NLP:language model(n-gram/Word2Vec/Glove)
首先,大概讲一下自然语言处理的背景。互联网上充斥着大规模、多样化、非结构化的自然语言描述的文本,如何较好的理解这些文本,服务于实际业务系统,如搜索引擎、在线广告、推荐系统、问答系统等, 给我们提出了挑战。例如在效果广告系统中,需要将 Query(User or Page) 和广告 Ad 投影到相同的特征语义空间做精准匹配,如果 Query 是用户,需要基于用户历史数据离线做用户行为分析,如果 Query 是网页,则需要离线或实时做网页语义分析。文本语义分析(又称文本理解、文本挖掘)技术研究基于词法、语法、语义等信息分析文本,挖掘有价值的信息,帮助人们更好的理解文本的意思,是典型的自然语言处理工作,关键子任务主要有分词、词性标注、命名实体识别、Collection 挖掘、Chunking、句法分析、语义角色标注、文本分类、文本聚类、自动文摘、情感分析、信息抽取等。而这些任务都基于一个基本的技术——语言模型。本文就将讲解一些常用高效的语言模型,具体的实现细节请参考相应的论文和理论讲解博客。
一、统计语言模型
记得最早学习语言模型是在研究生的《统计自然语言处理》课上,由哈工大关毅老师主讲,从噪声信道模型切入,到 N-Gram 语言模型的构建、平滑、评价(KL 距离/相对熵、交叉熵、困惑度),接着以音字转换系统(即拼音输入法)为应用实践,最终还引出隐马尔科夫模型和最大熵模型。
后来又接触到前腾讯副总裁,现 Goolge 研究员吴军撰写的《数学之美》,微软拼音输入法团队博客(微软拼音输入法最初由哈工大王晓龙、关毅等老师完成),逐渐领悟到语言模型,尤其是统计语言模型在众多领域中发挥着重要作用,如下:
- 中文分词:P(已/ 结婚/ 的/ 和/ 尚未/ 结婚/ 的/ 青年 | 已结婚的和尚未结婚的青年) > P(已/ 结婚/ 的/ 和尚/ 未/ 结婚/ 的/ 青年 | 已结婚的和尚未结婚的青年)
- 机器翻译:P(high winds tonight | 今晚有大风) > P(large winds tonight | 今晚有大风)
- 拼写纠错/Query 改写:P(about fifteen minutes from) > P(about fifteen minuets from)
- 语音识别:P(I saw a van) >> P(eyes awe of an)
- 音字转换:P(机器翻译及其应用激起了人们极其浓厚的学习兴趣 | ji qi fan yi ji qi ying yong ji qi le ren men ji qi nong hou de xue xi xing qu) > P(机器翻译机器应用激起了人们极其浓厚的学习兴趣 | ji qi fan yi ji qi ying yong ji qi le ren men ji qi nong hou de xue xi xing qu)
- 自动文摘、问答系统、OCR、… …
2011 年刚加入腾讯时,完成的第一个项目是在线广告系统中的 Keyword Extraction,曾尝试对 query log、bidterm、广告创意等建立统计语言模型,计算 Candidate Keyword 的生成概率,作为排序阶段的重要特征之一。
接下来,我们不妨一起看下语言模型,尤其是 N-Gram 语言模型的数学表示、效果评估、模型平滑及模型训练(尤其是分布式),为我们后续介绍神经网络语言模型和序列标注技术打个好基础。
语言模型介绍
以上语言模型的各种应用场景可以形式化统一表示如下:
p(S)=p(w1,w2,…,wn)=prodni=1p(wi|w1,w2,…,wi−1)
p(S) 就是语言模型,即用来计算一个句子 S 概率的模型。
那么,如何计算p(wi|w1,w2,…,wi−1) 呢?最简单、直接的方法是计数后做除法,即最大似然估计(Maximum Likelihood Estimate,MLE),如下:
p(wi|w1,w2,…,wi−1)=fraccount(w1,w2,…,wi−1,wi)count(w1,w2,…,wi−1)
其中,count(w1,w2,…,wi−1,wi) 表示词序列(w1,w2,…,wi−1,wi) 在语料库中出现的频率。这里面临两个重要的问题:数据稀疏严重和参数空间过大,导致无法实用。
实际中,我们一般较常使用的是 N 元语法模型(N-Gram),它采用了马尔科夫假设(Markov Assumption),即认为语言中每个单词只与其前面长度 N-1 的上下文有关。
- 假设下一个词的出现依赖它前面的一个词,即 bigram,则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn−1)=p(w1)p(w2|w1)p(w3|w2)…p(wn|wn−1)
- 假设下一个词的出现依赖它前面的两个词,即 trigram,则有:
p(S)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|w1,w2,…,wn−1)=p(w1)p(w2|w1)p(w3|w1,w2)…p(wn|wn−2,wn−1)
那么,我们在面临实际问题时,如何选择依赖词的个数,即 N 呢?
