王喆<深度学习推荐系统实战>之推荐模型篇学习笔记
一、协同过滤
1.在 MovieLens 数据集中,不同用户对物品打分的标准不尽相同。比如说,有的人可能爱打高分,评价的影片得分都在 4 分以上,有的人爱打低分,大部分影片都在 3 分以下。你觉得这样的偏好对于推荐结果有影响吗?我们能不能在算法中消除这种偏好呢?
答:在生成共现矩阵的时候对用户的评分进行用户级别的校正或者归一化,用当前得分减去用户平均得分作为共现矩阵里面的值。消除用户评分偏差可以根据用户的平均评分标准化,即原始向量【x1,x2,x3】变成【x1-xp,x2-xp,x3-xp】,这样有利于弱化个人评分标准不同的影响。或者,对用用户打分做归一化处理(cur-average)/(max_min)
2.老师您好,业务的指标是给不同用户推送可能点击概率比较大的广告,提高不同用户对不同广告的点击率,我这边是利用CTR模型来做的,预测每个用户点击某一个广告的概率,最后发现对于不同的广告,点击概率>0.5的人群重合度很大,目前分析有两个原因,一是测试所用的广告标签类似,导致可能点击用户群体相同;二是最可能的,就是喜欢点击广告的,就是那一波人,另外一波人无论什么广告都没有兴趣点击。老师有遇到过这种情况吗?是怎么解决的?
答:这是一个非常好的业界问题。我之前也是做计算广告的,确实有过类似的经历。我感觉从数据上说,第二个原因的可能性非常大,你其实可以分析一下原始的数据,是不是说点击人群的范围确实比较小。
至于解决方法我建议从特征设计的角度入手,看看能不能加入一些能增强模型泛化能力的特征,比如大家都有的一些人口属性特征,广告的分类结构特征之类的,希望能把特定人群的一些行为泛化出去。
3.老师,我这边做点击推荐的时候正负样本比例相差很大,除了随机抽样负样本,还有什么比较好的办法呢
答:其实没有什么magic,工作中常用的就是负样本欠采样,和正样本过采样,或者增大正样本学习的权重。
还有一种方法叫SMOTE,可以搜一下,大致意思是通过合成的方式过采样正样本。可以尝试但有一定风险
4.请问老师,MF如何做到迭代增量训练模型呢?每天全量更新做不到的情况下,只针对每天生产出的新数据训练是否会导致效果变差,比如更新了一部分item的向量从而影响到原本的相对距离。
答:MF没法做增量更新,新数据来了之后,共现矩阵都变了,整个求解的目标都变了,只能全量更新。
5.请问老师如果有上亿user和上亿item也能矩阵分解吗?这需要创建一个1亿*1亿的矩阵。工业界对此是如何处理的。
答:其实大家用的都是稀疏矩阵,不可能真正建立一个1亿*1亿的稠密矩阵。而且运算的时候是只对非零的部分做运算,并没有想象中运算量那么大。
6.embedding中用户的embedding是由用户所喜欢的物品的embedding计算获得,所以用户的embedding会和他喜欢的物品embedding相似。
但是矩阵分解的损失函数只保证“用户矩阵和物品矩阵的乘积尽量接近原来的共现矩阵”,那怎么保证分解后的用户隐向量和用户喜欢的物品的隐向量相似呢
答:当然不能保证矩阵分解中的用户向量和物品向量相似,而就是希望得到用户对物品的打分,再根据打分来进行排名。
7.1. 对于隐式行为,如果正反馈为1, 负反馈和无交互都取0会不会有问题?模型如何区分到底是没看过还是不喜欢?
