ICCV 2021口罩人物身份鉴别全球挑战赛冠军方案分享

1. 引言
10月11-17日,万众期待的国际计算机视觉大会 ICCV 2021 (International Conference on Computer Vision) 在线上如期举行,受到全球计算机视觉领域研究者的广泛关注。
今年阿里云多媒体 AI 团队(由阿里云视频云和达摩院视觉团队组成)参加了 MFR 口罩人物身份鉴别全球挑战赛,并在总共5个赛道中,一举拿下1个冠军、1个亚军和2个季军,展现了我们在人物身份鉴别领域深厚的技术积淀和业界领先的技术优势。
2. 竞赛介绍
MFR口罩人物身份鉴别全球挑战赛是由帝国理工学院、清华大学和InsightFace.AI联合举办的一次全球范围内的挑战赛,主要为了解决新冠疫情期间佩戴口罩给人物身份鉴别算法带来的挑战。竞赛从6月1日开始至10月11日结束,历时4个多月,共吸引了来自全球近400支队伍参赛,是目前为止人物身份鉴别领域规模最大、参与人数最多的权威赛事。据官方统计,此次竞赛收到的总提交次数超过10000次,各支队伍竞争异常激烈。
2.1 训练数据集
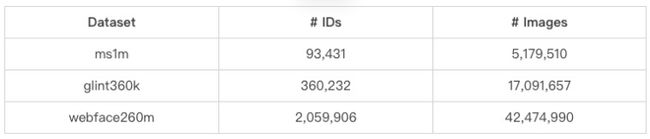
此次竞赛的训练数据集只能使用官方提供的3个数据集,不允许使用其它额外数据集以及预训练模型,以保证各算法对比的公平公正性。官方提供的3个数据集,分别是ms1m小规模数据集、glint360k中等规模数据集和webface260m大规模数据集,各数据集包含的人物ID数和图片数如下表所示:
2.2 评测数据集
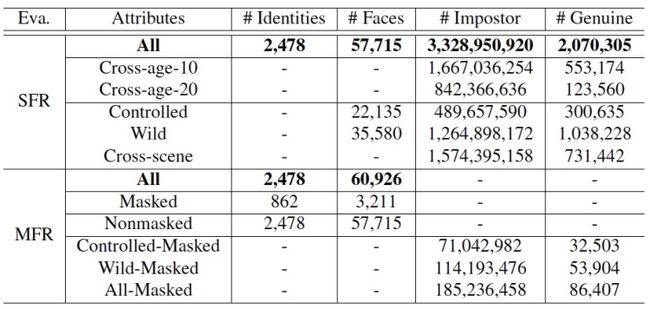
此次竞赛的评测数据集包含的正负样本对规模在万亿量级,是当前业界规模最大、包含信息最全的权威评测数据集。值得注意的是所有评测数据集均不对外开放,只提供接口在后台进行自动测评,避免算法过拟合测试数据集。
InsightFace赛道评测数据集的详细统计信息如下表所示:

WebFace260M赛道评测数据集的详细统计信息如下表所示:
2.3 评测指标
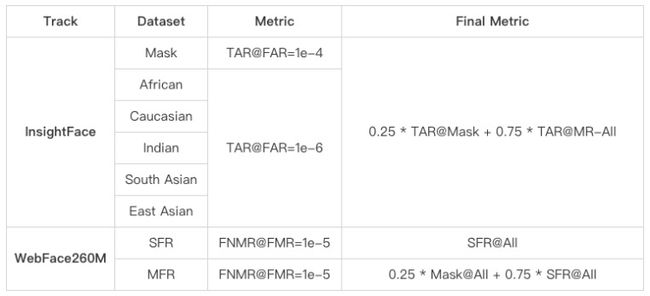
此次竞赛的评测指标不仅有性能方面的指标,而且还包含特征维度和推理时间的限制,因此更加贴近真实业务场景。详细的评测指标如下表所示:

