本文系作者GOPS全球运维大会演讲内容,由高效运维社区整理。
本次主题主要会包括两个方面,首先面对云原生技术的快速发展和落地,传统运维体系应该怎么去构建及过程中遇到的冲击和挑战,会有一个简单的分析。
其次,在面对不同的挑战时我们做了哪些事情,我会根据内部实践来做一些分享,希望能给大家一些参考。
对于运维来说,其实就是效率、稳定性、成本。其实,不管是稳定性,还是提升运维效率都是为了钱:效率提升了能减少人力成本,稳定性保障/监控报警做得好,可以少故障少赔钱。对于运维来说,当然还有一个非常重要的是安全,不过今天我们不会怎么讲安全。
在正式开始之前,我先简单介绍一下网易这边的技术情况。网易内部的各个BU之间的技术栈往往是有很大差异的,比如游戏、音乐、严选等,基本上可以认为是完全不同行业的,都有自己的特色以及行业背景,这导致在网易建设大一统的平台不太现实,所以我们更关注一些更细微的点。
1. 运维的新挑战
新技术栈
网易数帆部门大概从 Kubernetes 1.0 发布时就开始接触容器了,大规模使用容器是在18年前后。业务使用容器后面临的首个挑战是全新的技术栈,这个时候运维体系该如何规划?相关的技术选型,包括网络/存储方案的选择,集群规模容量规划,往往因为前面的短视造成后面的很多窘破。
容器化的场景下,对于 Kubernetes 的使用上,我们没有对业务部门做任何限制,业务部门可以任意调用 Kubernetes API。因为使用模式多样,导致运维保障面临更多挑战。很多由于业务的误用导致的问题,一样需要运维保障来兜底。
早期基础设施(包括Docker/内核/Kubernetes)一直Bug不断,比如,Docker 18年前很多的经典Bug,我们都遇到过。不过这两年比较新的版本问题已经少了很多了。
我们部门使用的主流操作系统发行版是debian,可能跟在座各位同仁绝大部分使用centos的不太一样。Debian发行版的好处是内核以及软件版本都相对较新。所有遇到的内核问题,也是需要我们自己去处理修复。
另外,容器化刚开始的时候,毕竟是新的技术栈,想招到匹配岗位的人才较困难,人力成本比较高。
技术惯性
技术惯性大家比较能理解,很多公司都有自己的传统的运维平台。从传统的运维平台到转变使用 Kubernetes 来做发布管理,从思想上,操作方式上,实现方式上多个方面,我们发现中间有很多鸿沟,弥合鸿沟也是很痛苦的事情。
这样就导致开发人员的一个认知,本来虚拟机用得好好的,你们搞什么容器,现在出问题了吧,反正赖容器就对了。
一句话,传统的运维开发方式对云原生没有做好准备。
知识库
知识库的问题,首先云原生落地过程中,当前状态很多知识库还不够完善,有时候遇到问题去搜索的话,还是会抓瞎的。
我们团队的人员因为处理了大量的实践问题,经验丰富,我们也输出了不少文档。
但是我们发现业务方真正遇到问题的时候,压根不翻文档,而是直接甩给我们。当然这里面的原因,可能是因为缺乏云原生相关技术背景不足而看不懂,或者就是一个意识问题。总的来说,知识库的传承成本比较高,一些问题的预案和效率是极低的。
我们认为推动云原生容器化落地过程中运维在这一块目前面临比较大的挑战。

