keras之父《python深度学习》笔记 第三章
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 前言
- 一、神经网络剖析
-
- 1.层:神经网络的基础单元
- 2.模型:由层构成的网络
- 3.损失函数优化器:学习过程的关键
- 二、keras介绍
-
- 1.keras特性
- 2.keras安装
- 三、用keras解决一个二分类问题
-
- 1.IMDB数据集介绍
- 2.数据预处理
- 3.模型定义
- 4.训练和验证过程
- 5.在测试集上预测结果
- 四、用keras解决一个多分类问题
-
- 1.路透社数据集
- 2.数据预处理
- 3.构建模型训练
- 五、keras解决回归问题
-
- 1.波士顿房价数据集
- 2.数据预处理
- 3.模型搭建训练
- 4.训练最终模型
- 总结
前言
本节介绍安装tensorflow和keras的过程,在配置好环境之后运行三个代码,分别解决二分类问题,多分类问题和回归问题,通过这一章内容能够对深度学习有更好的认识。
提示:以下是本篇文章正文内容,下面案例可供参考
一、神经网络剖析
训练神经网络一般是围绕以下四个方面
层 多个层堆叠组合在一起组合成了神经网络
输入数据和相应的目标数据是决定上限的关键,优化算法只能不断逼近这个上限
损失函数 损失值反向传播来优化权重
优化器决定神经网络的学习过程如何进行。
1.层:神经网络的基础单元
神经网络的基础结构就是层,层是一个数据处理模块,负责把输入张量转换为输出张量。层是有状态的,这个状态被称为权重。权重就是网络对于输入张量处理的参数,也可以认为是层通过学习得到的知识。
不同的张量格式需要不同的层,比如最简单的(samples,features)这种2D张量,通常用全连接层来处理。形状为(samples,timesteps,features)的3D序列张量,通常用循环层来处理(比如RNN及其改良版LSTM及GRU)。图像数据保存在4D张量中,通常用二维卷积层来处理。
用keras构建深度学习网络就跟搭积木一样简单,将多个相互兼容的层拼接在一起,建立起有用的数据变换流程。兼容的意思是每一层都只接受特定形状的输入张量,并返回特定形状的输出张量。
from keras import layers
layer = layers.Dense(32, input_shape=(784,))
我们创建的这个层,只接受维度大小为784的2d张量输入(0轴为批量维度,大小没有指定,因此可以任意取值)作为输入。而输出的张量的维度大小为32。数据经过这一层之后,之后衔接的层只能接受32维向量作为输入层。在keras当中可以很方便的做到这一点,因为keras中模型田间的层都会自动匹配输入层的形状,无需开发人员再去设置,比如下面的demo:
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(32, input_shape=(784,)))
model.add(layers.Dense(32))
其中第二层没有像第一层那样规定输入参数的形状。但是keras会自动计算出它的输入形状就是上一层的输出形状。
2.模型:由层构成的网络
深度学习最基本的模型就是层的线性堆叠,将单一输入映射为单一输出。但是在长期的实践和研究中,人们发现其他形式更为复杂的神经网络在解决问题是有更好的效果。一些常见的网络拓扑结构如下
双分支网络
多头网络
inception模块
现在有一些最佳实践和原则来指导大家如何选择神经网络的拓扑结构,但是由于神经网络的复杂性太高,所以要找到真正合适的神经网络模型还是需要大量的动手实验。本书会带大家搭建一些神经网络希望读者能够有初步的认知,明白对于特定的问题,哪些架构更有效。
3.损失函数优化器:学习过程的关键
确定了网络结构之后,损失函数和优化器的选择决定了学习过程
损失函数:训练过程中追求的就是损失函数结果的最小化,损失函数值决定了当前训练任务的结果是否达到我们的要求。
优化器:决定了如何根据损失函数值来对网络进行更新。常用的优化器一般是随机梯度下降及其变体。
对于常见的分类回归序列预测问题,有一些常用的损失函数可以满足需求:比如二分类问题的二元交叉熵损失函数;多分类问题常用的分类交叉熵损失函数;回归问题可以用均方误差损失函数;序列学习问题可以用联结主义时序分类损失函数。而对于一般的深度学习来说,随机梯度下降的优化器就能满足需求。
神经网络的优势在于即使用基础的模型。基础的损失函数和优化器,在常见问题上也能获得很好的效果。如果想要进一步提高效果,可以尝试复杂的损失函数和优化器,目前这个领域的研究还是很多的,可以参照研究成果尝试。
二、keras介绍
1.keras特性
本书中代码示例都是用keras实现的,keras最开始是为了研究人员能够快速开发并实验而设计的,所以对于初学者很友好,效率够高。
keras是一个模型级别的库,不提供张量操作,求微分这些底层的运算。keras把这些操作放到依赖的其他框架中处理,这些被依赖的框架被称为后端。keras支持多种后端,诸如tensorflow、CNTK、Theano。通过这些后端,keras的代码可以在gpu和cpu环境中运行。
tensorflow是目前最常见的keras后端,笔者就是用tensorflow作为后端来运行。在运行时会有如下提示:
![]()
2.keras安装
很奇怪原书中没有涉及到keras的安装教程。对于初学者来说,这些东西还是很重要的。笔者在windows环境下搭建的学习环境。首先是安装python3.7,然后安装keras2.3.1,最后安装tensorflow2.2.0
pip install keras==2.3.1
pip install tensorflow==2.2.0
python的安装相关教程有很多。keras和tensorflow安装时版本要对应(在新版的tensorflow中集成了keras,放到tensorflow.keras模块中,从而解决了版本兼容问题。鉴于本文还是基于keras开发的demo,还是推荐大家按照指定的版本来安装框架)。
三、用keras解决一个二分类问题
二分类问题可能是最广泛的机器学习问题,这个世界上划分为二分类的问题无处不在,计算机最常用的二进制给人感觉也是一个二分类做成的机器。
1.IMDB数据集介绍
IMDB数据集来自于互联网电影数据库(缩写为IMDB),这个数据集是一个5w条的两极分化的评论。训练集合测试集都有2w5的数据,而且都是1:1的正面评论和负面评论,是做二分类问题很好用的数据集。
和mnist数据集一样,IMDB数据集也内置在keras库中,而且经过了预处理,将评论的单词转换为整数序列,这个序列可以根据字典来映射成原始评论。通过下面的代码,我们可以很方便的获取到这个数据集(下载可能消耗一些时间,该数据集大小约为80MB)
from keras.datasets import imdb
(train_data, train_labels), (test_data, test_labels) = imdb.load_data(
num_words=10000)
参数num_words=10000的意思为保留数据集中最常用的1w个单词。在自然语言处理中经常有这样的操作,目的是舍去一部分低频单词,实践证明这种操作会解约训练资源,对于训练精度没有太大影响。
train_data 和test_data 这两个变量都是评论组成的列表,每条评论又是单词索引组成
的列表(表示一系列单词)。train_labels 和test_labels 都是0 和1 组成的列表,其中0代表负面(negative),1 代表正面(positive)。
2.数据预处理
在实际的业务当中,拿到的数据想要转换为训练模型的数据是一个重要而且复杂的过程。在demo中也有一些数据预处理过程,把我们拿到的数据转换为模型训练所需要的数据。
我们要把拿到的模型数据由列表转换为张量,这里采用的是one-hot处理,这是一种基础的数据处理方式。比如序列[3,5],将会转换为10000维向量(因为我们限制了前1w个常用单词,所以onehot之后是1w维向量),只有索引3和5的元素为1,其余元素都是0.记过这样的转换之后,我们在网络第一次采用Dense层可以处理这样的数据。
具体的onehot代码如下:
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
3.模型定义
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(16, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(16, activation='relu'))
model.add(layers.Dense(1, activation='sigmoid'))
在这个模型中,我们用到了带relu的激活函数层。普通的全连接层相当于给输入张量做矩阵运算,然而多个矩阵运算实质上可以变性为一个矩阵运算。所以只堆叠全连接层是没有意义的。而加上relu层之后的运算变成了
output = relu(dot(W, input) + b)
sigmoid是另一个激活函数,这个函数可以将输出值压缩到[0,1]的范围内。
在定义玩模型之后,我们下一步就是确定编译的参数。主要是优化器损失函数和监控量。二分类问题用交叉熵做损失函数是基本的思路。
model.compile(optimizer='rmsprop',
loss='binary_crossentropy',
metrics=['accuracy'])
当然读者也可以尝试用其他的编译参数,比如这种:
from keras import losses
from keras import metrics
model.compile(optimizer=optimizers.RMSprop(lr=0.001),
loss=losses.binary_crossentropy,
metrics=[metrics.binary_accuracy])
这本书是比较基础的入门书籍,只是带领大家了解深度学习的基本知识,不需要把结果做到最优(做到最优一般是各种比赛要做到的结果)
4.训练和验证过程
x_val = x_train[:10000]
partial_x_train = x_train[10000:]
y_val = y_train[:10000]
partial_y_train = y_train[10000:]
训练集中我们留出1w个样本用来做验证,这些样本不参与训练。因为深度学习算法通常包含大量参数,很容易出现过拟合(过拟合的概念以后会讲到),用不参与训练的样本来验证模型的精度,可以发现模型是否有过拟合现象,如果出现的话需要调整训练参数。