2. 如果数据是视频的播放完成率,能不能把这个隐式行为分箱到1至5的rating再去做als( implicitPrefs=False)
答:1. 非常好的点,这其实就是默认值选取的问题。理论上没必要只选取0或者1,可以多尝试不同的默认值选取。
2.完全可以
二、深度学习模型
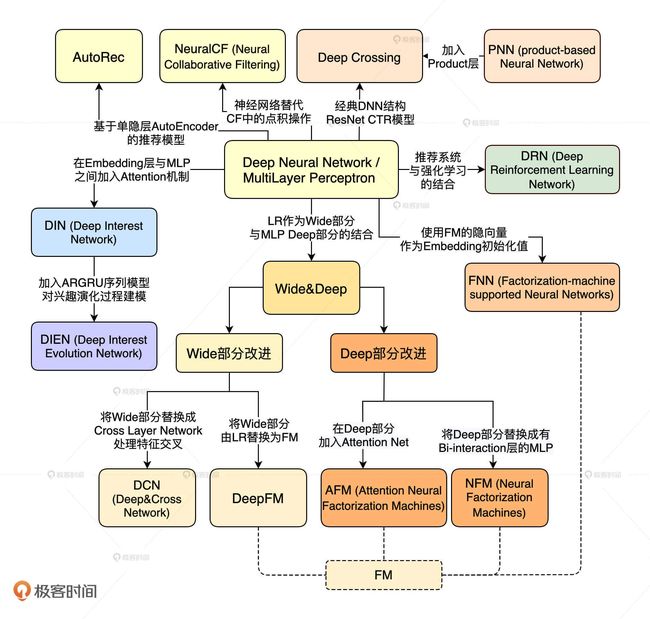

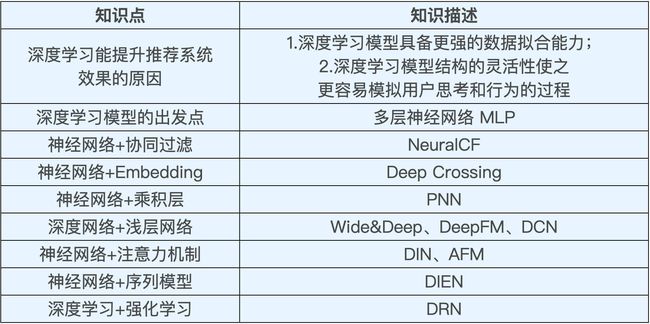
1.算法选型一定是与业务相关的,按照老师的说法就是没有银弹。比如阿里的购买序列是具有一定的所谓演化的概念的,但不适合feed信息流,feed的兴趣相对会比较稳定。但在结合业务特点情况下选择以后的模型优化好了是大概率有不错的效果提升的。
答:说的太好了,关于信息流和电商的思考也很好,推荐其他同学参考。
2.老师,想请教下,一般深度学习线上serving的方式是怎么来做的呢,如果用原生的tf-serving的方式,耗时有点久
答:之前我们有专门的一节课讲model serving,介绍了四五种方法,就是我们现在最主流的方式。
谈到tf serving,确实有这个问题,我们实践中同样有这个问题。就两种主流方案,一种是把模型拆了,复杂部分离线算,线上部分保持简单结构,用embedding连接两部分。
第二种是魔改tf serving,需要从源码入手,把其中一些复杂运算和没必要的操作去掉。
3.适合算法(选型、调参)+数据结构(数据准备)+业务场景(流程变动)=推荐系统优化。
首先从算法自身,在MLP层数是较多情况下,模型复杂度越高越精确,相对计算时间也越长久,但是实际的业务与数据,只需要2层的MLP,那么还不如Emmbedding+MLP简单层效果。
其次业务场景出发,不是所有的算法都是公司的业务,现有公司的业务数据就是这样,DIEN模型是因为阿里具有强大的大数据采集处理能力平台架构,用户行为变化的能力可以完全捕捉,才能实现Attention机制深度推荐系统,那么你公司现有架构能有这样超强能力吗?
最后,算法千千万,业务效益为王!了解各个算法的特性原理是每个算法工程师必修道路!
4.归根结底,这个世界数据为王,优秀的数据源+基于业务的特征工程足可以抹平一些“高级”深度模型带来的优势。当然推荐系统算法工程师肯定是想不断的尝试新的技术,毕竟工作和产品是公司的,事业和技术是自己的。但是,产品经理和项目经理不是这么想的,提高利润,降低成本,这是他们的业绩指标也是公司的核心利益。
所以一定要和团队上下把产品的优化目标协商好,不然就是出力不讨好了,工作成果得不到认可,这种挫败感可不好受。 要反复确定系统的评价指标,这个对系统的运维很重要。然后设计模型落地部署,做AB测试,用实际的运行结果说话,这样大家可以相互理解,管理团队和研发团队也都顺心。
5.请问老师,DIN模型中的注意力激活单元(两个输入向量拼合两个输入向量的差,然后输入到全连阶层)的设计思路是基于什么呀?两个向量按元素相减代表什么,为什么要这样设计?
