【ceph】ceph-mds journal模块解读
CephFS通过ceph-mds将文件系统元数据存储于metadata pool中,一般metadata pool实际生产环境中都建议用高性能ssd,加快元数据落盘以及加载至内存中性能。
本篇介绍ceph-mds如何将元数据存入metadata pool中,以及通过cephfs-journal-tool如何查看相关journal信息。
class MDLog () 类
class MDLog () 管理整个journal模块,内存数据与journal模块通道,所有元数据操作都通过此类与journal相关联
//主要成员
int num_events; //事件总数
inodeno_t ino;//metadata pool中对应inode,默认以0x200.mdsrank
Journaler *journaler;
Thread replay_thread;//当mds为hot standby时replay_thread从metadata_pool中将元数据回放至内存
Thread _recovery_thread;
Thread submit_thread;//事务条件线程,该线程负责将事务提交,flush至journal中
map segments;
map > pending_events;
class MDLog () 子类成员介绍
class Journaler (src/osdc/目录下))该类主要负责管理journal读写以及刷新
单mds情况下,journal在metadata池中obj从200.0000000后续持续递增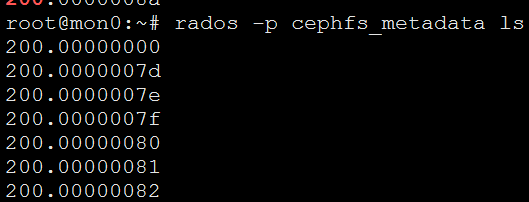
其中200.0000000为class Journaler包含类class Header
该类包含Header类,记录整个journal具体操作位置
class Header {
public:
uint64_t trimmed_pos;//已裁剪到达位置
uint64_t expire_pos;//失效到达位置
uint64_t unused_field;//未使用位置
uint64_t write_pos; //当前journal起始写位置
string magic;
file_layout_t layout; //< The mapping from byte stream offsets
// to RADOS objects
stream_format_t stream_format; //< The encoding of LogEvents
// within the journal byte stream
Header(const char *m="") :
trimmed_pos(0), expire_pos(0), unused_field(0), write_pos(0), magic(m),
stream_format(-1) {
}
Header实际内容如下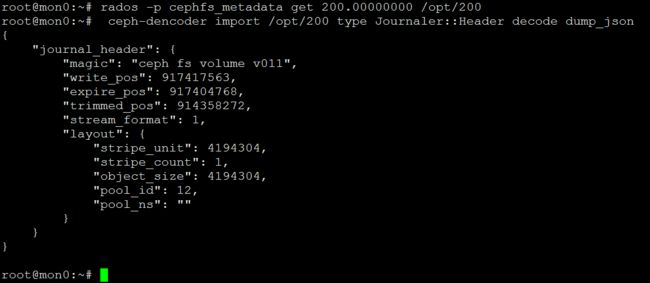
验证write_pos
测试集群中,0x200开头的最大obj为200.000000da
本集群中obj大小为默认4MB,write_pos当前为917417563,917417563/1024/1024/4=218.7293918132782 最后obj开头编号0xda=218.
Journaler类中除Header类外,本身也有读写位移位控制读写如下
// writer
uint64_t prezeroing_pos;
uint64_t prezero_pos; ///< we zero journal space ahead of write_pos to
// avoid problems with tail probing
uint64_t write_pos; ///< logical write position, where next entry
// will go
uint64_t flush_pos; ///< where we will flush. if
/// write_pos>flush_pos, we're buffering writes.
uint64_t safe_pos; ///< what has been committed safely to disk.
uint64_t next_safe_pos; /// start postion of the first entry that isn't
/// being fully flushed. If we don't flush any
// partial entry, it's equal to flush_pos.
bufferlist write_buf; ///< write buffer. flush_pos +
/// write_buf.length() == write_pos.
// reader
uint64_t read_pos; // logical read position, where next entry starts.
uint64_t requested_pos; // what we've requested from OSD.
uint64_t received_pos; // what we've received from OSD.
// read buffer. unused_field + read_buf.length() == prefetch_pos.
bufferlist read_buf;
成员函数主要如下
void _flush(C_OnFinisher *onsafe);
void _do_flush(unsigned amount=0);
void _finish_flush(int r, uint64_t start, ceph::real_time stamp);
简单点理解,Journaler类负责将内存中已经序列化的数据写入到对应metadata pool中的obj中,同时提供读取该obj的接口,那么序列化的是什么数据?