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
这里我们用512个样本组成一小批量进行训练,一共训练20个轮次(把样本中所有样本进行20次迭代)。训练的时候会返回一个History对象,这个对象有一个成员history,这个成员是一个字典结构,里面有训练过程中的参数,我们可以运行以下代码看到history成员的数据结构。
history_dict = history.history
history_dict.keys()
可以看到输出结果为
dict_keys([‘val_acc’, ‘acc’, ‘val_loss’, ‘loss’])
得益于python中强大的各种功能包,我们可以很方便的将训练过程的参数可视化,可视化之后能将各种参数展示的更加清楚。
首先执行命令
python -m pip install matplotlib
引入matplotlib包,然后调用这个包的工具将训练参数可视化展示
import matplotlib.pyplot as plt
history_dict = history.history
loss_values = history_dict['loss']
val_loss_values = history_dict['val_loss']
epochs = range(1, len(loss_values) + 1)
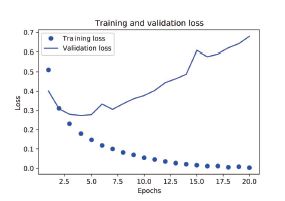
plt.plot(epochs, loss_values, 'bo', label='Training loss')
plt.plot(epochs, val_loss_values, 'b', label='Validation loss')
plt.title('Training and validation loss')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()

plt.clf()
acc = history_dict['acc']
val_acc = history_dict['val_acc']
plt.plot(epochs, acc, 'bo', label='Training acc')
plt.plot(epochs, val_acc, 'b', label='Validation acc')
plt.title('Training and validation accuracy')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
5.在测试集上预测结果
print(model.predict(x_test))
array([[ 0.98006207]
[ 0.99758697]
[ 0.99975556]
…,
[ 0.82167041]
[ 0.02885115]
[ 0.65371346]], dtype=float32)
可以看到预测结果实质上是一个概率。神经网络对某些样本的结果有很高的把握(大于0.99,下雨0.03),有一些结果并不是那么确信(0.6或0.4)
四、用keras解决一个多分类问题
1.路透社数据集
上一节我们用keras解决了一个二分类问题,这节我们用keras解决一个多分类问题。路透社数据集是多分类常用的一个入门数据集,它包含很多短新闻及其对应的主体。一共有46个不同的主题,每个主题至少有10个样本。keras当中也内置了这个数据集,我们可以很方便的导入这个数据集。
from keras.datasets import reuters
(train_data, train_labels), (test_data, test_labels) = reuters.load_data(
num_words=10000)
和对上一个数据集的处理方式一样,这个数据集我们也是只去了前1w个最常见的单词。一共有8982个训练样本和2246个测试样本。这些样本也是经过处理,每个样本都是一个整数列表。
2.数据预处理
和上个项目一样,拿到数据之后要做预处理来方便进行训练。
将数据向量化
import numpy as np
def vectorize_sequences(sequences, dimension=10000):
results = np.zeros((len(sequences), dimension))
for i, sequence in enumerate(sequences):
results[i, sequence] = 1.
return results
x_train = vectorize_sequences(train_data)
x_test = vectorize_sequences(test_data)
将标签向量化
def to_one_hot(labels, dimension=46):
results = np.zeros((len(labels), dimension))
for i, label in enumerate(labels):
results[i, label] = 1.
