最新论文笔记(+19):Biscotti_ A Blockchain System for Private and Secure Federated Learning / TPDS21
Biscotti: A Blockchain System for Private and Secure Federated Learning"译为“Biscotti:一个用于隐私和安全联邦学习的区块链系统”
这是IEEE Transactions on Parallel and Distributed Systems 21(简称TPDS)上的一篇联邦学习和区块链相结合的文章。众所周知,TPDS是CCF A类期刊,上面论文的质量都不错,因此选读了这篇论文。以下内容,是自己阅读完后的一些小笔记,有不懂和疑问的地方,记录的都是个人认为重点的地方。
- 原文链接:Biscotti: A Blockchain System for Private and Secure Federated Learning
需要注意的是,本文中提到的见附录,但是我在下载的文献pdf中并没有看到附录。因此,还需要结合该作者18年发表在arXiv上的一篇论文来理解。以下是原文链接:
Biscotti: A Ledger for Private and Secure Peer-to-Peer Machine Learning
文章目录预览
-
- 一、背景及挑战
-
- 1.1 相关背景
- 1.2 关键挑战
- 二、主要内容
-
- 2.1 训练初始化
- 2.2 区块链设计
- 2.3 使用权益进行角色选举
- 2.4 噪声协议
- 2.5 验证协议
- 2.6 聚合协议
- 2.7 区块链共识
- 三、实验
-
- 3.1 容忍投毒攻击
- 6.2 性能、可伸缩性和容错
- 四、总结
一、背景及挑战
1.1 相关背景
联邦学习(FL)中的客户端需要完全相信中央服务器进行协调,且恶意客户端可能通过投毒攻击来损害模型性能。当前,FL主要受到投毒攻击和信息泄露攻击两种类型的攻击。
- 1)投毒攻击:一般是指恶意客户端污染数据或模型,从而使得全局模型难以收敛或降低准确度。
- 2)信息泄露攻击:文中也可以叫推理攻击,指通过某一上传的参数信息,从而推理出客户端个人隐私信息。
而以往的方案都是通过集中的异常检测、差分隐私和安全聚合进行防御。但是,目前还不存在同时解决这两种威胁的隐私和去中心化的解决方案。况且,传统方法不适用于缺乏可信中心权威的训练过程。
综上,本文提出了一种完全去中心化的Peer多方机器学习方法,它使用区块链和加密原语来协调peer客户端之间的隐私包含ML过程,称为Biscotti。
Biscotti使用了基于PoF(Proof of Federation)的一致性哈希和可验证随机函数(VRF)结合,为peer节点选择关键的角色,这些角色将帮助协调模型更新的隐私和安全性。为防止peer通过Multi-Krum防御毒害模型,通过差异化的私有噪声提供隐私,使用shamir秘密共享进行安全聚合。
首先理解相关的小知识。
- 1)PoF:简称联邦共识协议,大概理解为客户端对每轮训练的模型状态达成一致性协议。(详细内容需要找相关文献,我还没深入调研)
- 2)VRF:简称可验证随机函数,大概理解是一种输入某个值,输出一个随机值(包含生成者的私钥签名)和可验证的值(无需私钥即可验证该随机值是它产生的)。VRF具有三大特性:可验证性、唯一性和随机性。(可验证随机函数详细介绍)
