ICCV2021 多目标跟踪(MOT)汇总
一、《Learning To Track With Object Permanence》
作者: Pavel Tokmakov Jie Li Wolfram Burgard Adrien Gaidon
Toyota Research Institute
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Tokmakov_Learning_To_Track_With_Object_Permanence_ICCV_2021_paper.pdf
Github:https://github.com/TRI-ML/permatrack
1、摘要
基于检测的跟踪是在线多目标跟踪的主要方法,它通过交替完成目标定位和数据关联来实现跟踪。从结果来看,它严重依赖于实例观测的质量,当物体不完全可见时,它往往会失败。相比之下,人类的追踪强调了物体持久性的概念:一旦一个物体被识别,我们就能意识到它的物理存在,即使在完全遮挡下也能近似地定位它。在这项工作中,我们引入了一种端到端可训练的联合目标检测和跟踪方法,它能够进行这样的推理。我们在CenterTrack的基础上进行了构建,并以任意长度的视频帧作为输入进行预测。我们用一个时空的循环记忆模块来增强模型,允许它使用所有之前的历史记录来推理当前帧中的实例位置和身份。然而,如何训练这种能力并不易得。我们在一个新的大规模的用于多对象跟踪的合成数据集上研究了这个问题,提并出了几种监测遮挡后跟踪的方法。我们的模型在合成和真实数据上联合训练,由于其对遮挡的鲁棒性,所提出的方法优于KITTI和MOT17数据集上的最先进水平。

该方法的创新在于不仅仅依靠视觉来预测实例的位置,也通过时间记忆网络来预测目标的位置。这种做法在目标被部分和完全遮挡的时候可以更有效的召回目标,提高目标的定位能力。这篇工作应该是首次将记忆网络作为一个模块引入到一体化多目标跟踪模型中,构建了端到端的网络。
2、方法

PermaTrack的做法很简单,首先将一系列帧作为输入并用Backbone网络处理生成蓝色特征图。该特征图会被收入记忆模块(Conv GRU)中进行再次编码,获得时序增强后的特征Mt。基于该部分特征图,通过两个单独的分支进行编码,可以获得基于目标视觉特征的预测和基于目标一致性的预测。
然而在模块设计中,作者并没有在机构上去区分这两种预测的差异,而是通过训练来保证输出。由于之前的数据很多是没有标注遮挡情况的,所以作者用了虚拟生成的数据集,将遮挡和被遮挡的目标分为两部分,用不同的分支进行监督(focal loss)。并加入部分真实数据进行微调,消除虚拟数据带来的gap。
二 、《Track without Appearance: Learn Box and Tracklet Embedding with Local and Global Motion Patterns for Vehicle Tracking》
作者: Gaoang Wang, Renshu Gu, Zuozhu Liu, Weijie Hu, Mingli Song, and Jenq-Neng Hwang
Zhejiang University, Hangzhou Dianzi University, Guangdong University of Petrochemical
Technology, University of Washington
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Wang_Track_Without_Appearance_Learn_Box_and_Tracklet_Embedding_With_Local_ICCV_2021_paper.pdf
Github:https://github.com/GaoangW/LGMTracker
1、摘要
车辆跟踪是多目标跟踪(MOT)领域的一项重要任务。对于车辆跟踪来说,一个明显特征是车辆的轨迹在世界坐标和图像坐标上都是相当光滑的。因此,捕捉运动一致性的模型是非常必要的。然而,由于信息有限、检测错误和遮挡以及目标很容易丢失,使用独立的基于运动的跟踪器进行跟踪是相当具有挑战性的。虽然利用外观信息来帮助对象重新识别可以在一定程度上解决这一挑战,但是这样做需要额外的计算,而外观信息对遮挡也很敏感。在本文中,我们试图探讨运动模式在没有外观信息的车辆跟踪中的意义。我们提出了一种新的方法解决关联问题的长时跟踪,充分利用目标的运动信息。我们提出了基于深度图卷积神经网络(GCN)的embedding重构策略来解决轨迹embedding生成的问题。在KITTIcar跟踪数据集和UA-Detrac数据集上进行的综合实验表明,该方法虽然没有外观信息,但可以实现与最先进的(SOTA)跟踪器竞争的性能。

