语音识别——基于深度学习的中文语音识别系统框架
本文搭建一个完整的中文语音识别系统,包括声学模型和语言模型,能够将输入的音频信号识别为汉字。
该系统实现了基于深度框架的语音识别中的声学模型和语言模型建模,其中声学模型包括CNN-CTC、GRU-CTC、CNN-RNN-CTC,语言模型包含transformer、CBHG。
数据集采用了目前能找到的所有中文免费数据,包括:thchs-30、aishell、primewords、st-cmd四个数据集,训练集总计大约450个小时。
项目地址:https://github.com/audier/DeepSpeechRecognition
为了方便同学们自己做实验,写了实践版的tutorial:
- 声学模型:https://blog.csdn.net/chinatelecom08/article/details/85013535
- 基于transformer的语言模型:https://blog.csdn.net/chinatelecom08/article/details/85051817
- 基于CBHG的语言模型:https://blog.csdn.net/chinatelecom08/article/details/85048019
文章目录
1. 声学模型
GRU-CTC
DFCNN
DFSMN
2. 语言模型
n-gram
CBHG
transformer
3. 数据集
4. 配置
1. 声学模型
声学模型目前开源了部分示例模型,后期将不定期更新一些模型。
GRU-CTC
我们使用 GRU-CTC的结构搭建了第一个声学模型,该模型在项目的gru_ctc.py文件中。
利用循环神经网络可以利用语音上下文相关的信息,得到更加准确地信息,而GUR又能选择性的保留需要的长时信息,使用双向rnn又能够充分的利用上下文信号。
但该方法缺点是一句话说完之后才能进行识别,且训练相对cnn较慢。该模型使用python/keras进行搭建,本文系统都使用python搭建。
网络结构如下:
def _model_init(self):
self.inputs = Input(name='the_inputs', shape=(None, 200, 1))
x = Reshape((-1, 200))(self.inputs)
x = dense(512, x)
x = dense(512, x)
x = bi_gru(512, x)
x = bi_gru(512, x)
x = bi_gru(512, x)
x = dense(512, x)
self.outputs = dense(self.vocab_size, x, activation='softmax')
self.model = Model(inputs=self.inputs, outputs=self.outputs)
self.model.summary()
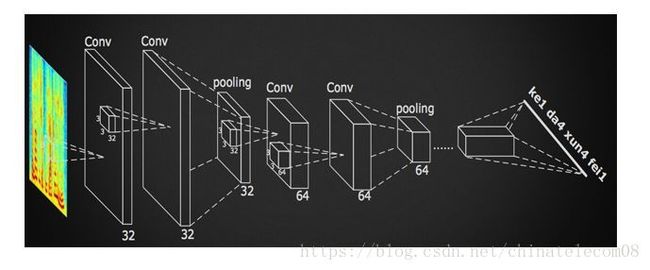
DFCNN
由于两个原因在使用GRU作为语音识别的时候我们会遇到问题。
- 一方面是我们常常使用双向循环神经网络才能取得更好的识别效果,这样会影响解码实时性。
- 另一方面随着网络结构复杂性增加,双向GRU的参数是相同节点数全连接层的6倍,这样会导致训练速度非常缓慢。
科大讯飞提出了一种使用深度卷积神经网络来对时频图进行识别的方法,就是DFCNN。
论文地址:http://xueshu.baidu.com/usercenter/paper/show?paperid=be5348048dd263aced0f2bdc75a535e8&site=xueshu_se
利用CNN参数共享机制,可以将参数数量下降几个数量级别,且深层次的卷积和池化层能够充分考虑语音信号的上下文信息,且可以在较短的时间内就可以得到识别结果,具有较好的实时性。
该模型在cnn_ctc.py中,实验中是所有网络结果最好的模型,目前能够取得较好的泛化能力。其网络结构如下:
def cnn_cell(size, x, pool=True):
x = norm(conv2d(size)(x))
x = norm(conv2d(size)(x))
if pool:
x = maxpool(x)
return x
class Am():
def _model_init(self):
self.inputs = Input(name='the_inputs', shape=(None, 200, 1))
self.h1 = cnn_cell(32, self.inputs)
self.h2 = cnn_cell(64, self.h1)
self.h3 = cnn_cell(128, self.h2)
self.h4 = cnn_cell(128, self.h3, pool=False)
self.h5 = cnn_cell(128, self.h4, pool=False)
# 200 / 8 * 128 = 3200
self.h6 = Reshape((-1, 3200))(self.h5)