return results
one_hot_train_labels = to_one_hot(train_labels)
one_hot_test_labels = to_one_hot(test_labels)
这里写了向量化的全过程,其实keras内部封装了这个方法,这里写出来是为了让读者更好的理解详细过程,实际上调用keras可以很方便的实现标签向量化:
from keras.utils.np_utils import to_categorical
one_hot_train_labels = to_categorical(train_labels)
one_hot_test_labels = to_categorical(test_labels)
3.构建模型训练
剩下的过程和二分类问题大致相同。需要注意的是,由于一共有46个分类,所以中间层最好要大于46维,尽量保留足够多的信息,不然维度较小的层可能成为信息瓶颈,永久的丢失相关信息。
from keras import models
from keras import layers
model = models.Sequential()
model.add(layers.Dense(64, activation='relu', input_shape=(10000,)))
model.add(layers.Dense(64, activation='relu'))
#读者也可以尝试一下,将中间层替换为较少的维度,看看会不会出现信息丢失导致精度下降的现象。
#model.add(layers.Dense(4, activation='relu'))
model.add(layers.Dense(46, activation='softmax'))
model.compile(optimizer='rmsprop',
loss='categorical_crossentropy',
metrics=['accuracy'])
x_val = x_train[:1000]
partial_x_train = x_train[1000:]
y_val = one_hot_train_labels[:1000]
partial_y_train = one_hot_train_labels[1000:]
history = model.fit(partial_x_train,
partial_y_train,
epochs=20,
batch_size=512,
validation_data=(x_val, y_val))
五、keras解决回归问题
前面都是用keras来解决分类问题,另一类常见问题是回归问题。预测的不是连续值而不是离散的标签,比如根据气象数据来预测明天的气温。
1.波士顿房价数据集
本节将要预测20 世纪70 年代中期波士顿郊区房屋价格的中位数,已知当时郊区的一些数据点,比如犯罪率、当地房产税率等。本节用到的数据集与前面两个例子有一个有趣的区别。它包含的数据点相对较少,只有506 个,分为404 个训练样本和102 个测试样本。输入数据的每个特征(比如犯罪率)都有不同的取值范围。例如,有些特性是比例,取值范围为01;有的取值范围为112;还有的取值范围为0~100,等等。
我们可以从keras中加载得到这个数据集。
from keras.datasets import boston_housing
(train_data, train_targets), (test_data, test_targets) = boston_housing.load_data()
查看一下数据的分布
>>> train_data.shape
(404, 13)
>>> test_data.shape
(102, 13)
如你所见,我们有404 个训练样本和102 个测试样本,每个样本都有13 个数值特征,比如
人均犯罪率、每个住宅的平均房间数、高速公路可达性等。
目标是房屋价格的中位数,单位是千美元。
>>> train_targets
array([ 15.2, 42.3, 50. ... 19.4, 19.4, 29.1])
2.数据预处理
这个数据的预处理比起之前的要复杂一些,因为数据之前范围不同,需要用numpy中的标准化功能处理一下。
mean = train_data.mean(axis=0)
train_data -= mean
std = train_data.std(axis=0)
train_data /= std
test_data -= mean
test_data /= std
由于数据集比较小,我们要用到k折验证。k折验证就是将数据划分为k个分区,每个模型在k-1个分区上训练,剩下一个分区进行评估。
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
3.模型搭建训练
from keras import models
from keras import layers
def build_model():
model = models.Sequential()
model.add(layers.Dense(64, activation='relu',
input_shape=(train_data.shape[1],)))
model.add(layers.Dense(64, activation='relu'))
model.add(layers.Dense(1))
model.compile(optimizer='rmsprop', loss='mse', metrics=['mae'])
return model
import numpy as np
k = 4
num_val_samples = len(train_data) // k
num_epochs = 100
all_scores = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
model.fit(partial_train_data, partial_train_targets,
epochs=num_epochs, batch_size=1, verbose=0)
val_mse, val_mae = model.evaluate(val_data, val_targets, verbose=0)
all_scores.append(val_mae))
设置num_epochs = 100,运行结果如下。
all_scores
[2.588258957792037, 3.1289568449719116, 3.1856116051248984, 3.0763342615401386]np.mean(all_scores)
2.9947904173572462
每次运行模型得到的验证分数有很大差异,从2.6 到3.2 不等。平均分数(3.0)是比单一
分数更可靠的指标——这就是K 折交叉验证的关键。在这个例子中,预测的房价与实际价格平
均相差3000 美元,考虑到实际价格范围在10 000~50 000 美元,这一差别还是很大的。
我们让训练时间更长一点,达到500 个轮次。为了记录模型在每轮的表现,我们需要修改
训练循环,以保存每轮的验证分数记录。
num_epochs = 500
all_mae_histories = []
for i in range(k):
print('processing fold #', i)
val_data = train_data[i * num_val_samples: (i + 1) * num_val_samples]
val_targets = train_targets[i * num_val_samples: (i + 1) * num_val_samples]
partial_train_data = np.concatenate(
[train_data[:i * num_val_samples],
train_data[(i + 1) * num_val_samples:]],
axis=0)
partial_train_targets = np.concatenate(
[train_targets[:i * num_val_samples],
train_targets[(i + 1) * num_val_samples:]],
axis=0)
model = build_model()
history = model.fit(partial_train_data, partial_train_targets,
validation_data=(val_data, val_targets),
epochs=num_epochs, batch_size=1, verbose=0)
mae_history = history.history['val_mean_absolute_error']
all_mae_histories.append(mae_history)
4.训练最终模型
model = build_model()
model.fit(train_data, train_targets,
epochs=80, batch_size=16, verbose=0)
test_mse_score, test_mae_score = model.evaluate(test_data, test_targets)
最终结果如下。
>>> test_mae_score
2.5532484335057877
你预测的房价还是和实际价格相差约2550 美元。
总结
通过以上的理论和例子,可以熟悉深度学习的大致流程和用keras来进行二分类、多分类以及回归问题的的解决方案。