文章的出发点是在没有外观信息的情况下充分挖掘目标的空间位置和运动信息,来实现有效匹配。
2、方法


本文的方法主要是想将物体的位置信息抽象成embedding用于匹配。从经典的基于embedding匹配的方法(deepsort或jde)来看,这类方法通常包含两个关键步骤,第一个是每个目标的embedding怎么抽象出来(包括当前帧和tracklet),第二个是这些embedding如何跨帧完成匹配,以实现整体轨迹的生成。
在第一方面,作者设计了两个网络来生成需要的embedding。在box embedding的抽象上,作者将每一个目标框的边框信息xyhw抽象成一个Nx4的特征图(N为当前帧目标数),并用图神经网络来处理,以构建用于匹配的embedding。在图网络的训练上用了经典的交叉熵损失和三元组损失。而在另一部分中,作者提出了一种基于tracklet的embedding生成方法,想通过学习目标的局部运动模式和轨迹情况来构建基于tracklet的embedding。具体来说,是通过图卷积抽象出每个tracklet之间的关联性,并通过轨迹之间的关系来重构新的向量。
在匹配方面,作者提出了50%匹配时间窗的概念。框会根据box embedding关联成轨迹,而轨迹如何贪婪匹配形成整体的轨迹没有展开讲(有兴趣的可以去看代码)。
三 、《Exploring Simple 3D Multi-Object Tracking for Autonomous Driving》
作者: Chenxu Luo, Xiaodong Yang, Alan Yuille
QCraft, Johns Hopkins University
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Luo_Exploring_Simple_3D_Multi-Object_Tracking_for_Autonomous_Driving_ICCV_2021_paper.pdf
Github:https://github.com/qcraftai/simtrack
1、摘要
基于激光雷达点云的三维多目标跟踪是自动驾驶车辆的关键组成。现有的方法主要是基于检测进行跟踪,不可避免地需要一个启发式的匹配步骤来进行数据关联。在本文中,我们提出了SimTrack,一个端到端可训练的模型来简化手工设计匹配步骤的范式。我们的关键设计是预测每个对象在一个给定的视频片段中首次出现的位置,以获得跟踪身份,然后基于运动估计更新位置。在推理中,启发式匹配步骤可以被一个简单的读出操作来完全替代(用预测替代手工设置)。SimTrack将跟踪对象关联、新生对象检测和死轨删除集成在一个统一的模型中。我们对两个大规模的数据集进行了广泛的评估:nuScenes和Waymo开放数据集。实验结果表明,在排除启发式匹配规则的同时,我们的简单方法优于现有的方法。
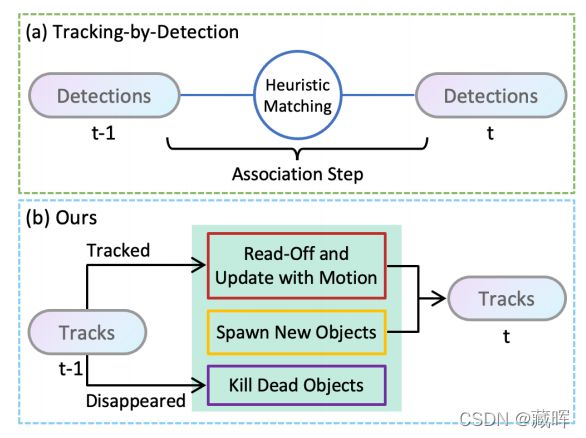
本文的亮点在于不需要手工去设计目标的关联策略,包括逐帧关联,新轨迹生成和旧轨迹终结。全由网络来自主学习出来。
2、方法
了解了本文的出发点之后,方法也很好理解。输入是相邻的两帧图像,通过backbone编码后输出三个map。第一个预测目标的位置(相当于一个前景概率),如果上一帧有目标在这个位置,则继承ID。如果上一帧没有,当前预测有则生成新的轨迹。如果上一帧有,当前帧预测没有则删除轨迹。之后两个特征图分别预测物体的运动方向和偏移量,以实现关联。
四 、《Assignment-Space-based Multi-Object Tracking and Segmentation》
作者: Anwesa Choudhuri, Girish Chowdhary, Alexander G. Schwing
University of Illinois at Urbana-Champaign
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Choudhuri_Assignment-Space-Based_Multi-Object_Tracking_and_Segmentation_ICCV_2021_paper.pdf
1、摘要
多目标跟踪和分割(MOTS)对于理解视频数据中的动态场景具有重要意义。现有的方法在独立视频帧的多目标检测和分割上效果良好,但随着时间的推移跟踪目标仍然是一个挑战。MOTS方法在局部进行跟踪,即逐帧跟踪,导致次优结果。经典的全局跟踪方法直接作用于对象检测,这导致了检测空间的组合增长。相比之下,我们制定了一个基于分配空间的MOTS的全局方法:首先,我们发现在任意两个连续帧之间检测和分割的对象的top-k分配,并开发一个结构化预测公式来对任意数量的连续帧的分配序列进行评分。我们使用动态规划在多项式时间内找到该公式的全局优化器。其次,我们连接了那些在消失一段时间后又会重新出现的物体。综上,我们将其设定为一个分配问题。在具有挑战性的KITTI-MOTS和MOTS挑战数据集上,这在各种方法之间取得了最先进的结果。
理解起来像是将原来基于实例的匹配替换成基于全局目标的匹配。
2、方法

