ElasticSearch(二)检索的进阶
ElasticSearch(二)检索的进阶
检索的进阶
SearchAPI
ES支持两种基本方式的检索:
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/getting-started.html
- 一个是通过使用REST request API 发送搜索参数(URL+检索参数)
GET /bank/_search?q=*&sort=account_number:asc
{
"took" : 21,
"timed_out" : false,
"_shards" : { //集群
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : { //命中的记录
"total" : {
"value" : 1000, //记录的条数 虽然是1000条 但只是返回10条
"relation" : "eq"
},
"max_score" : null,//模糊搜素的相关匹配程度
"hits" : [
{
"_index" : "bank",
"_type" : "account",
"_id" : "0",
"_score" : null,
"_source" : {
"account_number" : 0,
"balance" : 16623,
"firstname" : "Bradshaw",
"lastname" : "Mckenzie",
"age" : 29,
"gender" : "F",
"address" : "244 Columbus Place",
"employer" : "Euron",
"email" : "[email protected]",
"city" : "Hobucken",
"state" : "CO"
},
"sort" : [
0
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "1",
"_score" : null,
"_source" : {
"account_number" : 1,
"balance" : 39225,
"firstname" : "Amber",
"lastname" : "Duke",
"age" : 32,
"gender" : "M",
"address" : "880 Holmes Lane",
"employer" : "Pyrami",
"email" : "[email protected]",
"city" : "Brogan",
"state" : "IL"
},
"sort" : [
1
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "2",
"_score" : null,
"_source" : {
"account_number" : 2,
"balance" : 28838,
"firstname" : "Roberta",
"lastname" : "Bender",
"age" : 22,
"gender" : "F",
"address" : "560 Kingsway Place",
"employer" : "Chillium",
"email" : "[email protected]",
"city" : "Bennett",
"state" : "LA"
},
"sort" : [
2
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "3",
"_score" : null,
"_source" : {
"account_number" : 3,
"balance" : 44947,
"firstname" : "Levine",
"lastname" : "Burks",
"age" : 26,
"gender" : "F",
"address" : "328 Wilson Avenue",
"employer" : "Amtap",
"email" : "[email protected]",
"city" : "Cochranville",
"state" : "HI"
},
"sort" : [
3
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "4",
"_score" : null,
"_source" : {
"account_number" : 4,
"balance" : 27658,
"firstname" : "Rodriquez",
"lastname" : "Flores",
"age" : 31,
"gender" : "F",
"address" : "986 Wyckoff Avenue",
"employer" : "Tourmania",
"email" : "[email protected]",
"city" : "Eastvale",
"state" : "HI"
},
"sort" : [
4
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "5",
"_score" : null,
"_source" : {
"account_number" : 5,
"balance" : 29342,
"firstname" : "Leola",
"lastname" : "Stewart",
"age" : 30,
"gender" : "F",
"address" : "311 Elm Place",
"employer" : "Diginetic",
"email" : "[email protected]",
"city" : "Fairview",
"state" : "NJ"
},
"sort" : [
5
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "6",
"_score" : null,
"_source" : {
"account_number" : 6,
"balance" : 5686,
"firstname" : "Hattie",
"lastname" : "Bond",
"age" : 36,
"gender" : "M",
"address" : "671 Bristol Street",
"employer" : "Netagy",
"email" : "[email protected]",
"city" : "Dante",
"state" : "TN"
},
"sort" : [
6
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "7",
"_score" : null,
"_source" : {
"account_number" : 7,
"balance" : 39121,
"firstname" : "Levy",
"lastname" : "Richard",
"age" : 22,
"gender" : "M",
"address" : "820 Logan Street",
"employer" : "Teraprene",
"email" : "[email protected]",
"city" : "Shrewsbury",
"state" : "MO"
},
"sort" : [
7
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "8",
"_score" : null,
"_source" : {
"account_number" : 8,
"balance" : 48868,
"firstname" : "Jan",
"lastname" : "Burns",
"age" : 35,
"gender" : "M",
"address" : "699 Visitation Place",
"employer" : "Glasstep",
"email" : "[email protected]",
"city" : "Wakulla",
"state" : "AZ"
},
"sort" : [
8
]
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "9",
"_score" : null,
"_source" : {
"account_number" : 9,
"balance" : 24776,
"firstname" : "Opal",
"lastname" : "Meadows",
"age" : 39,
"gender" : "M",
"address" : "963 Neptune Avenue",
"employer" : "Cedward",
"email" : "[email protected]",
"city" : "Olney",
"state" : "OH"
},
"sort" : [
9
]
}
]
}
}
- 另一个是通过使用 REST request body 来发送他们(URL+请求体)
GET /bank/_search
{
"query": {"match_all": {}},
"sort": [
{
"account_number": {
"order": "asc"
}
}
]
}

