机器学习模型部署—PMML
之前阐述了逻辑回归、孤立森林等建模方法,本文介绍如何把建好的模型保存为标准格式(PMML文件)。那么,什么情况下需要把模型保存为PMML文件?
当模型需要跨平台部署或反复调用时,可以把模型保存为PMML文件。比如最近要上线一个反欺诈模型(用的GBDT)。训练模型用的Python(里面有很多现成的库,构建机器学习模型较方便),生产调用用的Java(写机器学习模型非常麻烦)。这时需要在Python中把训练好的模型保存为PMML文件,到Java中直接调用预测。
文章目录
-
-
- 一、什么是PMML
- 二、Python中模型保存为PMML的标准格式
- 三、实例一:把GBDT模型保存为PMML文件
-
- 1 导入数据
- 2 取出建模所需的变量
- 3 训练模型并保存为PMML文件
- 四、实例二:把随机森林模型保存为PMML
-
- 1 加载包
- 2 按标准流程建模并导出PMML文件
- 五、PMML的优缺点
-
- 1 优点
- 2 缺点
-
一、什么是PMML
PMML(Predictive Model Markup Language):预测模型标记语言,它用XML格式来描述生成的机器学习模型,是目前表示机器学习模型的实际标准。若要将在Python中训练好的模型部署到生产上时,可以使用目标环境解析PMML文件的库来加载模型,并做预测。
二、Python中模型保存为PMML的标准格式
Python中把模型导出为PMML文件的一般流程如下:
- step1:特征处理(DataFrameMapper函数)。
- step2:训练模型(pipeline函数)。
- step3:导出模型(sklearn2pmml函数)。
其中step1不是必须步骤。接下来看两个具体实例。
三、实例一:把GBDT模型保存为PMML文件
1 导入数据
首先导入建模所需数据。
# coding: utf-8
import os
import pandas as pd #导入数据处理的库
import numpy as np #导入数据处理的
os.chdir(r'F:\微信公众号\Python\40_机器学习模型导出为PMML文件')
data = pd.read_csv('testtdmodel.csv',sep=',',encoding='gb18030')
注:如需本文数据实现所有代码,可到公众号中回复“PMML”,即可免费获取。
2 取出建模所需的变量
本文选取了8个自变量,1个因变量进行建模。
columns_model = [
'1个月内借款人身份证申请借款平台数',
'3个月内关联P2P网贷平台数',
'3个月内申请人关联融资租赁平台数',
'3个月手机号关联身份证数',
'7天内关联P2P网贷平台数',
'二度风险名单个数',
'是否命中身份证风险关注名单',
'一度风险名单个数'
]
X_model = data[columns_model]
y = data['y']
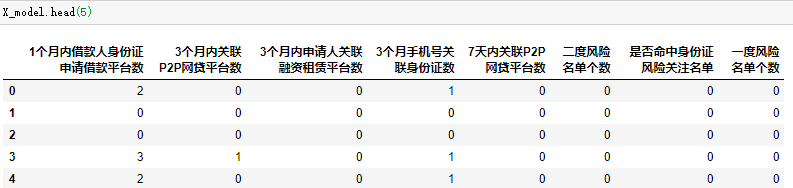
X_model具体格式如下:
3 训练模型并保存为PMML文件
在实例一中没有进行特征处理(step1),直接训练模型并导出PMML文件。
from sklearn import tree
from sklearn.model_selection import train_test_split
from sklearn2pmml import PMMLPipeline, sklearn2pmml
from sklearn.ensemble import GradientBoostingClassifier
train, test, train_labels, test_labels = train_test_split(X_model, y, test_size=0.2, random_state=0)
GBDT = GradientBoostingClassifier(random_state=9,max_depth=5,min_samples_split=10)
pipeline = PMMLPipeline([
("classifier", GBDT)
])
pipeline.fit(train, train_labels)
sklearn2pmml(pipeline, 'GBDT1.pmml', with_repr=True, debug=True)
参数详解:
train_test_split:把模型数据按test_size的比例生成训练集和测试集。
GBDT:建模所用方法,里面的参数可自行调整。
random_state:随机种子。
max_depth:树的最大深度。
min_samples_split:限制子树继续划分的条件,如果某节点的样本数目小于此值,则不会再继续划分。
pipeline.fit:训练模型,train代表自变量,train_labels代表因变量。
sklearn2pmml:把模型保存为PMML文件。
得到部分结果如下:

四、实例二:把随机森林模型保存为PMML
本例数据和实例一相同,就不赘述了。本例按Python中把模型导出为PMML文件的一般流程进行。
1 加载包
首先导入数据预处理和建模所需的包。
import numpy as np
import pandas as pd
from sklearn.ensemble import RandomForestClassifier
from sklearn.datasets import load_iris
from sklearn.ensemble import GradientBoostingClassifier