- 更大的 n:对下一个词出现的约束信息更多,具有更大的辨别力;
- 更小的 n:在训练语料库中出现的次数更多,具有更可靠的统计信息,具有更高的可靠性。
理论上,n 越大越好,经验上,trigram 用的最多,尽管如此,原则上,能用 bigram 解决,绝不使用 trigram。
从本质上说,这种统计语言模型描述的是有限状态的正则文法语言,而自然语言是不确定性语言,因此与真实语言差异较大,表达能力有限,尤其无法较好的处理长距离依赖语言现象。但是,其抓住了自然语言中的局部性约束(Local Constrain)性质,因此该模型在实际应用中取得了较大的成功。
构建 N-Gram 语言模型
通常,通过计算最大似然估计(Maximum Likelihood Estimate)构造语言模型,这是对训练数据的最佳估计,如 bigram 公式如下:
p(wi|wi−1)=fraccount(wi−1,wi)count(wi−1)
如给定句子集“ I am Sam
Sam I am
I do not like green eggs and ham ”
部分 bigram 语言模型如下所示:

count(wi) 如下:

count(wi−1,wi) 如下:

则 bigram 为:

那么,句子“ I want chinese food ”的概率为:
p(<s>Iwantchinesefood</s>) =p(I|<s>)P(want|I)p(chinese|want)p(food|chinese)p(</s>|food)=.000031
为了避免数据溢出、提高性能,通常会使用取 log 后使用加法运算替代乘法运算。
log(p1∗p2∗p3∗p4)=log(p1)+log(p2)+log(p3)+log(p4)
网上有一些公开的 n-gram 数据集:
- Google Web1T5-gram(http://googleresearch.blogspot.com/2006/08/all-our-n-gram-are-belong-to-you.html)
Total number of tokens: 1,306,807,412,486
Total number of sentences: 150,727,365,731
Total number of unigrams: 95,998,281
Total number of bigrams: 646,439,858
Total number of trigrams: 1,312,972,925
Total number of fourgrams: 1,396,154,236
Total number of fivegrams: 1,149,361,413
Total number of n-grams: 4,600,926,713
- Google Book N-grams(http://books.google.com/ngrams/)
- Chinese Web 5-gram(http://www.ldc.upenn.edu/Catalog/catalogEntry.jsp?catalogId=LDC2010T06)
语言模型效果评估
语言模型构造完成后,如何确定其好坏呢?目前主要有两种评价方法:
- 实用方法:通过查看该模型在实际应用(如拼写检查、机器翻译)中的表现来评价,优点是直观、实用,缺点是缺乏针对性、不够客观;
- 理论方法:迷惑度/困惑度/混乱度(preplexity),其基本思想是给测试集赋予较高概率值的语言模型较好,公式如下:

由公式可知,迷惑度越小,句子概率越大,语言模型越好。使用《华尔街日报》,训练数据规模为38 million words,构造 n-gram 语言模型,测试集规模为 1.5 million words,迷惑度如下表所示:

数据稀疏与平滑技术
大规模数据统计方法与有限的训练语料之间必然产生数据稀疏问题,导致零概率问题,符合经典的 zip’f 定律。如 IBM Brown:366M 英语语料训练 trigram,在测试语料中,有14.7% 的 trigram 和 2.2% 的bigram 在训练语料中未出现。
数据稀疏问题定义:“The problem of data sparseness, also known as the zero-frequency problem arises when analyses contain configurations that never occurred in the training corpus. Then it is not possible to estimate probabilities from observed frequencies, and some other estimation scheme that can generalize (that configurations) from the training data has to be used. —— Dagan”。
为了解决数据稀疏问题,人们为理论模型实用化而进行了众多尝试与努力,诞生了一系列经典的平滑技术,它们的基本思想是“降低已出现 n-gram 的条件概率分布,以使未出现的 n-gram 条件概率分布非零”,且经数据平滑后一定保证概率和为1,数据平滑前后如下图所示:
- Add-one(Laplace) Smoothing
加一平滑法,又称拉普拉斯定律,其保证每个 n-gram 在训练语料中至少出现 1次,以 bigram 为例,公式如下:

其中,V 是所有 bigram 的个数。
承接上一节给的例子,经 Add-one Smoothing 后,c(wi−1,wi) 如下所示:

则 bigram 为:

在V>>c(wi−1,wi)时,即训练语料库中绝大部分 n-gram 未出现的情况(一般都是如此),Add-one Smoothing后有些“喧宾夺主”的现象,效果不佳。如下图所示:
一种简单的改进方法是 add-δ smoothing (Lidstone, 1920; Jeffreys, 1948)。δ 是一个小于 1 的数。
- Good-Turing Smoothing
其基本思想是利用频率的类别信息对频率进行平滑。如下图所示:
其中,Nc表示出现次数为 c 的 n-gram 的个数。调整出现频率为 c 的 n-gram 折扣频率为 c∗:
但是,对于较大的 c,可能出现Nc+1=0 或者 Nc>Nc+1的情况,反而使得模型质量变差,如下图所示:

直接的改进策略就是“对出现次数超过某个阈值的 gram 不进行平滑,阈值一般取8~10,其他方法请参见“Simple Good-Turing”。
实际中,很少单独使用 Good Turing,而是将其应用到 backoff 平滑算法中。