3. 解决方案
下面,我们将从数据、模型、损失函数等方面,对我们的解决方案进行逐一解构。
3.1 基于自学习的数据清洗
众所周知,人物身份鉴别相关的训练数据集中广泛存在着噪声数据,例如同一人物图片分散到不同人物ID下、多个人物图片混合在同一人物ID下,数据集中的噪声会对识别模型的性能产生较大影响。针对上述问题,我们提出了基于自学习的数据清洗框架,如下图所示:
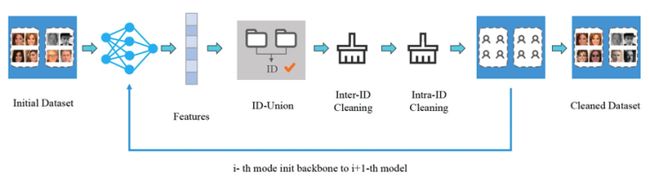
首先,我们使用原始数据训练初始模型M0,然后使用该模型进行特征提取、ID合并、类间清洗和类内清洗等一系列操作。对于每个人物ID,我们使用DBSCAN聚类算法去计算中心特征,然后使用中心特征进行相似度检索,这一步使用的高维向量特征检索引擎是达摩院自研的Proxima,它可以快速、精准地召回Doc中与Query记录相似度最高的topK个结果。紧接着,我们使用清洗完成的数据集,训练新的模型M1,然后重复数据清洗及新模型训练过程,通过不断进行迭代自学习方式,使得数据质量越来越高,模型性能也随之越来越强。具体来看,类间清洗和类内清洗的示意图如下图所示:

值得注意的是,我们的清洗流程中先进行类间清洗、再进行类内清洗,与CAST[1]数据清洗框架不同,这样在完成类间清洗后可以更新新的ID中心特征,使得整个清洗过程更加完备,清洗效果也更好。为了验证数据清洗对最终性能的影响,我们在ms1m数据集上做了一系列对比实验,结果如下表所示:
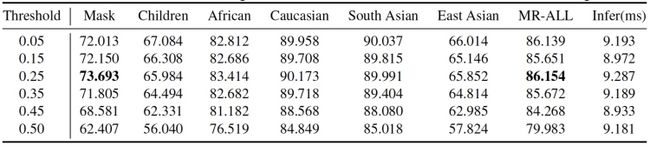
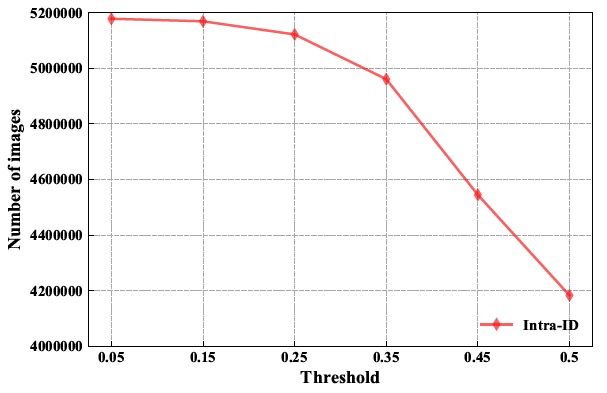
表中的阈值指的是类内清洗的相似度阈值,可以看出当阈值设置过低(如0.05)时,噪声没有被清洗干净,因此性能表现不是最佳;而当阈值设置过高(如0.50)时,噪声被清洗的同时难样本也被清洗了,导致模型泛化能力变弱,在评测数据集上性能反而下降。因此选择一个中间阈值0.25,既清洗了大量噪声,又保留了困难样本,在各项评测指标上均达到最佳性能。此外,我们还画出了不同相似度阈值与剩余图片数的关系,如下图所示:
3.2 戴口罩数据生成
为解决戴口罩数据不足的问题,一种可行的方案是在已有的无口罩图像上绘制口罩。然而,目前大部分的绘制方案属于位置贴图式,这种方案生成的戴口罩图像不够真实且缺乏灵活性。因此,我们借鉴PRNet[2,3]的思路,采用一种图像融合方案[4]来获取更符合真实情况的戴口罩图像,如下图所示,
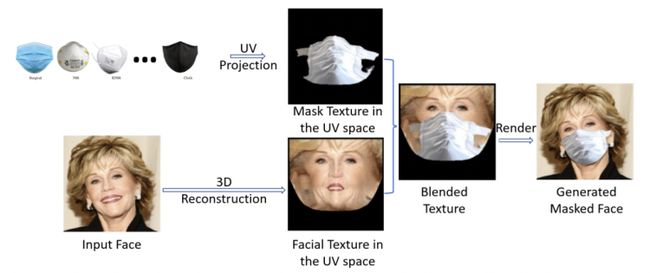
该方案的原理是将口罩图像和原图像通过3D重建分别生成UV Texture Map,然后借助纹理空间合成戴口罩图像。在数据生成过程中,我们使用了8种类型的口罩,意味着我们可在已有的数据集上对应生成8种不同风格的戴口罩图像。基于UV映射的方案克服了传统平面投影方式中原图像和口罩图像间的不理想衔接和变形等问题。此外,由于渲染过程的存在,戴口罩图像可以获得不同的渲染效果,比如调整口罩角度及光照效果等。生成的戴口罩图像示例如下图所示:

在生成戴口罩数据训练模型的过程中,我们发现戴口罩数据的比例对模型性能有不同程度的影响。因此,我们将戴口罩数据占比分别设置为5%、10%、15%、20%和25%,实验结果如下表所示:

从上表中发现,当戴口罩数据比例为5%时,模型在MR-ALL评测集上的性能最高;当戴口罩数据比例调整至25%时,对Mask戴口罩评测集的性能提升明显,但在MR-ALL上的性能下降明显。这说明当混合戴口罩数据和正常数据进行训练时,其比例是影响模型性能的重要参数。最终,我们选择戴口罩数据比例为15%,在戴口罩和正常数据上的性能达到一个较好平衡。
3.3 基于NAS的骨干网络
不同骨干网络对特征提取的能力差异较大,在人物身份鉴别领域,业界常用的基线骨干网络是在ArcFace[5]中提出的IR-100。在此次竞赛中,我们采用达摩院提出的Zero-shot NAS (Zen-NAS[6]) 范式,在模型空间搜索具有更强表征能力的骨干网络。Zen-NAS区别于传统NAS方法,它使用Zen-Score代替搜索模型的性能评测分数,值得注意的是Zen-Score与模型最终的性能指标成正比关系,因此整个搜索过程非常高效。Zen-NAS的核心算法结构如下图所示:
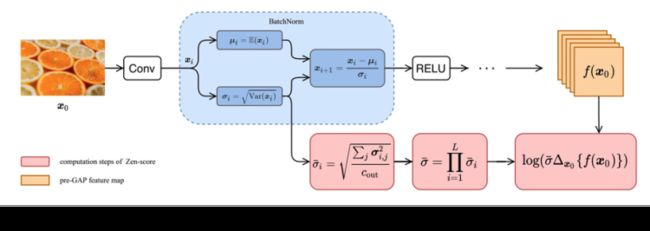
我们基于IR-SE基线骨干网络,使用Zen-NAS搜索3个模型结构相关的变量,分别是:Input层的通道数、Block层的通道数和不同Block层堆叠的次数,限制条件是搜索出的骨干网络满足各赛道的推理时间约束。一个有趣的发现是:Zen-NAS搜索出的骨干网络,在ms1m小数据集赛道上的性能表现与IR-SE-100几乎无差异,但在WebFace260M这样的大数据集赛道,性能表现会明显优于基线。原因可能是搜索空间增大后,NAS可搜索的范围随之增大,搜索到更强大模型的概率也随之增加。
3.4 损失函数
此次竞赛我们采用的基线损失函数为Curricular Loss[7],该损失函数在训练过程中模拟课程学习的思想,按照样本从易到难的顺序进行训练。然而,由于训练数据集通常是极度不平衡的,热门人物包含的图片数多达数千张,而冷门人物包含的图片数往往只有1张。为解决数据不均衡带来的长尾问题,我们将Balanced Softmax Loss[8]的思想引入Curricular Loss中,提出一个新的损失函数:Balanced Curricular Loss,其表达式如下图所示:
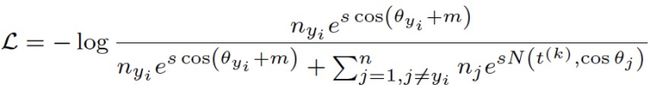
在ms1m赛道上,我们对比了Balanced Curricular Loss (BCL) 与原始Curricular Loss (CL) 的性能,结果如下表所示:
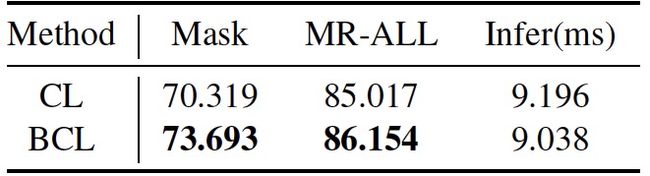
可以看出Balanced Curricular Loss相对于Curricular Loss,无论在Mask还是MR-ALL上的指标均有较大幅度的提升,充分证明了其有效性。
3.5 知识蒸馏
由于此次比赛对模型的推理时间有约束,模型超时会被直接取消成绩。因此,我们采用知识蒸馏的方式,将大模型强大的表征能力传递给小模型,然后使用小模型进行推理,以满足推理时间的要求。此次竞赛我们采用的知识蒸馏框架如下图所示:

其中,蒸馏损失采用最简单的L2 Loss,用以传递教师模型的特征信息,同时学生模型使用Balanced Curricular Loss训练,最终的损失函数是蒸馏损失与训练损失的加权和。经过知识蒸馏后,学生模型在评测数据集上的部分指标,甚至超过了教师模型,同时推理时间大大缩短,在ms1m小数据集赛道的性能有较大提升。
3.6 模型和数据同时并行
WebFace260M大数据集赛道的训练数据ID数量>200万、总图片数>4000万,导致传统的多机多卡数据并行训练方式已难以容纳完整的模型。Partial FC[9]采用将FC层均匀分散到不同GPU上,每个GPU负责计算存储在自己显存单元的sub FC层结果,最终通过所有GPU间的同步通信操作,得到近似的full FC层结果。Partial FC的示意图如下所示:
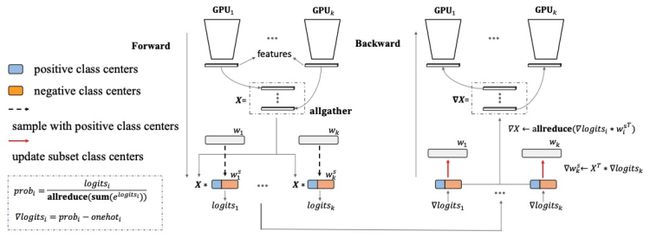
采用Partial FC,可同时使用模型并行与数据并行,使得之前无法训练的大模型可以正常训练,另外可采用负样本采样的方式,进一步加大训练的batch size,缩短模型训练周期。
3.7 其它技巧
在整个竞赛过程中,我们先后尝试了不同数据增强、标签重构及学习率改变等策略,其中有效的策略如下图所示:

4. 竞赛结果
此次竞赛我们mind_ft队在InsightFace和WebFace260M共5个赛道中获得1个冠军(WebFace260M SFR)、1个亚军(InsightFace unconstrained)和2个季军(WebFace260M Main和InsightFace ms1m)。其中,WebFace260M赛道官方排行榜的最终结果截图如下所示:

在竞赛结束之后的Workshop中,我们受邀在全球范围内分享此次竞赛的解决方案。此外,我们在此次竞赛中投稿的论文,也被同步收录于ICCV 2021 Workshop[10]。最后,展示一下我们在此次竞赛中收获的荣誉证书:

5. EssentialMC2介绍与开源
EssentialMC2,实体时空关系推理多媒体认知计算,是达摩院MinD-数智媒体组对于视频理解技术的一个长期研究结果沉淀的核心算法架构。核心内容包括表征学习MHRL、关系推理MECR2和开集学习MOSL3三大基础模块,三者分别对应从基础表征、关系推理和学习方法三个方面对视频理解算法框架进行优化。基于这三大基础模块,我们总结了一套适合于大规模视频理解算法研发训练的代码框架,并进行开源,开源工作中包含了组内近期发表的优秀论文和算法赛事结果。

essmc2是EssentialMC2配套的一整套适合大规模视频理解算法研发训练的深度学习训练框架代码包,开源的主要目标是希望提供大量可验证的算法和预训练模型,支持使用者以较低成本快速试错,同时希望在视频理解领域内建立一个有影响力的开源生态,吸引更多贡献者参与项目建设。essmc2的主要设计思路是“配置即对象”,通过简要明了的配置文件配合注册器的设计模式(Registry),可以将众多模型定义文件、优化器、数据集、预处理pipeline等参数以配置文件的形式快速构造出对象并使用,本质上贴合深度学习的日常使用中不断调参不断实验的场景。同时通过一致性的视角实现单机和分布式的无缝切换,使用者仅需定义一次,便可在单机单卡、单机多卡、分布式环境下进行切换,同时实现简单易用与高可移植性的特性。
目前essmc2的开源工作已经发布了第一个可用版本,欢迎大家试用,后续我们会增加更多算法和预训练模型。链接地址:https://github.com/alibaba/EssentialMC2。
6. 产品落地
随着互联网内容的视频化以及VR、元宇宙等应用的兴起,非结构化视频内容数量正在高速增长,如何对这些内容进行快速识别、准确理解,成为内容价值挖掘关键的一环。
人物是视频中的重要内容,高精度的视频人物身份鉴别技术,能够快速提取视频人物关键信息,实现人物片段剪辑、人物搜索等智能应用。另外,对于视频的视觉、语音、文字多维度内容进行分析理解,识别人、事、物、场、标识等更丰富的视频内容实体标签,可形成视频结构化信息,帮助更全面地提取视频关键信息。
更进一步,结构化的实体标签作为语义推理的基础,通过多模态信息融合,帮助理解视频核心内容,实现视频内容高层语义分析,进而实现类目、主题理解。
阿里云多媒体 AI 团队的高准确率人物身份鉴别及视频分析技术,已集成于EssentialMC2核心算法架构,并进行产品化输出,支持对视频、图像的多维度内容进行分析理解并输出结构化标签(点击进行体验:Retina视频云多媒体 AI 体验中心-智能标签产品 https://retina.aliyun.com/#/Label)。

