基于BiLSTM-CRF的命名实体识别
基于BiLSTM-CRF的命名实体识别
- 1. 任务说明
-
- 1.1 任务定义
- 1.2 语料说明
- 2. 实验环境
- 3. 算法说明(按文件说明)
-
- 3.1 model.py
- 3.2 data.py
- 3.3 predict.py
- 3.4 evaluate.py
- 3.5 run.py
- 4. 实验结果
- 5. 参考资料
- 6. 源码
1. 任务说明
1.1 任务定义
基于train.txt和train_TAG.txt数据训练一个BiLSTM-CRF命名实体识别模型,进而为test.txt进行序列标注,输出标签文件,标签文件输出格式与train_TAG.txt相同。即保持test.txt中的行次序、分行信息以及行内次序,行内每个字的标签之间用空格分隔。输出文件命名方式:学号.txt。
1.2 语料说明
- 训练语料:train.txt为字(符号)序列,train_TAG.txt为对应train.txt中每一个字(符号)的实体标签。例如:
train.txt第一句:人 民 网 1 月 1 日 讯 据 《 纽 约 时 报 》 报 道 ,
train_TAG.txt中对位的标签为:O O O B_T I_T I_T I_T O O O B_LOC I_LOC O O O O O O - 发展集dev.txt及其标注dev_TAG.txt(标注规范和train_TAG.txt中的相同),可用于训练过程中进行模型选择。
- 测试语料:test.txt:用于测试模型。
2. 实验环境
- Ubuntu 18.04.5
- Python 3.8.5
- torch 1.8.1
- seqeval 0.0.3
3. 算法说明(按文件说明)
3.1 model.py
- 在此实现BiLSTM_CRF模型,并进行优化
- 大部分代码源自pytorch示例模型,在此只展示修改部分,整体代码见源码
_forward_alg_new_parallel
- forward_var在一个feat的循环中,会被重复用到tag_num次,所以将tag转置成列,一并计算,从而只保留外层循环减少计算次数。
- terminal_var的每一行是一个标签。
def _forward_alg_new_parallel(self, feats):
init_alphas = torch.full([feats.shape[0], self.tagset_size], -10000.).to(self.device)
init_alphas[:, self.tag_to_ix[START_TAG]] = 0.
forward_var_list = []
forward_var_list.append(init_alphas)
for feat_index in range(feats.shape[1]):
gamar_r_l = torch.stack([forward_var_list[feat_index]] * feats.shape[2]).transpose(0, 1)
t_r1_k = torch.unsqueeze(feats[:, feat_index, :], 1).transpose(1, 2)
aa = gamar_r_l + t_r1_k + torch.unsqueeze(self.transitions, 0)
forward_var_list.append(torch.logsumexp(aa, dim=2))
# forward_var_list[-1]: batch_size x tag_num
terminal_var = forward_var_list[-1] + self.transitions[self.tag_to_ix[STOP_TAG]].repeat([feats.shape[0], 1])
alpha = torch.logsumexp(terminal_var, dim=1)
return alpha
_score_sentence_parallel
- 将所有的tag的分数一并计算
def _score_sentence_parallel(self, feats, tags):
# Gives the score of provided tag sequences
score = torch.zeros(tags.shape[0]).to(self.device)
tags = torch.cat([torch.full([tags.shape[0], 1], self.tag_to_ix[START_TAG], dtype=torch.long).to(self.device), tags], dim=1)
for i in range(feats.shape[1]):
feat = feats[:, i, :]
score = score + \
self.transitions[tags[:, i + 1], tags[:, i]] + feat[range(feat.shape[0]),tags[:, i + 1]]
score = score + self.transitions[self.tag_to_ix[STOP_TAG], tags[:, -1]]
return score
3.2 data.py
loadData
- 按行读取数据
def loadData(textPath, tagPath):
sents = []
with open(textPath, 'r', encoding='utf-8') as f:
for line in f.readlines():
sents.append(line.split())
tags = []
with open(tagPath, 'r', encoding='utf-8') as f:
for line in f.readlines():
tags.append(line.split())
dataset = list(zip(sents, tags))
return sents, tags, dataset
get_word_to_ix
- 获取word_to_ix字典
def get_word_to_ix(data):
word_to_ix = {}
word_to_ix[PAD_TAG] = 0
for sentence, tags in tqdm(data):
for word in sentence:
if word not in word_to_ix:
word_to_ix[word] = len(word_to_ix)
return word_to_ix
prepare_sequence