该方法是通过每一帧全局结果来进行匹配(这样做估计计算量要比实例大上不少,但是可以学习空间结构信息,而非只依靠于mask)。通过构建每一种全局匹配结果之间的距离,选择最小代价的链路为最终的匹配结果。这个方法的一大重点是全局匹配结果之间的距离怎么计算。
文中会像计算每一个目标两两实例之间的距离,这个距离为一个外观、IOU和空间距离的加权和。
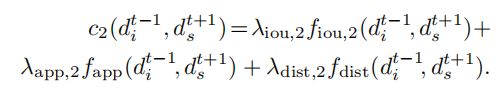
然后基于每一个距离,通过匹配关系矩阵a(矩阵上的权值代表目标间的关系)将当前两帧的匹配总代价计算出来,即:
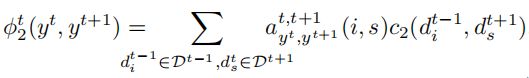
五 、《A General Recurrent Tracking Framework without Real Data》
作者: Shuai Wang, Hao Sheng,Yang Zhang, Yubin Wu, Zhang Xiong
State Key Laboratory of Software Development Environment, School of Computer
Science and Engineering, Beihang University, Beijing 100191, P.R.China
Beihang Hangzhou Innovation Institute Yuhang, Beihang University, Xixi Octagon City,
Yuhang District, Hangzhou 310023, P.R.China
College of Information Science & Technology, Beijing University of Chemical Technology,
Beijing 100029, P.R.China
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Wang_A_General_Recurrent_Tracking_Framework_Without_Real_Data_ICCV_2021_paper.pdf
1、摘要
多目标跟踪(MOT)的最新进展表明,鲁棒跟踪评分机制具有重要的意义。然而,由于MOT中缺乏可用的数据,因此很难学习一般的评分机制。在当前的手动评分功能中,只能使用外观、运动等多种线索来指定策略。在本文中,我们提出了一个适应于大多数跟踪器的多节点跟踪(MNT)框架。基于此框架,设计了一个循环跟踪单元(RTU),通过长期信息对潜在的跟踪进行评分。此外,我们提出了一种不需要真实数据就能生成模拟跟踪数据的方法,以克服MOT中可用数据有限的缺陷。实验表明,我们的模拟跟踪数据对训练RTU是有效的,并在MOT17和MOT16基准测试上都取得了最先进的性能。同时,RTU可以灵活地插入到DeepSORT和MHT等经典跟踪器中,并取得了显著的改进。

这个文章提出了除了GNN网络外,另一类评分策略的自动生成。与GNN类方法不同,本文基于记忆网络设计一个可以利用多个长期线索的通用评分机制,在利用时序信息上有一定优势。
2、方法

在本文中,作者提出了多节点跟踪框架(MNT),它也遵循了通过检测进行跟踪的范式,可以应用到如deepsort、FairMOT这类方法中。与上述工作不同的是,MNT连接了三种类型的基本节点来构建轨迹,而不是检测。正确的节点和假的节点分别代表正确的链接和错误的链接检测。我们还设计了虚拟节点来表示在严重遮挡的情况下的缺失检测。
如图所示,每个对象都由一个包含不同节点的轨迹树表示。对于每一个目标来说,每个节点会按RTU进行分类,并计算获得每一个分支的分数s。为了避免树的分支指数增加所带来的计算量,也采用了MHT中的剪枝策略。

