【三维深度学习】多视角场景点云重建模型PointMVS
PointMVS区别于先前利用cost volum来进行多视角处理的方法,直接基于点云的方式对场景进行处理。从过由粗到细的迭代优化过程,充分结合了几何先验信息和2D纹理信息来来增强点云特征,并利用图网络的来对深度的残差进行有效估计。这种由粗到精的迭代结构获得非常好的重建精度。
1.PointMVS
基于深度学习的现有三维重建方法大多都是基于3D CNN来进行深度图或者体素的预测。但这种方法对于内存的消耗达到了分辨率的三次方量级,使得生成结果的分辨率受到了很大的限制。而点云是一种十分高效高精度的三维表示方法。
在PointMVS中研究人员提出了直接利用点云表示来对目标场景进行处理。整个模型遵循着由粗到精的思想,并可通过迭代的方式不断提升结果的精度。
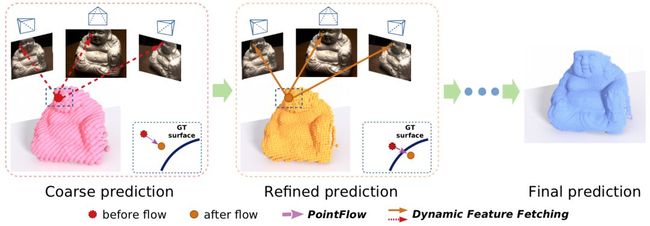
模型从整体上分为两个主要部分:初始深度估计和深度优化迭代两个部分。
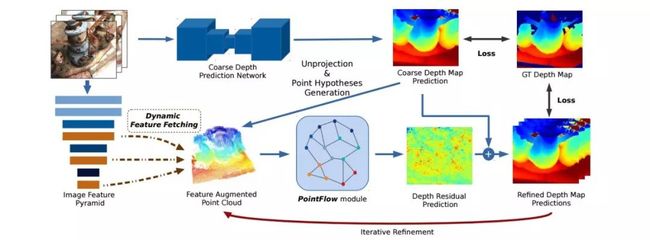
1.1初始深度估计
深度粗估计部分参考了MVSNet的方法,利用多尺度3D-CNN构建了较小的代价空间,从而进行深度粗估计。
多视角图像输出利用简化的MVSNet构建出代价空间,随后输出较为粗糙的深度估计结果。值得注意的是在MVSNet的原始结构中,其特征图尺寸为原图的1/4x1/4,而在PointNet中则使用了1/8x1/8大小的特征图;其次原始MVSNet中的虚拟深度平面为256个,而在PointNet中为了提高效率粗估计阶段只保留了48/96个深度层。这意味着PointNet在初始深度估计阶段的计算量为MVSNet的1/2x1/2x1/5~1/2x1/2x2/5,大约提速10到20倍。
1.2图像特征增强点云
在获得初始深度图的基础上,就可以利用相机参数将初始深度图反投影得到点云,而后从输入多视角图像中抽取特征来增强点云。基于增强后的点云和本文提出的PointFlow方法最终估计出初始深度于基准深度间的残差结果。
受到图像特征可以增强稠密像素匹配的启发,研究人员构建了多尺度的3层金字塔结构从输入图像帧中提取出特征金字塔。每一层金字塔由2D卷积构成,同时下采样步长为2,针对所有输入图像共享同一个特征金字塔。针对每一帧图像 I i I_i Ii,经过特征金字塔作用后得到的特征为:
F i = [ F i 1 , F i 2 , F i 3 ] F_i = [F^1_i,F^2_i,F^3_i] Fi=[Fi1,Fi2,Fi3]
PointMVS中使用的点云特征来自于多视角图像特征的方差和世界坐标系中的归一化三维坐标 X p X_p Xp。其中针对每一个三维点其对应的图像特征,可以在给定相机参数的情况下,通过可查分的反投影方式从多视角特征图中获取。针对不同尺度的金字塔,相机参数可以通过缩放变换来应用于对应尺度的特征图。研究人员将构建基于方差的损失度量(可以理解为不同视角下特征的差异)来将任意视角下的特征进行聚合。
C j = ∑ i = 1 N ( F i j − F j ˉ ) N , ( j = 1 , 2 , 3 ) C^j = \frac{\sum_{i=1}^{N}(F_i^j-\bar{F^j})}{N},(j=1,2,3) Cj=N∑i=1N(Fij−Fjˉ),(j=1,2,3)
上式表示了第j层特征金字塔上,N个不同视角下的特征方差指标。
随后为每个3D点构建特征,研究人员将从图像中获取的特征和归一化的点坐标合并在了一起:
C p = c o n c a t [ C p j , X p ] , ( j = 1 , 2 , 3 ) C_p = concat[C_p^j,X_p],(j=1,2,3) Cp=concat[Cpj,Xp],(j=1,2,3)
