数据结构与算法系列笔记五:树
树的基础
1 树的基本概念
树:一种数据结构。是由n(n>=1)个有限结点组成一个具有层次关系的集合。
树具有以下特点:
- 每个结点有零个或多个子结点;
- 没有父结点的结点为根结点;
- 每一个非根结点只有一个父结点;
- 每个结点及其后代结点整体上可以看做是一棵树,称为当前结点的父结点的一个子树;
树的相关术语
结点的度:一个结点含有的子树的个数称为该结点的度;
- 树的度:树中所有结点的度的最大值
- 叶结点:度为0的结点称为叶节点,也可以叫做终端结点;
- 分支结点:度不为0的结点称为分支节点,也叫作非终端结点
结点的层次:从根结点开始,根结点的层次为1,根的直接后继层次为2,以此类推
- 树的高度(深度):树中结点的最大层次
结点的层序编号:将树中的结点,按照从上层到下层,同层从左到右的次序排成一个线性序列,把他们编成连续的自然数
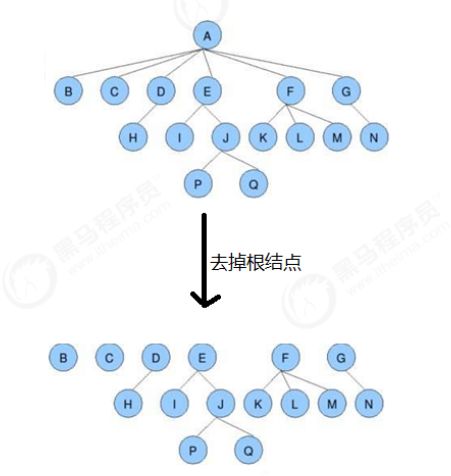
森林:m(m>=0)个互不相交的树的集合,将一颗非空树的根节点删去,树就变成一个森林;给森林增加一个统一的根节点,森林就变成一棵树。
2 二叉树的基本概念
二叉树:度不超过2的树(每个结点最多有两个子节点)
满二叉树:每一层的结点树都达到最大值
完全二叉树:叶节点只能出现在最下层和次下层,并且最下面一层的结点都集中在该层最左边的若干位置的二叉树
- 在二叉树的第i层至多有2i-1个结点
- 深度为k的二叉树至多有2k-1个结点
- 对任意一颗二叉树T,如果其终端结点数为n0,度为2的结点数为n2,则n0=n2+1
- 树的结点总数n=n0+n1+n2,分支线总数n-1=n1+2*n2,可推导出n0=n2+1
- 具有n个结点的完全二叉树的深度为 [log2n]+1([x]表示不大于x的最大整数)
- 2k-1-1
- 2k-1-1
3 二叉查找树的创建
二叉查找树API的实现
package study.algorithm.tree;
import com.sun.org.apache.regexp.internal.RE;
public class BinaryTree<Key extends Comparable<Key>, Value> {
//记录根节点
private Node root;
//记录树中元素的个数
private int N;
private class Node {
//记录左节点
public Node left;
//记录右节点
public Node right;
//存储键
public Key key;
//存储值
public Value value;
public Node(Key key, Value value, Node left, Node right) {
this.left = left;
this.right = right;
this.key = key;
this.value = value;
}
}
public int size() {
return N;
}
public boolean isEmpty() {
return N == 0;
}
public void put(Key key, Value value) {
root = put(root, key, value);
}
private Node put(Node x, Key key, Value value) {
//如果x子树为空
if (x == null) {
N++;
return new Node(key, value, null, null);
}
//如果x子树不为空
//比较x节点的键和key的大小
int cmp = key.compareTo(x.key);
if (cmp > 0) { //如果key大于节点的键,则继续找x节点的右子树
x.right = put(x.right, key, value);
