CVPR2021 多目标跟踪(MOT)汇总
CVPR2021 多目标跟踪(MOT)方向文章检索到了9篇,如有遗漏,麻烦告知,谢谢。
指标对比和论文下载地址已经更新到我们所做的指标对比库,欢迎大家查阅。
https://github.com/JudasDie/Comparison
一、《Discriminative Appearance Modeling with Multi-track Pooling for Real-time Multi-object Tracking》
作者: Chanho Kim 1, Li Fuxin 2, Mazen Alotaibi 2, James M. Rehg 1.
1Georgia Institute of Technology, 2Oregon State University
论文链接:https://arxiv.org/pdf/2101.12159.pdf
代码链接:https://github.com/chkim403/blstm-mtp
1、摘要:
在多对象跟踪中,跟踪器中的会保留每一个对象所有的外观和运动信息。这些信息存储被用于进行检测和跟踪的匹配,且新的匹配结果会用于更新每个目标的存储信息。很多方法独立地建模每一个目标,缺乏所有在场景中的目标地信息来更新内存。当场景中存在类似的外观对象时,这可能会出现问题。在本文中,我们通过一种新的多轨迹池化模块(multi-track pooling module),解决了在空间开销较小的内存更新过程中同时考虑所有轨迹的问题。此外,我们还提出了一种适应多跟踪池化的训练策略,可以在线生成硬跟踪片段(hard tracking episodes)。我们表明,这些创新的结合构建了一个强大的鉴别性的外观模型,其使用贪婪的数据关联来实现在线跟踪性能。我们的实验证明了在公共多对象跟踪(MOT)数据集上的实时、最先进的性能。
这个出发点挺有意思的,至少在之前的多目标跟踪中,我们都习惯于对每个目标进行单独建模,对于外观信息(即reid中提取出来的appearance embeddings)用的是训练集来拟合的,很难保证在测试的时候会不会出现外观及其相似的情况(虽然我们在训练中会用损失把这些可能相似的拉开,但是gap依然存在),他这个思路可能能在一定程度上在测试阶段可以动态调整,会更鲁棒。思路如果说相似的话有点像单目标的DMIP(建模环境信息),但是做法应该不一样。
2、方法:

思路其实也比较简单,之前的方法都是只用一个目标的embedding去做更新,文中提出不仅仅要考虑目标匹配上的那个embedding做正样本,还要考虑场景中的其他目标的embedding做负样本来做更新。模型构建见原文,训练是对每一个视频采集了一小段一小段的序列来做训练的,同时为了防止GPU显存爆炸也做了一些特殊的训练设计,这样也可以保证测试和训练对齐。
二、《Learning a Proposal Classifier for Multiple Object Tracking》
作者: Peng Dai 1, Renliang Weng 2, Wongun Choi 2, Changshui Zhang 1, Zhangping He 2, Wei Ding 2
1Tsinghua University, Beijng, China, 2Aibee Inc
论文链接:https://arxiv.org/pdf/2103.07889.pdf
代码链接:https://github.com/daip13/LPC_MOT.git
1、摘要:
多对象跟踪(MOT)的趋势是利用深度学习来提高跟踪性能。然而,以端到端的方式解决数据关联问题并不简单。在本文中,我们提出了一个新的基于提案的可学习框架,它将MOT建模为亲和力图上的提案生成、提案评分和轨迹推理范例。该框架类似于两阶段目标检测器更快的RCNN,可以以数据驱动的方式解决MOT问题。对于提案生成,我们提出了一种迭代图聚类方法,在降低计算成本的同时保持生成方案的质量。对于提案评分,我们部署了一个可训练的图卷积网络(GCN)来学习生成的提案的结构模式,并根据估计的质量评分对其进行排序。对于轨迹推理,采用一种简单的去重叠策略生成跟踪输出,同时满足不能检测的约束。我们的实验表明,在两个公开基准上,该方法在MOTA和IDF1上都取得了明显的性能改进。
出发点比较正常,端到端的框架也是只做数据关联部分,不涉及到检测,UMA,MPNTrack(CVPR2020)的出发点也是构建一个一体化的数据关联的端到端框架。而结合检测的一体化的mot tracker在这几年已经出现了。用图来做优化的话思路也比较像MPNTrack(CVPR2020),但是作者在后面的相关工作中指出MPNTrack是将不可学习的数据关联问题建模为一个可微的边缘分类任务,采用无向图对数据关联问题进行了建模。将网络学习到的特征通过边分类器判断这条边是激活状态还是非激活状态来完成分组(数据关联),获得最后的跟踪输出。作者认为这个方法一般不能保证流量守恒约束,最终的跟踪性能可能对所满足的流量守恒约束的百分比很敏感。而文中提出用了一种提案可学习的多目标框架有利于解决这个问题(我的理解是这种二阶段的分类结构比直接对边做分类的效果要好,可参考检测中的two-stage和one-stage比较),最后的方法对比IDF1比MPNTrack也有一定的提高。
2、方法:
思路是通过将一系列的帧和检测结果作为输入,通过图来建模不同帧目标(tracklets/detections)之间的关联问题。这篇文章主要设计了两个模块,一个是提案生成模块(proposal Generation),另一个是可训练的GCN(proposal Scoring)被用来评估生成的提案的质量分数。此外在生成最后的跟踪轨迹之前用了一个简单的消除重叠的策略,都比较好理解,细节可见原文。
三、《Multiple Object Tracking with Correlation Learning》
作者: Qiang Wang, Yun Zheng, Pan Pan, Yinghui Xu
Machine Intelligence Technology Lab, Alibaba Group
论文链接:https://arxiv.org/pdf/2104.03541.pdf
1、摘要:
最近的研究表明,卷积网络通过同时学习检测和外观特征,大大提高了多目标跟踪的性能。然而,由于对卷积网络结构本身的局部感知,无法有效地获得时空上的长期依赖关系。为了结合空间布局,我们提出利用局部相关模块来建模目标与周围环境之间的拓扑关系,从而增强模型在拥挤场景中的鉴别能力。具体地说,我们建立了每个空间位置及其上下文的密集对应关系,并通过自我监督学习明确地约束了相关量。为了利用时间上下文,现有的方法通常使用两个或多个相邻的帧来构建一个增强的特征表示,但动态运动场景本质上很难通过CNNs来描述。相反,我们的论文提出了一个可学习的相关算子来建立不同层的卷积特征图上的的帧与帧之间的匹配,以对齐和传播时间上下文。通过在MOT数据集上的大量实验结果,我们的方法证明了相关学习的有效性,并在MOT17上获得了最先进的MOTA的76.5%和IDF1的73.6%。
本文的出发点是打破现在性能先进的同时学习检测和外观特征的一体化跟踪器受到卷积结构限制而无法有效建立空间和时间上下文信息的局限,思路很新,这种方法可以比原有的apperance embeddings更具区分性。方法是基于FairMOT上进行改进的,取得了现在已发表文中中最高的性能。
2、方法:
方法主要可以分为两部分,一是局部结构感知网络,并通过自监督学习增强了相似对象的可识别性;二是利用局部相关网络来有效地建模时间信息。