这一通过图像特征增强后的点云 C p C_p Cp随后就会被送入到PointFlow中进行深度的残差估计。在每一次迭代过程中,点的三维坐标 X p X_p Xp都会被更新并与金字塔特征相匹配。而后基于动态特征匹配的方法来对增强后的特征进行处理。
值得注意的是,这里的动态特匹配可以基于更新后点云的位置来从图像特征的不同区域中获取特征,而不像基于cost-volum的方法其对应的特征是来自于固定的空间分区。那么这种方法就可以集中于感兴趣的区域来进行更为精细化的处理。
Todo(rjj):dynemic feature fetching understanding
1.3基于PointFlow方法的高精度深度估计
利用代价空间进行计算的深度图精度受限于3D cost volume的分辨率。为了进一步利用图像特征增强的点云网络来提升深度图的分辨率,PointMVS提出了PointFlow的方法来迭代的预测出深度图的残差以提升最终的深度图精度。首先将深度图反投影到3D点云上,而后针对每个点,在参考相机方向上观测所有视角下的邻域点来预测出其于基准表面间的位置差异,使得这些点“流向”目标表面/基准表面。
PointFlow方法主要由假设点生成、边缘卷积、流预测和上采样迭代优化等四部分构成。
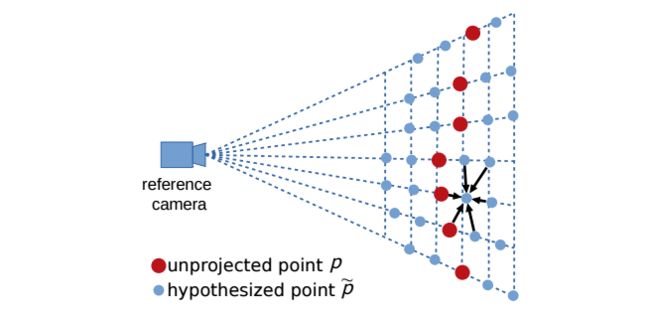
直接利用抽取的图像特征对每个点的位移进行抽取是比较困难的,由于透视变换的存在2D特征图无法有效反映3D欧氏空间中的空间结构特性,所以PointFlow提出了在参考相机方向上设置一系列假设点 p ~ \widetilde p p 来建模。
p ~ = p + k ∗ s ∗ t \widetilde p = p + k*s* \mathbf t p =p+k∗s∗t
其中s为假设点位移的步长,t为参考相机的方向。在某个点周围将构建出2m+1个邻域假设点来。这些参考点将在不同深度上抽取出图像的特征并包含了空间几何关系。
下图中可以看到红色点事反投影点,蓝色点是不同的位移步长生成的假设点。PointFlow的目的在于利用图像特征增强后的点云,计算出红色点相对于每个蓝色邻域假设点的位移概率,并最终得到与基准目标表面间的位移。
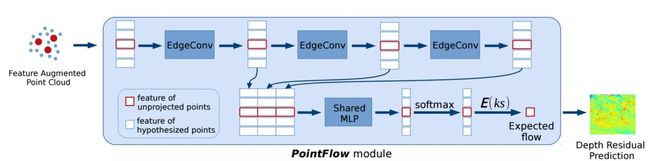
为了进行鲁棒的深度预测,PointFlow从DGCNN中从邻域抽取信息获得启发,利用了knn构建的有向图来表示局域几何结构信息,从而可以被用于点特征的传播。定义边缘卷积来对点云特征进行抽取:
C p ~ ′ = □ q ∈ k N N ( p ~ ) h θ ( C p ~ , C p ~ − C q ~ ) C'_{\tilde p} =\square_{q \in kNN(\tilde p)} h_\theta(C_{\tilde p} , C_{\tilde p} -C_{\tilde q} ) Cp~′=□q∈kNN(p~)hθ(Cp~,Cp~−Cq~)
其中 C p ~ = { C p ~ 1 , ⋯ , C p ~ n } C_{\tilde p} = \{C_{\tilde p_1} ,\cdots,C_{\tilde p_n} \} Cp~={Cp~1,⋯,Cp~n}为特征增强后的点集合,q为邻域点。h为非线性映射函数,方框为逐个通道的对称聚合操作(包括池化、加权等),最终用于学习每一点对应的局部特征。
在充分利用图像特征增强后的点云信息就可以进行流预测了。PointFlow中利用了3个边缘卷积层来聚合多尺度点云信息,并加入了跳接层保留局部信息。最终通过共享的MLP将逐点特征转换为每一反投影点的假设点的概率。最终通过所有假设点的概率加权和得到最终点的位移(每个假设点都在原始点周围领域上,通过特征抽取获取每个假设点的概率,加权后即可得到原始点向目标点流动的位移):