- 3)Multi-Krum:这是一种聚合算法,由krum聚合算法演变而来。krum聚合算法指在若干个局部模型种选择一个与其他模型都相似的模型作为全局模型。这里将欧氏距离作为相似性的评判标准。而Multi-Krum就是执行多次krum算法,具体而言,首先执行一次krum算法,将得到的梯度从总的里面删除,然后再次迭代执行krum算法,到最后将每轮迭代选出的梯度进行krum算法,选择最终的全局模型。
- 4)Shamir秘密共享:也称为门限秘密共享,是指一份秘密值分为 n n n份,至少拥有 t , ( 1 < t < n ) t,(1
1.2 关键挑战
- 1)Sybil Attack:使用VRF和PoF来解决。
- 2)中毒攻击:使用Multi-Krum聚合算法更新验证。
- 3)信息泄露攻击:VRF验证者peer、使用预先承诺的噪声进行差分隐私更新。
- 4)差分隐私的效用损失:安全更新聚合和加密承诺。
二、主要内容
设计目标:
- 1)聚合生成最优全局模型。
- 2)通过验证peer模型更新预防中毒。
- 3)保持peer训练数据隐私以预防信息泄露攻击。
- 4)获得影响而无需获得充足的stake预防共谋peers。
分布式账本中的每个区块就代表了每次SGD的迭代,账本包含每次迭代全局模型中的state。
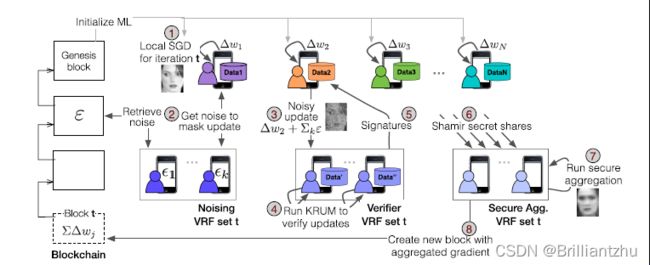
主要有八个步骤:
- 1)每个peers本地计算SGD更新。
- 2)因为SGD更新必须保持隐私,每个peer首先用差分隐私噪声masks(掩盖)更新。
- 3)这个噪声从每个客户端唯一的一组噪声peer中收集,并由VRF选择。
- 4)掩盖更新被验证委员会进行验证以防止投毒攻击,该验证委员会是由VRF算法选举出来的,若peer的掩盖更新可以通过multi-krum算法的验证,那么验证委员会的每个成员会为该peer的unmasked更新签署一个承诺。(不是很理解这句话)
- 5)若大多数委员会的成员都签署了更新。
- 6)这个更新就会通过shamir秘密共享协议分成多份。
- 7)然后多份更新就会发送到聚合委员会中进行聚合,聚合委员会执行一个安全协议去聚合unmasked的更新。完成聚合后,所有对梯度有贡献的peer以及担任了验证和聚合委员会的peer都将在系统中获得额外的stake(权益)。
- 8)聚合后的更新添加到全局模型中,并存储在一个区块内,同时将更新后的模型广播给所有的节点,并产生的区块会被添加到账本中。
2.1 训练初始化
每个peer使用genesis(原始)区块中的信息初始化训练过程。每个peer从生成区块中获取以下信息:
- 1)模型的初始状态 w 0 w_0 w0,期望的迭代次数 T T T。
- 2)创建SGD更新承诺的公钥 P K PK PK。
- 3)公钥系统中所有其他peer的 P K i PK_i PKi,用于验证过程中创建和验证签名。
- 4)每个peer对 T T T次SGD迭代的差分隐私噪声 ζ 1.. T \zeta_{1..T} ζ1..T的预承诺。
- 5)在peer之间的初始stake分配。
- 6)当添加新区块时执行的stake更新函数。
2.2 区块链设计