- 将未出现过的词按PAD_TAG处理
def prepare_sequence(seq, to_ix):
idxs = []
for w in seq:
if w not in to_ix:
w = PAD_TAG
idxs.append(to_ix[w])
return torch.tensor(idxs, dtype=torch.long).to(device)
prepare_sequence_batch
- 对batch数据提前进行处理,通过max_len限制最大输入长度,同时对长度不够的句子进行填充,保证句子长度一直(按最长句子限制会导致填充部分过多,训练速度下降)
def prepare_sequence_batch(data ,word_to_ix, tag_to_ix, max_len=100):
print("==============================【Data Processing】================================")
seqs = [i[0] for i in data]
tags = [i[1] for i in data]
# max_len = max([len(seq) for seq in seqs])
seqs_pad = []
tags_pad = []
for seq, tag in zip(seqs, tags):
if len(seq) > max_len:
seq_pad = seq[: max_len]
tag_pad = tag[: max_len]
else:
seq_pad = seq + [PAD_TAG] * (max_len - len(seq))
tag_pad = tag + [PAD_TAG] * (max_len - len(tag))
seqs_pad.append(seq_pad)
tags_pad.append(tag_pad)
idxs_pad = torch.tensor([[word_to_ix[w] for w in seq] for seq in tqdm(seqs_pad)], dtype=torch.long)
tags_pad = torch.tensor([[tag_to_ix[t] for t in tag] for tag in tqdm(tags_pad)], dtype=torch.long)
return idxs_pad, tags_pad
3.3 predict.py
to_tag
- 通过ix_to_tag字典将预测结果转换成tag序列
def to_tag(tag_list, ix_to_tag):
temp = []
for tag in tag_list:
temp.append(ix_to_tag[tag])
return temp
predict
- 如果输入pre_tag_path则会将预测结果保留原格式写入文件,否则将返回一个完整的预测序列。
def predict(model, sentence_set, word_to_ix, ix_to_tag, pre_tag_path=None):
if pre_tag_path == None:
pre_tags = []
for sentence in tqdm(sentence_set):
precheck_sent = prepare_sequence(sentence, word_to_ix)
score, tags = model(precheck_sent)
pre_tags.extend(to_tag(tags, ix_to_tag))
return pre_tags
else:
with open(pre_tag_path, "w") as f:
for sentence in tqdm(sentence_set):
precheck_sent = prepare_sequence(sentence, word_to_ix)
score, tags = model(precheck_sent)
f.write(' '.join(to_tag(tags, ix_to_tag)))
f.write('\n')
3.4 evaluate.py
evaluate
- 调用seqeval库,对预测结果与真实值进行评估,返回f1值和整体报告
def evaluate(model, dev_sents, dev_tags, word_to_ix, ix_to_tag):
pre_tags = predict(model, dev_sents, word_to_ix, ix_to_tag)
tags = []
for dev_tag in dev_tags:
tags.extend(dev_tag)
f1 = f1_score(tags, pre_tags)
report = classification_report(tags, pre_tags)
return f1, report
3.5 run.py
- 完成模型训练与评估,具体细节见注释
# 用来记录loss和f1值变化
writer = SummaryWriter('./result')
# embedding层维数
EMBEDDING_DIM = 300
# hidden层维数
HIDDEN_DIM = 400
# batch size
BATCH_SIZE = 256
# 训练轮次
NUM_EPOCHS = 30
# 输入最大长度
MAX_LEN = 150
# 检测GPU是否可用
device = 'cuda' if torch.cuda.is_available() else 'cpu'
# 创建logger记录训练信息
logger = logging.getLogger('logger')
logger.setLevel(logging.DEBUG)
rotating_handler = logging.handlers.RotatingFileHandler(
'training_log.log', encoding='UTF-8')
formatter = logging.Formatter('%(asctime)s - %(name)s - %(levelname)s - %(message)s')
rotating_handler.setFormatter(formatter)
logger.addHandler(rotating_handler)
# 读取训练和评估数据
train_sents, train_tags, train_data = loadData("./data/train.txt", "./data/train_TAG.txt")
