有了自学算法去提取特征,我们可以进一步扩展模型
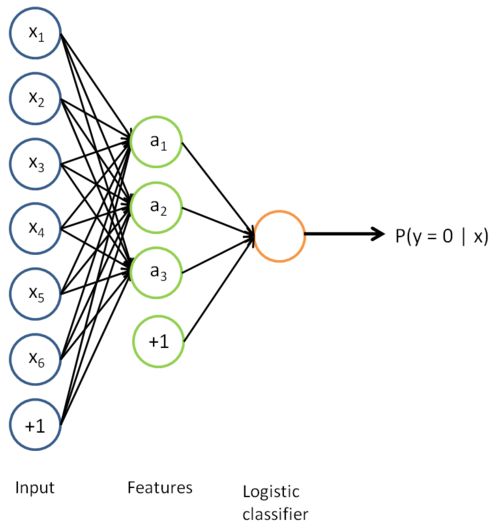
这个模型是在特征模型的基础上多了一步分类器,这个分类器的引入使得我们可以进一步调整参数。
微调(fine-tune)指的的是通过输入有标记的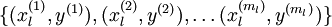
再通过牛顿下降法来调整参数从而减小训练误差
什么时候可以使用微调呢?当然是有大量的有标记样本啦。
上面这个模型试简单的三层神经网络
因为每一个隐层代表了对前一层的一次非线性变换,简单的三层模型最后输出的激活函数只与前一层相关,也就只经过了一层的非线性变换,如果能够增加隐层,就能够学习更加复杂的的关系,这也是为什么不用线性变换的原因,线性变换再经过线性变换还是线性的。
深层网络由如下好处:
1.由于隐层增加了,它可以学习更加复杂的函数。具体来说,一个k-1层的网络要想学习到和k层网络一样复杂的模型,得增加指数大小的隐层。
2.越深层,最后学到的特征越抽象
3.神经元计算也是多层的,这是深层神经网络的生物基础
神经网络的缺陷:
1.标记数据的难以获取
2.局部最优问题,浅层的神经网络容易收敛,但是深层神经网络就会有不收敛的问题,深层神经网络的高层监督学习涉及到高阶非凸最优化问题
3.梯度扩散问题。深度过多时,BP算法计算损失函数,梯度值随着深度慢慢向前而显著下降,这样就导致前面基层的网络对于整体的最终损失函数的贡献十分小。我们可以增加神经元的个数,但是这样就成了浅层。
所以我们怎么训练深层神经网络?
其中以个比较成功的方法是贪婪逐层训练法,也就是每次只训练网络的一层,从前往后逐层训练,这种训练可以试监督的也可是是无监督的,但是一般是无监督的,初始化之后再微调。成功的逐层训练方法由以下几个因素构成:
1.数据的有效性,有标记的数据很难获取。通过无标记的数据来学习一个很好的初始权值,我们的算法能够学习和发现更好的模式。
2.更好的局部最优。通过无标记数据的训练,权重在参数空间后更好的初始化了。前提假设是,通过无标记数据的训练,这些信息提供了很好的先验信息使我们去逼近一个局部最优解。
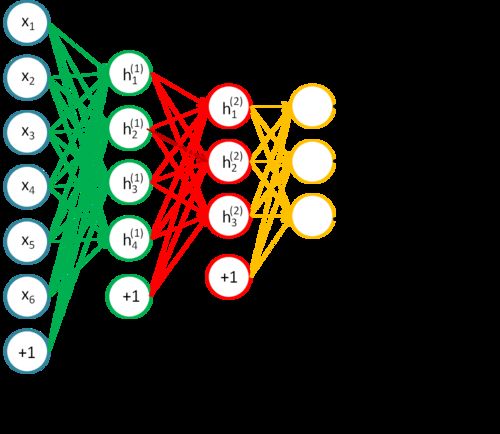
下面我们介绍stacked autoencoder
也就是包含多个稀疏自编码器的神经网络
版权声明:本文为博主原创文章,未经博主允许不得转载。