RTU的输入输出如下,Xt表示当前节点的状态特性Xt(一个所有度量相似性所构成的向量,并包含一个是否丢失的自定义项)。Ft表示当前节点的视觉外观特征,Ft-1表示匹配模板(由RTU上一帧生成),ht-1为记忆网络的隐藏记忆,用于传输。在输出中,ht表示更新后的隐藏记忆,F’t表示更新后的模板,St表示当前节点两两匹配关系所获得的评分。
这样也就实现了本文motivation所提及的不用根据手工线索来设计匹配策略的出发点,同时也适合移植到基于deepsort类思路的方法。
六 、《Continuous Copy-Paste for One-stage Multi-object Tracking and Segmentation》
作者: Zhenbo Xu, Ajin Meng, Zhenbo Shi, Wei Yang, Zhi Chen, Liusheng Huang
University of Science and Technology of China
Hangzhou Innovation Institute, Beihang University, Hangzhou, China
Beihang Univ, Beijing Key Lab Digital Media, Sch Comp Sci & Engn, Beijing, China
Beihang Univ, State Key Lab Virtual Real Technol & Syst, Beijing, China
ShiFang Technology Inc., Hangzhou, China
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Xu_Continuous_Copy-Paste_for_One-Stage_Multi-Object_Tracking_and_Segmentation_ICCV_2021_paper.pdf
Github:https://github.com/detectRecog/CCP
1、摘要
目前的一步多目标跟踪和分割(MOTS)方法落后于最近的两步方法。通过将实例分割阶段与跟踪阶段分离,两步法方法可以利用非视频数据集作为额外的数据来训练实例分割。此外,可以收集在不同帧上属于不同id的实例,而不是在原始连续帧中收集有限数量的实例,以便在跟踪器的训练中更有效地进行硬示例挖掘。在本文中,我们通过提出一种新的数据增强策略连续复制粘贴(立方最密堆积)来弥补这一差距。我们在立方最密堆积背后的直觉是充分利用MOTS提供的像素级注释,积极地增加训练中的实例数量和唯一的实例id。在不对框架进行任何修改的情况下,当前的MOTS方法在使用立方最密堆积进行训练时获得了显著的性能提高。在立方最密堆积的基础上,我们提出了第一种有效的单级在线MOTS方法CCPNet,该方法可以一次性生成实例掩模和跟踪结果。
这个文章的出发点是提出了一种数据充分利用的方法,解决原来数量量不足的问题,以提高一体化MOTS模型的性能。
2、方法

本文的方法很好理解,从视频或者单张图像数据集上扣取实例的mask,然后把这些模板来构建一个instance database。在数据增强的时候,把这些instance贴到其他视频序列上,以实现数据增强。
七 、《MOTSynth: How Can Synthetic Data Help Pedestrian Detection and Tracking?》
作者: Matteo Fabbri, Guillem Braso,Gianluca Maugeri, Orcun Cetintas, Riccardo Gasparini, Aljosa O ˘ sep ˘, Simone Calderara, Laura Leal-Taixe,Rita Cucchiara
University of Modena and Reggio Emilia, Italy
Technical University of Munich, Germany
论文链接:https://openaccess.thecvf.com/content/ICCV2021/papers/Fabbri_MOTSynth_How_Can_Synthetic_Data_Help_Pedestrian_Detection_and_Tracking_ICCV_2021_paper.pdf
1、摘要
基于深度学习的视频行人检测和跟踪方法需要大量的训练数据才能获得良好的性能。然而,在拥挤的公共环境中获取数据会引发数据隐私问题——我们不允许在没有所有参与者明确同意的情况下简单地记录和存储数据。此外,对于计算机视觉应用程序,对此类数据的注释通常需要大量的手工工作,特别是在视频领域。在高度拥挤的场景中,标记行人的实例即使对人类注释者来说也可能具有挑战性,并可能在训练数据中引入错误。在本文中,我们研究了如何可以单独使用合成数据来推进多人跟踪在不同方面的发展。为此,我们使用渲染游戏引擎生成了MOTSynth,一个大型的、高度多样化的合成数据集,用于进行目标检测和跟踪方面的研究。我们的实验表明,MOTSynth可以用来替代行人检测、重新识别、分割和跟踪等任务上的真实数据。

这个工作很有意义,一个是数据量更大,一个是标签很干净,且生成的标签更多样,一个也解决了现在构建大规模数据集隐私的问题。
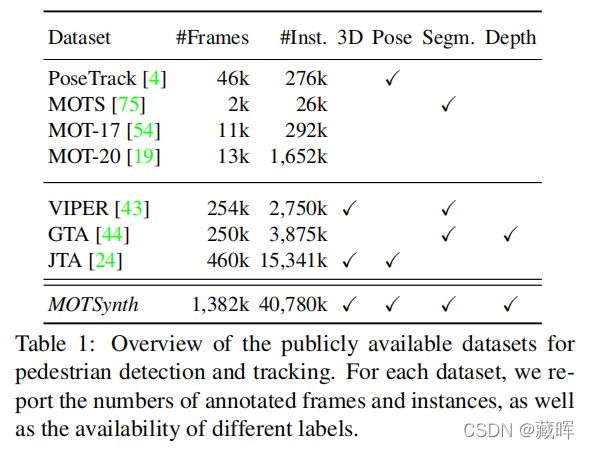
2、数据集信息
标注情况
数据集规模
在实验过程中,作者也做了实验验证在该数据集上训练的模型可以在真实数据集如MOT Challenge和Market等也可以起到很好的效果。