研数据
雷达图
通用雷达图绘制:matplotlib库
专业的多维数据表示:numpy库
实例展示

#HollandRadarDraw
import numpy as np
import matplotlib.pyplot as plt
import matplotlib
matplotlib.rcParams['font.family']='SimHei'
radar_labels = np.array(['研究型(I)','艺术型(A)','社会型(S)',\
'企业型(E)','常规型(C)','现实型(R)']) #雷达标签
nAttr = 6
data = np.array([[0.40, 0.32, 0.35, 0.30, 0.30, 0.88],
[0.85, 0.35, 0.30, 0.40, 0.40, 0.30],
[0.43, 0.89, 0.30, 0.28, 0.22, 0.30],
[0.30, 0.25, 0.48, 0.85, 0.45, 0.40],
[0.20, 0.38, 0.87, 0.45, 0.32, 0.28],
[0.34, 0.31, 0.38, 0.40, 0.92, 0.28]]) #数据值
data_labels = ('艺术家', '实验员', '工程师', '推销员', '社会工作者','记事员')
angles = np.linspace(0, 2*np.pi, nAttr, endpoint=False)
data = np.concatenate((data, [data[0]]))
angles = np.concatenate((angles, [angles[0]]))
fig = plt.figure(facecolor="white")
plt.subplot(111, polar=True)
plt.plot(angles,data,'o-', linewidth=1, alpha=0.2)
plt.fill(angles,data, alpha=0.25)
plt.thetagrids(angles*180/np.pi, radar_labels,frac = 1.2)
plt.figtext(0.52, 0.95, '霍兰德人格分析', ha='center', size=20)
legend = plt.legend(data_labels, loc=(0.94, 0.80), labelspacing=0.1)
plt.setp(legend.get_texts(), fontsize='large')
plt.grid(True)
plt.savefig('holland_radar.jpg')
plt.show()
举一反三
目标 沉浸 熟练
找到合适的目标
思考可实现的方法
不断的练习、练习
###0x3 从web解析到网络空间
####python库之网络爬虫
Requests
最友好的网络爬虫功能库
提供了简单易用的类HTTP协议网络爬虫功能
支持连接池、SSL、Cookies、HTTP(S)代理等
页面级网络爬虫功能库
import requests
r = requests.get('https://api.github.com/user',\
auth=('user','pass')) #访问连接,获取信息
r.status_code #获得访问网络的状态效果
r.headers['content-type']
r.encoding
r.text #获得文本信息
http://www.python-requests.org/
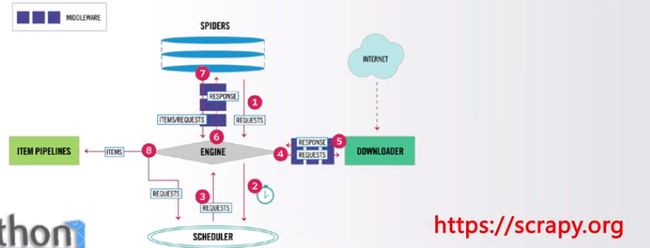
Scrapy
优秀的网络爬虫框架
框架是已经拥有了基础功能,只需开发者在基础之上进行扩展开发或者额外配置
支持批量和定时的网页爬取、提供数据处理流程等
主要和优秀的基础库
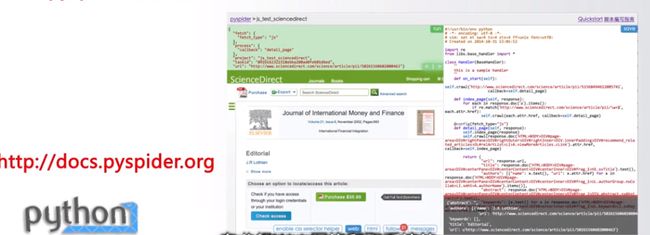
pyspider
强大的web网页爬取系统
提供了完整的网页爬取系统构建功能
支持数据库后端、消息队列、优先级、分布式架构
####python库之web信息提取
如何解析HTML和XML的内容
Beautiful Soup
HTML和XML的解析库
提供解析HTML和XML等Web信息的功能
又名 beautifulsoup4 或 bs4,可以加载多种解析引擎
常与网络爬虫库搭配使用,如Scrapy、requests等