组织与人员架构
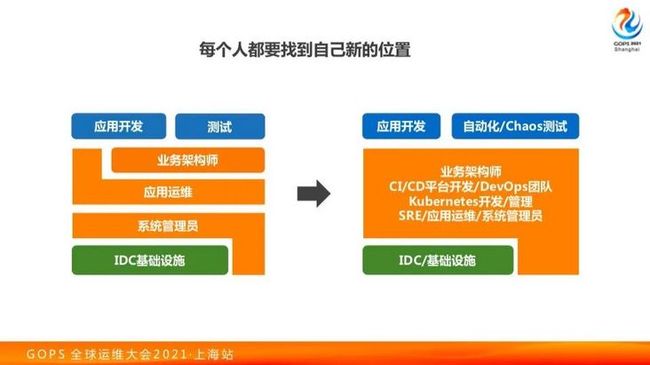
在传统开发场景下最上层是开发、测试,中间会有业务的架构团队、应用运维、系统运维、平台开发,下面是整个IDC的基础设施保障,整个架构层次分明。
但如果某个公司正在做云原生容器化落地,你会发现中间层成为了一团浆糊,多多少少大家工作都有一些交叉。如果一个平台开发不知道业务方使用容器的姿势,可能会出现业务方会用各种奇怪的玩法而导致出问题,最后还是运维运维来兜底。
问题的原因在于每个工程师的定位发生了改变,比如 SA 以前只管理机器,现在会涉及到容器的网络和存储,需要去了解 Kubernetes 的工作原理,这样一来很多人都必须去学习 Kubernetes。
容量管理
关于容量,有几个方面。一个是业务方不合理申请资源,另一个是业务方也无法预知情况,比如突然来了一个促销之类的活动,容量需求增长。
运维 Kubernetes 还一个比较关键的容量问题是,控制组件的资源消耗的容量评估常常被忽略。客户往往部署了 Kubernetes 集群并配置了报警,然后后续就不停地加节点。突然某一天发生了事故崩掉了,找运维问怎么回事,结果可能发现就是管控面容量不足了。
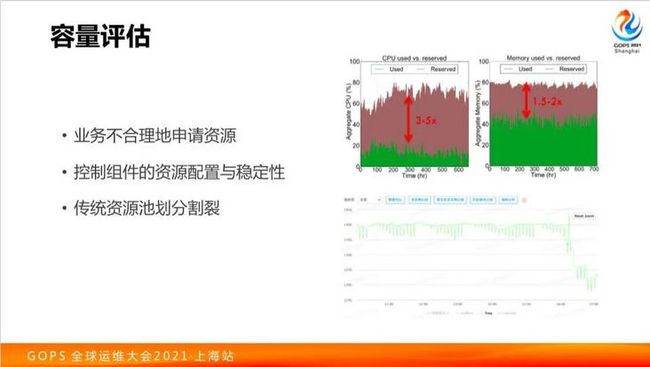
这里展示一个截图,因为 Kubernetes APIserver 重启了一下,内存在极短时间增加了百分之二十多,重启的那一刹那会有大量的请求进来,导致内存消耗得比较厉害。这种情况下,一般都会配置有阈值报警。当然如果你不处理这种问题,一旦触发了,接下来可能会出现雪崩效应,再也拉不起来了,直到你增大资源容量为止。
接下来简单从刚才我说的运维提效、稳定性保障、成本上我们做的实践。
2. 运维提效
首先我们集群使用了中心化的托管,当然并不是所有部门都是我们管的,我们只管跟我们关系比较密切的集群。整个权限认证体系,直接走我内部的员工认证系统,做到了统一认证,权限还是走RBAC,授权到个人。其次是因为我们大量的人力在帮客户做排障,不同人和不同部门一遍遍找过来,不愿意看文档和你做的事情,你兜底就可以了,我们团队一直是超载的状态。因此,我们要把一些常见的排障诊断过程做成自动化。最后,针对监控数据这一块,监控数据的存储没有直接使用开源系统,而是使用内部实现的TSDB,来把监控数据统一存下来,这样可以更好对数据进行消费。
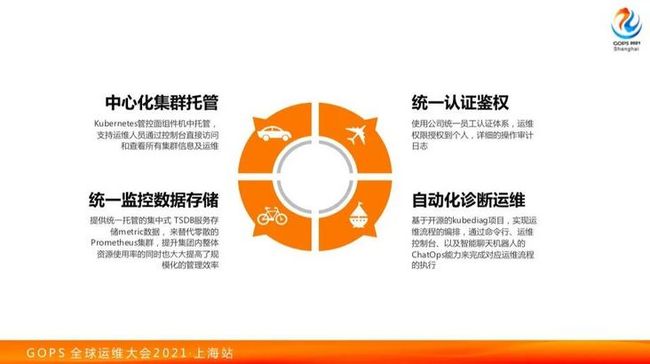
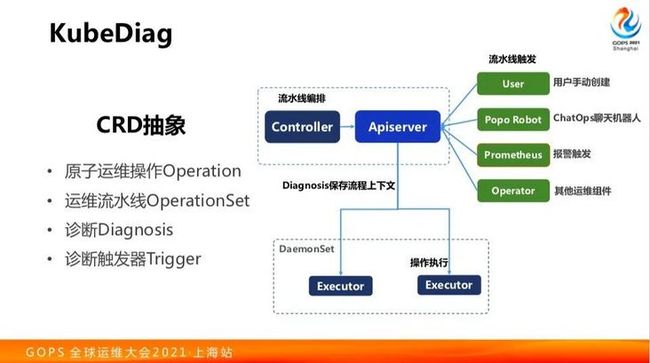
下面说下自动化诊断运维,刚才前面的两位老师也都分享过类似的内容。类似的,我们也是有知识库和流水线执行。很多公司做流水线的时候是做了自己内部一个平台,和其他的内部系统进行对接,这样一来可能解决了自己的问题,但是通用性并不高。我们在网易内部面临什么问题呢?我们还按那种方式去做别人不会用你的东西,因为你是一个平台。别的部门要和它的做适配用起来比较痛苦。我们更多想通用一些方案,Kubernetes场景下有CRD的支持,把运维诊断、性能排查等各种东西抽象成CRD的方式去做。