dev_sents, dev_tags, dev_data = loadData("./data/dev.txt", "./data/dev_TAG.txt")
# 获取word_to_ix字典
word_to_ix = get_word_to_ix(train_data)
# 初始化model和optimizer
model = BiLSTM_CRF(len(word_to_ix), tag_to_ix, EMBEDDING_DIM, HIDDEN_DIM, device)
optimizer = optim.SGD(model.parameters(), lr=0.01, weight_decay=1e-4)
# GPU可用的话将模型转移到GPU上
model.to(device)
# Check predictions before training
with torch.no_grad():
print(predict(model, [train_sents[0]], word_to_ix, ix_to_tag))
# 对训练数据进行预处理
sentence_in_pad, targets_pad = prepare_sequence_batch(train_data, word_to_ix, tag_to_ix, max_len=MAX_LEN)
# 创建DataLoader
batch_dataset = Data.TensorDataset(sentence_in_pad, targets_pad)
batch_loader = Data.DataLoader(
dataset=batch_dataset,
batch_size=BATCH_SIZE,
shuffle=True,
num_workers=8
)
# 开始训练
logger.info("=================================【Begin Training】=================================")
for epoch in trange(NUM_EPOCHS):
logger.info("=================================【Begin Epoch_{}】=================================".format(str(epoch)))
epoch_iterator = tqdm(batch_loader, desc="Iteration")
for step, batch in enumerate(epoch_iterator):
model.zero_grad()
sentence_in, targets = batch
loss = model.neg_log_likelihood_parallel(sentence_in.to(device), targets.to(device))
loss.backward()
optimizer.step()
print("\n" + time.strftime("%a %b %d %H:%M:%S %Y", time.localtime()) + \
", epoch: " + str(epoch) + ", loss: " + str(float(loss)))
# logger.info("epoch: " + str(epoch) + ", step: " + str(step) + \
# ", loss: " + str(float(loss)))
# 保存每个epoch的模型作为checkpoint
torch.save(model, './checkpoints/checkpoint_{}.pkl'.format(epoch))
logger.info("Checkpoint has saved as checkpoint_{}.pkl in ./checkpoints".format(epoch))
# 记录loss值
writer.add_scalar('loss', loss, epoch)
logger.info("epoch: " + str(epoch) + ", loss: " + str(float(loss)))
logger.info("=================================【Evaluating】=================================")
# 进行模型评估
f1, report = evaluate(model, dev_sents, dev_tags, word_to_ix, ix_to_tag)
# 记录f1值
writer.add_scalar('f1', f1, epoch)
print("f1_score: " + str(f1))
logger.info("f1_score: " + str(f1))
logger.info("Report: \n" + report)
# 训练完成
with torch.no_grad():
print(predict(model, [train_sents[0]], word_to_ix, ix_to_tag))
logger.info("=================================【Completed】=================================")
4. 实验结果
- 选取最好的一次训练结果进行说明,详细训练日志见training_log.log
训练参数
EMBEDDING_DIM = 300
HIDDEN_DIM = 400
BATCH_SIZE = 256
NUM_EPOCHS = 30
MAX_LEN = 150
lr=0.01
weight_decay=1e-4
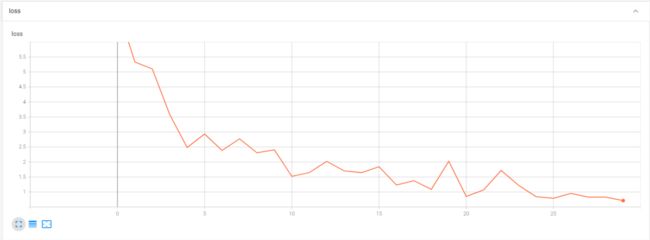
loss变化图像
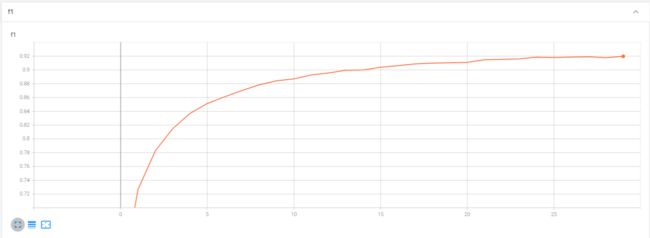
f1变化图像
最后一个epoch的评估报告

5. 参考资料
https://pytorch.org/tutorials/beginner/nlp/advanced_tutorial.html
https://zhuanlan.zhihu.com/p/61227299
https://www.jiqizhixin.com/articles/2018-10-24-13
https://www.jianshu.com/p/566c6faace64
https://blog.csdn.net/leadai/article/details/80731463
6. 源码
- 见附件