再回到Mdlog类中submit_thread线程,该线程调用journaler->flush()将序列化数据刷入obj中。
map >::iterator it = pending_events.begin();
if (it == pending_events.end()) {
submit_cond.Wait(submit_mutex);
continue;
}
从上述代码得知,submit_thread会遍历pending_events,map
void MDLog::_submit_entry(LogEvent *le, MDSLogContextBase *c)
{
pending_events[ls->seq].push_back(PendingEvent(le, c));
}
_submit_entry函数在journal_and_reply中被submit_mdlog_entry所调用,journal_and_reply函数在所有处理元数据请求后,都会被调用。
由此可见,当mds处理客户端请求后,都分装成LogEvent事件,通过journal_and_reply函数中的submit_mdlog_entry,提交到pending_events集合中,再通过submit_thread线程,将LogEvent事件刷新到metadata pool中。下面介绍下LogEvent类
class LogEvent是所有操作日志事件的基类,具体成员函数都是通过集成该类的子类实现,其中EventType表示该子类类型
class LogEvent {
public:
typedef __u32 EventType;
}
std::string LogEvent::get_type_str() const
{
switch(_type) {
case EVENT_SUBTREEMAP: return "SUBTREEMAP";
case EVENT_SUBTREEMAP_TEST: return "SUBTREEMAP_TEST";
case EVENT_EXPORT: return "EXPORT";
case EVENT_IMPORTSTART: return "IMPORTSTART";
case EVENT_IMPORTFINISH: return "IMPORTFINISH";
case EVENT_FRAGMENT: return "FRAGMENT";
case EVENT_RESETJOURNAL: return "RESETJOURNAL";
case EVENT_SESSION: return "SESSION";
case EVENT_SESSIONS_OLD: return "SESSIONS_OLD";
case EVENT_SESSIONS: return "SESSIONS";
case EVENT_UPDATE: return "UPDATE";
case EVENT_SLAVEUPDATE: return "SLAVEUPDATE";
case EVENT_OPEN: return "OPEN";
case EVENT_COMMITTED: return "COMMITTED";
case EVENT_TABLECLIENT: return "TABLECLIENT";
case EVENT_TABLESERVER: return "TABLESERVER";
case EVENT_NOOP: return "NOOP";
default:
generic_dout(0) << "get_type_str: unknown type " << _type << dendl;
return "UNKNOWN";
}
}
我们以EVENT_UPDATE为例,该事件表示更新元数据事件,对应class EUpdate
class EUpdate : public LogEvent {
public:
EMetaBlob metablob;
string type;
bufferlist client_map;
version_t cmapv;
metareqid_t reqid;
bool had_slaves;
EUpdate() : LogEvent(EVENT_UPDATE), cmapv(0), had_slaves(false) { }
EUpdate(MDLog *mdlog, const char *s) :
LogEvent(EVENT_UPDATE), metablob(mdlog),
type(s), cmapv(0), had_slaves(false) { }
void print(ostream& out) const override {
if (type.length())
out << "EUpdate " << type << " ";
out << metablob;
}
EMetaBlob *get_metablob() override { return &metablob; }
void encode(bufferlist& bl, uint64_t features) const override;
void decode(bufferlist::iterator& bl) override;
void dump(Formatter *f) const override;
static void generate_test_instances(list& ls);
void update_segment() override;
void replay(MDSRank *mds) override;
EMetaBlob const *get_metablob() const {return &metablob;}
};
只要涉及元数据更新的client操作,都会生成EVENT_UPDATE事件
handle_client_openc ---------> EUpdate *le = new EUpdate(mdlog, "openc")
handle_client_setattr ---------> EUpdate *le = new EUpdate(mdlog, "setattr")
handle_client_setlayout ---------> EUpdate *le = new EUpdate(mdlog, "setlayout")
.
.
.