我们把一个运维操作抽象成一个原子运维操作Operation,把一个机器设置为不可调度,判断是不是符合某个已知Bug场景等。多个Operation的编排会构成一个运维流水线OperationSet。针对诊断上下文,我们做了个Diagnosis的抽象。
诊断流水线的触发方式可以有更多种。首先用户可以自己手动创建一个Diagnosis执行。
我们内部也使用泡泡(网易内部的IM)聊天机器人,来实现Chatops,通过与机器人聊天来触发相关的流程。对于聊天机器人,我们不想去做比较复杂的知识理解,我们更多的是很直接的。给聊天机器人发相对结构化的语句,告诉他你帮助我看一下什么问题就可以了。因为我们公司整个认证体系是一块的,泡泡机器人也会通过统一的认证体系,可以很轻易找到你的权限,避免你做一些超越权限的事情。通过这种ChatOps你可以触发流水线的执行。
还有一个更大的流水线触发源,就是监控报警的触发。比如说业务的某个应用,容器使用的CPU/内存占用达到了阈值之后,可以自动触发一次拿堆栈的信息,做内存的dump,然后把对应的对战信息,以及dump的内存文件上传到对象存储里面去。接下来的流程中,是可以把这些dump出来的数据拿出来进行分析的。
当然有一些像中间件也会有这样一些情况,他们往往要做稳定性保障,如果我的中间件实例出现了某种情况,应该执行什么操作?类似于这样的逻辑我们也可以把它编排起来,这样我们可以让其他的operater来去创建这种我们新的Diagnosis的Oparater,通过这种方式把这个东西实现起来。
简单来说我们整个场景就是Kubernetes下的一套应用,就是用apiserver接受相关的CRD,然后用Operator做执行,大概就是这么一个东西。
这块我们希望这个东西后续在内部把它做成一个平台,我们希望这个东西更泛化来看,就是通过一个事件触发一个流程,做一些运维操作、运维诊断,传统遗留下来的脚本都可以完整继承下来。详见:KubeDiag 框架技术解析
因为Kubernetes是标准的API,如果说你是基于Kubernetes的场景,那我们的一些经验可能是对你们有用的,很多东西景是共通的。比如,大家可能都遇到过内核版本在4.19之前的,memcg的回收处理是有问题的,会导致大量的泄露,包括像Docker的早期版本也会有大量的容器删除不掉的问题。
我们都有一系列的workaround的手段,这样的手段我们可以把它做得非常的智能化,比如说我们报警监测到一个Pod退出超过15分钟,还没有被干死,那我们可能就触发一次诊断,来看是不是已知的Bug,如果是的话,我们就通过一些手段把它自动恢复掉。这种类型的诊断是通用的。
在传统的场景下,可能不同的公司,运维人员登陆机器的方式都不一样,因此传统的场景下我们没有办法做到通用。但是Kubernetes的场景下我们可以做到通用,因为Kubernetes RBAC可以做权限控制,我们整体的有daemonset的方式去对你的进程做一操作,去帮你收集很多东西是可以做到的。
