Pytorch笔记:DataLoader,Dataset和Sampler
简介:
在 PyTorch 中,我们的数据集往往会用一个类去表示,在训练时用 Dataloader 产生一个 batch 的数据。简单说,用一个类 抽象地表示数据集,而 Dataloader 作为迭代器,每次产生一个 batch 大小的数据,节省内存。
Dataset用于存放、处理图片和相应的标签。
Dataloader则是决定了我们以怎样的采样策略,每次输送多少张图片和标签到网络中进行学习。先通过sampler拿到图片和标签的索引【可能一个也可能是一个batch】,然后再通过索引从Dataset中拿到图片和对应的标签。
几者间的关系如下:
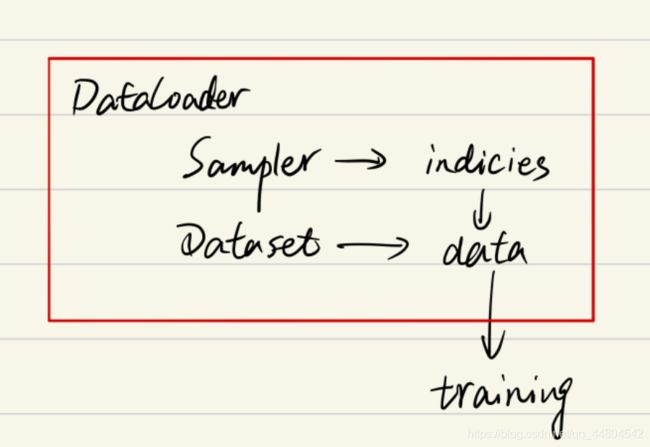
pytorch中加载数据的顺序是:
①创建一个dataset对象
②创建一个dataloader对象
③循环dataloader对象,将data,label拿到模型中去训练
Dataset
torch.utils.data.Dataset是一个抽象类,是Pytorch中图像数据集中最为重要的一个类,也是Pytorch中所有数据集加载类中应该继承的父类。
作用:保存数据集的图片和相应的标签,通过索引能够完成图片的加载以及预处理、标签的加载以及预处理。Datasets是后续构建Dataloader工具函数的实例参数之一。
在Dataset可以自己定义图片和标签的加载方式【针对不同的标签格式书写不同的加载方式】,各种预处理操作
用户想要加载自定义的数据只需要继承这个类,并且覆写其中的几个方法即可:
①__init__:传入数据,初始化信息
②__len__:返回整个数据集的大小
③__getitem__:返回一条训练数据【使用dataset[i]返回数据集中第i个样本】。根据传入的下标返回label和transform之后的图片并将其转换成tensor
注意:方法2-3必须重写,不覆写这两个方法会直接返回错误
class FirstDataset(data.Dataset):#需要继承data.Dataset
def __init__(self):
# TODO
# 1. 初始化文件路径或文件名列表。
#也就是在这个模块里,我们所做的工作就是初始化该类的一些基本参数。
pass
def __getitem__(self, index):
# TODO
#1。从文件中读取一个数据
#2。预处理数据(例如torchvision.Transform)。
#3。返回数据对(例如图像和标签)。
#这里需要注意的是,read one data,是一个data
pass
def __len__(self):
# 您应该将0更改为数据集的总大小
实例讲解
#导入相关模块
from torch.utils.data import DataLoader,Dataset
from skimage import io,transform
import matplotlib.pyplot as plt
import os
import torch
from torchvision import transforms
import numpy as np
class AnimalData(Dataset): #继承Dataset
def __init__(self, root_dir, transform=None): #__init__是初始化该类的一些基础参数
self.root_dir = root_dir #文件目录
self.transform = transform #变换
self.images = os.listdir(self.root_dir)#目录里的所有文件
def __len__(self):#返回整个数据集的大小
return len(self.images)
def __getitem__(self,index):#根据索引index返回dataset[index]
image_index = self.images[index]#根据索引index获取该图片
img_path = os.path.join(self.root_dir, image_index)#获取索引为index的图片的路径名
img = io.imread(img_path)# 读取该图片
label = img_path.split('\\')[-1].split('.')[0]# 根据该图片的路径名获取该图片的label,具体根据路径名进行分割。我这里是"E:\\Python Project\\Pytorch\\dogs-vs-cats\\train\\cat.0.jpg",所以先用"\\"分割,选取最后一个为['cat.0.jpg'],然后使用"."分割,选取[cat]作为该图片的标签
#label的解析方式多样
sample = {'image':img,'label':label}#根据图片和标签创建字典
if self.transform:
sample = self.transform(sample)#对样本进行变换
return sample #返回该样本