handle_client_mknod -------------> EUpdate *le = new EUpdate(mdlog, "mknod")
class EUpdate成员变量EMetaBlob metablob,EMetaBlob 为序列化的具体类,该类包含操作inode所有元数据信息,包括该inode父目录统计信息,该inode元数据信息,以及对此inode操作的client信息
LogEvent类中encode_with_header,将EMetaBlob 进行序列化,EUpdate为LogEvent子类,具体序列化方法如下
void encode_with_header(bufferlist& bl, uint64_t features) {
::encode(EVENT_NEW_ENCODING, bl);
ENCODE_START(1, 1, bl)
::encode(_type, bl);
encode(bl, features);
ENCODE_FINISH(bl);
}
EMetaBlob 序列化
void EMetaBlob::encode(bufferlist& bl, uint64_t features) const
{
ENCODE_START(8, 5, bl);
::encode(lump_order, bl);
::encode(lump_map, bl, features);
::encode(roots, bl, features);
::encode(table_tids, bl);
::encode(opened_ino, bl);
::encode(allocated_ino, bl);
::encode(used_preallocated_ino, bl);
::encode(preallocated_inos, bl);
::encode(client_name, bl);
::encode(inotablev, bl);
::encode(sessionmapv, bl);
::encode(truncate_start, bl);
::encode(truncate_finish, bl);
::encode(destroyed_inodes, bl);
::encode(client_reqs, bl);
::encode(renamed_dirino, bl);
::encode(renamed_dir_frags, bl);
{
// make MDSRank use v6 format happy
int64_t i = -1;
bool b = false;
::encode(i, bl);
::encode(b, bl);
}
::encode(client_flushes, bl);
ENCODE_FINISH(bl);
}
验证方法:
touch /mnt/cephfs/yyn/testtouch
cephfs-journal-tool --rank=cephfs:0 event get --type=UPDATE binary --path /opt/test
ceph-dencoder import /opt/test/0x36aee5de_UPDATE.bin type EUpdate decode dump_json


已mknod为例
// prepare finisher
mdr->ls = mdlog->get_current_segment();
EUpdate *le = new EUpdate(mdlog, "mknod");
mdlog->start_entry(le);
le->metablob.add_client_req(req->get_reqid(), req->get_oldest_client_tid());
journal_allocated_inos(mdr, &le->metablob);
mdcache->predirty_journal_parents(mdr, &le->metablob, newi, dn->get_dir(),
PREDIRTY_PRIMARY|PREDIRTY_DIR, 1);
le->metablob.add_primary_dentry(dn, newi, true, true, true);
journal_and_reply(mdr, newi, dn, le, new C_MDS_mknod_finish(this, mdr, dn, newi));
mknod中通过add_client_req,predirty_journal_parents,add_primary_dentry填充需要metablob信息,通过journal_and_reply序列化固化到metadata pool中。
3.上述两点已分析mds接收请求,序列化元数据信息,刷到metadata pool对应journal的obj中,那journal obj 如何将数据回落到各个目录的元数据当中呢?
metadata pool中每个文件夹都会以该文件夹inode号保存一个对应此文件夹的obj信息,该obj中保存了该目录下的所有文件信息,以及目录自身统计信息。
journal中的metablob只是临时保存,后续必然要刷回到对应目录的obj中。
ceph-mds中通过class LogSegment类来保存dirty的inode信息。
class LogSegment {
public:
const log_segment_seq_t seq;
uint64_t offset, end;
int num_events;
// dirty items
elist dirty_dirfrags, new_dirfrags;
elist dirty_inodes;
elist dirty_dentries;
elist open_files;
elist dirty_parent_inodes;
elist dirty_dirfrag_dir;
elist dirty_dirfrag_nest;
elist dirty_dirfrag_dirfragtree;
elist slave_updates;
set truncating_inodes;
map > pending_commit_tids; // mdstable
set uncommitted_masters;
set uncommitted_fragments;
// client request ids
map last_client_tids;
// potentially dirty sessions
std::set touched_sessions;
// table version
version_t inotablev;
version_t sessionmapv;
map tablev;
}
LogSegment 类保存的是公共num_events事件过程中,发生修改的元数据的集合,例如:
elist
elist
elist
默认单个LogSegment 记录1024个LogEvent发生的inode修改集合,由mds_log_events_per_segment参数控制.所有的LogSegment 保存在MDlog类中的map
还是以mknod为例
ournal_and_reply(mdr, newi, dn, le, new C_MDS_mknod_finish(this, mdr, dn, newi));
当元数据写入journal后,回调C_MDS_mknod_finish,该函数中会将发生的修改的inode信息push到LogSegment dirty_inodes以及dirty_parent_inodes中。
newi->mark_dirty(newi->inode.version + 1, mdr->ls);
newi->_mark_dirty_parent(mdr->ls, true);
void CInode::_mark_dirty(LogSegment *ls)
{
if (!state_test(STATE_DIRTY)) {
state_set(STATE_DIRTY);
get(PIN_DIRTY);
assert(ls);
}
// move myself to this segment's dirty list
if (ls)
ls->dirty_inodes.push_back(&item_dirty);
}
当mdsrank.cc通过trim_mdlog时,遍历MDlog中所有的segments进行try_expire,通过LogSegment将脏数据刷入目录对应的obj中。
map::iterator p = segments.begin();
while (p != segments.end() &&
p->first < last_seq &&
p->second->end < safe_pos) { // next segment should have been started
LogSegment *ls = p->second;
++p;
try_expire(ls, CEPH_MSG_PRIO_DEFAULT);
}
void LogSegment::try_to_expire(MDSRank *mds, MDSGatherBuilder &gather_bld, int op_prio)
{
{
set commit;