- Interpolation Smoothing
不管是 Add-one,还是 Good Turing 平滑技术,对于未出现的 n-gram 都一视同仁,难免存在不合理性(事件发生概率存在差别),所以这里再介绍一种线性插值平滑技术,其基本思想是将高阶模型和低阶模型作线性组合,利用低元 n-gram 模型对高元 n-gram 模型进行线性插值。因为在没有足够的数据对高元 n-gram 模型进行概率估计时,低元 n-gram 模型通常可以提供有用的信息。公式如下(下方为上下文相关的扩展表示):
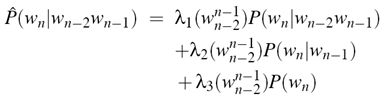
lambdas可以通过 EM 算法来估计,具体步骤如下:
-
- 首先,确定三种数据:Training data、Held-out data 和Test data;

-
- 然后,根据 Training data 构造初始的语言模型,并确定初始的lambdas(如均为平均值,保证和为1);
-
- 最后,基于 EM 算法迭代地优化lambdas,使得 Held-out data 概率最大化,如下式所示:
- Katz Backoff
其基本思想是如果 n-gram 出现频率为 0,就回退到(n-1)-gram 近似求解,如下式所示:
其中,P∗为折扣概率,而不直接使用 MLE 的概率,比如使用 Good-Turing,这样才能保证 ,alpha是归一化因子,求解公式如下:
其他的平滑算法,还有 Absolute discounting,Kneser-Ney Smoothing,Interpolated Kneser-Ney Smoothing 等,在此不再一一详述。
- Web-scale LMs
2007 年 Google Inc. 的 Brants et al. 提出了针对大规模 n-gram 的平滑技术——“Stupid Backoff”,取得了非常好的效果(有数据,任性),已成功应用于 Google 翻译、语音搜索和自动语音识别等产品中。其 backoff 策略简单粗暴,甚至不保证 n-gram 的概率意义(用 S 代替 P,仅表示相对大小的 Score),公式如下:

数据平滑技术是构造高鲁棒性语言模型的重要手段,且数据平滑的效果与训练语料库的规模有关。训练语料库规模越小,数据平滑的效果越显著;训练语料库规模越大,数据平滑的效果越不显著,甚至可以忽略不计——锦上添花。
语言模型实战
n-gram 语言模型的训练流程如下图所示:
以 MLE 为例,可以将模型训练拆分成三个 MapReduce 任务(在此基础上很容易增加平滑功能),如下表所示:
如果不想自己动手实现,推荐几款开源的语言模型项目:
- SRILM(http://www.speech.sri.com/projects/srilm/)
- IRSTLM(http://hlt.fbk.eu/en/irstlm)
- MITLM(http://code.google.com/p/mitlm/)
- BerkeleyLM(http://code.google.com/p/berkeleylm/)
在使用 n-gram 语言模型时,也有一些技巧在里面。例如,面对 Google N-gram 语料库,压缩文件大小为 27.9G,解压后 1T 左右,如此庞大的语料资源,使用前一般需要先剪枝(Pruning)处理,缩小规模,如仅使用出现频率大于 threshold 的 n-gram,过滤高阶的 n-gram(如仅使用 n<=3 的资源),基于熵值剪枝,等等。
另外,在存储方面也需要做一些优化,如使用 Trie 数据结构存储,借助 bloom filter 辅助查询,把 string 映射为 int 类型处理(基于 huffman 编码、varint 等方法),float/double 转成 varint 或 int 类型(如概率值精确到小数点后 6 位,然后乘 10E6,即可将浮点数转为整数)。
语言模型变种
- Class-based N-gram Model
该方法基于词类建立语言模型,以缓解数据稀疏问题,且可以方便融合部分语法信息。
- Topic-based N-gram Model
该方法将训练集按主题划分成多个子集,并对每个子集分别建立N-gram语言模型,以解决语言模型的主题自适应问题。架构如下:
- Cache-based N-gram Model
该方法利用 cache 缓存前一时刻的信息,以用于计算当前时刻概率,以解决语言模型动态自适应问题。这源于:
-People tends to use words as few as possible in the article.
-If a word has been used, it would possibly be used again in the future.
架构如下图所示:
像 QQ、搜狗、谷歌等智能拼音输入法就可以采用此策略(声明:作者并不清楚实际产品中的设计),即针对用户个性化输入日志建立基于 cache 的语言模型,用于对通用语言模型输出结果的调权,还可以丰富个性化词条,实现输入法的个性化、智能化。由于动态自适应模块的引入,产品越用越智能,越用越好用,越用越上瘾。
- Skipping N-gram Model &Trigger-based N-gram Model
二者核心思想都是刻画远距离约束关系。
- 指数语言模型:最大熵模型 MaxEnt、最大熵马尔科夫模型 MEMM、条件随机域模型 CRF
传统的 n-gram 语言模型,只是考虑了词形方面的特征,而没有词性以及语义层面上的知识,并且数据稀疏问题严重,经典的平滑技术也都是从统计学角度解决,未考虑语法、语义等语言学作用。
MaxEnt、MEMM、CRF 可以更好的融入多种知识源,刻画语言序列特点,常用于解决序列标注问题。如下图所示,对比了 HMM、MEMM 和 CRF 结构。
二、神经语言模型
NNLM 最早由Bengio系统化提出并进行了深入研究[Bengio, 2000, 2003]。当然分开来看,(1) distributed representation最早由Hinton提出(1985), (2)利用神经网络建模语言模型由Miikkulainen and Dyer,Xu and Rudnicky分别在1991和2000提出。
NNLM 依赖的一个核心概念就是词向量(Word Embedding)。词向量源于Hinton在Learning distributed representations of concepts提出的Distributed Representation,Bengio将其引入到语言模型建模中,提出了NNLM。那么,我们不禁要问,什么是词向量呢?