Δ d p = E ( k s ) = ∑ k = − m m k s ∗ P o r b ( p ~ k ) \Delta d_p = \mathbf E(ks) = \sum_{k=-m}^m ks * Porb(\tilde p_k) Δdp=E(ks)=k=−m∑mks∗Porb(p~k)
下图显示了特征增强后的点云通过边缘卷积处理得到深度图的残差结果:
由于这种方法针对点云进行处理十分灵活,所以可以对结果进行迭代处理不断提升精度,克服课3D cost volum固定剖分的性质。对于预测出的粗深度图,PointFlow中可以先对其进行上采样,随后再进行流预测得到优化后的深度图。此外还可以在迭代过程中减小深度步长s,使得更近距离的假设点可以捕捉到更为精细的特征,并得到更为精确的深度预测结果。
2.实现过程和实验结果
通过PointFlow处理后,最终的损失函数如下图所示,其中包含了l次迭代的L1损失,其中损失只在有效点上进行计算。 λ , s \lambda,s λ,s为迭代过程中的调节参数。
L o s s = ∑ i = 0 l λ ( i ) s ( i ) ( ∑ p ∈ P v a l i d ∣ ∣ D G T ( p ) − D ( i ) ( p ) ∣ ∣ 1 ) Loss = \sum_{i=0}^l{\frac{\lambda^{(i)}}{s^{(i)}}(\sum_{p \in P_{valid}}} ||D_{GT}(p)-D^{(i)}(p)||_1 ) Loss=i=0∑ls(i)λ(i)(p∈Pvalid∑∣∣DGT(p)−D(i)(p)∣∣1)
输入图像的尺寸为640x512,输入三个视角(预测时候使用5视角)。第一部分构架3D 代价空间的虚拟深度层数设置为 48(预测是使用了96层,425mm–921mm,比MVSNet约快20倍),优化迭代两次。PointFlow中使用的点数为16。
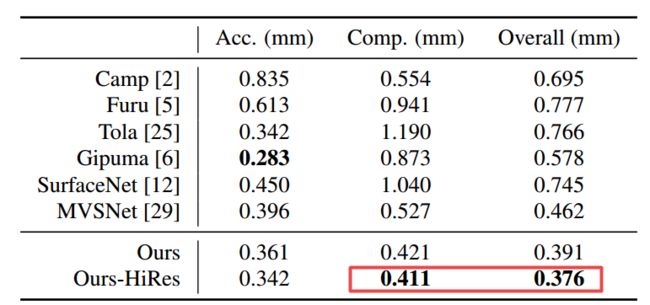
实验在DTU数据上进行,其中包含了7种光照条件在49-64个位置的124个场景下的图像数据集及其相机参数。PointMVS算法重建点云的完整性和精度如下表所示,重建的视觉效果也较为细腻,细节更为准确丰富。

3.消融性分析
研究中比较了优化迭代次数、边缘卷积和图像特征金字塔对于最终结果的作用。首先迭代对于点云质量有着明显的提升:


可以看到在第二次迭代时起生成结果已经明显超过了MVSNet的结果,证明了迭代优化策略的有效性。
其次,边缘卷积、欧氏空间聚类和特征金字塔增强都为模型性能做出了贡献。EdgeConv:基于邻域点的边缘卷积对于居于几何关系的抽取十分重要,可以利用特来针对性的处理点云。EUCNN:欧氏空间中的knn聚类可以有效克服图像空间中邻近点(但在三维空间中有很大距离的点)所带来的影响。Feature Pyramid:图像的内容信息为增强点云特征贡献了很大的部分。
TODO(TOM):tab3+supplementary
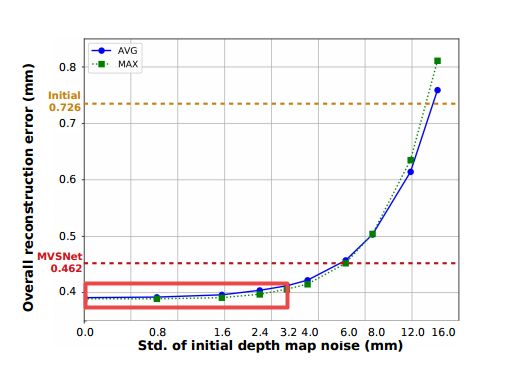
通过对初始深度图加入不同强度的高斯噪声,结果精度较为稳定,显示出PointFlow较强鲁棒性,下图显示了在两种pool情况下起误差随初始深度图噪声的变换,在0~2.4mm的误差下都保持了较小的误差。
同时于PU-Net比较,对于粗深度图的优化过程表明,引入流机制的PointFlow上采样能力更强。
此外,由于这种方法(PointFlow中的迭代优化)可以处理任意大小的点云,所以可以针对性的对感兴趣区域进行优化(Foveated),得到粗中有细、层次清晰的重建结果,可以在同一个结果中包含多种点云密度(迭代优化的分区不同)。

pic from pexels.com