设置好数据类之后,我们就可以将其用torch.utils.data.DataLoader加载,并访问它
if __name__=='__main__':
data = AnimalData('E:/Python Project/PyTorch/dogs-vs-cats/train',transform=None)#初始化类,设置数据集所在路径以及变换
dataloader = DataLoader(data,batch_size=128,shuffle=True)#使用DataLoader加载数据
for i_batch,batch_data in enumerate(dataloader):
print(i_batch)#打印batch编号
print(batch_data['image'].size())#打印该batch里面图片的大小
print(batch_data['label'])#打印该batch里面图片的标签
DataLoader
通过上面的方式,可以定义我们需要的数据类,可以通过迭代的方式来获取每一个数据。但是光有这个功能是不够用的,在实际的加载数据集的过程中,我们的数据量往往都很大,此时效率就较低。
DataLoader这个类可以更加快捷的对数据进行操作。它为我们提供的常用操作有:batch_size(每个batch的大小), shuffle(是否进行shuffle操作), num_workers(并行加载数据的时候使用几个子进程)等操作。
作用:将自定义的Dataset根据batch size大小、是否shuffle等封装成一个Batch Size大小的Tensor,用于后面的训练
相关参数:
dataset:Dataset类型,从其中加载数据和标签
batch_size:int,可选。每个batch加载多少样本
shuffle:bool,可选。为True时表示每个epoch都对数据进行洗牌
sampler:Sampler,可选。 自定义从数据集中取样本的策略,如果指定这个参数,那么shuffle必须为False
batch_sampler(Sampler, optional): 与sampler类似,但是一次返回一个batch的indices(索引),需要注意的是,一旦指定了这个参数,那么batch_size,shuffle,sampler,drop_last就不能再制定了(互斥——Mutually exclusive)
num_workers:int,可选。加载数据时使用多少子进程。默认值为0,表示在主进程中加载数据。
collate_fn:callable,可选。如何取样本的,我们可以定义自己的函数来准确地实现想要的功能
pin_memory:bool,可选。如果设置为True,那么data loader将会在返回它们之前,将tensors拷贝到CUDA中的固定内存(CUDA pinned memory)中.
drop_last:bool,可选。 如果设置为True:这个是对最后的未完成的batch来说的,比如你的batch_size设置为64,而一个epoch只有100个样本,那么训练的时候后面的36个就被扔掉了;如果为False(默认),那么会继续正常执行,只是最后的batch_size会小一点【36】。
class DataLoader(object):
r"""
Data loader. Combines a dataset and a sampler, and provides
single- or multi-process iterators over the dataset.
Arguments:
dataset (Dataset): dataset from which to load the data.
batch_size (int, optional): how many samples per batch to load
(default: 1).
shuffle (bool, optional): set to ``True`` to have the data reshuffled
at every epoch (default: False).
sampler (Sampler, optional): defines the strategy to draw samples from
the dataset. If specified, ``shuffle`` must be False.
batch_sampler (Sampler, optional): like sampler, but returns a batch of
indices at a time. Mutually exclusive with batch_size, shuffle,
sampler, and drop_last.
num_workers (int, optional): how many subprocesses to use for data
loading. 0 means that the data will be loaded in the main process.