2.1 词向量
简而言之,词向量是用一个向量来表示一个词,一定程度上可以用来刻画词之间的语义距离。
a、词表中的词i表示为一个词向量C(i),C(i)∈Rm,其维度m一般取值为30,50,60,100等值。
b、词向量为神经网络的一类参数,可以通过训练得到,同时基于词向量可以表示词序列wt1的联合分布。
为了得到词向量,我们需要在给定训练数据集情况下,训练得到目标模型f(wt,….,wt−n+1)=P^(wt|wt−n+1t)。而模型需要满足的约束,即对于任意的wt−11,∑|V|i=1f(wi,wt−1,…,wt−n+1)=1,f>0,表示wt与上下文wt−1,…,wt−n+1所有可能的组合的概率和为1。 如此,我们可以将f(wt,….,wt−n+1)分解成两部分:
a、词表中任意单词wi表示为词向量,由此构建了一个m×|V|的矩阵C。
b、词的概率分布可以通过矩阵C进行变换得到。函数g是组合上下文中词向量(C(wt−n+1),C(wt−n),…C(wt−1))构建一个词wt的条件概率分布,即函数g的输出为一个向量,其第i个分量表示当前词wt等于词表中第i个词Vi的条件概率,P^(wt=Vi|wt−11),函数f组合了C和g得到最终的输出结果。
2.2求解目标
一般而言,神经网络语言模型的优化目标是最大化带正则化项的Log-Likelihood,其中参数集合为θ =(C,ω),ω为神经网络的参数。
L=1T∑tlogf(wt,wt−1,…wt−n+1;θ)+R(θ)(2)
3 Bengio NIPS’03 Model
3.1 模型结构
Bengio使用前馈神经网络(FFNN,Feed Forward Neural Network)表示f,其结构如下:
图 1 Bengio Yoshua提出的神经网络结构
上图中,输出层为Softmax,保证满足概率分布的约束:
P^(wt|wt−1,…,wt−n+1)=eywt∑ieywi(3)
其中,ywi是每个词非正规化的log概率值,y的值是通过下式计算得到,参数分别为b,W,U,d,H:
y=b+Wx+Utanh(d+Hx)(4)
W通常设置为0,即输出层和输入层不存在直接联系,输入向量x为上下文环境对应的词向量的拼接组合。在模型中,令θ=(b,U,d,H,C),其中,d是输入层到隐藏层的偏置(长度为|V|),U为隐藏层到输出层的参数(大小为|V|×h),H为输入层到隐藏层的参数,b为隐藏层到输出层的偏置(长度为|h|),C是词向量矩阵(大小为|V|×m),总共的参数为|V|(1+nm+h)+h(1+(n−1)m)。
模型求解方式采用随机梯度上升(SGA,Stochastic Gradient Ascent),SGA类似于SGD,仅目标函数存在min和max的区别。
θ←θ+ϵ∂logP^(wt|wt−11)∂θ(5)
3.2发展方向
Bengio在论文的Feature Work部分提出了神经网络语言模型的可能改进方向,在后续研究者(包括他本人)的工作中多有所体现。
a、将神经网络分解成为小的子网络,比如利用词的聚类等。
b、加速SoftMax中的正则项Z的快速求导
c、仅对一部分输出进行梯度传播。
d、引入先验知识,比如语义信息(WordNet),语法信息(low-level: POS, high level:句法结构)等。
e、词向量可解释性。
f、解决一词多义问题(Polysemous)。
4 Hierarchical Neural Language Model
基于前述工作,Bengio又提出了层次结构的神经网络语言模型,用于加速模型的训练和推断过程。
4.1 模型结构
Hierarchical Neural Language Model的表达式如下:
f(wt,wt−1,wt−2,…,wt−n+1)=e−g(wt,wt−1,wt−2,…,wt−n+1)∑ve−g(v,wt−1,wt−2,…,wt−n+1)(6)
其中g(wt,wt−1,wt−2,…,wt−n+1)可以看作能量函数。
同上文一致,令C为词向量矩阵(word embedding matrix),Ci为词i对应的向量,上述能量函数可以表示为,
g(wt,wt−1,wt−2,…,wt−n+1)=aTtanh(c+Wx+UCTv)(7)
上式中,xT为x的转置,a,b,c,W,U为对应的参数向量和矩阵,x是通过拼接词wt的上下文中词向量得到。
令h为模型中隐藏层的单元数,我们可以计算得到整个模型的参数个数为(n–1)hd+|V|h(d+1)。假定h为100,词表|V|的大小20,000,Context的大小n为5,可知第一部分为12,000,第二部分为6,000,000,计算量依然很大。
4.2 参数求解
模型求解参考了Goodman加速最大熵的语言模型训练过程中的工作,将词表中的词进行一个预处理(按类层级划分),这样可以达到不错的加速比,O(Vlog2V√)。这样在计算式(2)时,可以转换为,
P(wt|wt−1,wt−2,…,wt−n+1)=∏j=1L(wt)−1P(bj(wt)|b1(wt),…,bj−1(wt),wt−1,wt−2,…,wt−n+1)(8)
其中,L(wt)为树的深度,bj(wt)是wt属于类别j的指示变量。按照上述形式,计算log(wt|wt−1,wt−2,…,wt−n+1)和▽log(wt|wt−1,wt−2,…,wt−n+1)的复杂度和L(wt)成正比(相比V,要小很多)。
5 Log Bi-Linear
Hinton在研究RBM时,结合神经网络语言模型提出了三种基于RBM的语言模型,FRBM(Factored RBM)、Temporal FRBM、Log-Bilinear Language Model,其中Log Bi-Linear为前两者的简化版本,本文中仅介绍Log-BiLinear Language Model。
5.1 模型结构
类似于Log-Linear模型,Log Bi-Linear模型在能量函数部分(EXP上面那个部分的相反数)加入了一个双线性项,注意这里的R是词向量构成的矩阵,C代表此之前的连接权值。
E(wn;w1:n−1)=−(∑i=1n−1viRCi)RTvn–bTrRTvn–bTvvn(9)