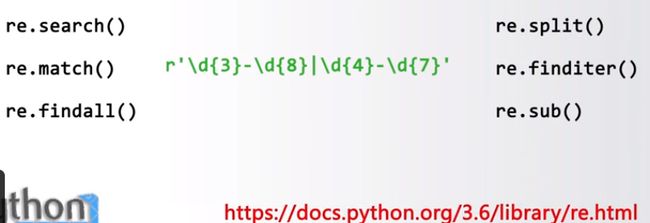
Re
正则表达式解析和处理功能库
提供了定义和解析正则表达式的一批通用功能
可用于各类场景,包括定点的Web信息提取
Python最主要的标准库之一,无需安装
Python-Goose
提取文章类型Web页面的功能库
提供了对Web也米娜中文章信息/视频等元数据的提取功能
针对特定Web页面,应用覆盖面较广
Python最主要的Web信息提取库
from goose import Goose
url = 'http://www.elmundo.es/elmundo/2012/10/28/espana/1351388909.html'
g = Goose({'use_meta_language':False,'target_language':'es'})
article = g.extract(url=url)
article.cleaned_text[:150]
https://github.com/grangier/python-goose
####python库之web网站开发
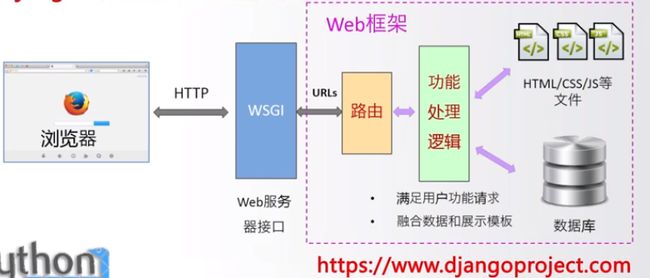
Django
提供了构建Web系统的基本应用框架
MTV:模型(model)、模板(Template)、视图(Views)
Python最重要的Web应用框架,略微复杂的应用框架
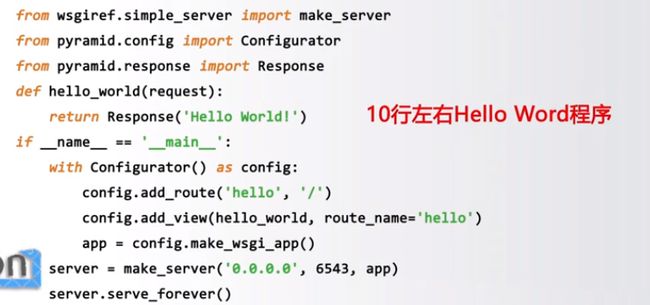
Pyramid
规模适中的Web应用框架
提供了简单方便构建Web系统的应用框架
不大不小,规模适中,适合快速构建并熟读扩展类应用
Python产品级Web应用框架,起步简单可扩展性好
Flask
提供了最简单构建Web系统的应用框架
特点是:简单、规模小、快速