from sklearn2pmml import sklearn2pmml, PMMLPipeline
from sklearn2pmml.decoration import ContinuousDomain
from sklearn.feature_selection import SelectKBest
# frameworks for ML
from sklearn_pandas import DataFrameMapper
from sklearn.pipeline import make_pipeline
# transformers for category variables
from sklearn.preprocessing import LabelBinarizer
from sklearn.preprocessing import MultiLabelBinarizer
from sklearn.preprocessing import LabelEncoder
from sklearn.preprocessing import OneHotEncoder
#from sklearn.preprocessing import Imputer
from sklearn.impute import SimpleImputer
# transformers for numerical variables
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import Normalizer
# transformers for combined variables
from sklearn.decomposition import PCA
from sklearn.preprocessing import PolynomialFeatures
# user-defined transformers
from sklearn.preprocessing import FunctionTransformer
2 按标准流程建模并导出PMML文件
本文选取了8个自变量和一个因变量进行建模,并对其中4个变量进行数据处理。
#step1:特征工程
mapper = DataFrameMapper([
(['1个月内借款人身份证申请借款平台数'],FunctionTransformer(np.abs)),
(['3个月内关联P2P网贷平台数'],OneHotEncoder()),
(['7天内关联P2P网贷平台数', '二度风险名单个数'], [MinMaxScaler(),StandardScaler()])
])
iris_pipeline = PMMLPipeline([
("mapper", mapper),
("pca", PCA(n_components=3)),
("selector", SelectKBest(k=2)), #返回k个最佳特征
("classifier", RandomForestClassifier())])
#step2:训练模型
iris_pipeline.fit(X_model,y)
#step3:导出模型到 RandomForestClassifier_Iris.pmml 文件
sklearn2pmml(iris_pipeline, "RandomForestClassifier_Iris.pmml")
参数详解:
DataFrameMapper:进行数据预处理。
np.abs:对该列进行绝对值处理。
OneHotEncoder:对该列进行one-hot编码。
MinMaxScaler:对该列进行标准化处理(min max 归一化)。
PCA:主成分分析。
RandomForestClassifier:随机森林建模。
iris_pipeline.fit:用通道中设定的方法训练模型。
sklearn2pmml:把通道中训练好的模型保存为PMML文件。
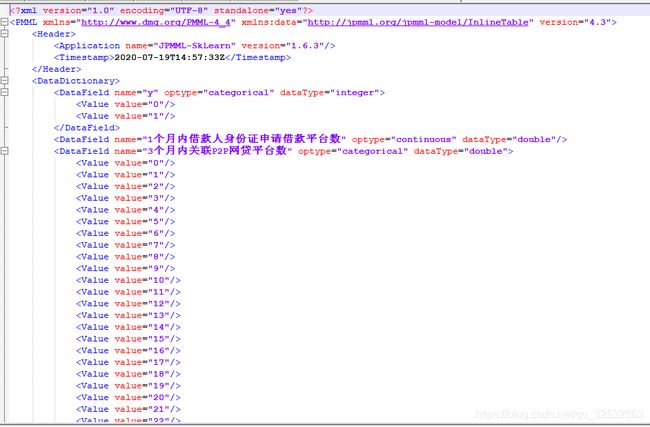
生成的PMML文件内容如下:
如果模型训练和预测用同一种语言,我认为没必要使用PMML。因为R、Python等语言都有标准的输出格式可以直接加载。比如在Python中训练了GBDT模型,模型还没有上线,需每天手工打样验证。可以用pickle函数把模型打包,之后要使用直接加载就可以了。
如果训练环境和预测环境不一样,在生产上安装(R、Python、Spark等)不方便,可以使用PMML文件的方式,在生成环境直接读取PMML获得训练后的模型。
五、PMML的优缺点
1 优点
1. 平台无关性。PMML采用标准的XML格式保存模型,可以实现跨平台部署。
2. 广泛的支持性。很多常用的开源模型都可以转换成PMML文件。
3. 易读性。PMML模型文件是一个基于XML的文本文件,任意文本编辑器都可以打开查阅。
2 缺点
1. 对数据预处理的支持有限。 虽然已经支持了几乎所有的标准数据处理方式,但是对于自拓展的方法,还缺乏有效支持。
2. 模型类型支持有限。 缺乏对深度学习模型的支持。
3. 预测会有一点偏差。 因为PMML格式的通用性,会损失特殊模型的特殊优化。
比如一个样本,用sklearn的决策树模型预测为类别2,但是我们把这个决策树保存为PMML文件,并用JAVA加载后,继续预测刚才这个样本,有较小的概率出现预测的结果不为类别2。
你可能感兴趣:
用Python绘制皮卡丘
用Python绘制词云图
Python人脸识别—我的眼里只有你
Python画好看的星空图(唯美的背景)
用Python中的py2neo库操作neo4j,搭建关联图谱
Python浪漫表白源码合集(爱心、玫瑰花、照片墙、星空下的告白)