(default: 0)
collate_fn (callable, optional): merges a list of samples to form a mini-batch.
pin_memory (bool, optional): If ``True``, the data loader will copy tensors
into CUDA pinned memory before returning them.
drop_last (bool, optional): set to ``True`` to drop the last incomplete batch,
if the dataset size is not divisible by the batch size. If ``False`` and
the size of dataset is not divisible by the batch size, then the last batch
will be smaller. (default: False)
timeout (numeric, optional): if positive, the timeout value for collecting a batch
from workers. Should always be non-negative. (default: 0)
worker_init_fn (callable, optional): If not None, this will be called on each
worker subprocess with the worker id (an int in ``[0, num_workers - 1]``) as
input, after seeding and before data loading. (default: None)
.. note:: By default, each worker will have its PyTorch seed set to
``base_seed + worker_id``, where ``base_seed`` is a long generated
by main process using its RNG. However, seeds for other libraies
may be duplicated upon initializing workers (w.g., NumPy), causing
each worker to return identical random numbers. (See
:ref:`dataloader-workers-random-seed` section in FAQ.) You may
use ``torch.initial_seed()`` to access the PyTorch seed for each
worker in :attr:`worker_init_fn`, and use it to set other seeds
before data loading.
.. warning:: If ``spawn`` start method is used, :attr:`worker_init_fn` cannot be an
unpicklable object, e.g., a lambda function.
"""
__initialized = False
def __init__(self, dataset, batch_size=1, shuffle=False, sampler=None, batch_sampler=None,
num_workers=0, collate_fn=default_collate, pin_memory=False, drop_last=False,
timeout=0, worker_init_fn=None):
self.dataset = dataset
self.batch_size = batch_size
self.num_workers = num_workers
self.collate_fn = collate_fn
self.pin_memory = pin_memory
self.drop_last = drop_last
self.timeout = timeout
self.worker_init_fn = worker_init_fn
if timeout < 0:
raise ValueError('timeout option should be non-negative')
if batch_sampler is not None:
if batch_size > 1 or shuffle or sampler is not None or drop_last:
raise ValueError('batch_sampler option is mutually exclusive '
'with batch_size, shuffle, sampler, and '
'drop_last')
self.batch_size = None
self.drop_last = None
if sampler is not None and shuffle:
raise ValueError('sampler option is mutually exclusive with '
'shuffle')
if self.num_workers < 0:
raise ValueError('num_workers option cannot be negative; '
'use num_workers=0 to disable multiprocessing.')
if batch_sampler is None:
if sampler is None:
if shuffle:
sampler = RandomSampler(dataset) //将list打乱
else:
sampler = SequentialSampler(dataset)
batch_sampler = BatchSampler(sampler, batch_size, drop_last)
self.sampler = sampler
self.batch_sampler = batch_sampler
self.__initialized = True
def __setattr__(self, attr, val):
if self.__initialized and attr in ('batch_size', 'sampler', 'drop_last'):
raise ValueError('{} attribute should not be set after {} is '
'initialized'.format(attr, self.__class__.__name__))
super(DataLoader, self).__setattr__(attr, val)
def __iter__(self):
return _DataLoaderIter(self)
def __len__(self):
return len(self.batch_sampler)
Dataloader 可以理解为一个迭代器,最基本的使用就是传入一个 Dataset 对象,它就会根据参数 batch_size 的值生成一个 batch 的数据
- dataloader本质是一个可迭代对象,使用iter()访问,不能使用next()访问;
- 使用iter(dataloader)返回的是一个迭代器,然后可以使用next访问;
- 也可以使用
for inputs, labels in dataloaders进行可迭代对象的访问; - 一般我们实现一个datasets对象,传入到dataloader中;然后内部使用yeild返回每一次batch的数据
- DataLoader本质上就是一个iterable(跟python的内置类型list等一样),并利用多进程来加速batch data的处理,使用yield来使用有限的内存
因为DataLoader只有__iter__()而没有实现__next__()。所以DataLoader是一个iterable而不是iterator。这个iterator的实现在_DataLoaderIter中
Sampler
sampler的作用在于生成相应的索引。在DataLoader类的初始化参数里有两种sampler:sampler和batch_sampler,都默认为None。前者的作用是生成一系列的index,而batch_sampler则是将sampler生成的indices打包分组,得到一个又一个batch的index。
in : list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
out: [[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
首先需要知道的是所有的采样器都继承自Sampler这个类,如下:
class Sampler(object):
r"""Base class for all Samplers.