self.h7 = dense(256)(self.h6)
self.outputs = dense(self.vocab_size, activation='softmax')(self.h7)
self.model = Model(inputs=self.inputs, outputs=self.outputs)
self.model.summary()
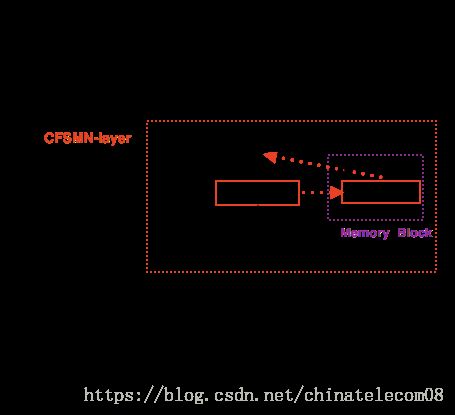
DFSMN
而前馈记忆神经网络也也解决了双向GRU的参数过多和实时性较差的缺点,它利用一个记忆模块,包含了上下几帧信息,能够得到不输于双向GRU-CTC的识别结果,阿里最新的开源系统就是基于DFSMN的声学模型,只不过在kaldi的框架上实现的。我们将考虑使用DFSMN+CTC的结构在python上实现。该网络实质上是用一个特殊的CNN就可以取得相同的效果,我们将CNN的宽设置为memory size,将高度设置为feature dim,将channel设置为hidden units,这样一个cnn的层就可以模仿fsmn的实现了。
结构如下:
2. 语言模型
n-gram
n元语法是一个非常经典的语言模型,这里不过多介绍啦。
如果想要通过语料来训练一个n-gram的模型,可以参考我的小实验的实现方法。
CBHG
该想法来自于一个大神搞输入法的项目,下面部分也引用此处:搜喵出入法
他是利用该模型建立一个按键到汉字的作用,本文对其结构和数据处理部分稍作改动,作为语言模型。
拼音输入的本质上就是一个序列到序列的模型:输入拼音序列,输出汉字序列。所以天然适合用在诸如机器翻译的seq2seq模型上。
模型初始输入是一个随机采样的拼音字母的character embedding,经过一个CBHG的模型,输出是五千个汉字对应的label。
这里使用的CBHG模块是state-of-art的seq2seq模型,用在Google的机器翻译和语音合成中,该模型放在cbhg.py中,结构如下:
图片来自 Tacotron: Towards End-to-End Speech Synthesis

该模型训练实验结果如下,实际上,后续和transformer的比较中,该模型无论是收敛速度还是识别效果上都是很难和transformer比较。
请输入测试拼音:ta1 mei2 you3 duo1 shao3 hao2 yan2 zhuang4 yu3 dan4 ta1 que4 ba3 ai4 qin1 ren2 ai4 jia1 ting2 ai4 zu3 guo2 ai4 jun1 dui4 wan2 mei3 de tong3 yi1 le qi3 lai2
她没有多少豪言壮语但她却把爱亲人爱家庭爱祖国爱军队完美地统一了起来
请输入测试拼音:chu2 cai2 zheng4 bo1 gei3 liang3 qian1 san1 bai3 wan4 yuan2 jiao4 yu4 zi1 jin1 wai4 hai2 bo1 chu1 zhuan1 kuan3 si4 qian1 wu3 bai3 qi1 shi2 wan4 yuan2 xin1 jian4 zhong1 xiao3 xue2
除财政拨给两千三百万元教太资金外还拨出专款四千五百七十万元新建中小学
请输入测试拼音:ke3 shi4 chang2 chang2 you3 ren2 gao4 su4 yao2 xian1 sheng1 shuo1 kan4 jian4 er4 xiao3 jie3 zai4 ka1 fei1 guan3 li3 he2 wang2 jun4 ye4 wo4 zhe shou3 yi1 zuo4 zuo4 shang4 ji3 ge4 zhong1 tou2
可是常常有人告诉姚先生说看见二小姐在咖啡馆里和王俊业握着族一坐坐上几个钟头
transformer
新增基于transformer结构的语言模型transformer.py,该模型已经被证明有强于其他框架的语言表达能力。
- 论文地址:https://arxiv.org/abs/1706.03762。
- tutorial:https://blog.csdn.net/chinatelecom08/article/details/85051817
建议使用transformer作为语言模型,该模型是自然语言处理这两年最火的模型,今年的bert就是使用的该结构。本文最近更新系统使用的语言模型就是transformer。
the 0 th example.
文本结果: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
原文结果: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
原文汉字: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
识别结果: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
the 1 th example.