还有比较头疼的,像很多做AI、大数据相关的,主要是AI训练,他们有C/CPP代码,会出现coredump,coredump会带来几个问题,会导致本地的磁盘当时使用率会很高,会影响同节点上其他的业务。这个时候我们可以通过一些方法,做到全局统一的本地不落盘的coredump采集。还有像发数据包、打火焰图等等类似这种,很多时候像性能诊断,还有一些常规的软件Bug workaround是非常通用,这个都是底层的能力了。
我们再往上考虑业务层面也会有一些很通用的能力,比如说一个Node出现半死不活的状态可以把Node隔离掉等等。我们希望后面能够把这个东西做得更完善一点,希望有更多的场景,有更多人参与进来。
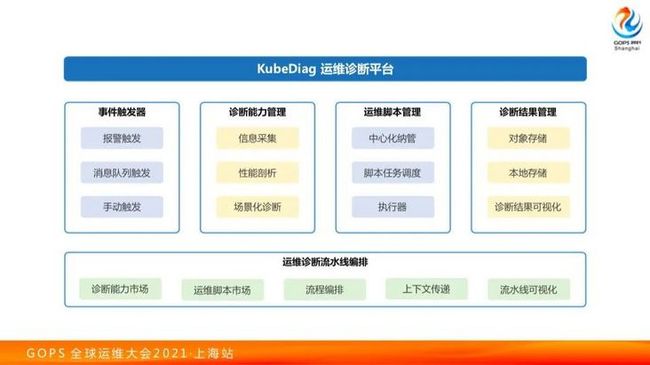
我们整个项目是一个框架加很多的规则,这块目前也已经把这个东西放出去了,我们短期内的一个想法是把界面做好一点,然后我们把之前传承下来的很多经验输出成代码,放到流程里面去,达到开箱即用的流程体验。
关于提效这一块通过这种方式能够做到什么效果呢?不再让我们团队Overload了,不用看文档看怎么回事自动解决掉了,解决自己人力耗费的问题。同时这个东西是相对代码化的,不存在某个兄弟比较猛技术比较好,他走了搞不定了,因为代码留下来了。
3. 监控与报警
稳定性大家知道 Tracing、logging 和 Metric,但是像 Tracing 和 logging 几年前提得比较少,现在分布式场景下的很多问题,导致分布式 Tracing 也做起来了。但是 Metric 这方面一直是一个金字标,今天也主要关注的是 Metric 这一块。
在采集系统指标时,传统的方式可能是*stat数据,各种从procfs中的数据进行采集,现在我们希望通过 eBPF 拿到更细粒度的数据。采集这些个细粒度的数据的主要原因是分清责任。比如业务方要查一下业务抖动,可能是基础设施和机房的问题,这个时候很难自证清白。可以通过这样的手段,像我们采集 TCP 的 RTT 数据可以证明是不是系统的问题。
内存更多是内存回收相关的,像 Memory Cgroup 相关的回收、PageCache reclaim 这类报警的指标采集了不少。CPU 调度这块,基本上就是关注调度延时,进程从它变成 Running 到开始运行到底延迟了多长时间。
还有像文件IO,有时候磁盘会抖一下,抖一下有的业务方异步写日志不受影响,如果是全同步会导致受到影响。这个时候我们需要定位到到底是什么原因导致的。我们还需要监视,像VFS的延迟等等,这些指标都需要从底层去获取到。
像 eBPF 现在支持 uprobe 技术,因此还可以做另外一块。比如传统监控应用访问数据库,会在客户端,像 Java 程序通过 agent 注入一些字节码增强来发现访问 MySQL 快了还是慢了。如果有了 uprobe 机制,在 MySQL 或 Kafka,代码固定情况下可以用 uprobe 勾服务端的函数,不再从客户端的方式抓问题了。
这时候也是自证清白的,比如说用户自己代码有Bug,他认为是你后端 Redis 出问题了,你可以说数据没有到我这里来,我函数执行勾出来了,效果是好的。这一块当前我们还是在尝试和落地中。