} else if (cmp < 0) { //如果key小于节点的键,则继续找x节点的左子树
x.left = put(x.left, key, value);
} else { //如果key等于节点的键,则替换x节点的值为value即可
x.value = value;
}
return x;
}
public Value get(Key key) {
return get(root, key);
}
private Value get(Node x, Key key) {
//x树为null
if (x == null) {
return null;
}
//x树不为null
//比较key和x节点的键的大小
int cmp = key.compareTo(x.key);
if (cmp > 0) {
return get(x.right, key);
} else if (cmp < 0) {
return get(x.left, key);
} else {
return x.value;
}
}
public void delete(Key key) {
delete(root, key);
}
private Node delete(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp > 0) {
x.right = delete(x.right, key);
} else if (cmp < 0) {
x.left = delete(x.left, key);
} else {
N--;
if (x.right == null) {
return x.left;
}
if (x.left == null) {
return x.right;
}
Node lastMinNode = x;
Node minNode = x.right;
while (minNode.left != null) {
lastMinNode = minNode;
minNode = minNode.left;
}
lastMinNode.left = null;
minNode.left = x.left;
minNode.right = x.right;
x = minNode;
}
return x;
}
public Value min() {
if (root == null) {
return null;
}
Node x = root;
while (x.left != null) {
x = x.left;
}
return x.value;
}
public Value max() {
if (root == null) {
return null;
}
Node x = root;
while (x.right != null) {
x = x.right;
}
return x.value;
}
}
4 二叉树的遍历
深度优先
二叉树的深度优先遍历分为以下三种方式:
- 前序遍历:先访问根节点,再访问左子树,最后访问右子树
- 中序遍历:先访问左子树,再访问根节点,最后访问右子树
- 后序遍历:先访问左子树,再访问右子树,最后访问根节点
注:
- 已知前序遍历序列和中序遍历序列,可以唯一确定一颗二叉树
- 已知中序遍历序列和后序遍历序列,可以唯一确定一颗二叉树
- 已知前序遍历和后序遍历,不能确定一颗二叉树
//使用前序遍历,获取整个树中的所有键
public Queue<Key> preErgodic() {
Queue<Key> keys = new LinkedList<>();
preErgodic(root, keys);
return keys;
}
//使用前序遍历,把指定树x中的所有键放入到keys队列中
private void preErgodic(Node x, Queue<Key> keys) {