第二种方式也是用的最多的。
Query DSL
https://www.elastic.co/guide/en/elasticsearch/reference/7.13/query-dsl.html


Domain Specific Language 领域特定语言。
一个查询语句的典型结构。
{
"query_name":{
"argument":{values},
....
}
}
argument:

argument

GET /bank/_search
{
"query": {
//匹配规则
"match_all": {}
}
//排序
, "sort": [
{
"balance": {
"order": "desc"
}
}
],
//类似分页查询
"from": 0,
"size": 1,
//返回指定的列
"_source": ["age","gender"]
}
match
//精确查询
GET /bank/_search
{
"query": {
"match": {
"age": "36"
}
}
}
//模糊查询
GET /bank/_search
{
"query": {
"match": {
"address": "Avenue"
}
}
}
match_phrase「短语匹配」
将需要匹配的值当成一个整体单词(不分词)进行检索
GET /bank/_search
{
"query": {
"match_phrase": {
"address": "671 Bristol"
}
}
}
multi_match「多字段匹配」
GET /bank/_search
{
"query": {
"multi_match": {
"query": "mill",
"fields": ["state","address"]
}
}
}
state或者address 含有mill
bool复合查询
bool是用来做复合查询。复合语句 可以 合并任何其他查询语句,包括复合语句,了解这一点是很重要的。这就意味着,复合语句可以相互嵌套,可以表达非常复杂的逻辑。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "mill"
}},
{"match": {
"gender": "M"
}}
]
, "must_not": [
{"match": {
"state": "MT"
}},
{"match": {
"age": "28"
}}
],
"should": [
{"match": {
"employer": "Baluba"
}}
]
}
}
}
filter过滤
并不是所有的查询都需要产生分数,特别是那些仅用于filtering(过滤)的文档。为了不计算分数ElasticSearch会自动检查场景并且优化查询的执行。
GET /bank/_search
{
"query": {
"bool": {
"must": [
{"match": {
"address": "mill"
}}
],
"filter": [
{"range": {
"balance": {
"gte": 10000,
"lte": 20000
}
}}
]
}
}
}
term
和match一样,匹配某个属性的值。全文检索字段用match(分词匹配),其他非text字段匹配用term。(精确匹配)
GET /bank/_search
{
"query": {
"term": {
"account_number": {
"value": "970"
}
}
}
}
分析
aggregations(执行集合)
聚合提供了从数据中分组和提取数据的能力。最简单的聚合方法大致等于SQL Group by 和SQL聚合函数。在Elasticsearch中,您有执行搜索返回this(命中结果),并且同时返回聚合结果,把一个响应中的所有hits(命中的结果)分隔开的能力。这是非常强大的且有效的,您可以执行查询和多个聚合,并且在一次使用中得到各自的(任何一个的)返回结果,使用一次简洁和简化的API来避免网络往返。
案例:搜索address中包含mill的所有人的年龄分布以及平均年龄,但不显示这些人的详情
GET /bank/_search
{
"query": {
"match": {
"address": "mill"
}
},
"aggs": {
//年龄分布
"ageAgg": {
"terms": {
"field": "age",
"size": 10
}
},
//求平均年龄
"ageAvg":{
"avg": {
"field": "age"
}
}
}
}
结果:
{
"took" : 2,
"timed_out" : false,
"_shards" : {
"total" : 1,
"successful" : 1,
"skipped" : 0,
"failed" : 0
},
"hits" : {
"total" : {
"value" : 4,
"relation" : "eq"
},
"max_score" : 5.4032025,
"hits" : [ //匹配后的结果
{
"_index" : "bank",
"_type" : "account",
"_id" : "970",
"_score" : 5.4032025,
"_source" : {
"account_number" : 970,
"balance" : 19648,
"firstname" : "Forbes",
"lastname" : "Wallace",
"age" : 28,
"gender" : "M",
"address" : "990 Mill Road",
"employer" : "Pheast",
"email" : "[email protected]",
"city" : "Lopezo",
"state" : "AK"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "136",
"_score" : 5.4032025,
"_source" : {
"account_number" : 136,
"balance" : 45801,
"firstname" : "Winnie",
"lastname" : "Holland",
"age" : 38,
"gender" : "M",
"address" : "198 Mill Lane",
"employer" : "Neteria",
"email" : "[email protected]",
"city" : "Urie",
"state" : "IL"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "345",
"_score" : 5.4032025,
"_source" : {
"account_number" : 345,
"balance" : 9812,
"firstname" : "Parker",
"lastname" : "Hines",
"age" : 38,
"gender" : "M",
"address" : "715 Mill Avenue",
"employer" : "Baluba",
"email" : "[email protected]",
"city" : "Blackgum",
"state" : "KY"
}
},
{
"_index" : "bank",
"_type" : "account",
"_id" : "472",
"_score" : 5.4032025,
"_source" : {
"account_number" : 472,
"balance" : 25571,
"firstname" : "Lee",
"lastname" : "Long",
"age" : 32,
"gender" : "F",
"address" : "288 Mill Street",
"employer" : "Comverges",
"email" : "[email protected]",
"city" : "Movico",
"state" : "MT"
}
}
]
},
"aggregations" : { //对聚合结果进行分析
"ageAgg" : {
"doc_count_error_upper_bound" : 0,
"sum_other_doc_count" : 0,
"buckets" : [ //桶
{
"key" : 38,
"doc_count" : 2
},
{
"key" : 28,
"doc_count" : 1
},
{
"key" : 32,
"doc_count" : 1
}
]
},
"ageAvg" : {
"value" : 34.0
}
}
}
案例:按照年龄聚合,并且请求这些年龄段的人的平均薪资
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"Agg": {
"terms": {
"field": "age",
"size": 100
},
"aggs": {
"balanceAvg": {
"avg": {
"field": "balance"
}
}
}
}
}
}
案例:查出所有年龄分布,并且这些年龄段中M的平均薪资和F的平均薪资以及这个年龄段的总体平均薪资
GET /bank/_search
{
"query": {
"match_all": {}
},
"aggs": {
"Agg": {
"terms": {
"field": "age",
"size": 10
},
"aggs": {
"genderNAME": {
"terms": {
"field": "gender.keyword",
"size": 10
},
"aggs": {
"banAvg": {
"avg": {
"field": "balance"
}
}
}
},
"totalAvg":{
"avg": {
"field": "balance"
}
}
}
}
}
}
Mapping
就类似我们在操作数据库的时候,给每个数据字段的数据类型,Varchar等等。
这里是es中的所有数据类型:https://www.elastic.co/guide/en/elasticsearch/reference/7.13/mapping-types.html
映射
Mapping(映射)Mapping是用来定义一个文档(document),以及它所包含的属性(field)是如何存储和索引的。
比如,mapping来定义:
- 那些字符串属性应该被看作全文本属性(full text fields)
- 那些属性包含数字、日期或者地理位置
- 文档中的所有属性是否能够被索引(_all配置)
- 日期的格式
- 自定义映射规则来执行动态添加属性
- 查看mapping信息
GET /bank/_mapping