每个区块包含前一个区块的哈希指针,还有多个peer的SGD更新的聚合 Δ w \Delta w Δw和在迭代 t t t次时的全局模型 w t w_t wt。新添加到账本中的区块存储了多个peer的聚合更新 ∑ Δ w i \sum\Delta w_i ∑Δwi。为了验证聚合是真实计算的,需要将单个更新包含在区块中。然而,单独存储会泄露个人私有训练数据,本文使用多项式承诺来解决这个问题。
通过在区块中包含每个peer i i i的承诺列表 C O M M ( Δ w i ) COMM(\Delta w_i) COMM(Δwi),可以提供聚合的隐私性和可验证性。若提交的更新列表等于聚合总和,即以下等式成立
C O M M ( ∑ Δ w i ) = ∏ i C O M M ( Δ w i ) COMM(\sum\Delta w_i) = \prod_i COMM(\Delta w_i) COMM(∑Δwi)=i∏COMM(Δwi)
2.3 使用权益进行角色选举
每次迭代中,一个由peer的stake权重的一致性哈希进行选举出噪声者、验证者和聚合者。PoF确保peer的影响受其stake的限制。Peer可以在给定迭代中被分配多个角色。验证和聚合委员会对所有peers是相同的,但噪声委员会对每个peers是唯一的。
最后一个区块的初始SHA256被重复的进行哈希,每个新哈希被映射到一个哈希环,在这个哈希环中,根据他们的权益比例分配给peers,直至选出正确数量的验证者和聚合者委员会。
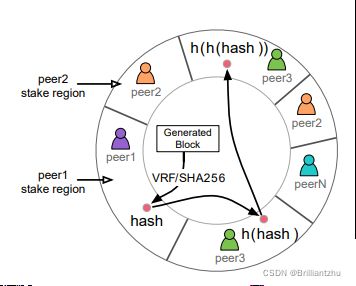
攻击者无法预测未来区块的状态,则不可能猜测出一致性哈希的输出,并制定策略进行攻击。
2.4 噪声协议
为防止信息泄露攻击,peer在验证过程中使用差分隐私,通过添加正态分布采样的噪声来隐藏自己的更新。
攻击者可能恶意使用噪声协议进行投毒或信息泄露攻击。若没有提前承诺噪声,那恶意参与方在完成本地梯度更新后,再生成自己的噪声,很容易进行伪造。
- 1)例如:一个peer可以发送一个有毒的更新 Δ w p o i s o n \Delta w_{poison} Δwpoison和添加噪声 ζ p \zeta_p ζp,使其更新类似于一个诚实更新 Δ w \Delta w Δw,正如 Δ w p o s i o n + ζ p = Δ w \Delta w_{posion} + \zeta_p = \Delta w Δwposion+ζp=Δw。在最终梯度聚合时,噪声会被去掉,那么就会把投毒的更新加到了最终的模型中,从而敌手完成了攻击。
- 解决办法:关键在于更新 Δ w \Delta w Δw的承诺时间点,若协议规定对更新承诺是在参与方获取噪声前,就没有办法作假了。此噪声并未来自参与方自己,而是通过VRF选举出来的噪声委员会,即这个参与方无法提前预知这个噪声,参与方也无法预知更新值,即无法根据噪声值和更新来求出投毒更新值。因此,一定要先产生更新,再添加噪声,若规定必须先对更新值做出承诺,那么该参与方不知道噪声的前提下,就无法构造投毒更新,即使构造了,在后面的验证过程也会被发现。
- 2)例如:有噪声的peer A和验证者B共谋攻击受害者peer C时,也可能发送信息泄露攻击。噪声peer A可以提交0噪声,完全不隐藏原始梯度值。B是验证者,当peer C添加了来自A的噪声,并将噪声梯度发送给验证者B时,B进行验证就知道是A提供的噪声0,就可以看到C传递的更新是unmasked更新,就可以对客户端C的梯度进行重构出训练数据。