多媒体AI产品
智能标签产品通过对视频中视觉、文字、语音、行为等信息进行综合分析,结合多模态信息融合及对齐技术,实现高准确率内容识别,综合视频类目分析结果,输出贴合视频内容的多维度场景化标签。
类目标签:实现视频内容高层语义分析,进而实现类目、主题的理解,视频分类标签,分为一级、二级和三级类目,实现媒资管理及个性化推荐应用。
实体标签:视频内容识别的实体标签,维度包括视频类目主题、影视综漫IP、人物、行为事件、物品、场景、标识、画面标签,同时支持人物、IP的知识图谱信息。其中,影视综漫的IP搜索基于视频指纹技术,将目标视频与库内的影视综等资源进行指纹比对检索,支持6万余部电影、电视剧、综艺、动漫、音乐的IP识别,可分析识别出目标视频内容中包含哪一部电影、电视剧等IP内容,帮助实现精准的个性化推荐、版权检索等应用。基于优酷、豆瓣、百科等各类型数据,构建了涵盖影视综、音乐、人物、地标、物体的信息图谱,对于视频识别命中的实体标签,支持输出知识图谱信息,可用于媒资关联及相关推荐等应用。
关键词标签:支持视频语音识别及视频OCR文字识别,结合NLP技术融合分析语音及文字的文本内容,输出与视频主题内容相关的关键词标签,用于精细化内容匹配推荐。

完善的标签体系、灵活的定制化能力
智能标签产品综合优酷、土豆、UC海外等平台的PGC、UGC视频内容进行学习、训练,提供最全面完善、高质量的视频标签体系。在提供通用的标签类目体系外,支持开放多层面定制化的能力,支持人脸自注册、自定义实体标签等扩展功能;面向客户特定标签体系的业务场景,采用标签映射、定制化训练等方式,提供一对一的标签定制服务,更有针对性地帮助客户解决平台的视频处理效率问题。
高品质人机协同服务
针对要求准确的业务场景,智能标签产品支持引入人工交互判断,形成高效、专业的人机协同平台服务,AI识别算法与人工相辅相成,提供面向个性化业务场景的精准视频标签。
人机协同体系具备先进的人机协同平台工具、专业的标注团队,通过人员培训、试运行、质检、验收环节等标准化的交付管理流程,确保数据标注质量,帮助快速实现高品质、低成本的标注数据服务。通过AI算法+人工的人机协同方式,提供人工标注服务作为AI算法的补充和修正,确保精准、高质量的服务输出结果,实现业务效率和用户体验的提升。

体育行业和影视行业的视频标签识别
传媒行业和电商行业的视频标签识别
以上能力均已集成到阿里云视频云智能标签产品,提供高品质的视频分析及人机协同服务,欢迎大家了解及体验试用(智能标签产品 https://retina.aliyun.com/#/Label),搭建更高效、智能化的视频业务应用。
参考文献:
[1] Zheng Zhu, et al. Webface260m: A benchmark unveilingthe power of million-scale deep face recognition. CVPR 2021.
[2] Yao Feng, et al. Joint 3d face reconstruction and dense alignment with position map regression network. ECCV, 2018.
[3] Jun Wang et al. Facex-zoo: A pytorch toolbox for face recognition. arxiv, abs/2101.04407, 2021.
[4] Jiankang Deng et al. Masked Face Recognition Challenge: The InsightFace Track Report. arXiv, abs/2108.08191, 2021.
[5] Jiankang Deng, et al. Arcface: Additive angular margin loss for deep face recognition. CVPR 2019.
[6] Ming Lin, et al. Zen-NAS: A Zero-Shot NAS for High-Performance Image Recognition. ICCV 2021.
[7] Yuge Huang et al. Curricularface: Adaptive curriculum learning loss for deep face recognition. CVPR 2020.
[8] Jiawei Ren et al. Balanced meta-softmax for long-tailed visual recognition. NeurIPS, 2020.
[9] Xiang An, et al. Partial fc: Training 10 million identities on a single machine. ICCV 2021.
[10] Tao Feng, et al. Towards Mask-robust Face Recognition. ICCV 2021.
「视频云技术」你最值得关注的音视频技术公众号,每周推送来自阿里云一线的实践技术文章,在这里与音视频领域一流工程师交流切磋。公众号后台回复【技术】可加入阿里云视频云产品技术交流群,和业内大咖一起探讨音视频技术,获取更多行业最新信息。