dout(6) << "LogSegment(" << seq << "/" << offset << ").try_to_expire" << dendl;
assert(g_conf->mds_kill_journal_expire_at != 1);
// commit dirs
for (elist::iterator p = new_dirfrags.begin(); !p.end(); ++p) {
dout(20) << " new_dirfrag " << **p << dendl;
assert((*p)->is_auth());
commit.insert(*p);
}
for (elist::iterator p = dirty_dirfrags.begin(); !p.end(); ++p) {
dout(20) << " dirty_dirfrag " << **p << dendl;
assert((*p)->is_auth());
commit.insert(*p);
}
for (elist::iterator p = dirty_dentries.begin(); !p.end(); ++p) {
dout(20) << " dirty_dentry " << **p << dendl;
assert((*p)->is_auth());
commit.insert((*p)->get_dir());
}
for (elist::iterator p = dirty_inodes.begin(); !p.end(); ++p) {
dout(20) << " dirty_inode " << **p << dendl;
assert((*p)->is_auth());
if ((*p)->is_base()) {
(*p)->store(gather_bld.new_sub());
} else
commit.insert((*p)->get_parent_dn()->get_dir());
}
if (!commit.empty()) {
for (set::iterator p = commit.begin();
p != commit.end();
++p) {
CDir *dir = *p;
assert(dir->is_auth());
if (dir->can_auth_pin()) {
dout(15) << "try_to_expire committing " << *dir << dendl;
dir->commit(0, gather_bld.new_sub(), false, op_prio);
} else {
dout(15) << "try_to_expire waiting for unfreeze on " << *dir << dendl;
dir->add_waiter(CDir::WAIT_UNFREEZE, gather_bld.new_sub());
}
}
}
// master ops with possibly uncommitted slaves
for (set::iterator p = uncommitted_masters.begin();
p != uncommitted_masters.end();
++p) {
dout(10) << "try_to_expire waiting for slaves to ack commit on " << *p << dendl;
mds->mdcache->wait_for_uncommitted_master(*p, gather_bld.new_sub());
}
// uncommitted fragments
for (set::iterator p = uncommitted_fragments.begin();
p != uncommitted_fragments.end();
++p) {
dout(10) << "try_to_expire waiting for uncommitted fragment " << *p << dendl;
mds->mdcache->wait_for_uncommitted_fragment(*p, gather_bld.new_sub());
}
// nudge scatterlocks
for (elist::iterator p = dirty_dirfrag_dir.begin(); !p.end(); ++p) {
CInode *in = *p;
dout(10) << "try_to_expire waiting for dirlock flush on " << *in << dendl;
mds->locker->scatter_nudge(&in->filelock, gather_bld.new_sub());
}
for (elist::iterator p = dirty_dirfrag_dirfragtree.begin(); !p.end(); ++p) {
CInode *in = *p;
dout(10) << "try_to_expire waiting for dirfragtreelock flush on " << *in << dendl;
mds->locker->scatter_nudge(&in->dirfragtreelock, gather_bld.new_sub());
}
for (elist::iterator p = dirty_dirfrag_nest.begin(); !p.end(); ++p) {
CInode *in = *p;
dout(10) << "try_to_expire waiting for nest flush on " << *in << dendl;
mds->locker->scatter_nudge(&in->nestlock, gather_bld.new_sub());
}
assert(g_conf->mds_kill_journal_expire_at != 2);
// open files and snap inodes
if (!open_files.empty()) {
assert(!mds->mdlog->is_capped()); // hmm FIXME
EOpen *le = 0;
LogSegment *ls = mds->mdlog->get_current_segment();
assert(ls != this);
elist::iterator p = open_files.begin(member_offset(CInode, item_open_file));
while (!p.end()) {
CInode *in = *p;
++p;
if (in->last == CEPH_NOSNAP && in->is_auth() &&
!in->is_ambiguous_auth() && in->is_any_caps()) {
if (in->is_any_caps_wanted()) {
dout(20) << "try_to_expire requeueing open file " << *in << dendl;
if (!le) {
le = new EOpen(mds->mdlog);
mds->mdlog->start_entry(le);
}
le->add_clean_inode(in);
ls->open_files.push_back(&in->item_open_file);
} else {
// drop inodes that aren't wanted
dout(20) << "try_to_expire not requeueing and delisting unwanted file " << *in << dendl;
in->item_open_file.remove_myself();
}
} else if (in->last != CEPH_NOSNAP && !in->client_snap_caps.empty()) {
// journal snap inodes that need flush. This simplify the mds failover hanlding
dout(20) << "try_to_expire requeueing snap needflush inode " << *in << dendl;
if (!le) {
le = new EOpen(mds->mdlog);
mds->mdlog->start_entry(le);
}
le->add_clean_inode(in);
ls->open_files.push_back(&in->item_open_file);
} else {
/*
* we can get a capless inode here if we replay an open file, the client fails to
* reconnect it, but does REPLAY an open request (that adds it to the logseg). AFAICS
* it's ok for the client to replay an open on a file it doesn't have in it's cache
* anymore.
