0. 数据预览
这里的数据是虚构的语数外成绩,大家在演示的时候拷贝一下就好啦。
import pandas as pd df = pd.read_clipboard() df
姓名 |
语文 |
数学 |
英语 |
性别 |
总分 |
0 |
才哥 |
91 |
95 |
92 |
1 |
1 |
小明 |
82 |
93 |
91 |
1 |
2 |
小华 |
82 |
87 |
94 |
1 |
3 |
小草 |
96 |
55 |
88 |
0 |
4 |
小红 |
51 |
41 |
70 |
0 |
5 |
小花 |
58 |
59 |
40 |
0 |
6 |
小龙 |
70 |
55 |
59 |
1 |
7 |
杰克 |
53 |
44 |
42 |
1 |
8 |
韩梅梅 |
45 |
51 |
67 |
0 |
1. apply
apply可以对DataFrame类型数据按照列或行进行函数处理,默认情况下是按照列(单独对Series亦可)。
在案例数据中,比如我们想将性别列中的1替换为男,0替换为女,那么可以这样搞定。
先自定义一个函数,这个函数有一个参数 s(Series类型数据)。
def getSex(s): if s==1: return '男' elif s==0: return '女'
上述函数还有更简洁写法,这里方便理解采用最直观的写法哈。
然后,我们直接使用apply去调用这个函数即可。
df['性别'].apply(getSex)
可以看到输出结果如下:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性别, dtype: object
当然,我们也可以直接用调用匿名函数lambda的形式:
df['性别'].apply( lambda s: '男' if s==1 else '女' )
可以看到结果是一样的:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性别, dtype: object
以上是单纯根据一列的值条件进行的数据处理,我们也可以根据多列组合条件(可以了解为按行)进行处理,需要注意这种情况下需要指定参数axis=1,具体看下面案例。
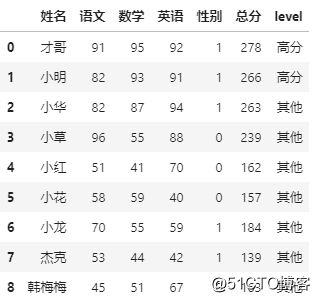
案例中,我们认为总分高于200且数学分数高于90为高分
# 多列条件组合 df['level'] = df.apply(lambda df: '高分' if df['总分']>=200 and df['数学']>=90 else '其他', axis=1) df
同样,上述用apply调用的函数都是自定义的,实际上我们也可以调用内置或者pandas/numpy等自带的函数。
比如,求语数外和总分最高分:
# python内置的函数 df[['语文','数学','英语','总分']].apply(max)
语文 96
数学 95
英语 94
总分 278
dtype: int64
求语数外和总分平均分:
# numpy自带的函数 import numpy as np df[['语文','数学','英语','总分']].apply(np.mean)
语文 69.777778
数学 64.444444
英语 71.444444
总分 205.666667
dtype: float64
2. applymap
applymap则是对每个元素的函数处理,变量是每个元素值。
比如对语数外三科超过90分认为是科目高分
df[['语文','数学','英语']].applymap(lambda x:'高分' if x>=90 else '其他')
语文 |
数学 |
英语 |
0 |
高分 |
高分 |
1 |
其他 |
高分 |
2 |
其他 |
其他 |
3 |
高分 |
其他 |
4 |
其他 |
其他 |
5 |
其他 |
其他 |
6 |
其他 |
其他 |
7 |
其他 |
其他 |
8 |
其他 |
其他 |
3. map
map则是根据输入对应关系映射值返回最终数据,作用于某一列。传入的值可以是字典,键值为原始值,值为需要替换的值。也可以传入一个函数或者字符格式化表达式等等。
以上面性别列中的1替换为男,0替换为女为例,还可以通过map来实现
df['性别'].map({1:'男', 0:'女'})
输出结果也是一致的:
0 男
1 男
2 男
3 女
4 女
5 女
6 男
7 男
8 女
Name: 性别, dtype: object
比如总分列想变成格式化字符:
df['总分'].map('总分:{}分'.format)
0 总分:278分
1 总分:266分
2 总分:263分
3 总分:239分
4 总分:162分
5 总分:157分
6 总分:184分
7 总分:139分
8 总分:163分
Name: 总分, dtype: object
4. agg
agg一般用于聚合,在分组或透视操作中常见到,用法是和apply比较接近。
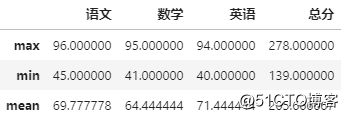
比如,求语数外和总分的最高分、最低分和平均分
df[['语文','数学','英语','总分']].agg(['max','min','mean'])
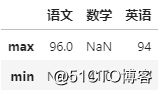
我们还可以对不同的列进行不同的运算(用字典形式指定)
# 语文最高分、数学最低分和英文最高最低分
df.agg({'语文':['max'],'数学':'min','英语':['max','min']})
当然也支持自定义函数的调用
5. pipe
以上四个调用函数的方法,我们发现被调用的函数的参数就是 DataFrame或Serise数据,如果我们被调用的函数还需要别的参数,那么该如何做呢?
所以,pipe就出现了。
pipe又称管道方法,可以将我们的处理分析过程标准化、流程化。它在调用函数的时候可以带被调用函数的其他参数,这样就方便自定义函数的功能扩展了。
比如,我们需要获取总分大于n,性别为sex的同学的数据,其中n和sex是可变参数,那么用apply等就不太好处理。这个时候,就可以用到pipe方法来搞事了!
我们先定义一个函数:
# 定义一个函数,总分大于等于n,性别为sex的同学数据(sex为2表示不分性别) def total(df, n, sex): dfT = df.copy() if sex == 2: return dfT[(dfT['总分']>=n)] else: return dfT[(dfT['总分']>=n) & (dfT['性别']==sex)]
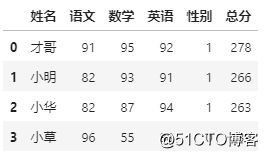
如果我们要找到总分大于200,不分性别的学生成绩,可以这样:
df.pipe(total,200,2)
再找总分大于150,性别为男生(1)的学生成绩,可以这样:
df.pipe(total,150,1)
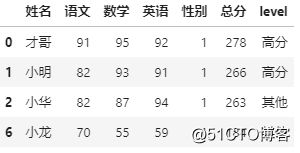
再找总分大于200,性别为女生(0)的学生成绩,可以这样:
df.pipe(total,200,0)

以上就是本次我们介绍的5种调用函数的方法,这些操作技巧可以让我们在处理数据时更加灵活自如
到此这篇关于分享5个数据处理更加灵活的pandas调用函数方法的文章就介绍到这了,更多相关pandas调用函数方法内容请搜索脚本之家以前的文章或继续浏览下面的相关文章希望大家以后多多支持脚本之家!