- 解决办法:参与方C的噪声提供者与其私钥相关(签名噪声委员会选举时,参与方的私钥被作为参数传递给VRF函数的),只要C的私钥不泄露,谁也无法提前知道C的噪声委员会是由哪个参与方构成。就算有共谋,这个恶意的噪声提供者不一定会被C采纳,且噪声提供者的数量不止一个,里面也不可能全为恶意的噪声提供者,就算其中一个提供了0噪声,那么也无法获取真的更新值。
每个参与方对训练的每次迭代产生一个噪声和该噪声的承诺。

- 1)每次包含某个参与方i在T轮迭代中所有的噪声;
- 2)每列表示在第t次迭代中可能被使用的噪声;
- 3)当参与方准备在某次迭代中贡献自己的更新时,他会通过噪声VRF选举一个噪声委员会,并从中获取噪声提供者的噪声。
- 4)他们提供的噪声都是提前做过承诺的噪声;
- 5)这个参与方使用验证VRF去选举验证者集合;
- 5)该参与者把如下信息发送给验证者集合,如添加噪声的更新、噪声的承诺、未添加噪声更新的承诺和噪声委员会的选举证明。
2.5 验证协议
验证者peer对接收的更新集合运行Multi-krum算法,通过接收每轮接收到的大部分更新来过滤恶意的更新。每个验证者受到每个参与方 i i i的如下信息:
- 1)添加噪声后(mask SGD)的更新: ( Δ w i + ∑ k ζ k ) (\Delta w_i + \sum_k \zeta_k) (Δwi+∑kζk)。
- 2)对SGD更新的承诺: C O M M ( Δ w i ) COMM(\Delta w_i) COMM(Δwi)。
- 3)一组 k k k个噪声承诺: { C O M M ( ζ 1 ) , C O M M ( ζ 2 ) , . . . , C O M M ( ζ k ) } \{COMM(\zeta_1),COMM(\zeta_2),...,COMM(\zeta_k)\} {COMM(ζ1),COMM(ζ2),...,COMM(ζk)}。
- 4)一份关于 k k k个噪声提供者的身份VRF证明。
当验证者收到上述信息后,会按照如下公式进行验证:
C O M M ( Δ w i + ∑ k ζ k ) = C O M M ( Δ w i ) ∗ ∏ k C O M M ( Δ ζ k ) COMM(\Delta w_i + \sum_k \zeta_k) = COMM(\Delta w_i) *\prod_k COMM(\Delta \zeta_k) COMM(Δwi+k∑ζk)=COMM(Δwi)∗k∏COMM(Δζk)
只要验证者收到了足够多的更新 R R R,他会使用multi-krum算法去挑选最好的更新。
- 1)对每个peer i i i,验证者计算分数 s ( i ) s(i) s(i),即 i i i更新到最接近 R − f − 2 R-f-2 R−f−2欧式距离的和,即
s ( i ) = ∑ i → j ∣ ∣ ( Δ w i + ∑ i , k ζ i , k ) − ( Δ w j + ∑ j , k ζ j , k ) ∣ ∣ 2 s(i) = \sum_{i\to j}||(\Delta w_i + \sum_{i,k} \zeta_{i,k}) - (\Delta w_j + \sum_{j,k} \zeta_{j,k})||^2 s(i)=i→j∑∣∣(Δwi+i,k∑ζi,k)−(Δwj+j,k∑ζj,k)∣∣2