*
* this makes the mds less sensitive to strict open_file consistency, although it does
* make it easier to miss subtle problems.
*/
dout(20) << "try_to_expire not requeueing and delisting capless file " << *in << dendl;
in->item_open_file.remove_myself();
}
}
if (le) {
mds->mdlog->submit_entry(le);
mds->mdlog->wait_for_safe(gather_bld.new_sub());
dout(10) << "try_to_expire waiting for open files to rejournal" << dendl;
}
}
assert(g_conf->mds_kill_journal_expire_at != 3);
// backtraces to be stored/updated
for (elist::iterator p = dirty_parent_inodes.begin(); !p.end(); ++p) {
CInode *in = *p;
assert(in->is_auth());
if (in->can_auth_pin()) {
dout(15) << "try_to_expire waiting for storing backtrace on " << *in << dendl;
in->store_backtrace(gather_bld.new_sub(), op_prio);
} else {
dout(15) << "try_to_expire waiting for unfreeze on " << *in << dendl;
in->add_waiter(CInode::WAIT_UNFREEZE, gather_bld.new_sub());
}
}
assert(g_conf->mds_kill_journal_expire_at != 4);
// slave updates
for (elist::iterator p = slave_updates.begin(member_offset(MDSlaveUpdate,
item));
!p.end(); ++p) {
MDSlaveUpdate *su = *p;
dout(10) << "try_to_expire waiting on slave update " << su << dendl;
assert(su->waiter == 0);
su->waiter = gather_bld.new_sub();
}
// idalloc
if (inotablev > mds->inotable->get_committed_version()) {
dout(10) << "try_to_expire saving inotable table, need " << inotablev
<< ", committed is " << mds->inotable->get_committed_version()
<< " (" << mds->inotable->get_committing_version() << ")"
<< dendl;
mds->inotable->save(gather_bld.new_sub(), inotablev);
}
// sessionmap
if (sessionmapv > mds->sessionmap.get_committed()) {
dout(10) << "try_to_expire saving sessionmap, need " << sessionmapv
<< ", committed is " << mds->sessionmap.get_committed()
<< " (" << mds->sessionmap.get_committing() << ")"
<< dendl;
mds->sessionmap.save(gather_bld.new_sub(), sessionmapv);
}
// updates to sessions for completed_requests
mds->sessionmap.save_if_dirty(touched_sessions, &gather_bld);
touched_sessions.clear();
// pending commit atids
for (map >::iterator p = pending_commit_tids.begin();
p != pending_commit_tids.end();
++p) {
MDSTableClient *client = mds->get_table_client(p->first);
assert(client);
for (ceph::unordered_set::iterator q = p->second.begin();
q != p->second.end();
++q) {
dout(10) << "try_to_expire " << get_mdstable_name(p->first) << " transaction " << *q
<< " pending commit (not yet acked), waiting" << dendl;
assert(!client->has_committed(*q));
client->wait_for_ack(*q, gather_bld.new_sub());
}
}
// table servers
for (map::iterator p = tablev.begin();
p != tablev.end();
++p) {
MDSTableServer *server = mds->get_table_server(p->first);
assert(server);
if (p->second > server->get_committed_version()) {
dout(10) << "try_to_expire waiting for " << get_mdstable_name(p->first)
<< " to save, need " << p->second << dendl;
server->save(gather_bld.new_sub());
}
}
}
try_to_expire函数中
将修改过的inode信息通过dir->commit(0, gather_bld.new_sub(), false, op_prio)调用CDIR类中的commit方法,将更新信息写入对应dir的inode 的obj的omap中
同时也会修改in->store_backtrace(gather_bld.new_sub(), op_prio)以及mds->inotable->save(gather_bld.new_sub(), inotablev);对应metadata中的mds0_inotable obj
mds->sessionmap.save(gather_bld.new_sub(), sessionmapv);
原文:https://www.csdn.net/tags/NtzaggysOTI0NjMtYmxvZwO0O0OO0O0O.html