数据库 的索引优化 mysql (建议收藏)
独立的列
在进行查询时,索引列不能是表达式的一部分,也不能是函数的参数,否则无法使用索引。
例如下面的查询不能使用 actor_id 列的索引:
SELECT actor_id FROM sakila.actor WHERE actor_id + 1 = 5;
多列索引
在需要使用多个列作为条件进行查询时,使用多列索引比使用多个单列索引性能更好。例如下面的语句中,最好把 actor_id 和 film_id 设置为多列索引。
SELECT film_id, actor_ id FROM sakila.film_actor WHERE actor_id = 1 AND film_id = 1;
索引列的顺序
让选择性最强的索引列放在前面。
索引的选择性是指:不重复的索引值和记录总数的比值。最大值为 1,此时每个记录都有唯一的索引与其对应。选择性越高,每个记录的区分度越高,查询效率也越高。
例如下面显示的结果中 customer_id 的选择性比 staff_id 更高,因此最好把 customer_id 列放在多列索引的前面。
SELECT COUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity,
COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity,
COUNT(*)
FROM payment;
staff_id_selectivity: 0.0001
customer_id_selectivity: 0.0373
COUNT(*): 16049
前缀索引
对于 BLOB、TEXT 和 VARCHAR 类型的列,必须使用前缀索引,只索引开始的部分字符。
前缀长度的选取需要根据索引选择性来确定。
覆盖索引
索引包含所有需要查询的字段的值。
具有以下优点:
-
索引通常远小于数据行的大小,只读取索引能大大减少数据访问量。
-
一些存储引擎(例如 MyISAM)在内存中只缓存索引,而数据依赖于操作系统来缓存。因此,只访问索引可以不使用系统调用(通常比较费时)。
-
对于 InnoDB 引擎,若辅助索引能够覆盖查询,则无需访问主索引。
索引的优点 -
大大减少了服务器需要扫描的数据行数。
-
帮助服务器避免进行排序和分组,以及避免创建临时表(B+Tree 索引是有序的,可以用于 ORDER BY 和 GROUP BY 操作。临时表主要是在排序和分组过程中创建,不需要排序和分组,也就不需要创建临时表)。
-
将随机 I/O 变为顺序 I/O(B+Tree 索引是有序的,会将相邻的数据都存储在一起)。
索引的使用条件
-
对于非常小的表、大部分情况下简单的全表扫描比建立索引更高效;
-
对于中到大型的表,索引就非常有效;
-
但是对于特大型的表,建立和维护索引的代价将会随之增长。这种情况下,需要用到一种技术可以直接区分出需要查询的一组数据,而不是一条记录一条记录地匹配,例如可以使用分区技术。
为什么对于非常小的表,大部分情况下简单的全表扫描比建立索引更高效?
如果一个表比较小,那么显然直接遍历表比走索引要快(因为需要回表)。
注:首先,要注意这个答案隐含的条件是查询的数据不是索引的构成部分,否也不需要回表操作。其次,查询条件也不是主键,否则可以直接从聚簇索引中拿到数据。
查询性能优化
使用 explain 分析 select 查询语句
explain 用来分析 SELECT 查询语句,开发人员可以通过分析 Explain 结果来优化查询语句。
select_type
常用的有 SIMPLE 简单查询,UNION 联合查询,SUBQUERY 子查询等。
table
要查询的表
possible_keys
The possible indexes to choose
可选择的索引
key
The index actually chosen
实际使用的索引
rows
Estimate of rows to be examined
扫描的行数
type
索引查询类型,经常用到的索引查询类型:
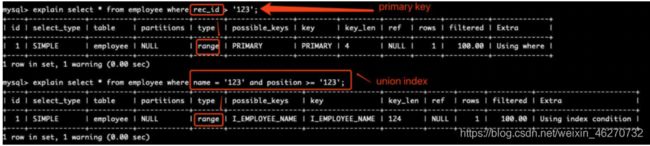
const:使用主键或者唯一索引进行查询的时候只有一行匹配
ref:使用非唯一索引
range:使用主键、单个字段的辅助索引、多个字段的辅助索引的最后一个字段进行范围查询
index:和all的区别是扫描的是索引树
all:扫描全表:
system
触发条件:表只有一行,这是一个 const type 的特殊情况
const
触发条件:在使用主键或者唯一索引进行查询的时候只有一行匹配。
SELECT * FROM tbl_name WHERE primary_key=1;
SELECT * FROM tbl_name
WHERE primary_key_part1=1 AND primary_key_part2=2;
eq_ref
触发条件:在进行联接查询的,使用主键或者唯一索引并且只匹配到一行记录的时候
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;
ref
触发条件:使用非唯一索引
SELECT * FROM ref_table WHERE key_column=expr;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column=other_table.column;
SELECT * FROM ref_table,other_table
WHERE ref_table.key_column_part1=other_table.column
AND ref_table.key_column_part2=1;

range
触发条件:只有在使用主键、单个字段的辅助索引、多个字段的辅助索引的最后一个字段进行范围查询才是 range
SELECT * FROM tbl_name
WHERE key_column = 10;
SELECT * FROM tbl_name
WHERE key_column BETWEEN 10 and 20;
SELECT * FROM tbl_name
WHERE key_column IN (10,20,30);
SELECT * FROM tbl_name
WHERE key_part1 = 10 AND key_part2 IN (10,20,30);
index
The index join type is the same as ALL, except that the index tree is scanned. This occurs two ways:
触发条件:
只扫描索引树
1)查询的字段是索引的一部分,覆盖索引。
2)使用主键进行排序

all
触发条件:全表扫描,不走索引
优化数据访问
减少请求的数据量
- 只返回必要的列:最好不要使用 SELECT * 语句。
- 只返回必要的行:使用 LIMIT 语句来限制返回的数据。
- 缓存重复查询的数据:使用缓存可以避免在数据库中进行查询,特别在要查询的数据经常被重复查询时,缓存带来的查询性能提升将会是非常明显的。
减少服务器端扫描的行数
最有效的方式是使用索引来覆盖查询。
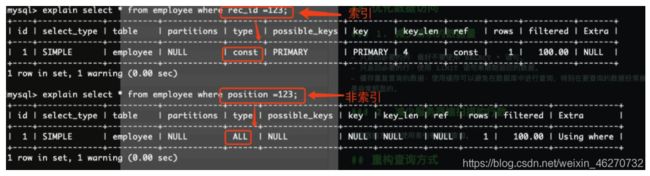
重构查询方式
切分大查询
一个大查询如果一次性执行的话,可能一次锁住很多数据、占满整个事务日志、耗尽系统资源、阻塞很多小的但重要的查询。
DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH);
1
rows_affected = 0
do {
rows_affected = do_query(
"DELETE FROM messages WHERE create < DATE_SUB(NOW(), INTERVAL 3 MONTH) LIMIT 10000")
} while rows_affected > 0
事务
事务是指满足 ACID 特性的一组操作,可以通过 Commit 提交一个事务,也可以使用 Rollback 进行回滚。
ACID
事务最基本的莫过于 ACID 四个特性了,这四个特性分别是:
Atomicity:原子性
Consistency:一致性
Isolation:隔离性
Durability:持久性
原子性
事务被视为不可分割的最小单元,事务的所有操作要么全部成功,要么全部失败回滚。
一致性
数据库在事务执行前后都保持一致性状态,在一致性状态下,所有事务对一个数据的读取结果都是相同的。
隔离性
一个事务所做的修改在最终提交以前,对其他事务是不可见的。
持久性
一旦事务提交,则其所做的修改将会永远?