然后在 Tracing 领域的话,像一些手段是通过日志分析,通过SDK代码里面打日志的。事实上如果在一些传统的应用,一些非常老的遗留的应用里面,你不太好让他做这样的集成的时候可以用 uprobe 的手段拿到里面动态的信息。也可以在在网络层面,做一些 Redis 协议的解析,可以通过网络输出流量层面拿到错误信息、延迟信息,错误。这个相关的实现相对复杂一点,这个阶段我们是尝试落地阶段。
当然我们现在做这个事情非常细粒度指标对于内核版本要求比较高,我们内部有一个部门的内核版本已经到 5.13 了,比较激进。
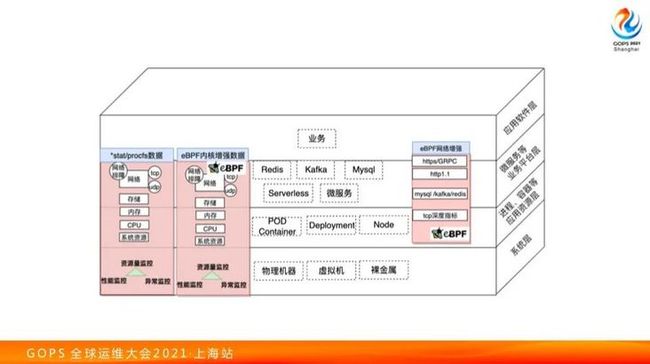
这样以来造成我们采集到指标比较多,指标是用来做报警的,报警其实不好做,前面两个老师也一直在提这个问题,报警解决什么问题?第一不该报警不能报出来,第二该报的报警都要报出来,这两个都不好解决。
报警的治理
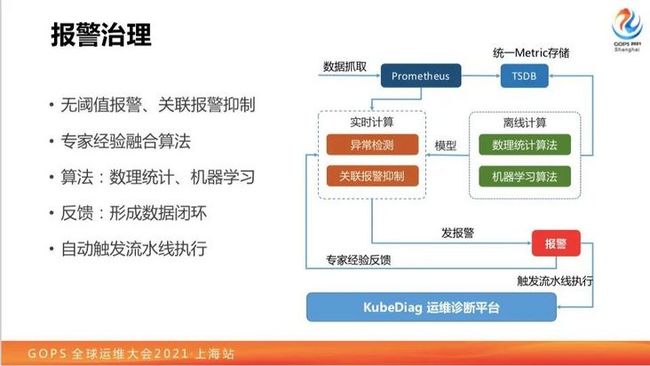
首先传统的阈值报警有什么问题呢?它会变的,你今天的请求和明天的请求由于什么原因就变了。要么就是没有快速配、改阈值出现了问题,或者是出现了误报警你自己吓一跳,会导致这种情况。无阈值报警相关的想法,大概我们从2017年、2018年开始探索的东西,只不过我们现在往云原生去做移植。
还有一块是关联报警抑制的问题,比如说你磁盘慢了,磁盘慢了会导致什么问题呢?会导致用户打日志会卡,日志一卡像Java程序会导致处理线程增多,线程池会爆掉,导致响应延迟变高等一系列的影响。事实上你想一下这些报警之间还是有关联的,我们报警的时候可能只需要报出来磁盘慢就可以了,其他没有必要报,其实需要一个报警关联作为抑制的策略。
这块怎么做的呢?大家今天看到了AIOps的专场里面人非常多,大家都会对这样一些话题感兴趣。目前来看不管是实践还是个人感觉来看,完全依赖AI不是那么现实的,至少现在这个阶段好像没有看到很好的实践。
我们现在更多是做了数理统计,有少量的机器学习算法帮助我们建模,这个建模更多是分析单一指标或者是相关联的指标,相关联的指标还是靠经验输入,不是真正自动分析。因为到现在为止,还是不相信AI真的能达到那么好的智能。
我们目前依赖数理统计算法,正态分布等等,使用非常基本的机器学习算法通过离线计算,来生成模型,然后实时计算模块做异常检测,达到无阈值报警的状态。还有关联报警抑制,关联报警抑制是输入进去的,不是机器学习学习出来的。
还有报警的反馈问题,报警之后检测异常发给你一个报警,这个报警是不合适或者是有问题的你可以做一个调参。比如说我们算某一个指标的周期函数做拟合,拟合某个参数,它的周期就是有问题,我们假定就是不对的可以手动调一下、改一下都可以。或者是有些报警瞎报有问题的,我们抑制掉就好了。
我们希望能做好一整套,从监控到问题触发,到整体离线计算、实时计算,人工反馈回去这样做的闭环,使得这个东西做下去。
这是我们关于监控和报警这块的内容。
4. 成本的节约
成本节约手段
下面就是成本方面。成本管理在网易这边,包括之前面临最大的问题,一个事业部现在突然间来了一批任务,我们网易有做内容安全的,在某些时候,会突然有大量的业务过来。他们机器不够用,就会到处借机器、协调机器,浪费了大量的人力精力。
