100天搞定机器学习(100-Days-Of-ML)(一)数据预处理
这是github一个开源项目,作者是Avik Jain,内容是从机器学习的基础概念起步,逐层递进,很适合初学者。github地址是https://github.com/Avik-Jain/100-Days-Of-ML-Code。截至到现在,已经有近16000多的star。
为了学习ML的实战技巧,跟着这个开源项目学习了一段时间,并贡献了一点issues。现在将自己的学习过程总结起来,仅供以后参考。
该项目前期用的是sklearn来学习各种ML的模型,但是对于时下火热的深度学习并没有多少的代码实战,可以这样说该项目是Avik Jain学习机器学习方面的步骤,很多知识点都是一句话带过(比如,今天深入学习了SVM,Day9 Got an intution on what SVM is and how it is used to solve Classification problem.)。
总结了一下,该项目中有关ML模型只有很少的一部分有代码实例:
- 有监督学习:1.数据预处理 2.简单线性回归 3.多元线性回归 4.逻辑回归 5.KNN 6.SVM支持向量机 7.决策树 8.随机森林
- 无监督学习:1.K-Means 2.层次聚类
将这些简单的机器学习实战总结,并给出sklearn中这些模型的相关解释。另外所有数据集可以从Avik Jain的github上下载。
第一天:数据预处理
数据预处理是机器学习的基础,完美的数据预处理会对模型的训练有着很大的帮助。实际场景下的数据集大多是比较复杂的,也有很多的噪音数据,缺失数据,如何解决这些数据集问题是十分重要的。
上面是Avik Jain给出的相关步骤,下面我们跟着这些步骤来操作。
第一步:导入库
import numpy as np
import pandas as pd第二步:加载数据集
数据集如下:
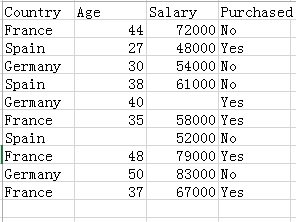
dataset = pd.read_csv('E:/Data.csv') //读取数据集,这里是存放data的位置
X = dataset.iloc[ : , :-1].values // 这里是将data中 除 最后一列的(faatures)数据保存
Y = dataset.iloc[ : , 3].values //这里是将data最后一列(label)数据保存
-----------------------------------------------------------------------------
print(X)
print(Y)
打印X和Y查看具体的数据,方便理解第三步:处理丢失数据
from sklearn.preprocessing import Imputer //导入sklearn的Imputer
imputer = Imputer(missing_values = "NaN", strategy = "mean", axis = 0)
//创建一个Imputer实例,并设置处理丢失值的策略,这里使用的是数据的平均值
imputer = imputer.fit(X[ : , 1:3]) //转换特征范围
X[ : , 1:3] = imputer.transform(X[ : , 1:3]) //开始处理
-----------------------------------------------------------------------------
print(X) 和上面的数据对比可查看缺失值的变化Tips:Imputer补充说明
sklearn.preprocessing.Imputer(missing_values=’NaN’, strategy=’mean’, axis=0, verbose=0, copy=True)
主要参数说明:
missing_values:缺失值,可以为整数或NaN(缺失值numpy.nan用字符串‘NaN’表示),默认为NaN
strategy:缺失值替换策略,字符串,默认用均值mean替换
(1)mean:用特征列的均值替换
(2)median:用特征列的中位数替换
(3)most_frequen:用特征列的众数替换
axis:指定轴数,默认axis=0代表列,axis=1代表行
verbose:整型,Controls the verbosity of the imputer
copy:设置为True代表不在原数据集上修改,设置为False时,就地修改,存在如下情况时,即使设置为False时,也不会就地修改
(1)X不是浮点值数组
(2)X是稀疏且missing_values=0
(3)axis=0且X为CRS矩阵
(4)axis=1且X为CSC矩阵第四步:解析分类数据(转换数据)
因为有的数据并不是数值型的,有的是字符串类型,需要进行标签转换和独热编码
from sklearn.preprocessing import LabelEncoder, OneHotEncoder
labelencoder_X = LabelEncoder() //创建 LabelEncoder实例
//转换特定的特征列 这里的第一列数据时国家,字符串类型,需要转换
X[ : , 0] = labelencoder_X.fit_transform(X[ : , 0])
onehotencoder = OneHotEncoder(categorical_features = [0]) //转换特定的特征列
X = onehotencoder.fit_transform(X).toarray()
labelencoder_Y = LabelEncoder()
Y = labelencoder_Y.fit_transform(Y) //将标签yes no 转成成数值形式
-----------------------------------------------------------------------------
print(X)
print(Y)第五步:划分数据集
from sklearn.model_selection import train_test_split
X_train, X_test, Y_train, Y_test = train_test_split( X , Y , test_size = 0.2, random_state = 0)
Tips:这里我们使用的是model_selection ,不同的python版本不一样,比如2.7版本可能使用的cross_validationTips:train_test_split补充说明
sklearn.model_selection.train_test_split(train_data,train_target,test_size=0.2, random_state=0)
主要参数说明:
train_data:待划分的样本集
train_target:待划分的样本集的标签集
test_size:样本占比,test数据集的占比 如果是整数,就是样本集的数量
random_state:是随机数的种子第六步:特征缩放
从数据集看,我们发现不同的特征的特征值差别较大,salary和age,这样的数据集不利于训练模型。需要特征缩放。
from sklearn.preprocessing import StandardScaler
sc_X = StandardScaler()
X_train = sc_X.fit_transform(X_train)
X_test = sc_X.transform(X_test)Tips:这里的StandardScaler是去均值和方差归一化,防止两个特征列中特征值的范围差距过大,从而导致的收敛速率变慢。
走到这里,那么代表机器学习的第一步我们已经走完了,接下里就可以进行相关的模型学习和训练实战了。