1) 空间局部相关图层(Spatial Local Correlation Layers)是通过计算query特征和周围相关特征(一个边长为2R的矩形)的相关性,并将其计算结果通过MLP将相关性结果进行编码并与原来的外观特征相加来获得(详见文中公式),此外,为了实现长程的相关性,文中也提出学习特征金字塔上的相关性(即多个尺度的感知层上的)。
2)时间相关性学习(Temporal Correlation Learning)是通过计算query特征和之前帧周围位置相关特征(一个边长为2R的矩形)的相关性,并获得增强后的特征信息。这个特征信息会包含前面的embedding feature所提供的时序信息。
这样的结构设计保证了学习到了特征更具有时空信息,从实验表明,该特征对提高检测和跟踪性能都很有效果。
四、《Online Multiple Object Tracking with Cross-Task Synergy》
作者: Song Guo 1, Jingya Wang 1,2, Xinchao Wang 3,4, Dacheng Tao 1
1The University of Sydney, 2ShanghaiTech University, 3National University of Singapore, 4Stevens Institute of Technology
论文链接:https://arxiv.org/pdf/2104.00380.pdf
代码链接:https://github.com/songguocode/TADAM
1、摘要:
现代在线多对象跟踪(MOT)方法通常关注两个方向,以提高跟踪性能。一种是基于来自之前帧的跟踪信息来预测输入帧中的新位置,另一种是通过生成产生更有鉴别别的身份嵌入来增强数据关联。有些工作在一个框架内结合了两个方向,但将它们作为两个单独的任务处理,因此几乎没有互惠互利。在本文中,我们提出了一种新的在位置预测和嵌入关联之间具有协同作用的统一模型。这两个任务通过时间感知目标注意力和干扰器注意力以及识别感知记忆聚合模型联系起来。具体地说,注意模块可以使预测更关注于目标,而更少地关注分散注意力,因此可以相应地提取更可靠的嵌入以进行关联。另一方面,这种可靠的嵌入可以通过内存聚合来提高身份识别意识,从而增强注意力模块,抑制漂移。这样,就实现了位置预测和嵌入关联之间的协同作用,从而对遮挡具有很强的鲁棒性。大量的实验证明,我们提出的模型比现有的各种方法的优越性。
看摘要第一感觉作者所分的这两个方向并不是很准确,应该需要增加一个前提,就是基于public检测器的情况下,即假设已有了官方提供的检测结果不外接检测器后才会通常关注于这两个方向。出发点是多任务之间的协作,还是挺有意思的,逻辑思路很直观(见introdution中的图)。这个方法中和第一篇文章有个相似的地方,就是都去考虑了其他目标作为干扰的影响,不同的是之前那个用的是分类器,这个用的是attention。这里的协同在introduction中指的是attention有利于增强关联,目标不漂移,获得正确的定位框;而正确的定位框有利于在memory中聚合更有用的身份信息,来增强attention,获得更丰富,更robust的attention。
2、方法
1、位置预测(position prediction)
文中使用了Faster RCNN的结构,并重新训练了一个回归头,通过从先前位置的框在当前的特征图上获得ROI pooling的向量,预测出当前帧的位置(有点像Tracktor,不同的是考虑了作者提出的TADAM Attention)。
2、时间感知的目标注意和干扰器注意(Temporal-Aware Target Attention and Distractor Attention)
