pandas高级操作2
这次是接着上次的高级操作进行讲解,主要是来介绍高级数据聚合,透视表和交叉表
高级数据聚合
使用groupby分组后,也可以使用transform和apply提供自定义函数实现更多的运算
df.groupby('item')['price'].sum() <==> df.groupby('item')['price'].apply(sum)
transform和apply都会进行运算,在transform或者apply中传入函数即可
transform和apply也可以传入一个lambda表达式
虽然groupby里含有很多函数,但如果你想要用自己设定的函数完成特定计算,则可以使用apply和transform。
具体操作则只需要定义函数之后将函数放入apply就可以了,lambda函数也是可以用的

transform则是可以对返回的结果自动实行一个映射操作,这是apply所不具备的。
操作方法则是和apply一样

结果两者肯定是不同的。
这是apply的结果
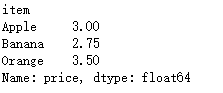
这是transform的结果

如果使用apply则需要手动输入映射操作,transform则不需要。
透视表
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
透视表的优点:
灵活性高,可以随意定制你的分析计算要求
脉络清晰易于理解数据
操作性强,报表神器
比如说我们先导入一个表格(表格数据纯属虚构)
这样的图表非常乱且难以寻得关键信息,这种时候透视表的优点就显现出来了。
pivot_table有四个最重要的参数index、values、columns、aggfunc
index参数:分类汇总的分类条件
每个pivot_table必须拥有一个index。
想看看对阵同一对手在不同主客场下的数据,分类条件为对手和主客场,则可以在index中依次输入对手与主客场。

values参数则是对计算的数据进行筛选
如果我们只需要在主客场和不同胜负情况下的得分、篮板与助攻三项数据,就可以这样操作
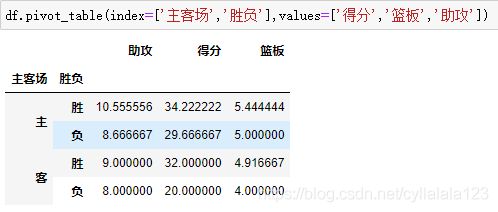
Aggfunc参数是设置我们对数据聚合时进行的函数操作,当我们未设置aggfunc时,它默认aggfunc='mean’计算均值。
如果还想获得在主客场和不同胜负情况下的总得分、总篮板、总助攻时:

将aggfunc更改则可以换为最大值最小值之类的其他值

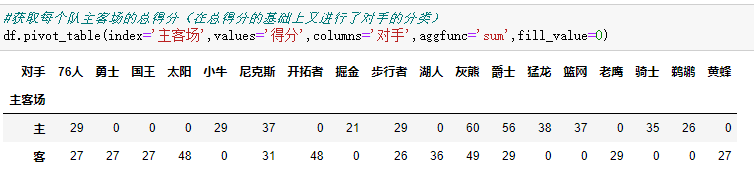
Columns是可以设置列层次字段,对values字段进行分类
比如将主客场设为行对手设为列则可以进行这样的操作
交叉表
是一种用于计算分组的特殊透视图,对数据进行汇总
pd.crosstab(index,colums)
index:分组数据,交叉表的行索引
columns:交叉表的列索引
先设定一个表格:
交叉表比较简单,只需要在crosstab中前者填入根据什么分类后者填入想得到的数据则可完成。