####python库之网络应用开发
WeRoBot
微信公众号开发框架
提供了解析微信服务器消息及反馈消息的功能
建立微信机器人的重要技术手段

百度AI的开发平台接口aip
提供了访问百度Ai服务的Python功能接口
语言、人脸、OCR、NLP、知识图谱、图像搜索等领域

MyQR
二维码生成第三方库
提供了生成二维码的系列功能
基本二维码、艺术二维码、动态二维码

###0x4 从人机交互到艺术设计
####Python库之图形用户界面
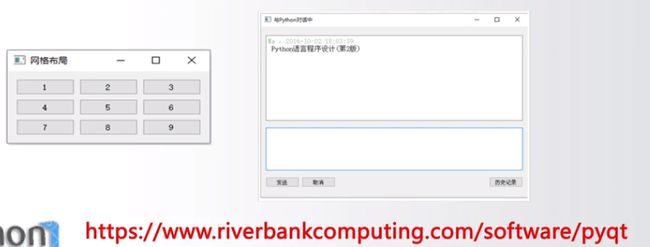
PyQt5
Qt 框架 由诺基亚公司创建
提供了创建Qt5程序的Python API接口
Qt是非常成熟的跨平台桌面应用开发系统,完备GUI
推荐Python GUI开发第三方库
wxpython
跨平台GUI开发框架
提供了赚用于Python的跨平台GUI开发框架
理解数据类型与索引的关系,操作索引即操作数据
Python最主要的数据分析功能库,基于Numpy开发

PyGObject
使用GTK+开发GUI的功能库
提供了整合GTK+、WebKitGTK+等库的功能
GTK+:跨平台的一种用户图形界面GUI框架

####Python库之游戏开发
PyGame:
提供了基于SDL的简单游戏开发功能及实现引擎
理解游戏对外部输入的相应计值及角色构建和交互机制
Python游戏入门最主要的第三方库

Panda3D
开源、跨平台的3D渲染和游戏开发库
一个3D游戏引擎,提供Python和C++两种接口
支持很多先进特性:法线贴图、光泽贴图、卡通渲染等

cocos2d
构建2D游戏和图形界面交互式应用的框架
提供了基于OpenGL的游戏开发图形渲染功能
支持GPU加速,采用树形结构分层管理游戏对象类型
适用于2D专业级游戏开发

####Python库之虚拟现实
VR Zero
在树莓派上开发VR应用的Python库
提供大量与VR开发相关的功能
针对树莓派的VR开发库,支持设备小型化,配置简单化
适合初学者

pyovr
针对Oculus VR设备的Python开发库
基于成熟的VR设备,提供全套问答,工业级应用设备
Python + 虚拟现实领域探索的一种思路

Vizard
基于Python的通用VR开发引擎
专业企业家开发引擎
提供详细的官方文档
支持多种主流的VR硬件设备,具有一定通用性

####Python库之图形艺术
Quads
迭代的艺术
对图片进行四分迭代,形成像素风
可以生成动图或静图图像

ascii_art
将图片转为ASCII艺术风格
输出可以是纯文本或彩色文本
以图片格式输出

turtle
海龟绘图体系
random Art

0x5 实例 玫瑰花绘制
玫瑰花绘制
需求:Python绘制一朵玫瑰花,献给所思所念
输入:你的想象力
输出:玫瑰花
实例
艺术之余编程
创新、思想
思想最重要
编程只是手段
#全课程总结
总结
感性认识、理性学习、展望未来
主要是面向过程的讲解
第三方库
实例
python语法的三个阶段
函数式编程、面向对象编程、Pythonic编程
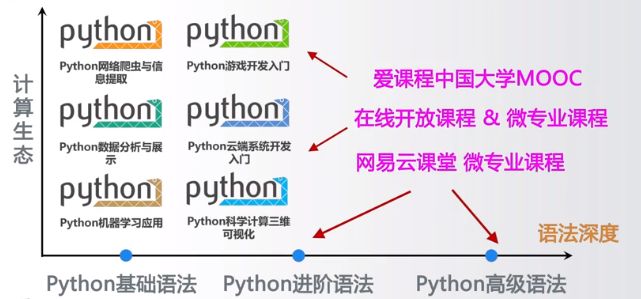
Python的未来之路
无处不在
C、JS

