【Python爬虫】Scrapy学习之路
目录
一、概述
二、安装部署
三、项目运行流程
四、框架结构解析
五、项目实例
六、项目整体代码
七、抓取效果截图
八、Scrapy框架总结
一、概述
1.它是一个为了爬取网站数据,提取结构性数据而编写的应用框架。
2.应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中。
二、安装部署
pip install Scrapy三、项目运行流程
1.使用 scrapy startproject test_scrapy(项目名) 指令创建一个项目
scrapy startproject test_scrapy2.使用 scrapy genspider scrapy_01 www.baidu.com 指令创建一个爬虫代码
scrapy genspider scrapy_01 www.baidu.com其中,scrapy_01为文件名,www.baidu.com为抓取的网址,其都可以自己指定。
3.在创建的Scrapy文件上进行编写代码
4.使用 scrapy crawl scrapy_01 -o ./phone.csv 指令启动项目或使用 scrapy crawl scrapy_01 -o ./phone.csv 指令启动并将结果存储在phone.csv文件中
#启动项目
scrapy crawl scrapy_01 -o
#也可以启动并将结果存储在phone.csv文件中
scrapy crawl scrapy_01 -o ./phone.csv 四、框架结构解析
1.项目目录
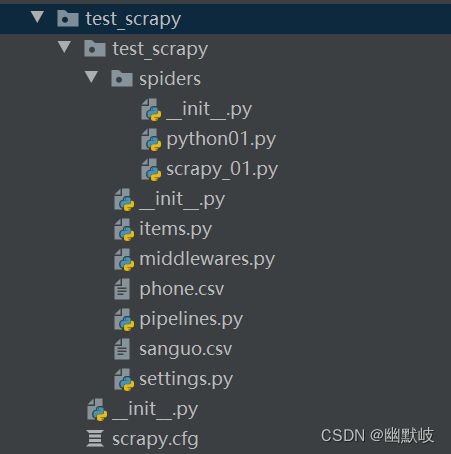
scrapy.cfg 【项目的配置文件】
settings.py 【项目的配置文件】
spiders/ 【防止 爬虫代码的目录】
2. 爬虫文件的名字name不能重复
name = 'scrapy_01'3.scrapy 允许爬取的 url
allowed_domains = ['www.baidu.com']4.scrapy 去爬取的 url 列表
start_urls = ['http://www.baidu.com/','https://www.sougou.com']五、项目实例
使用Scrapy爬虫框架,进行爬取58同城的手机信息,并将信息保存在csv文件中。
六、项目整体代码
import scrapy
class Scrapy01Spider(scrapy.Spider):
name = 'scrapy_01'
allowed_domains = ['www.baidu.com']
start_urls = ['https://dl.58.com/shouji']
def parse(self, response):
#1.返回selector(xpath,data[标签内容])
tr_list = response.xpath('//div[@class="containnerWrap clearfix"]/section/div[@class="cleft"]/table//tr')
res = []
for index,tr in enumerate(tr_list):
message_get = tr.xpath('./td/a/div[@class="new-long-tit new-long-tit2"]/text()').get()
dic = {
'id' : index,
'message' : message_get
}
res.append(dic)
return res七、抓取效果截图

八、Scrapy框架总结
Scrapy是Python开发的一个快速、高层次的屏幕抓取和web抓取框架,用于抓取web站点并从页面中提取结构化的Scrapy吸引人的地方在于它是一个框架,任何人都可以根据需求方便的修改。