if (x == null) {
return;
}
//把x节点的key放到keys中
keys.add(x.key);
//递归遍历x节点的左子树
if (x.left != null) {
preErgodic(x.left, keys);
}
//递归遍历x节点的右子树
if (x.right != null) {
preErgodic(x.right, keys);
}
}
//使用中序遍历,获取整个树中的所有键
public Queue<Key> midErgodic() {
Queue<Key> keys = new LinkedList<>();
midErgodic(root, keys);
return keys;
}
//使用中序遍历,把指定树x中的所有键放入到keys队列中
private void midErgodic(Node x, Queue<Key> keys) {
if (x == null) {
return;
}
//先递归,把左子树中的键放到keys中
if (x.left != null) {
midErgodic(x.left, keys);
}
//把当前节点x的键放到keys中
keys.add(x.key);
//再递归,把右子树中的键放到keys中
if (x.right != null) {
midErgodic(x.right, keys);
}
}
//使用后序遍历,获取整个树中的所有键
public Queue<Key> afterErgodic() {
Queue<Key> keys = new LinkedList<>();
afterErgodic(root, keys);
return keys;
}
//使用后序遍历,把指定树x中的所有键放入到keys队列中
private void afterErgodic(Node x, Queue<Key> keys) {
if (x == null) {
return;
}
//先递归,把左子树中的键放到keys中
if (x.left != null) {
afterErgodic(x.left, keys);
}
//再递归,把右子树中的键放到keys中
if (x.right != null) {
afterErgodic(x.right, keys);
}
//最后把当前节点x的键放到keys中
keys.add(x.key);
}
广度优先
层序遍历:就是从根节点(第一层)开始,依次向下,获取每一层所有节点的值。
//使用层序遍历,获取整个树中的所有键
public Queue<Key> layerErgodic() {
Queue<Key> keys = new LinkedList<>();
Queue<Node> nodes = new LinkedList<>();
nodes.add(root);
while (!nodes.isEmpty()) {
//从队列中弹出一个节点,把key放入到keys中
Node n = nodes.poll();
keys.add(n.key);
//判断当前节点还有没有左节点。如果有,则放入到nodes中
if (n.left != null) {
nodes.add(n.left);
}
//判断当前节点还有没有右节点。如果有,则放入到nodes中
if (n.right != null) {
nodes.add(n.right);
}
}
return keys;
}
5 二叉树的最大深度问题
//计算整个树的最大深度
public int maxDepth() {
return maxDepth(root);
}
//计算指定树x的最大深度
private int maxDepth(Node x) {
if (x == null) {
return 0;
}