其中,Ci表示wi和wn之间的连接关系的参数,R表示字典中词向量的矩阵,第i行表示第i个单词的词向量,vi表示一个和字典长度相同的指示向量,即词i对应词向量可以表示为viR; br,bv表示对应的偏置。从上述能量函数可以看出,它是一个双线性函数,需要注意的是这里的能量函数是RBM的幂数部分,其对应的语言模型形式为,
P(wn|w1:n−1)=1Zcexp(−E(wn;w1:n−1))(10)
其中,Zc=∑wnexp(−E(wn;w1:n−1))。
Log Bi-Linear的模型结构见下图,
图2 Log Bi-Linear模型结构
上图表示,每个词vi在词向量矩阵中找到对应的词向量表示,然后通过链接矩阵和当前词(图中v3)关联,其中关联关系是使用能量函数表示。
5.2 参数求解
套用RBM的求解框架,Log Bi-Linear可以采用Contrast Divergence Learning求解,其参数(Ci,R)的梯度表达式,
对于Ci,
∂∂CilogP(wn|w1:n−1)=<RTviR>D−<RTvivTnR>M(11)
对于R,
∂∂RlogP(wn|w1:n−1)=<∑i=1n=1(vnvTiRCi+vivTnRCTi)+vnbTr>D–<∑i=1n–1(vnvTiRCi+vivTnRCTi+vnbTr>M(12)
这里<.>D表示data distribution P^,<.>表示model distribution P。
6 Hierarchical LBL
Hinton将Bengio的Hierarchical NNLM和Log Bi-Linear思想结合,提出了Hierarchical Log Bi-Linear Language Model。
6.1 模型结构
Hierarchical LBL是将Hierarchical NNLM和Log Bi-Linear结合起来,对应的语言模型形式,
Log Bi-Linear部分可以简要表示为,
r^=∑i=t–1t−n+1Cirwi(13)
P(wt=w|wt−1:t−n+1)=exp(r^Trw+bw)∑jexp(r^Trj+bj)(14)
其中,b为对应的偏置项(bias),r^是上下文中的词向量加权,权值为当前词t和上下文中词的关系权值C,rw为词w对应的词向量。
由以上,可以推出HLBL的模型为,
P(wn|w1:n–1)=∏iP(di|qi,w1:n−1)(15)
P(di=1|qi,w1:n−1)=σ(r^Tqi+bi)(16)
其中,di词w的在层次(树)结构的编码,qi是编码路径中第i个节点的向量,σ为Logistic方程。
这里可以允许存在多种层次结构,即每个词对应多种编码,P(wn|w1:n–1)可以将词的所有编码方式求和,即
P(wn|w1:n–1)=∑d∈D(w)∏iP(di|qi,w1:n−1)(17)
其中,D(w)为词w的编码集合,这词采用多种编码方式能够更好刻画词的不同形式和“语义”,这种思路在后续的SENNA中也有体现。
6.2 参数求解
该模型参数求解可以直接套用Log Bi-Linear和Hierarchical NNLM的方式,其中不同之处,Hinton提出了一种新的简单的构建层次结构的方法:通过递归的使用二维的高斯混合模型(GMM,Gaussian Mixture Model)进行聚类,直到每个cluster中仅包含两个词,这样所有的结果就构成一个二叉树。
7 SENNA
SENNA中不仅仅提出了word embedding的构建方法,同时还从神经网络语言模型角度系统去解决自然语言处理任务(POS,Chunking,NER,SRL)。SENNA中,每个词可以直接从Lookup Table中直接查找到对应的向量。
LTW(w)=<W>1w(18)
其中,dwrd是词向量的维度,W∈Rdwrd×|D|为词向量的矩阵,<W>1w表示取矩阵W的第w列。SENNA中,表示句子或者词序列仅将对应的词向量拼接起来得到对应的向量。
SENNA中采用HLBL中同一个词存在不同的词向量,用于刻画不同的语义和语法用途,一个词的词向量最终由各种形态下的词向量组合起来,比如,一个词可以有word stemming的向量,本身的向量(这些向量可能来自不同的Lookup table)等,需要将这些向量结合起来表示这个词。SENNA直接将这些向量拼接起来,构成了一个维度为dTwrd=∑kdkwrd。
7.1 模型结构
SENNA包含两种网络构建方式(1)window approach(图3)(2)sentence approach(图4)。
(1)window approach
window approach是一个前馈神经网络,包含线性层、HardTanh层。window approach的输入是包含当前词在内的窗口大小ksz的序列,拼接所有词的向量得到的表示向量,维度dwrd×ksz,
图3 window approach
f1θ=<LTw([w]T1)>dwint=⎧⎩⎨⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪<W>1[w]t−dwin/2…<W>1[w]t…<W>1[w]t−dwin/2⎫⎭⎬⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪⎪(19)
从图3可知,f1θ输入下一层或者几层线性层,记为flθ。
flθ=Wlfl−1θ+bl(20)
其中,Wl∈Rnlhu×nl−1h,bl∈Rnlhu为待训练参数,nlhu为第l层隐藏单元数。
SENNA中包含了一个特殊的层,HardTanh层,它的输入是前一个线性层。HardTanh层是一个非线性层,形式如下,
[flθ]=HardTanh([fl−1θ]i)(21)
其中,
HardTanh(x)=⎧⎩⎨−1x1ifx≤ −1if−1≥x≤1ifx>1(22)
SENNA的输出层为输入序列对应的得分,大小具体任务有关。
(2) sentence approach