- 修改mapping信息

https://www.elastic.co/guide/en/elasticsearch/reference/7.13/explicit-mapping.html

那为什么要移除type呢?
关系型数据库中两个数据表示是独立的,即使他们里面有相同名称的列也不影响使用,但ES 中不是这样的。
elasticsearch是基于Lucene开发的搜索引擎,而ES中不同type下名称相同 的filed最终在Lucene中的处理方式是一样的。 两个不同type下的两个user_name,在ES同一个索引下其实被认为是同一个filed,你必 须在两个不同的type中定义相同的filed映射。否则,不同type中的相同字段名称就会在 处理中出现冲突的情况,导致Lucene处理效率下降。
去掉type就是为了提高ES处理数据的效率。
Elasticsearch 7.x
URL中的type参数为可选。比如,索引一个文档不再要求提供文档类型。
Elasticsearch 8.x
不再支持URL中的type参数。
解决:将索引从多类型迁移到单类型,每种类型文档一个独立索引
修改映射
**数据迁移:**https://www.elastic.co/guide/en/elasticsearch/reference/7.13/docs-reindex.html

POST _reindex
{
"source": {
"index": "my-index-000001"
},
"dest": {
"index": "my-new-index-000001"
}
}
分词
分词器:https://www.elastic.co/guide/en/elasticsearch/reference/7.13/analysis-tokenizers.html
默认的分词器:https://www.elastic.co/guide/en/elasticsearch/reference/7.13/analysis-standard-tokenizer.html
一个tokenizer(分词器)接受一个字符串,将之分割为独立的tokens(词元,通常是独立的单词),然后输出tokens流。
例如,whitespace tokenizer遇到空白字符时分割文本。它会将文本Quick brown fox!分割为「Quick,brown,fox」
该tokenizer(分词器)还负责记录各个term(词条)的顺序或position位置(用于phrase短语和word proximity词近邻查询),以及term(词条)所代表的原始word(单词)的start(起始)和 end(结束)character offsers(字符偏移量)(用于高亮显示搜索的内容)。
POST _analyze
{
"tokenizer": "standard",
"text": "The 2 QUICK Brown-Foxes jumped over the lazy dog's bone."
}
Elasticsearch提供了很多内置分词器,可以构建自定义的Custom analyzers(自定义分词器)。
安装IK分词器
因为官方的分词器对中文的分词,不是很友好,所以我们需要针对中文的分词安装中文的分词器。
IK分词器:https://github.com/medcl/elasticsearch-analysis-ik
需要注意的是要兼容自己的版本,对应下载。
安装步骤,首先需要进入es的plugins文件夹,但是我们的es是用docker安装的。所以需要我们执行exec命令。
docker exec -it es容器ID /bin/bash
wget https://github.com/medcl/elasticsearch-analysis-ik/releases/download/v7.17.3/elasticsearch-analysis-ik-7.17.3.zip