return Math.max(maxDepth(x.left), maxDepth(x.right)) + 1;
}
6 折纸问题
需求:
请把一段纸条竖着放在桌子上,然后从纸条的下边向上方对折1次,压出折痕后展开。此时 折痕是凹下去的,即折痕突起的方向指向纸条的背面。如果从纸条的下边向上方连续对折2 次,压出折痕后展开,此时有三条折痕,从上到下依次是下折痕、下折痕和上折痕。
给定一 个输入参数N,代表纸条都从下边向上方连续对折N次,请从上到下打印所有折痕的方向 例如:N=1时,打印: down;N=2时,打印: down down up
分析:
我们把对折后的纸张翻过来,让粉色朝下,这时把第一次对折产生的折痕看做是根结点,那第二次对折产生的下折痕就是该结点的左子结点,而第二次对折产生的上折痕就是该结点的右子结点,这样我们就可以使用树型数据结构来描述对折后产生的折痕。(中序遍历)
这棵树有这样的特点:
- 根结点为下折痕;
- 每一个结点的左子结点为下折痕;
- 每一个结点的右子结点为上折痕;
package study.algorithm.tree;
import java.util.LinkedList;
import java.util.Queue;
public class PagerFolding {
public static void main(String[] args) {
//模拟折纸过程,产生树
Node<String> tree = createFullTree(2);
//中序遍历,打印整个节点
printTree(tree);
}
private static class Node<T> {
public T item;
public Node left;
public Node right;
public Node(T item, Node left, Node right) {
this.item = item;
this.left = left;
this.right = right;
}
}
//产生树
public static Node<String> createFullTree(int n) {
Node<String> root = null;
for (int i = 0; i < n; i++) {
if (i == 0) {
root = new Node<>("down", null, null);
continue;
}
Queue<Node> queue = new LinkedList<>();
queue.add(root);
while (!queue.isEmpty()) {
Node<String> tmp = queue.poll();
if (tmp.left != null) {
queue.add(tmp.left);
}
if (tmp.right != null) {
queue.add(tmp.right);
}
if (tmp.left == null && tmp.right == null) {
tmp.left = new Node("down", null, null);
tmp.right = new Node("up", null, null);
}
}
}
return root;
}
//打印树(中序遍历)
public static void printTree(Node<String> root) {
if (root == null) {
return;
}
if (root.left != null) {
printTree(root.left);
}
System.out.print(root.item + " ");
if (root.right != null) {
printTree(root.right);
}
}
}
树的进阶
树 --》二叉树 --》二叉排序树(二叉查询树) --》 平衡二叉树 --》红黑树