其中 i → j i\to j i→j表示 ( Δ w j + ∑ j , k ζ j , k ) (\Delta w_j + \sum_{j,k} \zeta_{j,k}) (Δwj+∑j,kζj,k)属于 R − f − 2 R-f-2 R−f−2最接近更新的 ( Δ w i + ∑ i , k ζ i , k ) (\Delta w_i + \sum_{i,k} \zeta_{i,k}) (Δwi+∑i,kζi,k)。 - 2)分数最低的 R − f R-f R−f个peers被选择,其余的被拒绝。
- 3)验证者使用所有接受更新peers的公钥对 C O M M ( Δ w i ) COMM(\Delta w_i) COMM(Δwi)签名。
需要验证委员会中的大多数委员对这个更新验证通过,才能防止恶意的验证者接收共谋者的所有更新。
2.6 聚合协议
所有在验证阶段具有足够数量签名的peer都提交他们的SGD更新,以便聚合到全局模型中。
w t + 1 = w t + ∑ i = 1 Δ w v e r i f i e d Δ w i w_{t+1} = w_t + \sum^{\Delta w_{verified}}_{i=1} \Delta w_i wt+1=wt+i=1∑ΔwverifiedΔwi
其中, Δ w i \Delta w_i Δwi为peer验证过的SGD更新, w t w_t wt是迭代 t t t时的全局模型。
聚合协议允许一组 m m m个聚合器中至少有一半诚实地参与聚合阶段,就可以保护个人更新的隐私。若一致性哈希选择了大多数诚实的聚合器,那么这种保证就成立了,使用多项式承诺和可验证的秘密共享用于个人更新的聚合。
2.7 区块链共识
当peer观察到新区块时,可通过对最新区块执行一致性的哈希协议,并验证每个新区块指定的验证者和聚合者的签名,来验证所执行的计算是正确的。每个验证和聚合只在指定时间内发生,若未成功传播的任何更新将被删除。
三、实验
实验环境:GO1.1.0、Python2.7.12实现了Biscotti,用PyTorch框架在训练过程中生成SGD更新和噪声。
实验目标:
- 1)Biscotti对投毒攻击具有鲁棒性。
- 2)Biscotti保护单个客户端数据的隐私。
- 3)Biscotti是可伸缩的、容错的,可以用来训练不同的ML模型。
在分布式设置中完成了实验,迭代100次,记录全局模型的测试误差。
- 用逻辑回归模型评估Credit Card fraud 数据集,使用个人财务和个人信息来预测他们下次是否会拖欠信用卡付款。
- 用softmax分类器评估MNIST数据集,对齐进行图像预测。
3.1 容忍投毒攻击
调查Biscotti成功防御投毒攻击的不同参数设置,然后评估与联邦学习基准相比,它在30%恶意节点攻击下的性能。
- 1)要求验证委员会的每个成员在运行Multi-krum算法之前收集足够数量的更新样本。
- 2)评估了在MNIST中,改变Multi-krum在每轮收集更新的百分比对不同投毒攻击率的影响,从而评估Multi-krum的性能表现。
实验表明,在每轮攻击者数量为30%的情况下,至少需要70%的更新数量被收集才能有效的抵抗投毒攻击。
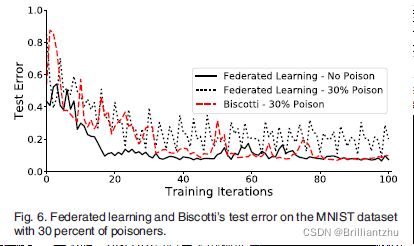
Biscotti与联邦学习的基准率相比:使用相同恶意数据集30%的peer引入系统。下图显示了联邦学习相比的测试误差。