window approach能够完成绝大部分自然语言处理任务,但是在SRL上表现不佳。因此,SENNA提出了sentence approach用于适应SRL。sentence approach采用的卷积网络结构,除了线性层和HardTanh层外,还有一个卷积层和一个Max层。
<flθ>1t=Wl<fl−1θ>dwint+bl ∀t(23)
[flθ]i=maxt[fl−1θ]i,t1≤i≥nl−1hu(24)
7.2 参数估计
上述神经网络的参数均通过MLE + SGD得到,我们将参数记为θ,训练数据记为T, 则参数估计记为,
θ←∑(x,y)∈Tlogp(y|x,θ)(25)
其中,x为输入的句子或词序列(window approach)对应的表示向量,y表示具体任务(POS,NER,Chunking,SRL)的tag,p(.)为神经网络的输出结果,箭头右边为data log likelihood。
SENNA求解方式分为两种,word-level log-likelihood,sentence-level log-likelihood。
(1)word-level log-likelihood
在给定输入x的情况下,神经网络输出一个得分[fθ(x)]i,这里i为输出的tag编号。这个得分不满足概率的约束,需要对它进行归一化,这里采用了softmax方程,
p(i|x,θ)=e[fθ]i∑je[fθ]j(26)
为方便运算,对上述等式取log值,记分母部分为logaddj[fθ]j=log(∑je[fθ]j),得到的形式带入data log likelihood中,最终形式为交叉熵(cross entropy)。但是,由于在句子中当前词和相邻的词的tag存在关联性,上述方案并非最好的求解方式,所以SENNA提出了sentence-level log-likelihood。
(2)sentence-level log-likelihood
在输入的句子中,有些tag不能在某些tag之后。从序列的角度看,tag和tag之间的转换是有条件的,这种转换是需要满足约束的。记,[fθ]为句子[x]T1的网络输出得分,[fθ]i,t为输入序列中第t个词,输出为第i个tag的得分。基于上述考虑,SENNA引如一个转换矩阵[A]用于保存tag和tag之间的转换关系,[A]i,j表示从tag i到tag j的得分,转换得分需要通过从数据中训练得到,故参数为θ^=θ⋃{[A]i,j,∀i,j}。按照上述处理,序列的得分是神经网络得分加上转换得分,
s([x]T1,[i]T1,θ^)=∑t=1T([A][i]t−1,[i]t+[fθ][i]t,t)(27)
类似于word-level的处理,最终输出需要满足概率分布的约束,sentence level仅对所有可能的tag路径进行softmax归一化,我们定义这个结果比值为tag路径条件概率。对条件概率取log后,
logp([y]T1|[x]T1,θ^)=s([x]T1,[i]T1,θ^)–logadd∀[j]T1s([x]T1,[j]T1,θ^)(28)
上式中,logadd操作拥有特殊的性质可以递归的求解,可以方便的得到递推公式,
终止条件为,
logadds([x]T1,[f]T1,θ^)=logaddiδT(i)(29)
上述过程理解可以参照HMM的前向算法。在训练时,对所有的样本([x]T1,[y]T1)最大化data log likelihood,注意其中p(.)为tag路径条件概率。
SENNA的推断部分采用的是Viterbi算法,推断过程理解可以参照HMM的推断过程,形式为,
argmax[j]T1s([x]T1,[f]T1,θ^)(30)
类似于HMM中,也需要按照参数求解过程进行递归处理,但是每步需要用max操作替代logadd操作,然后回溯得到解。viterbi的过程理解可以参照动态规划问题,找出状态转移方程即可。
8 Eric Huang’s Model
在Bengio的神经网络结构的基础上,Eric Huang提出了引入文档的全局信息引神经网络语言模型,结构类似于Bengio的网络结构。
8.1 模型结构
相比Bengio的模型,Eric Huang引入了词的全局信息,在原本的网络结构中加入了子网络,形成如下图所示结构。
图5 Eric Huang的网络结构图
其中,score=scorel+scoreg,scorel代表局部的得分,scoreg代表全局的得分。scorel的计算公式为,
scorel=W2a1+b2(31)
a1=f(W1[x1;x2;...;xm]+b1)(32)
[x1;x2;...;xm]为当前词的Context中m个词向量的拼接,f为激活函数(逐个元素使用),比如tanh,W1,W2为对网络中的参数。
相应的,scorel的计算公式,
scoreg=W(g)2ag1+bg1(33)
ag1=f(Wg1[c;xm]+bg1)(34)
c=∑ki=1w(ti)di∑ki=1w(ti)(35)
其中,c为文章中包含的词向量的加权平均,权值公式可以有多种形式,Eric Huang采用IDF加权的方式。
8.2 参数求解
Eric Huang采用[C&W, 2007]中的求解方法,从词表中随机采样一个替换当前词,构造如下损失函数(类似于Ranking问题)
Cs,d=∑w∈Vmax(0,1–g(s,d)+g(sw,d))(36)
求解过程采用了min-batch L-BFGS。
9 word2vec
word2vec是word embedding中最为人知的模型,其原因(能想到的)有,(1)模型简单,训练速度快;(2)代码和数据开源,容易复现;(3)Google出品(作者在Google实习期间工作,但代码很难读)。
word2vec由Tim Mikolov的三篇论文引出(虽然有一篇是讲Recurrent NN),项目开源(https://code.google.com/p/word2vec/),训练速度快(单机跑缺省数据集,仅20+min)。word2vec代码中包含了两个模型CBOW(Continue BOW)和Skip-Gram。
9.1 CBOW
CBOW模型见下图,
类似于[Bengio, 2003]中的模型,CBOW的优化目标是:给定词序列w1,w2,w3,…,wT,最大化下式,