1、平衡树
2-3查找树
一棵2-3查找树要么为空,要么满足满足下面两个要求:
- 2- 结点:含有一个键(及其对应的值)和两条链,左链接指向2-3树中的键都小于该结点,右链接指向的2-3树中的键都大于该结点。
- 3- 结点:含有两个键(及其对应的值)和三条链,左链接指向的2-3树中的键都小于该结点,中链接指向的2-3树中的键都位于该结点的两个键之间,右链接指向的2-3树中的键都大于该结点。

2-3树的性质:
- 任意空连接到根节点的路径长度都是相等的
- 4-结点变换3-结点时,树的高度不会发生变化,只有当根结点是临时的4-结点,分解根结点时,树高+1
- 2-3树与普通二叉查找树最大的区别在于,普通的二叉查找树是自顶向下生长,而二叉树是自底向上生长。
2-3查找树实现起来比较复杂,在某些情况插入后的平衡操作可能会使得效率降低。但是2-3查找树作为一种比较重要的概念和思路对于我们后面要讲到的红黑树、B树和B+树非常重要。
2、红黑树
1 红黑树定义
红黑树主要是对2-3树进行编码,红黑树背后的基本思想是用标准的二叉查找树(完全由2-结点构成)和一些额外的信息(替换3-结点)来表示2-3树。我们将树中的链接分为两种类型:
- 红链接:将两个2-结点连接起来构成一个3-结点
- 黑链接:是2-3树中的普通链接。
确切的说,我们将3-结点表示为由由一条左斜的红色链接(两个2-结点其中之一是另一个的左子结点)相连的两个2-结点。这种表示法的一个优点是,我们无需修改就可以直接使用标准的二叉查找树的get方法。
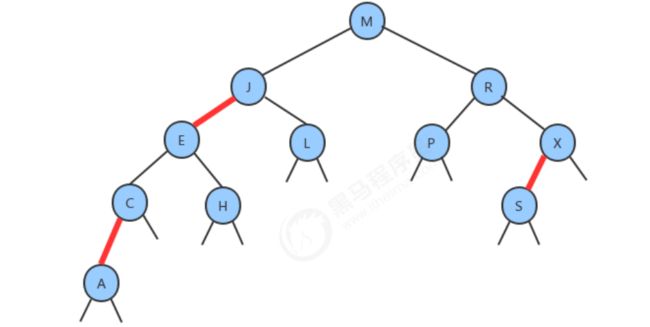
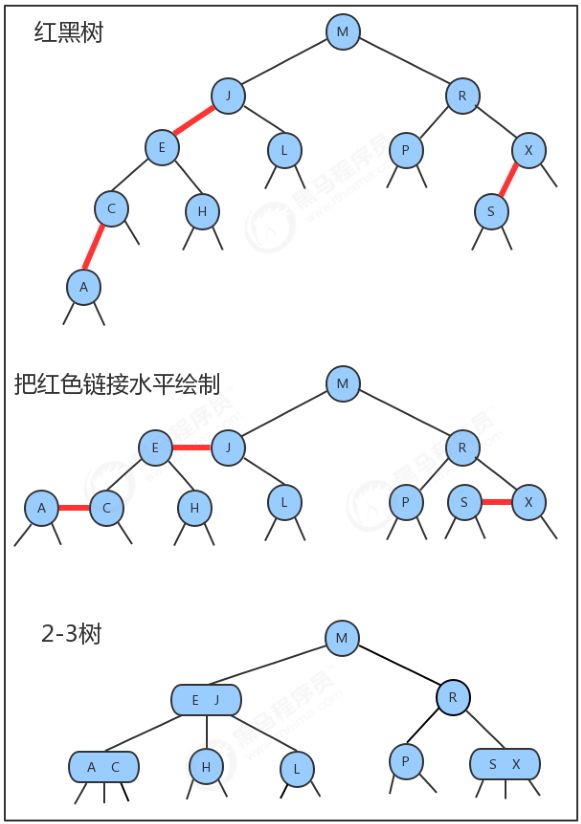
红黑树:红黑树是含有红黑链接并满足下列条件的二叉查找树:
- 红链接均为左链接;
- 没有任何一个节点同时和两条红链接相连
- 该树是完美黑色平衡的,即任意空链接到根节点的路径上的黑链接数量相同
红黑树与2-3树的对应关系:
2 红黑树的平衡化
在对红黑树进行一些增删改查的操作后,很有可能会出现红色的右链接或者两条连续红色的链接,而这些都不满足红黑树的定义,所以我们需要对这些情况通过旋转进行修复,让红黑树保持平衡。
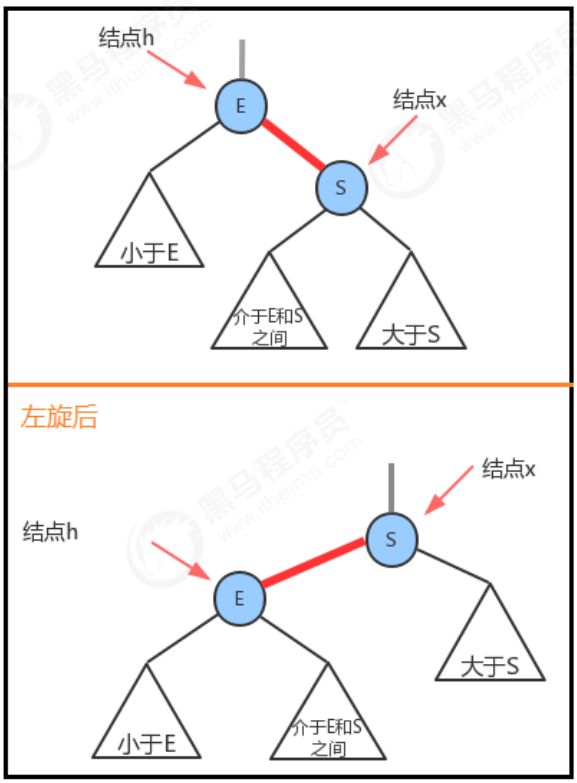
1 左旋
当某个结点的左子结点为黑色,右子结点为红色,此时需要左旋。
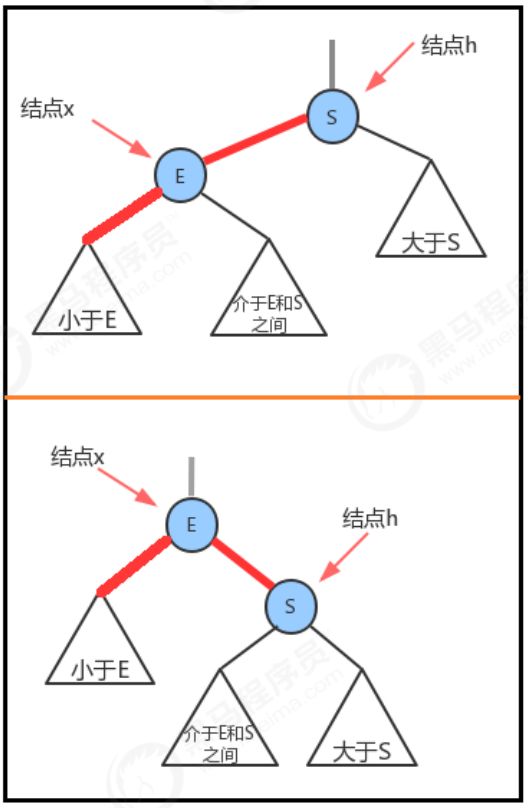
2 右旋
当某个结点的左子结点是红色,且左子结点的左子结点也是红色,需要右旋
颜色反转
当一个结点的左子结点和右子结点的color都为RED时,也就是出现了临时的4-结点,此时只需要把左子结点和右子结点的颜色变为BLACK,同时让当前结点的颜色变为RED即可。

根结点的颜色总是黑色
之前我们介绍结点 API的时候,在结点Node对象中color属性表示的是父结点指向当前结点的连接的颜色,由于根结点不存在父结点,所以每次插入操作后,我们都需要把根结点的颜色设置为黑色。
红黑树API的实现

package study.algorithm.tree2;
public class RedBlackTree<Key extends Comparable<Key>, Value> {
//根节点
private Node root;
//记录树中元素的个数
private int N;
//红色链接
private static final boolean RED = true;
//黑色链接
private static final boolean BLACK = false;
//结点类
private class Node {
//存储键
private Key key;
//存储值
private Value value;
//记录左子节点
private Node left;
//记录右子节点