答:其实只是创造一些两个embedding交互的操作,不要过多寻求可解释性的东西。强行解释的话,element wise minus也是一种表达相似度的操作。
6.一般来说,我们不会人为预设哪个特征有用,哪个特征无用,而是让模型自己去判断,如果一个特征的加入没有提升模型效果,我们再去除这个特征。就像我刚才虽然提取了不少特征,但并不是说每个模型都会使用全部的特征,而是根据模型结构、模型效果有针对性地部分使用它们。
7.不能引入未来信息(未来信息偏差)
刚才我们说到有一个用户特征叫做用户平均评分(userAvgRating),我们通过把用户评论过的电影评分取均值得到它。假设,一个用户今年评论过三部电影,分别是 11 月 1 日评价电影 A,评分为 3 分,11 月 2 日评价电影 B,评分为 4 分,11 月 3 日评价电影 C,评分为 5 分。如果让你利用电影 B 这条评价记录生成样本,样本中 userAvgRating 这个特征的值应该取多少呢?有的同学会说,应该取评价过的电影评分的均值啊,(3+4+5)/3=4 分,应该取 4 分啊。这就错了,因为在样本 B 发生的时候,样本 C 还未产生啊,它属于未来信息,你怎么能把 C 的评分也加进去计算呢?而且样本 B 的评分也不应该加进去,因为 userAvgRating 指的是历史评分均值,B 的评分是我们要预估的值,也不可以加到历史评分中去,所以正确答案是 3 分,我们只能考虑电影 A 的评分。

避免引入未来特征的方法2:线上会组装当前访问时的历史序列及历史平均值等,可以利用flink实时落盘这些线上特征,这样线下就不用再离线生成,也就杜绝了特征穿越问题
8.老师好,想问下使用hset把用户和物品的特征存入redis的场景下,如果用户上亿物品也上亿的话,存入redis会使用很大的资源。实际场景下并不是所有用户都是活跃用户,很多情况下可能用不上。那是否是在redis只存入活跃用户的特征呢?但是如果这样解决,遇到非活跃用户是否就没有特征值了?
从您的实践经验里有什么好的方法吗?
答:我在存储模块那节课说过,SparrowRecsys项目确实对存储模块进行了一定程度的简化,实际应用中还是要多考虑分级存储,redis实际上当作一个缓存层来使用。
关于大量数据key value数据的存储和线上查找,可以多调研rocksdb,cassandra,dynamodb和mongodb
9.把评分大于等于 3.5 分的样本标签标识为 1,意为“喜欢”,评分小于 3.5 分的样本标签标识为 0,意为“不喜欢”。这样可以完全把推荐问题转换为 CTR 预估问题。请问老师,3.5分这个值是怎么来的呢?
另外一个问题,我们把评分时间戳作为代表时间场景的特征放到特征工程中。请问把时间戳用于特征工程,有木有需要注意的地方?比如是否是周末,假日等?老师在实际应用中有哪些实践么?
答:两个问题都很好,希望大家都有这样实践中的思考。
第一个问题。基本原则是我在分析完分数的总体分布后得出的,3.5分基本是正负样本比例1:1的分界线,另外大于3.5分也符合我们直观意义上的高分,所以认为3.5分是比较合理的。
第二个问题。确实像你说的这样,我们实践中经常从时间戳中提取出周末,假日,季节这些特征,因为这些时间特征往往影响着数据的一些潜在模式,所以还是非常有价值的。
10.老师好,我想问下用户行为的时间序列,最一开始的那个用户行为的历史数据我们都是置0吗?比如您上面所说的“userAvgRating”,在B上是填A的打分3,那么在A上呢?因为这里收集到的信息A是最前面的,那此时就是置为0吗?还是说可以选一个全局中值填进去呢?