现在我们做这样的手段,希望把内部资源池做得更好一点。成本节约主体就是资源配置的推荐问题,刚刚嘉宾也说到这样的问题,包括升配、降配这样的问题,就是VPA。VPA其实还是蛮有意义的东西。
另外混合部署,在业界也是比较热的。这个东西落地下来可能真的很困难,可能真不的适合很多中小企业。
还有刚刚说到融合内部的资源池,希望构建大的池子,供每个业务部门来使用。
还有业务推动的问题,从老板到干活的,你做新的东西不可避免会有不稳定因素。我们的实际经验,你在做容器化的时候遇到问题从业务方看来都是容器的问题,你在做混合部署的时候遇到所有问题,业务方都认为是混合部署导致的问题,业务方认为他自己一点问题都没有,但是最后查下来都是业务方的问题,你要告诉他有问题。
下面简单说一下我们的两块内容,一块是混合部署,一块是资源融合的。
混部系统
网易在前年开始尝试落地混合部署,现在已经拥有一定的规模。
首先是两块,一块是调度,一块是隔离,调度我们做得比较简单,虽然业界有机器学习、资源画像、资源调度等论文和实践,但我们目前只是基于实时数据采集来做依据。
从实际来看,基于实时监控数据来去看资源的使用量,目前来看还算好。也就是说不太会有某个在线业务真的不停在波动,至少可以让离线业务相对平稳运行一段时间。

隔离手段
隔离手段主要有几块,计算主要就是CPU的调度和内存管理。CPU的调度传统的CFS的Share隔离有一点问题,因为它的一个要求,公平调度不管你的业务优先级多低都是公平的。还有最小调度延时的问题,跑一定的时间才会切换CPU。像离线的业务跑起来,比如大数据的业务,CPU一定是满的,会造成在线业务一定的延迟是正常的。业界有比较好的落地案例,腾讯开了自己的调度类,阿里云有自己的技术,叫Group Identity。类似的东西业界有些实践,我们内部会参考别人的思考结合到自己的版本里面去。
还有超线程相关的,不知道大家清楚不清楚,超线程如果在物理核上实际是单核。不同场景下会有不一样,但是一般我们认为大概120%-130%,并不是两个核的算力,这样一来如果说你的离线业务和在线业务在一个物理核的两个超线程上,在线业务会受到非常大的干扰,在这块在调度器上可以做一些规避。
还有像L3隔离,我们基本上限制离线任务的量。
Page Cache回收对在线业务基本可控,但是对于中间件服务来说,基本是不可控的。如果你的Page Cache回收没有处理好的话,非预期被回收掉会造成性能极大下降,或者是一直不回收导致业务OOM掉。因为我们内核版本比较新,里面也加了一些自动回收和主动回收的手段。
最后,混部最大的落地挑战就是离线业务往往需要做到存算分离,这个跟IDC的基建相关。在自建IDC会发现IDC可能是N年前建的,老旧的设备能不能支撑全链路QoS,都是打问号的。之前遇到过交换机的坑,当把流量打满,离线业务访问远端存储的网络是满的,这个时候触碰交换机的Bug,会导致一些随机性的延迟,排查起来是很痛苦的。
在IO隔离这一块,虽然 CgroupV2 里面有很多 Buffer IO 隔离策略,但可能最简单粗暴的还是用不同的块设备,这是最简单的。