private Node right;
//由其父结点指向它的链接的颜色
private boolean color;
public Node(Key key, Value value, Node left, Node right, boolean color) {
this.key = key;
this.value = value;
this.left = left;
this.right = right;
this.color = color;
}
}
public int size() {
return N;
}
public boolean isEmpty() {
return this.N == 0;
}
private boolean isRed(Node x) {
return x == null ? false : x.color == RED;
}
//左旋转
private Node rotateLeft(Node h) {
//获取h结点的右子节点x
Node x = h.right;
//让x结点的左子节点成为h结点的右子节点
h.right = x.left;
//让h成为x结点的左子节点
x.left = h;
//让x结点的color属性等于h结点的color属性
x.color = h.color;
//让h结点的color属性变为红色
h.color = RED;
return x;
}
//右旋转
private Node rotateRight(Node h) {
//获取h结点的左子节点x
Node x = h.left;
//让x结点的右子节点成为h结点的左子节点
h.left = x.right;
//让h结点成为x结点的右子节点
x.right = h;
//让x结点的color属性等于h结点的color属性
x.color = h.color;
//让h结点的color属性为红色
h.color = RED;
return x;
}
//颜色反转,相当于完成拆分4-结点
private void flipColors(Node h) {
//当前节点变为红色
h.color = RED;
//子节点变为黑色
h.left.color = BLACK;
h.right.color = BLACK;
}
//在整个树上完成插入操作
public void put(Key key, Value val) {
root = put(root, key, val);
//根节点的颜色总是黑色
root.color = BLACK;
}
//在指定树中,完成插入操作,并返回添加元素后新的树
private Node put(Node h, Key key, Value val) {
//判断h是否为空。如果为空,直接返回一个红色节点
if (h == null) {
N++;
return new Node(key, val, null, null, RED);
}
//比较h节点的键和key的大小
int cmp = key.compareTo(h.key);
if (cmp < 0) {
h.left = put(h.left, key, val);
} else if (cmp > 0) {
h.right = put(h.right, key, val);
} else {
h.value = val;
}
//进行左旋:当前节点h的左子节点为黑色,右子节点为红色,需要左旋
if (isRed(h.right) && !isRed(h.left)) {
h = rotateLeft(h);
}
//进行右旋:当当前节点h的左子节点和左子节点的左子节点都为红色,需要右旋
if (isRed(h.left) && isRed(h.left.left)) {
h = rotateRight(h);
}
//颜色反转