答:这是个好问题,涉及到默认值选取的问题。常规做法是把全局的均值填进去,但其实没有什么统一的最好的方法。
三、 Embedding+MLP
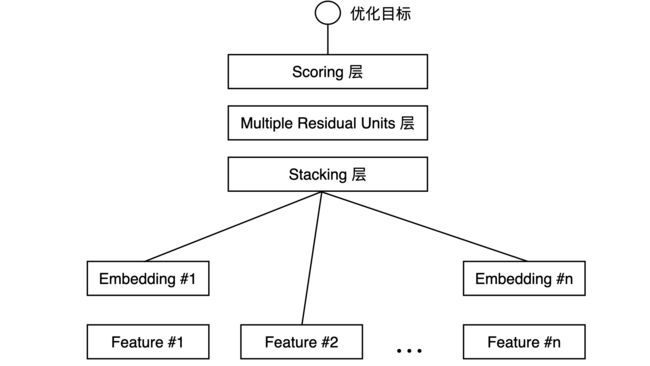
思考题:在我们实现的 Embedding+MLP 模型中,也有用户 Embedding 层和物品 Embedding 层。你觉得从这两个 Embedding 层中,抽取出来的用户和物品 Embedding,能直接用来计算用户和物品之间的相似度吗?为什么?
答:无法直接计算相似度. user embedding 和 item embedding 虽然输入数据来源自同一个数据集,但是本身并不在一个向量空间内.
(有直接的交互,才能算在一个向量空间。)
如果这个模型的结构变一下,把拼接操作变成user emb点乘item emb直接得到预测评分,那训练出来user emb和item emb就在一个向量空间了.
问题1.
1.看了您实现的MLPRecModel, 由于对tf2.x 版本不是很熟悉,没有看出来 是否 针对 发布时间、电影阅读数等等统计字段 进行了 标准化,
我当时用keras 实现了一下,没有对统计特征进行标准化,效果很差,只有56%左右,损失一直不降,然后最那些统计指标进行标准化话,训练完第一轮,测试集就能达到73%。
2. 您这次实现的MLPRecModel,针对用户、电影,先直接给出的初始化Embedding,然后训练对应的Embedding 权重,
在训练集中,假如 一个用户 有10条样本数据集,那么模型训练该用户Embedding 是根据这10条数据最终训练成能表示该用户Embedding吗?
数据集特征中, 针对一条样本,没有特征表示: 用户历史观看电影 【电影1,电影2 电影 3。。。】(按照时间排序) 这样一条特征,对训练Embedding有影响吗,我总感觉好像丢了这部分信息。
答:1. 确实没有加normalization,当然可以在tensorflow预处理时候加上normalization,或者在spark中生成训练样本的时候加上特征预处理的一些操作,没问题。而且也确实推荐在实际工作中尝试用normalization,bucketize,maxminscaling去做不同的预处理查看效果,这一点我们之前在特征工程部分介绍过。
2.是个好问题,如果embedidng层是在模型中,通过e2e训练的,那么你如果细致的理解梯度下降的过程就知道,某个用户的embedding确实是只用TA自己的历史数据生成的。
这样的弊端当然有,就是收敛慢,而且在用户历史行为过少的时候,这个用户的embedding不稳定。所以也可以采用embedding预训练的方式,就像我们之前embedding部分讲解的。
问题2
老师好,最近正好在做dssm,其中的好几个有疑惑的点一起讨论
1. 当id类特征,比如movieId和userId数量很大时,目前userId大概每天有1000w级别。我选择了先使用hash_bucket来做散列,然后再压缩到300维的embedding。但是我对这种方法有怀疑,就是这么大的数量,会不会出现大量的冲突。这样对准确性是不是有影响。
2. mlp的每层的维度如何确定,是越大越好,还是越小越好。
3. 模型特征可选的目前大概有几千个,如何从中选出重要性最大的特征呢?
答:作者回复: 1. 会有冲突,在硬件允许情况下,最好把hashbucket数量加大。
2. 自己调参,一般不建议非常大
3. 经典面试题,自己去搜一下相关资料。