题目 全题解 2022年第十三届蓝桥杯省赛 C/C++b组 含解析
题目 全题解 2022年第十三届蓝桥杯省赛 C/C++b组 含解析
目录
- 题目 全题解 2022年第十三届蓝桥杯省赛 C/C++b组 含解析
- 试题 A: 九进制转十进制
- 试题 B: 顺子日期
- 试题 C: 刷题统计
-
- 方法一:二分答案
- 方法二:数学
- 试题 D: 修剪灌木
-
- 方法一:脑筋急转弯(划掉)
- 试题 E: X 进制减法
-
- 方法一:数学 + 贪心
- 试题 F: 统计子矩阵
-
- 方法一:前缀和 + 双指针
- 试题 G: 积木画
-
- 方法一:动态规划
-
- 空间优化
- 方法二:动态规划优化
- 方法三:矩阵快速幂
- 试题 H: 扫雷
-
- 方法一:BFS + 哈希表(待优化)
- 试题 I: 李白打酒加强版
-
- 方法一:动态规划
- 试题 J: 砍竹子
-
- 方法一:逆向思维
经过简单测试基本正确,测试网站
试题 A: 九进制转十进制

1478
(29^3+29+2=1478)
试题 B: 顺子日期

争议性很强的一个题,主要是012算还是321算
我这里按照012算来写的,14个
(20221012 20221123 20221230 20221231 2022012X(x为0~9)
试题 C: 刷题统计

方法一:二分答案
写了个蛇皮写法
#include方法二:数学
建议直接计算即可
#include试题 D: 修剪灌木

方法一:脑筋急转弯(划掉)
这个数据范围……含不含1啊,应该不含吧
含1要特判一下 输出1而不是0(但是这个范围……)
#include试题 E: X 进制减法


方法一:数学 + 贪心
用x进制做减法,然后按照最小进制转回10进制就行了,不知道理解的对不对
#include试题 F: 统计子矩阵


方法一:前缀和 + 双指针
枚举右下角坐标,用双指针找出左上的端点范围,计算可行的矩阵数量
#include复杂度分析
- 时间复杂度 O ( m n ( m + n ) ) O(mn (m+n)) O(mn(m+n)) 每一个右下角端点, 双指针最多移动 m + n m+n m+n 次
- 空间复杂度 O ( m n ) O(mn) O(mn)
试题 G: 积木画

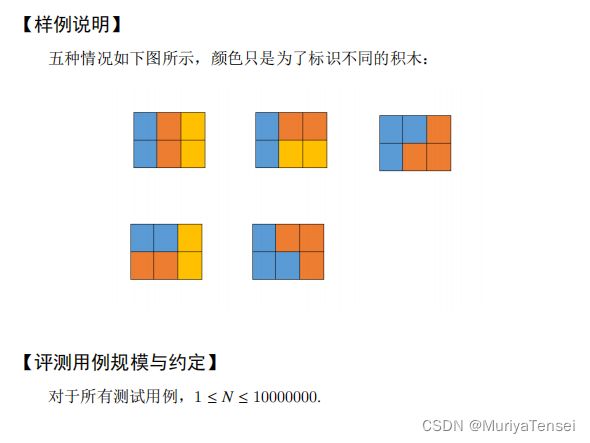
方法一:动态规划
设 f ( n ) f(n) f(n) 为 2 ∗ n 2*n 2∗n 大小的画布可行的方法数
自己画一画就能发现,
多一行可以加一块,
多两行可以立着的两块(另一个方向在多一行的部分计算过了)
多一行半加一块L
而一行半结尾的情况,又由 整行+L或 半行+I 转移而来
因此有
f ( x ) = f ( x − 1 ) + f ( x − 2 ) + g ( x − 2 ) f(x) = f(x-1) +f(x-2) + g(x-2) f(x)=f(x−1)+f(x−2)+g(x−2)
g ( x ) = g ( x − 1 ) + f ( x − 1 ) ∗ 2 g(x) = g(x-1) + f(x-1)*2 g(x)=g(x−1)+f(x−1)∗2
注意转移然后取模即可
#include复杂度分析
- 时间复杂度 O ( n ) O(n) O(n)
- 空间复杂度 O ( n ) O(n) O(n)
空间优化
可以进行如下空间优化,使得空间化为 O ( 1 ) O(1) O(1)
#include方法二:动态规划优化
把方法一中的式子化简
把②式不断代入①式消去g, 再把得到的式子③中的x替换为x-1得到④
③④左右分别作差后化简即可得到如下式子
f ( n ) = f ( n − 1 ) ∗ 2 + f ( n − 3 ) f(n) = f(n-1) * 2 + f(n-3) f(n)=f(n−1)∗2+f(n−3)
#include复杂度分析
- 时间复杂度 O ( n ) O(n) O(n)
- 空间复杂度 O ( 1 ) O(1) O(1)
方法三:矩阵快速幂
化简后的式子就可以用矩阵快速幂进行进一步优化(不过本题数据量1e7应该没太大必要)
#include复杂度分析
- 时间复杂度 O ( l o g ( n ) ) O(log(n)) O(log(n)) 实际上常数为运算四阶矩阵乘法所需 O ( 4 3 ) O(4^3) O(43)
- 空间复杂度 O ( 1 ) O(1) O(1)实际上常数为储存四阶矩阵乘法所需
试题 H: 扫雷