####python库之web信息提取
如何解析HTML和XML的内容
Beautiful Soup
HTML和XML的解析库
提供解析HTML和XML等Web信息的功能
又名 beautifulsoup4 或 bs4,可以加载多种解析引擎
常与网络爬虫库搭配使用,如Scrapy、requests等
Re
正则表达式解析和处理功能库
提供了定义和解析正则表达式的一批通用功能
可用于各类场景,包括定点的Web信息提取
Python最主要的标准库之一,无需安装
Python-Goose
提取文章类型Web页面的功能库
提供了对Web也米娜中文章信息/视频等元数据的提取功能
针对特定Web页面,应用覆盖面较广
Python最主要的Web信息提取库
from goose import Goose
url = 'http://www.elmundo.es/elmundo/2012/10/28/espana/1351388909.html'
g = Goose({'use_meta_language':False,'target_language':'es'})
article = g.extract(url=url)
article.cleaned_text[:150]
https://github.com/grangier/python-goose
####python库之web网站开发
Django
提供了构建Web系统的基本应用框架
MTV:模型(model)、模板(Template)、视图(Views)
Python最重要的Web应用框架,略微复杂的应用框架
Pyramid
规模适中的Web应用框架
提供了简单方便构建Web系统的应用框架
不大不小,规模适中,适合快速构建并熟读扩展类应用
Python产品级Web应用框架,起步简单可扩展性好
Flask
提供了最简单构建Web系统的应用框架
特点是:简单、规模小、快速
####python库之网络应用开发
WeRoBot
微信公众号开发框架
提供了解析微信服务器消息及反馈消息的功能
建立微信机器人的重要技术手段
百度AI的开发平台接口aip
提供了访问百度Ai服务的Python功能接口
语言、人脸、OCR、NLP、知识图谱、图像搜索等领域
MyQR
二维码生成第三方库
提供了生成二维码的系列功能
基本二维码、艺术二维码、动态二维码
###0x4 从人机交互到艺术设计
####Python库之图形用户界面
PyQt5
Qt 框架 由诺基亚公司创建
提供了创建Qt5程序的Python API接口
Qt是非常成熟的跨平台桌面应用开发系统,完备GUI
推荐Python GUI开发第三方库
wxpython
跨平台GUI开发框架
提供了赚用于Python的跨平台GUI开发框架
理解数据类型与索引的关系,操作索引即操作数据
Python最主要的数据分析功能库,基于Numpy开发
PyGObject
使用GTK+开发GUI的功能库
提供了整合GTK+、WebKitGTK+等库的功能
GTK+:跨平台的一种用户图形界面GUI框架
####Python库之游戏开发
PyGame:
提供了基于SDL的简单游戏开发功能及实现引擎
理解游戏对外部输入的相应计值及角色构建和交互机制
Python游戏入门最主要的第三方库
Panda3D
开源、跨平台的3D渲染和游戏开发库
一个3D游戏引擎,提供Python和C++两种接口
支持很多先进特性:法线贴图、光泽贴图、卡通渲染等
cocos2d
构建2D游戏和图形界面交互式应用的框架
提供了基于OpenGL的游戏开发图形渲染功能
支持GPU加速,采用树形结构分层管理游戏对象类型
适用于2D专业级游戏开发
####Python库之虚拟现实
VR Zero
在树莓派上开发VR应用的Python库
提供大量与VR开发相关的功能
针对树莓派的VR开发库,支持设备小型化,配置简单化
适合初学者
pyovr
针对Oculus VR设备的Python开发库
基于成熟的VR设备,提供全套问答,工业级应用设备
Python + 虚拟现实领域探索的一种思路
Vizard
基于Python的通用VR开发引擎
专业企业家开发引擎
提供详细的官方文档
支持多种主流的VR硬件设备,具有一定通用性
####Python库之图形艺术
Quads
迭代的艺术
对图片进行四分迭代,形成像素风
可以生成动图或静图图像
ascii_art
将图片转为ASCII艺术风格
输出可以是纯文本或彩色文本
以图片格式输出
turtle
海龟绘图体系
random Art
0x5 实例 玫瑰花绘制
玫瑰花绘制
需求:Python绘制一朵玫瑰花,献给所思所念
输入:你的想象力
输出:玫瑰花
实例
艺术之余编程
创新、思想
思想最重要
编程只是手段
#全课程总结
总结
感性认识、理性学习、展望未来
主要是面向过程的讲解
第三方库
实例
python语法的三个阶段
函数式编程、面向对象编程、Pythonic编程
Python的未来之路
无处不在
C、JS