我的理解是框的位置预测用的是上一帧的框的回归(类似Tracktor),然后iou大于阈值的目标框认为是干扰,用来计算attention(TADAM ,具体使用的non-local attention)。注意力的结果会去调节要每一个目标框(ROI)中的特征,通过元素级的加减,从而获得更有效的特征表示,保证目标不漂移。
3、ID的内存聚合(Identity-Aware Memory Aggregation)
出于减少每个目标的内存内存在噪声,设计了一个具有卷积门控递归单元(Gru)的判别记忆模块,其中Gru中的矩阵乘积被替换为卷积。
五、《Probabilistic Tracklet Scoring and Inpainting for Multiple Object Tracking》
作者: Song Guo 1, Jingya Wang 1,2, Xinchao Wang 3,4, Dacheng Tao 1
1The University of Sydney, 2ShanghaiTech University, 3National University of Singapore, 4Stevens Institute of Technology
论文链接:https://arxiv.org/pdf/2012.02337.pdf
1、摘要:
尽管通过联合检测和跟踪在多目标跟踪(MOT)方面取得了最新的进展,但处理长遮挡仍然是一个挑战。这是因为这些技术往往会忽略长期的运动信息。在本文中,我们引入了一个概率自回归运动模型,通过直接测量轨迹建议的可能性来评分。这是通过训练我们的模型来学习自然轨迹的潜在分布来实现的。因此,我们的模型不仅允许我们为现有的轨迹分配新的检测,还允许我们在对象丢失很长一段时间内绘制轨迹,例如,通过采样轨迹,以填补由于检测错误造成的空白。我们的实验证明了我们的方法在具有挑战性的序列中跟踪对象方面的优越性;它在多个MOT基准数据集上,包括MOT16、MOT17和MOT20。
这个模型是online的,出发点很有意思。在以往,我们解决一个物体被长期遮挡都是offline利用全局的信息来做,比如插值等等。文中认为之前所有这些方法都将人类的运动视为一个确定性的或一个单模态的过程。而作者认为人类的运动是一个随机的多模态过程,因此应该被设计成一个非线性随机运动模型,以便在面对遮挡时解释场景中的不确定性。
2、方法

作者提出了一种自回归的轨迹修补和评分方法(ArTIST,Autoregressive Tracklet Inpainting and Scoring for
Tracking)。ArTIST估计自然运动的多模态分布,产生S条可能的轨迹,并对它们进行选择来获得最有可能的轨迹来和之前的轨迹拼接,实现对轨迹空白的修补。可见,该方法实现的两个核心在于如何生成S条轨迹和如何选择合适的轨迹修补空白。
1)ArTIST结构
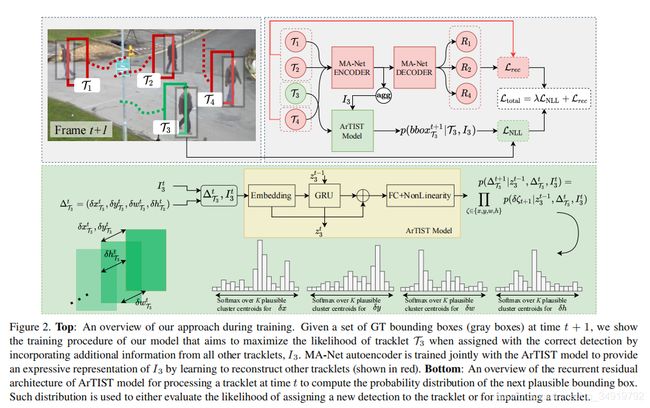
这个结构比较直观,先将其他的轨迹信息送入递归的自编码器神经网络(MA-Net,Moving Agent Network)进行编码,学习重建可能与感兴趣的轨迹相互作用的所有移动代理的轨迹。然后将自身的信息和其他轨迹的编码信息送入一个网络(ArTIST)中,输出是一系列的运动可能性。在实践中,作者使用非参数k均值聚类来获得K个簇,并将每个簇质心视为一个离散运动类。(实现细节见原文)
2)轨迹评分(用于分配的时候用)
我们可以评分在时间t的检测是跟踪Tj的延续的可能性。为此,给定Tj的速度序列和Ij,该模型估计了t时刻在边界框位置上的概率分布。结合估计分布,将检测的可能性作为tracklet-detection对的得分。
3)轨迹修补
由于ArTIST只依赖于几何信息,因此它本身不能估计哪些未绘制的选项是有效的。为了选择其中一个候选对象,作者用了一个比较简单的轨迹拒绝方案(TRS),如下:如果要选择一个候选对象,我们计算最后生成的边界框与当前帧中所有检测的IOU,然后选择IOU最高的且高过一定阈值的匹配轨迹作为修补轨迹。为了减少错误匹配(如匹配到误检或者其他目标上去),作者还往后多匹配了几帧。