if (isRed(h.left) && isRed(h.right)) {
flipColors(h);
}
return h;
}
public Value get(Key key) {
return get(root, key);
}
private Value get(Node x, Key key) {
if (x == null) {
return null;
}
int cmp = key.compareTo(x.key);
if (cmp < 0) {
return get(x.left, key);
} else if (cmp > 0) {
return get(x.right, key);
} else {
return x.value;
}
}
}
2、B树
2.1 B树概念
B树中允许一个结点中包含多个key,可以是3个、4个、5个甚至更多,并不确定,需要看具体的实现。现在我们选择一个参数M,来构造一个B树,我们可以把它称作是M阶的B树,那么该树会具有如下特点:
- 每个结点最多有 M-1个key,并且以升序排列;
- 每个结点最多能有 M个子结点;
- 根结点至少有两个子结点;
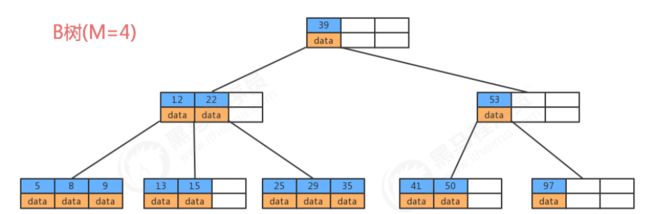
在实际应用中 B树的阶数一般都比较大(通常大于100),所以,即使存储大量的数据,B树的高度仍然比较小,这样在某些应用场景下,就可以体现出它的优势。
2.2 B树存储数据
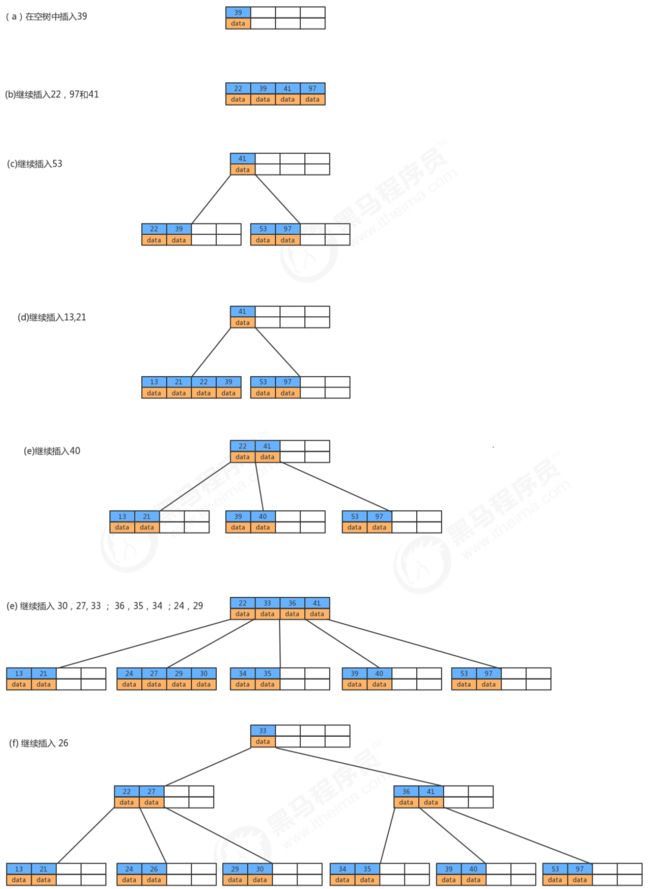
若参数M选择为5,那么每个结点最多包含4个键值对,我们以5阶B树为例,看看B树的数据存储。
2.3 B树在磁盘文件中的应用
3、B+树
B+树是对B树的一种变形树,它与B树的差异在于:
- 非叶结点仅具有索引作用,也就是说,非叶子结点只存储key,不存储value;
- 树的所有叶结点构成一个有序链表,可以按照key排序的次序遍历全部数据。
3.1 B+树存储数据
若参数M选择为5,那么每个结点最多包含4个键值对,我们以5阶B+树为例,看看B+树的数据存储。

3.2 B+树和B树的对比
B+ 树的优点在于:
- 由于B+树在非叶子结点上不包含真正的数据,只当做索引使用,因此在内存相同的情况下,能够存放更多的key。
- B+树的叶子结点都是相连的,因此对整棵树的遍历只需要一次线性遍历叶子结点即可。而且由于数据顺序排列并且相连,所以便于区间查找和搜索。而B树则需要进行每一层的递归遍历。
B树的优点在于:
由于B树的每一个节点都包含key和value,因此我们根据key查找value时,只需要找到key所在的位置,就能找到value,但B+树只有叶子结点存储数据,索引每一次查找,都必须一次一次,一直找到树的最大深度处,也就是叶子结点的深度,才能找到value。
3.3 B+树在数据库中的应用
在数据库的操作中,查询操作可以说是最频繁的一种操作,因此在设计数据库时,必须要考虑到查询的效率问题,在很多数据库中,都是用到了B+树来提高查询的效率;
在操作数据库时,我们为了提高查询效率,可以基于某张表的某个字段建立索引,就可以提高查询效率,那其实这个索引就是B+树这种数据结构实现的。
例:索引查询
未建立主键索引查询
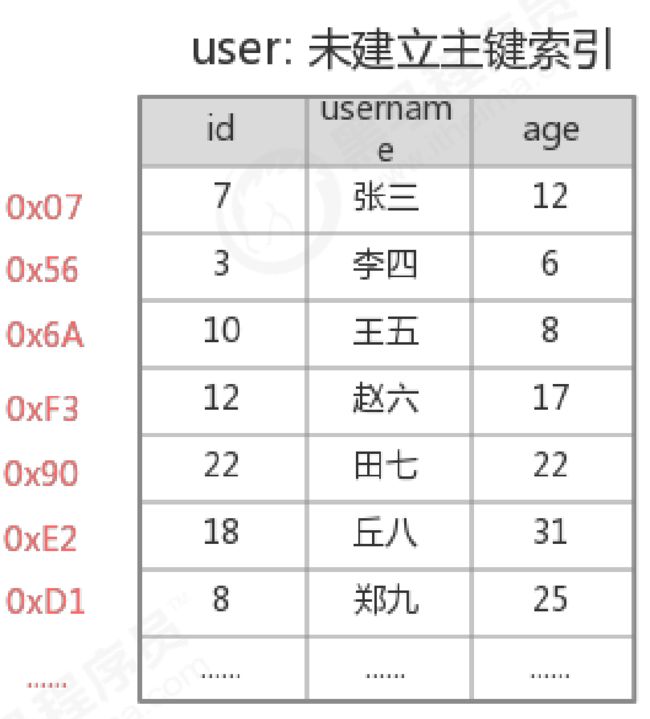
执行 select * from user where id=18 ,需要从第一条数据开始,一直查询到第6条,发现id=18,此时才能查询出目标结果,共需要比较6次;
建立主键索引查询
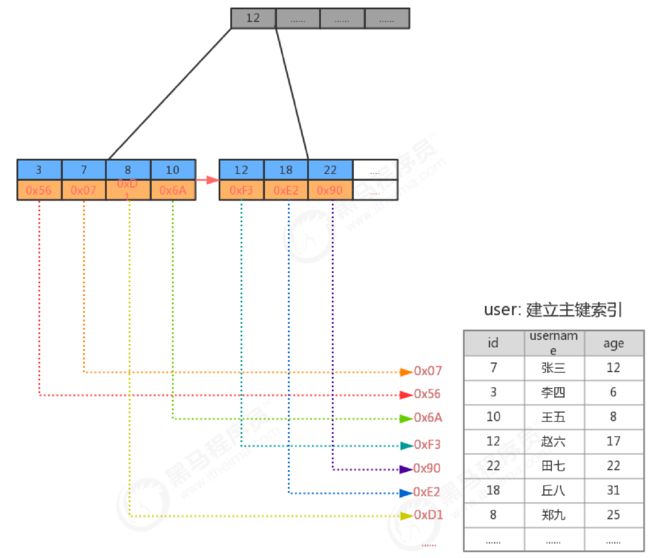
区间查询
执行 select * from user where id>=12 and id<=18 ,如果有了索引,由于B+树的叶子结点形成了一个有序链表,所以我们只需要找到id为12的叶子结点,按照遍历链表的方式顺序往后查即可,效率非常高。