结果表明,对于这两个数据集,有毒的联邦学习部署很难收敛,Biscotti在测试集中的性能与基线无投毒FL部署一样好。说明Biscotti能有效抵抗这种攻击,而普通的FL无法抵抗这种攻击。

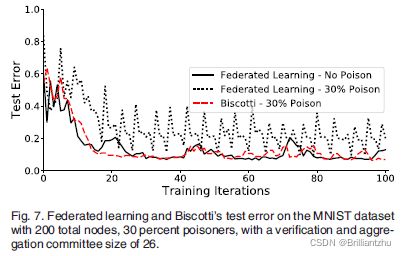
为证明委员会规模对攻击下收敛性的影响,作者用26个peers的更大验证和聚合委员会的MNIST数据集来分析,该数据集足够大,可以对控制系统30%stake的敌手提供保护。
由于在验证或聚合委员会中的peer在该轮中没有贡献更新,100个peers不能生成70%的更新来防止Multi-krum。因此,在这个实验中,将节点数增加到了200个。如下图
结果表明,Biscotti具有更大的验证和聚合委员会时,其收敛的迭代次数与未中毒的联邦学习相同。
6.2 性能、可伸缩性和容错
评估随着peer数量的增加,每个阶段的开销变化。衡量不同委员会规模时,对Biscotti的性能影响,以及参与方退出对Biscotti收敛性的影响
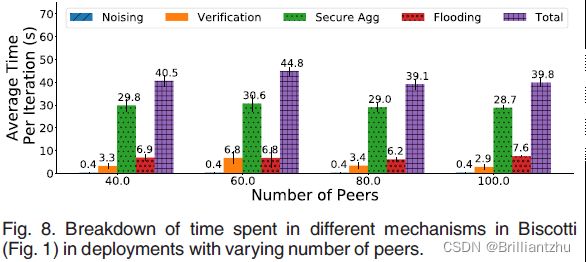
- 1)性能成分析:如下图,从噪声客户端收集的噪声,通过Multi-krum验证和签名收集和SGD更新的安全聚合。显示了在3次运行中部署40、60、80和100个节点时,每个阶段的每次迭代的评价成本。
结果表明,参与方数量的增加对各阶段时间性能的影响几乎不变。
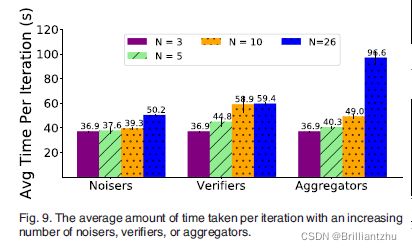
- 2)委员会规模扩大:MNIST数据集大小固定未100个peers,只改变每个SGD更新所需的噪声数,每个验证委员会使用的验证数量,以及安全聚合中的聚合数量。
结果表明,随着委员会规模的增大,每次迭代所需的花费的平均时间也会增加。
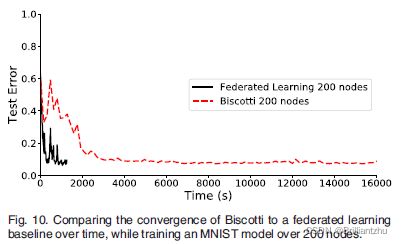
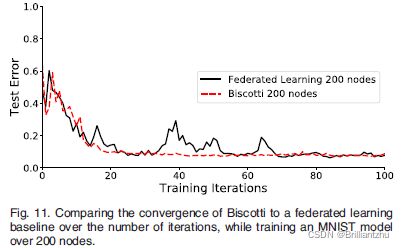
- 3)基线性能:将Biscotti与原始联邦学习基线进行比较,使用5个噪声者、26个验证者和26个聚合者。经过100次迭代,Biscotti和FL都接近全局模型最优。
结果表明,Biscotti划分时间是联邦学习的13.8倍,但在相同的100次迭代后获得了相似的模型性能,92%的准确率。
- 4)参与方退出的训练影响:Biscotti的P2P设计的一个关键特征是,对参与peer的退出具有弹性。也就是说,任何节点的故障都不会阻塞或阻止系统收敛。评估了Biscotti通过运行Credit Card部署50个peers对peer流失的弹性。
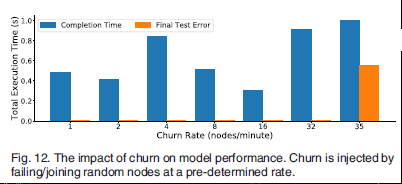
结果表明,当验证其和聚合器失败时,Biscotti默认在超时后进入下次迭代,故不影响收敛。当流失率增加到35个peers/分钟时,系统不会收敛。从下图可知,Biscotti对32个peers/分钟的流失是有弹性的。
四、总结
本文与之前的工作不同,Biscotti不依赖集中的服务、可信的执行环境或专门的硬件来提供针对对手的防御。本文的实验做的比较多,但是个人知识匮乏,还有许多没读懂的地方。例如,如何实现哈希环的构造和执行等。本文还提供了源代码网址如下,希望后期能学一学复现。
https://github.com/DistributedML/Biscotti