4)分配
为了适应作者的方法提出了一种分配策略,分为两步。第一次只对那些没有进行修补的轨迹于当前帧的检测做匹配计算;第二次对进行修补的轨迹和第一次没有匹配上的检测进行匹配计算。
六、《Quasi-Dense Similarity Learning for Multiple Object Tracking》
作者: Jiangmiao Pang 1, Linlu Qiu 2, Xia Li 3, Haofeng Chen 4,Qi Li 1,Trevor Darrell 5,Fisher Yu 3
1Zhejiang University, 2Georgia Institute of Technology, 3ETH Zürich, 4Stanford University,4UC Berkeley
论文链接:https://arxiv.org/pdf/2006.06664.pdf
代码链接:https://github.com/SysCV/qdtrack
1、摘要:
相似性学习已被认为是目标跟踪的一个关键步骤。然而,现有的多目标跟踪方法只使用稀疏的地面真值匹配作为训练目标,而忽略了图像上的大部分信息区域。在本文中,我们提出了拟密度相似性学习,它密集地采样了一对图像上的数百个区域候选。我们可以直接将这种相似性学习与现有的检测方法相结合,建立近密度跟踪(QDTrack),而不转向位移回归或运动先验。我们还发现,所得到的独特特征空间在推理时允许一个简单的最近邻搜索。尽管它很简单,但QDTrack在MOT、BDD100K、Waymo和TAO跟踪基准上还是优于所有现有的方法。
出发点很简单,就是现在的MOT中ReID学习的时候用的是交叉熵和三元组(及其变形)基本。这种损失的构建只是取了GT的框来提取信息,作者认为这样的训练不够充分,要针对于目标取dense一些,这样有利于学习更好的的相似性。

2、方法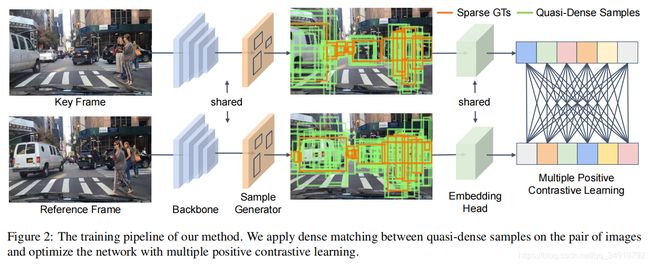
训练:感觉比较相似于检测中的一种密集采样。
测试:用了一种bi-softmax来替代余弦相似性(感觉像双向的点积和),保证了双向的一致性,在实验中带来了IDF1的提高。
七、《SiamMOT: Siamese Multi-Object Tracking》
作者: Bing Shuai, Andrew Berneshawi, Xinyu Li, Davide Modolo,Joseph Tighe
Amazon Web Services (AWS)
论文链接:https://www.amazon.science/publications/siammot-siamese-multi-object-tracking
1、摘要:
在本文中,我们着重于改进在线多对象跟踪(MOT)。特别地,我们引入了一个基于区域的Siamese多目标跟踪网络,我们将其命名为SiamMOT。SiamMOT包括一个运动模型,估计实例在两帧之间的移动,使检测实例相关联。为了探索运动建模如何影响其跟踪能力,我们提出了Siamese跟踪器的两种变体,一种是隐式建模运动,另一种是显式建模。我们在三个不同的MOT数据集上进行了广泛的定量实验:MOT17、 TAO-person和Caltech Roadside Pedestrians,显示了运动建模对MOT的重要性,以及SiamMOT大大优于最先进的能力。最后,SiamMOT在HiEve数据集上的表现也超过了ACMMM的20HiEve大挑战的获胜者。此外,SiamMOT是高效的,它在一个现代GPU上为720P视频以17FPS的速度运行。