Every Sampler subclass has to provide an __iter__ method, providing a way
to iterate over indices of dataset elements, and a __len__ method that
returns the length of the returned iterators.
"""
# 一个 迭代器 基类
def __init__(self, data_source):
pass
def __iter__(self):
raise NotImplementedError
def __len__(self):
raise NotImplementedError
可以看到主要有三种方法:分别是:
init: 这个很好理解,就是初始化
iter: 这个是用来产生迭代索引值的,也就是指定每个step需要读取哪些数据
len: 这个是用来返回每次迭代器的长度
对于每个采样器,都需要提供__iter__方法,这个方法用以表示数据遍历的方式和__len__方法,用以返回数据的长度。所以你要做的就是定义好__iter__(self)函数,需要注意的是该函数的返回值需要是可迭代的。例如SequentialSampler返回的是iter(range(len(self.data_source)))。
Pytorch中已经实现的Sampler有如下几种:
1.SequentialSampler
这个看名字就很好理解,其实就是按顺序对数据集采样。
其原理是首先在初始化的时候拿到数据集data_source,之后在__iter__方法中首先得到一个和data_source一样长度的range可迭代器。每次只会返回一个索引值
class SequentialSampler(Sampler):
r"""Samples elements sequentially, always in the same order.
Arguments:
data_source (Dataset): dataset to sample from
"""
# 产生顺序 迭代器
def __init__(self, data_source):
self.data_source = data_source
def __iter__(self):
return iter(range(len(self.data_source)))
def __len__(self):
return len(self.data_source)
2.RandomSampler
参数:
data_source: 同上
num_samples: 指定采样的数量,默认是所有[和batch_size无关]
replacement: 若为True,则表示可以重复采样,即同一个样本可以重复采样,这样可能导致有的样本采样不到。所以此时我们可以设置num_samples来增加采样数量使得每个样本都可能被采样到
class RandomSampler(Sampler):
r"""Samples elements randomly. If without replacement, then sample from a shuffled dataset.
If with replacement, then user can specify ``num_samples`` to draw.
Arguments:
data_source (Dataset): dataset to sample from
num_samples (int): number of samples to draw, default=len(dataset)
replacement (bool): samples are drawn with replacement if ``True``, default=False
"""
def __init__(self, data_source, replacement=False, num_samples=None):
self.data_source = data_source
self.replacement = replacement
self.num_samples = num_samples
def __iter__(self):
n = len(self.data_source)
if self.replacement:
return iter(torch.randint(high=n, size=(self.num_samples,), dtype=torch.int64).tolist())
return iter(torch.randperm(n).tolist())
def __len__(self):
return len(self.data_source)
可以看出RandomSampler等方法返回的就是DataSet中的索引位置(indices),其中,在子类中的__iter__方法中,需要返回的是iter(xxx)(即iterator)的形式
3.WeightedRandomSample
参数作用同上面的RandomSampler,不再赘述
4.SubsetRandomSampler
这个采样器常见的使用场景是将训练集划分成训练集和验证集,示例如下:
n_train = len(train_dataset)
split = n_train // 3
indices = random.shuffle(list(range(n_train)))
train_sampler = torch.utils.data.sampler.SubsetRandomSampler(indices[split:])
valid_sampler = torch.utils.data.sampler.SubsetRandomSampler(indices[:split])
train_loader = DataLoader(..., sampler=train_sampler, ...)
valid_loader = DataLoader(..., sampler=valid_sampler, ...)
5.BatchSampler【重要】
以上提到的采样器每次都只返回一个索引,但是我们在训练时是对批量的数据进行训练,而这个工作就需要BatchSampler来做。也就是说BatchSampler的作用就是将前面的Sampler采样得到的索引值进行合并,当数量等于一个batch大小后就将这一批的索引值返回
class BatchSampler(Sampler):
r"""Wraps another sampler to yield a mini-batch of indices.