方法一:BFS + 哈希表(待优化)
模拟了下,似乎常数太大了,试了一个小时没降下去,极限用例无论如何都要 20s+(而民间测试中,应该是随机数据,可以极限过)
这里直接跑的BFS,但是还是差点意思,优化了好久
试过在map上二分优化,但是map又不能在查找过程中删除(会导致迭代器失效),所以效果比较有限
但是总感觉不应该爆,有没有大佬帮忙挑挑问题,是不是哪里删除失效了,或者错误插入了导致破坏了线性复杂度
感觉做的很暴力,极限对于半径均为10的5e4个雷和火箭 就会超时
最好的优化方法应该是自己手写哈希,大概能快10~30倍左右,就没问题了(蠢了,STL玩太多)
#include复杂度分析
- 时间复杂度 O ( ( m + n ) ∗ r 2 ) O((m + n)* r^2) O((m+n)∗r2) 至多遍历每个点(包括地雷和火箭)及其周围r^2的区域
- 空间复杂度 O ( m + n ) O(m + n) O(m+n)
试题 I: 李白打酒加强版


方法一:动态规划
三维dp, d p [ i ] [ j ] [ k ] dp[i][j][k] dp[i][j][k] 表示 剩余 i i i 次店、 j j j 次花 时 有 k k k 斗酒 的方法数
转移方法如代码所示,非常好理解
注意:最后返回的是 dp[0][1][1] 因为最后一次是花,因此最后剩余1次花1斗酒
这里懒得用vector开三维数组了,c++11自推导模板类型太菜了,写起来好麻烦,直接开全局数组了。
如果支持c++14我就继续vector了,开成 n+1 m+1 m+1三维即可
#include复杂度分析
- 时间复杂度 O ( n m 2 ) O(nm ^2) O(nm2) 注意到,酒的数量不能超过花(不然喝不完)因此,酒这一维上限与花一样即可
- 空间复杂度 O ( n m 2 ) O(nm^2) O(nm2)
试题 J: 砍竹子


不确定对不对,做的时候写错了个函数名,直接g了(样例过了,我自己测了两组也过了,但是考完又造了一组wa了……)
注意到,(数据范围内)最大的数 运行转换至多七次可以到1
那么我们处理出所有数字转化的路线,从小到大 合并连续相同的部分即可
方法一:逆向思维
#include复杂度分析
- 时间复杂度 O ( n ) O(n) O(n) 这里把7次视为常数了,因为数据范围是固定的
- 空间复杂度 O ( n ) O(n) O(n)