从出发点来看主要是通过Siamese的思路构建一个MOT的实例跟踪器。但依然需要通过单独的Siamese Tracker对每一个目标进行处理。
2、方法
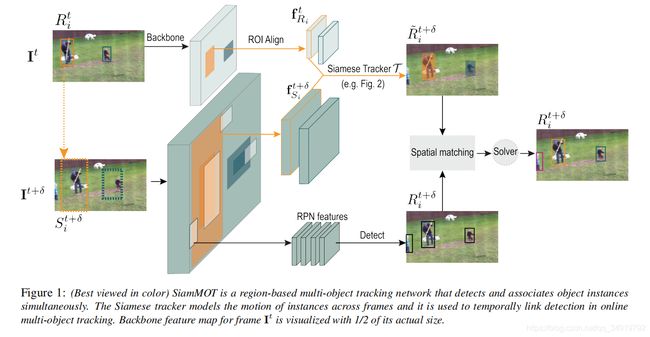

思路很简单,基本上可以通过图看懂。图中的spatial matching指的是计算检测框和Siamese预测框的IOU,超过阈值则匹配、
八、《Track to Detect and Segment: An Online Multi-Object Tracker》
作者: Jialian Wu1, Jiale Cao 2, Liangchen Song 1, Yu Wang 3,Ming Yang 3,Junsong Yuan 1
1SUNY Buffalo, 2TJU, 3Horizon Robotics
论文链接:https://arxiv.org/pdf/2103.08808.pdf
代码链接:https://jialianwu.com/projects/TraDeS.html
1、摘要:
大多数在线多对象跟踪器在神经网络中独立地执行对象检测,而没有来自跟踪的任何输入。在本文中,我们提出了一种新的在线联合检测和跟踪模型,TraDeS(跟踪,检测和分割),利用跟踪线索来帮助端到端检测。TraDeS推断对象跟踪的偏移量通过计算成本,用于传播以前的对象特征,以改进当前的对象检测和分割。TraDeS的有效性和优势性在4个数据集上显示出来,包括MOT(2D跟踪)、nuScenes(3D跟踪)、MOTS和Youtube-VIS(实例分割跟踪)。
构建了一个端到端的框架,这个框架可以同时完成检测,多目标跟踪(2D和3D),实例多目标跟踪与分割。同时,它融合了时序的信息,像通过上一帧的信息来增强当前帧的检测。因为这个方法是基于CenterNet搭建的,从图上看有很多细节和FairMOT和CenterTrack有些思路相似的地方。通过CVA和MFW来增强时序信息,这个的出发点和之前的CorrTrack(第三篇文章)有点类似,但是构建的图更加的dense,同时学出来的Tracking offset是全图检索的,比直接做回归的效果可能更鲁棒一些。
2、方法
1)基准,用了CenterNet,参考了CenterTrack的思路增加额外的分支来传播时序信息。此外在输出的head中也加了多个分支,让其可以有更多功能的输出,网络内部的改进主要是提出了基于成本量的关联(Cost Volume based Association。CVA)和运动导向特征整合(Motion-guided Feature Warper,MFW)。
2)CVA:用于学习re-ID嵌入和推导对象运动。首先提取embeddings的feature通过图中的embedding network σ(·)。计算Cost Volume为C∈RHc x Wc x Hc x Wc,其中每一个值表示不同帧之间的embedding的相似性,这个图是dense的,比CorrTrack还要dense。通过模板,可以获得2个维度的Tracking offset,这个offset相比于CenterTrack来说更远(因为是全图检索的),同时可以作为MFW的输入来增强特征。
训练的时候,会用计算的Cost Volume来构建loss,目的是让不相似的距离更远一些,同时也和环境区分开来。作者说这种训练机制更有利于在学习更好的ID embeddings的同时不伤害检测性能。
3)MFW:利用来自CVA的跟踪线索来传播和增强对象功能。为了实现这一目标,文中通过一个单一的可变形卷积进行了一个有效的时间传播,即通过聚合传播的特征来增强当前帧的特征ft。
九、《Learnable Graph Matching: Incorporating Graph Partitioning with Deep Feature Learning for Multiple Object Tracking》