Args:
sampler (Sampler): Base sampler.
batch_size (int): Size of mini-batch.
drop_last (bool): If ``True``, the sampler will drop the last batch if
its size would be less than ``batch_size``
Example:
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=False))
[[0, 1, 2], [3, 4, 5], [6, 7, 8], [9]]
>>> list(BatchSampler(SequentialSampler(range(10)), batch_size=3, drop_last=True))
[[0, 1, 2], [3, 4, 5], [6, 7, 8]]
"""
# 批次采样
def __init__(self, sampler, batch_size, drop_last):
if not isinstance(sampler, Sampler):
raise ValueError("sampler should be an instance of "
"torch.utils.data.Sampler, but got sampler={}"
.format(sampler))
if not isinstance(batch_size, _int_classes) or isinstance(batch_size, bool) or \
batch_size <= 0:
raise ValueError("batch_size should be a positive integeral value, "
"but got batch_size={}".format(batch_size))
if not isinstance(drop_last, bool):
raise ValueError("drop_last should be a boolean value, but got "
"drop_last={}".format(drop_last))
self.sampler = sampler
self.batch_size = batch_size
self.drop_last = drop_last
def __iter__(self):
batch = []
# 一旦达到batch_size的长度,说明batch被填满,就可以yield出去了
for idx in self.sampler:
batch.append(idx)
if len(batch) == self.batch_size:
yield batch
batch = []
if len(batch) > 0 and not self.drop_last:
yield batch
def __len__(self):
# 比如epoch有100个样本,batch_size选择为64,那么drop_last的结果为1,不drop_last的结果为2
if self.drop_last:
return len(self.sampler) // self.batch_size
else:
return (len(self.sampler) + self.batch_size - 1) // self.batch_size
需要注意的是DataLoader的部分初始化参数之间存在互斥关系:
- 如果你自定义了batch_sampler,那么这些参数都必须使用默认值:batch_size,shuffle,sampler,drop_last.
- 如果你自定义了sampler,那么shuffle需要设置为False
- 如果sampler和batch_sampler都为None,那么batch_sampler使用Pytorch已经实现好的BatchSampler,而sampler分两种情况:
- 若shuffle=True,则sampler=RandomSampler(dataset)【使用较多】
- 若shuffle=False,则sampler=SequentialSampler(dataset)
其它:
**collate_fn
用于对数据做一些额外的处理。比如在文本任务中,一般由于文本长度不一致,我们需要进行截断或者填充。对于图片,我们则希望它们有同样的尺寸。我们可以编写一个函数,然后用这个参数调用它,下面是一个简单的例子,我们把文本截断成只有10个字符
def truncate(data_list):
"""传进一个batch_size大小的数据"""
for data in data_list:
text = data["text"]
data["text"]=text[:10]
return data_list
test_loader = DataLoader(sentiment_train_set, batch_size=batch_size, shuffle=True, num_workers=2, collate_fn=truncate)
正常情况下,默认的collate_fn是将img和label分别合并成imgs和labels,所以如果你的__getitem__方法只是返回 img, label,那么你可以使用默认的collate_fn方法,但是如果你每次读取的数据有img, box, label等等,那么你就需要自定义collate_fn来将对应的数据合并成一个batch数据,这样方便后续的训练步骤。
DataLoader数据加载运行过程
在模型训练过程中,数据从硬盘加载并经过相应的预处理操作后将标签和图片送到网络中,总个过程主要通过DataLoader实现,大致运行流程如下:
[1].train_data = MyDataset(data_path = …)
[2].train_loader = DataLoader(dataset=train_data, sampler=…)
[3].for i, data in enumerate(train_loader,0)
[4] class DataLoader():def iter(self): return _DataLoaderIter(self) [或其它]
[5]_DataLoaderIter(): def next(self):
[6] class BatchSampler(Sampler):def iter(self):
[7] class GroupSampler(Sampler):def iter(self):
[8]class MyDataset(): def getitem():
[7]class MyDataset(): img = self.transform(img)
[8]inputs,labels = data; inputs,labels = Variable(inputs),Variable(labels)
[9]output = net(inputs)
参考链接:
1.https://www.cnblogs.com/marsggbo/p/11541054.html