目前网易内部的隔离手段还是选择简单和普适性,并没有追求极致的混合部署效果。

资源池融合
网易内部的各个部门相对独立,意味着每个部门都有多套 Kubernetes 集群。如果一个业务的集群资源大量剩余,另一个业务的资源完全不够用怎么办?我们做了一个超大的资源池叫Kubeminer,我们把业务的 Kubernetes 集群分为 Consumer 和 Provider,一个资源的消费方,一个资源的提供方,都使用 KubeMiner 的方式模拟虚拟节点。
对于资源消费方来说看到了虚拟节点,对于资源提供方来说完全无感知,因为帮别人把业务跑到他的集群里面去,中间进行了转化。
通过这种方式把之前单集群的资源扩展到所有其他 Kubernetes 的集群里去。这样如果某个业务方容量没有规划好,或者是某个时间段内资源剩余比较多,他可以把资源卖给别人。如果某个业务资源方临时有些需求,可以看看别人谁有资源。
为什么做成这种架构?首先这个比较普适,对于 Consumer 来说无非改一下业务调度条件,把业务调度到虚拟节点就可以了,Provider来说完全无感知,他们无非看到跑了一堆我不认识的 Pod 上来。
还有一个好处对业务零感知,业务不用做特别多的适配,对于 Consumer 还是在自己的集群,对于 Provider 没有感知,因为不关心这个东西。我们中间要做结算体系,我们要给他把钱算清楚,这是我们的工作。
难点
难点列了三个,组织形态导致我们出现了非常分裂的场景,每一方的 Kubernetes 集群网络方案不一样,有各种各样的网络方案,我们做统一资源池的时候要做到互通,这是我们做的过程当中认为挑战比较大的。
还有对跨集群对象同步,虽然你把Pod调度过来了,但是像 PV,像 Service 访问、ConfigMap 之类的token等等都要在这个集群中同步,因为我们要做到让他体验到在自己集群一样。
还有我们怎么做最佳撮合?什么意思呢?业务方需要10个Pod,Provider没有一个集群能够承担10个Pod的容量,怎么办?我们要往好多个集群去分。那我们怎么把它做得更好一点?因为底下Provider集群还在动态变,人家本来也在用,这个时候我们怎么做到达到相对好的效果?这一块我们现在手段比较简单,基本上根据经验简单配了一些参数,因为现在的参数去撮合。
大概就是这样子,目前没有做特别复杂的算法,后续可能会在调度机制上做一些手段。

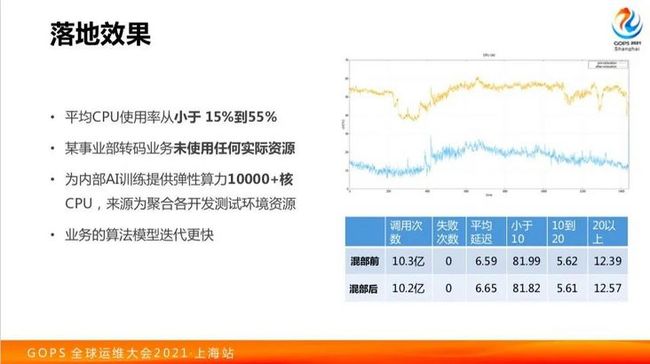
落地效果
今天的整体分享大概就这些,最后有一个效果,整体成本节约产生的一些价值,我们内部并没有做到很极致,平均CPU利用率到55%而已;某事业部的视频转码业务实现了没有消耗任何的真实资源,都以低优先级的任务在混部着跑;通过弹性的资源池方式聚合了各种各样 Kubernetes 集群的算力资源,给其他业务方向提供了弹性资源能力。
今天就到这里,谢谢大家。
作者简介
王新勇,网易数帆容器编排团队负责人,曾参与网易集团负载均衡,SDN等项目建设,目前主要在推动网易互联网业务云原生技术落地,致力于云原生环境下的稳定性保障和成本优化相关工作。
了解更多