作者: Jiawei He1,3, Zehao Huang 2, Naiyan Wang 2, Zhaoxiang Zhang 1,3,4
1Institute of Automation, Chinese Academy of Sciences (CASIA), 2 TuSimple, 3School of Artificial Intelligence, University of Chinese Academy of Sciences (UCAS), 4 Centre for Artificial Intelligence and Robotics, HKISI CAS
论文链接:https://arxiv.org/abs/2103.16178.pdf
代码链接:https://github.com/jiaweihe1996/GMTracker
1、摘要:
跨帧的数据关联是多对象跟踪(MOT)任务的核心。这个问题通常通过传统的基于图的优化来解决,或直接通过深度学习来学习。尽管它们很受欢迎,但我们发现一些当前的范式值得研究:1)现有的方法大多忽略了跟踪器和帧内检测之间的上下文信息,这使得跟踪器在严重遮挡等具有挑战性的情况下难以有效。2)端到端关联方法仅依赖于深度神经网络的数据拟合能力,而它们几乎没有利用基于优化的分配方法的优势。3)基于图的优化方法主要利用单独的神经网络提取特征,导致训练与推理的不一致性。因此,本文提出了一种新的可学习的图匹配方法来解决这些问题。简单地说,我们将轨迹和帧内检测之间的关系建模为一个一般的无向图。然后将关联问题变成了轨迹图和检测图之间的一般图匹配。此外,为了使优化的端到端可微,我们将原始图匹配简化为连续二次规划,然后利用隐式函数定理将其训练合并到深度图网络中,效果SOTA。
又是一篇用图的思路来做数据关联的文章,与之前的工作不同点在于,这篇工作认为要做到更好的匹配效果不仅仅需要建模帧间目标的关系,轨迹和帧内检测之间的关系也需要做一个建模。我觉得作者这一点想表达的意思是同一帧目标和目标在特征和空间相对位置在相邻帧中存在一定的时序一致性(同样对于轨迹),可以通过挖掘这些信息来获得更好的匹配。另外一个点是在原来的图数据关联方法中提取特征的网络是分开的,而这篇文章将其和匹配联合在一起做优化。
2、方法
该文章中将把多对象跟踪问题表述为一个图匹配问题。我们没有求解原始的二次分配问题(QAP),而是将图匹配公式relax为一个凸二次规划(QP)问题,并将该公式从边缘权值扩展到边缘特征。这种改变促进了特征表示和组合优化的可微学习和联合学习。
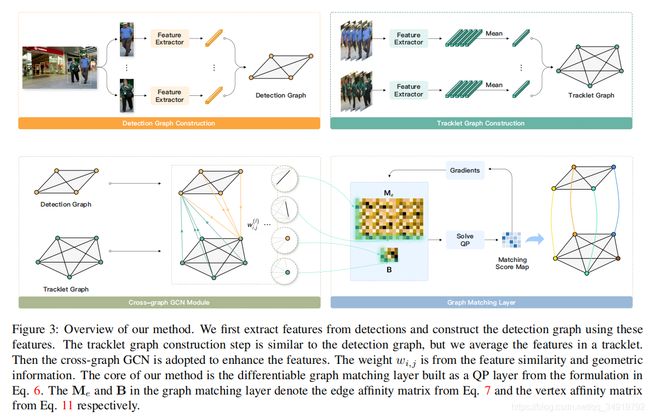
感觉这篇工作要弄明白的两个点一个是Me和B这两个矩阵是怎么构建的,另一个是怎么做匹配。
1、B (vertex affinity matrix):点亲和力网络这个基本是所有MOT中都会构建到的,先用ReID模型提取向量,然后向量计算两两相似性,再加权个kalman和IOU的组合,经典的Deepsort中搭配。
2、Me(edge affinity matrix):作者在文章将其称之为边亲和力矩阵,其计算公式如下

其中h_{i,i}表示了当前帧/轨迹所构建的图网络中边的向量,然后计算这些两个完全图之间每一个边的相似性(向量相似性)来构建矩阵中的数值。这些边向量应该是通过两个点之间的ReID网络提取出来的向量concat在一起做一次l2的归一化。虽然看不出这样拼接为什么能很好的表达出边的亲和力还有和ReID的亲和力学习是否和相互冲突,但是因为这个和后续是联合一起优化的,在一定程度上可以认为是多任务学习。
3、匹配
Me会被映射为一个方阵M,然后和B一起通过图网络学习匹配分数,最终的匹配分数会被构建为形状为n_{d}和n_{t}的匹配分数图X。