∑t=1TlogP(wt|wt−c,…wt−1.wt+1,…,wt+c)(37)
其中,P(wt|wt−c,…wt−1.wt+1,…,wt+c)采用log-linear(Softmax)模型用于正确分类当前词。在求解上式梯度时,每步的计算量与词表V大小成正比,十分耗时,需要借助其他方法近似求解。
9.2 Skip-Gram
Skip-Gram结构图见下图
Skip-Gram中优化的目标:给定词序列w1,w2,w3,…,wT,最大化下式,
1T∑t=1T∑−c≤j≤c,j≠0logP(wt+j|wt)(38)
其中,c是上下文的大小,P(wt+j|wt)采用softmax方程,
P(wO|wI)=exp(vTwOvwI)∑Vw=1exp(vTwOvwI)(39)
vw和vTw为对应的输入和输出词向量,上式中梯度(▽logP(wO|wI)的计算复杂度正比于词表V的大小,处理方法同CBOW。
9.3 参数求解
(1)Hierarchical Softmax
同Section 4中Hierarchical NNLM[Bengio, 2006],基于tf-idf构建Huffman树,简单快速。
(2)Noise Constractive Estimation
在section 4中提到了如何快速近似求解partition function的问题,Gutmann在AISTAT(理论的会议,如无基础误入,坑!)和ICANN上介绍一种新的近似求解方法-NCE,最终在JMLR上发表一篇长文来详细阐述其思想。此方法思想后续,本博客会撰文专门解释。
10 Glove
Glove(Global Vectors for word representation)由Jeffrey和Socher提出,并在word analogies,word similarity,NER任务中取得不错的效果。Glove融合了Globall Matrix Factorization和Local Context Window(见Section 11),提出了Log Bi-Linear的回归模型。从Glove的模型结构看,与神经网络结构存在不同,但是将其中F函数设置为神经网络结构,即二者等价。
10.1 模型结构
所有非监督的word representation学习算法均需要基于词的共现矩阵,然后经过复杂变换和分解得到对应的word representation。Glove直接构造一个词共现矩阵的近似矩阵(Context为固定长度),尽可能保存词之间的共现信息,如下图所示,
词表中三个词i,j,k,Pik表示词k出现在词i的context中的概率,同理,Pjk。以i=ice, j=steam, k=solid(solid语义上更靠近ice而不是steam),Glove的目标是极大比率PikPjk,参照Logistic Regression,其一般形式为,
F(wi,wj,w˜k)=PikPjk(40)
其中,w∈Rd是对应的词向量,w˜k∈Rd是context中词对应的向量。
由于F属于一个非常大的泛函空间,所以需要对F形式进行限制:
(1)F需要编码比率PikPjk中包含的信息,由于向量空间和线性结构的一致性,所以最直接的方法是F建模的是两个目标词向量的差值。
F(wi−wj,w˜k)=PikPjk(41)
(2)上式中,等式右边是一个标量。如果F拥有复杂的结构,这样和需要得到线性结构的冲突,故F变为如下形式,
F((wi–wj)Tw˜k)=PikPjk(42)
(3)Context的词k和目标词(i,j)可以任意交换,所以模型需要能适应如此变形。在F满足对称性下,其形式为
F((wi–wj)Tw˜k)=F(wTiw˜k)FTjw˜k(43)
结合,上述两式可以解得F=exp,即
wTiw˜k=log(Pik)=log(Xik)–log(Xi)(44)
对上式进行变形—将log(xi吸收到wi的偏置bi中,引入w˜k的偏置b˜k,
wTiw˜k+bi+b˜k=log(Xik)(45)
由于logx函数性质,需要对log(Xik)进行平滑,log(Xik)←log(1+Xik)
10.2 模型求解
依据上式,我们可以构造出对应的损失函数,由于词与词之间的共现关系不均衡,有部分共现关系不合理的(噪声)词会赋上极小的权重,不利于模型学习参数。所以,在构造函数时考虑引入一个权重方程f(Xij),
J=∑i,j=1Vf(Xij)(wTiw˜j+bi+b˜j–logXij)2(46)
其中,f(x)需要满足如下特性,
(1)f(0)=0,如果f(x)是一个连续函数,当x→0时,limx→0f(x)log2x是有限的。
(2)f(x)需要满足非递减的特性,如此,较少的出现的共现组合不会赋较大值。
(3)f(x)的函数值需要比较小,这样常见的共现组合也不会赋较大值
Glove中使用的权值方程,
f(x)=⎧⎩⎨(xxmax)α1ifx<xmaxotherwise(47)
通常xmax=100,α=3/4。
11 Recurrent Neural Network Language Model
在前馈神经网络语言模型建模过程中取得STOA(the STate Of Art)的效果后,Thomas Mikolov将Recurrent Neural Network引入,同样取得很好的效果。相比前馈神经网络,RNN能讲更多的上下文考虑到模型中来(FFNN仅能考虑窗口内的上下文),RRN的隐藏层能够囊括当前词的所有前序词(all previous words)。在序列数据中,RNN能够发现更多的词与词之间的pattern(与模型能够囊括更多的前序词有关)。
11.1 模型结构
在进行语言模型建模,一般采用简化版本的网络结构,此为时延神经网络(TDNN,Time Delay Neural Network),RNN的结构参照下图[Mikolov, 2013]
其中,输入层包括一个|V|维的向量w(t)和一个|H|维的向量s(t−1),|H|为隐藏层大小。网络训练结束后,输出层y(t)表示P(wt+1|wt,s(t–1))。
上述网络结构中,各个链接可以表示为
sj(t)=f(∑iwi(t)uji+∑jsl(t–1)wjl)(48)