文本结果: ta1 jin3 ping2 yao1 bu4 de li4 liang4 zai4 yong3 dao4 shang4 xia4 fan1 teng2 yong3 dong4 she2 xing2 zhuang4 ru2 hai3 tun2 yi4 zhi2 yi3 yi1 tou2 de you1 shi4 ling3 xian1
原文结果: ta1 jin3 ping2 yao1 bu4 de li4 liang4 zai4 yong3 dao4 shang4 xia4 fan1 teng2 yong3 dong4 she2 xing2 zhuang4 ru2 hai3 tun2 yi4 zhi2 yi3 yi1 tou2 de you1 shi4 ling3 xian1
原文汉字: 他仅凭腰部的力量在泳道上下翻腾蛹动蛇行状如海豚一直以一头的优势领先
识别结果: 他仅凭腰部的力量在泳道上下翻腾蛹动蛇行状如海豚一直以一头的优势领先
the 2 th example.
文本结果: pao4 yan3 da3 hao3 le zha4 yao4 zen3 me zhuang1 yue4 zheng4 cai2 yao3 le yao3 ya2 shu1 di4 tuo1 qu4 yi1 fu2 guang1 bang3 zi chong1 jin4 le shui3 cuan4 dong4
原文结果: pao4 yan3 da3 hao3 le zha4 yao4 zen3 me zhuang1 yue4 zheng4 cai2 yao3 le yao3 ya2 shu1 di4 tuo1 qu4 yi1 fu2 guang1 bang3 zi chong1 jin4 le shui3 cuan4 dong4
原文汉字: 炮眼打好了炸药怎么装岳正才咬了咬牙倏地脱去衣服光膀子冲进了水窜洞
识别结果: 炮眼打好了炸药怎么装岳正才咬了咬牙倏地脱去衣服光膀子冲进了水窜洞
3. 数据集
数据集采用了目前我能找到的所有中文免费数据,包括:thchs-30、aishell、primewords、st-cmd四个数据集,训练集总计大约450个小时,在之前实验过程中,使用thchs-30+aishell+st-cmd数据集对DFCNN声学模型进行训练,以64batch_size训练。
包括stc、primewords、Aishell、thchs30四个数据集,共计约430小时, 相关链接:http://www.openslr.org/resources.php
Name train dev test
aishell 120098 14326 7176
primewords 40783 5046 5073
thchs-30 10000 893 2495
st-cmd 10000 600 2000
数据标签整理在data路径下,其中primewords、st-cmd目前未区分训练集测试集。
若需要使用所有数据集,只需解压到统一路径下,然后设置utils.py中datapath的路径即可。
4. 配置
本项目现已训练一个迷你的语音识别系统,将项目下载到本地上,下载thchs数据集并解压至data,运行test.py,不出意外能够进行识别,结果如下:
the 0 th example.
文本结果: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
原文结果: lv4 shi4 yang2 chun1 yan1 jing3 da4 kuai4 wen2 zhang1 de di3 se4 si4 yue4 de lin2 luan2 geng4 shi4 lv4 de2 xian1 huo2 xiu4 mei4 shi1 yi4 ang4 ran2
原文汉字: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
识别结果: 绿是阳春烟景大块文章的底色四月的林峦更是绿得鲜活秀媚诗意盎然
若自己建立模型则需要删除现有模型,重新配置参数训练。
与数据相关参数在utils.py中:
data_type: train, test, dev
data_path: 对应解压数据的路径
thchs30, aishell, prime, stcmd: 是否使用该数据集
batch_size: batch_size
data_length: 我自己做实验时写小一些看效果用的,正常使用设为None即可
shuffle:正常训练设为True,是否打乱训练顺序
def data_hparams():
params = tf.contrib.training.HParams(
# vocab
data_type = 'train',
data_path = 'data/',
thchs30 = True,
aishell = True,
prime = False,
stcmd = False,
batch_size = 1,
data_length = None,
shuffle = False)
return params
使用train.py文件进行模型的训练。
声学模型可选cnn-ctc、gru-ctc,只需修改导入路径即可:
from model_speech.cnn_ctc import Am, am_hparams
from model_speech.gru_ctc import Am, am_hparams
语言模型可选transformer和cbhg:
from model_language.transformer import Lm, lm_hparams
from model_language.cbhg import Lm, lm_hparams
————————————————
版权声明:本文为CSDN博主「Audior」的原创文章,遵循 CC 4.0 BY-SA 版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/chinatelecom08/article/details/82557715