yk(t)=g(∑jsj(t)vkj)(49)
其中,f(x)和g(x)为sigmoid和softmax激活函数。网络每步训练复杂度为O(H×(H+V))。
11.2 模型求解
由于RNN网络结构比较复杂,Backpropagation无法得到很好的训练结果,所以需要对传统Backpropagation进行改进,Mozer,Rumelhart,Robinson,Werbos等分别独立提出了BPTT(BackPropagation Through Time)用于训练RNN[Mozer, 1995][Rumelhart, 1986][Robinson, 1987][Werbos,1988]。
单隐藏层的RNN可以展开成一个多层的深度FFNN,隐藏层被使用N次,则可以展开为一个包含N个隐藏层的深度FFNN(见下图),深度的FFNN可以使用梯度下降方法学习得到参数。
图9 展开的RNN
按照上述结构,输出层的误差可以递归的往下传递,误差表达式为:
eh(t−τ–1)=dh(eh(t–τ)TW,t–τ–1)(50)
其中,d(.)对向量中元素逐个使用,
dhj(x,t)=xsj(t)(1–sj(t))(51)
如此,RNN中参数更新表达式为,
对于uij,
uij(t+1)=wij(t)+∑z=0Twi(t−z)ehj(t−z)α–uij(t)β(52)
对于wlj,
wlj(t+1)=wlj(t)+∑z=0Tsl(t−z−1)ehj(t−z)α–wlj(t)β(53)
其中,T为网络中被展开的步数(见上图)。
RNN用于Word Embedding学习的相关项目见:http://www.fit.vutbr.cz/~imikolov/rnnlm/
12 The Expressive Power of Word Embedding
这里列举两篇关于评测词向量的论文:Word Representation: Word representations :A simple and general method for semi-supervised learning[Turian et al., 2010],The Expressive Power of Word Embeddings[Yanqing Chen et al., 2013]。
在Word Representation一文中,将Word Representation分为三类,(1)Distributional Representation;(2)Clustering-based word representation;(3)Distributed Representation。
Distributional Representation是基于共现矩阵FW×C,其中W为词表大小,C为Context大小,矩阵中每行为一个词的表示向量,每一列为某些Context内容。构造矩阵F有许多的方案和技巧,比如context的构建(左边 or 右边的Context窗口内容,Context窗口大小等)。同时,基于现有的共现矩阵,可以采用一些降维方法压缩词的表示,比如LSA中的SVD + Low Rank Approximation等。
Clustering-based word Representation是进行Distributional Representation中的共现矩阵“变换”成一个个聚类。常见的模型有:brown clustering,HMM-LDA based POS and word segmentation等。
Distributed Representation在Section 3.1中已经讲到,现有的词向量表示都可以归到此类中,这类模型到现在已经提出了好几十种,主要是Feed Forward Neural Network based和Recurrent Neural Network based两大类。
在评测中包含有监督的评测任务:Chunking和NER,主要针对Brown Clustering和C&W,实验结果如下图:
从上图中可以看出,Brown Clustering比C&W要优,但是Brown Clustering的训练耗时要比SENNA和其他词向量要高得多。
以上实验,读者可以自行复现,参考网址:http://metaoptimize.com/ projects/wordreprs/
Yanqing Chen在ICML-13上发表一篇评测现有Word Embedding的表达能力的论文,文中提到了四种公开发布的Word Embedding(HLBL,SENNA, Turian’s, Eric Huang’s)。文中基于的评测任务有(1)Sentiment:情感分析(两类情感);(2)Noun Gender:人名性别识别(Noun Gender);(3)Plurality:复数(英文)形式判定;(3)Synonyms and Antonyms:同义词反义词判定;(4)Regional Spellings:不同语种形式判定(UK vs. U.S.A.)
表4 评价任务示例
从上表中可以看出,每个任务可以描述为一个二分类问题,现在需要考虑的是如何构建分类的特征。
词向量数据集:SENNA(130,000 words × 50 dimension)、Turian’s(268,810 words × 25or50or100 dimension)、HLBL(246,122 words × 50 or 100 dimensions)、Huang‘s(100,232 words × 50 dimensions)
评测中采用了线性和非线性两类分类器,分别为Logistic Regression和SVM with RBF kernel。
图10 基于Term的任务评测结果,阴影区域为使用SVM with kernel得到的提升
从上述几个任务的结果图中,可以明显看出Eric Huang’s和SENNA有明显的优势。从总体来看,对比原有Baseline均有提升,可见词向量一定程度上符合语言的表述,但此文中没有将word2vec、Glove等后起之秀考虑在内,无法客观的评价词向量技术哪家强。