当然,我们在安装的初始已经对es的文件夹进行了挂载,docker外面就有我们的文件夹目录。
cd /mydata/elasticsearch/

解压完成之后,需要重启es服务。
docker restart elasticsearch
初使用。
ik_smart
POST _analyze
{
"tokenizer": "ik_smart", //智能分词器
"text": "今天天气真好,早上还喝了咖啡"
}
{
"tokens" : [
{
"token" : "今天天气",
"start_offset" : 0,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "真好",
"start_offset" : 4,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "早上",
"start_offset" : 7,
"end_offset" : 9,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "还",
"start_offset" : 9,
"end_offset" : 10,
"type" : "CN_CHAR",
"position" : 3
},
{
"token" : "喝了",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "咖啡",
"start_offset" : 12,
"end_offset" : 14,
"type" : "CN_WORD",
"position" : 5
}
]
}
ik_max_word
POST _analyze
{
"tokenizer": "ik_max_word", //最大单词分组
"text":"我是中国人"
}
{
"tokens" : [
{
"token" : "我",
"start_offset" : 0,
"end_offset" : 1,
"type" : "CN_CHAR",
"position" : 0
},
{
"token" : "是",
"start_offset" : 1,
"end_offset" : 2,
"type" : "CN_CHAR",
"position" : 1
},
{
"token" : "中国人",
"start_offset" : 2,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "中国",
"start_offset" : 2,
"end_offset" : 4,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "国人",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 4
}
]
}
自定义的分词器
由于我们前期给es的最大内存有点小。所以需要重新给内存。我们可以通过重新创建es的实例,由于之前在安装的时候,我们将es的文件都挂载在我们的docker外面,所以就算重新创建实例,数据和配置不会丢失。
#先停掉服务
docker stop es容器的id
#在移除实例
docker rm es容器的id
# 重新给最大内存
docker run --name elasticsearch -p 9200:9200 -p 9300:9300 \
-e "discovery.type=single-node" \
-e ES_JAVA_OPTS="-Xms64m -Xmx512m" \
-v /mydata/elasticsearch/config/elasticsearch.yml:/usr/share/elasticsearch/config/elasticsearch.yml \
-v /mydata/elasticsearch/data:/usr/share/elasticsearch/data \
-v /mydata/elasticsearch/plugins:/usr/share/elasticsearch/plugins \
-d elasticsearch:7.17.3
我们在来安装Nginx,使用Nginx是为了我们在自定义分词器的时候,需要数据。此时,es就可以通过Nginx来向我们要我们自定义分词的数据。
当然安装Nginx,我们也是通过docker安装。
可以参考:Nginx - Official Image | Docker Hub
# 随便启动一个nginx的实例,只是为了复制出配置
docker run -p 80:80 --name nginx -d nginx
#将容器内的配置文件拷贝到当前目录
docker container cp nginx:/etc/nginx .

docker stop nginx
docker rm nginx

然后我们执行新的nginx容器。
docker run -p 80:80 --name nginx \
-v /mydata/nginx/html:/usr/share/nginx/html \
-v /mydata/nginx/logs:/var/log/nginx \
-v /mydata/nginx/conf:/etc/nginx \
-d nginx
# /mydata/nginx/html:/usr/share/nginx/html \
# 是将nginx的html映射到我自己的/mydata/nginx/html
#-d nginx 失去找nginx镜像
然后我们在Nginx的html的文件夹下创建index.html

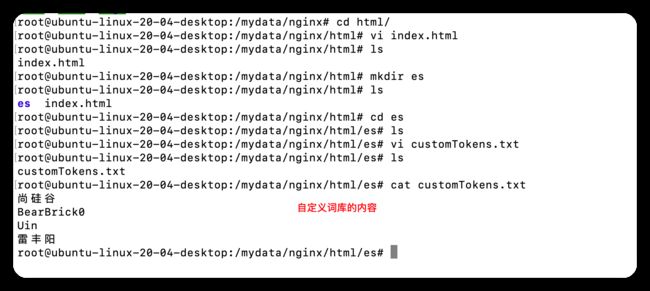
现在我有自己的词库,只需要告诉ES中的IK分词器去哪里找就行。
进入到ik的目录下。


哈哈哈哈国人开发的东西就是好!!!!


之后需要重启ES服务,基操。
哈哈哈之后报错了。

我给它换行了,我有很严重的强迫症哈哈哈哈。改了就好了。
自测一下
POST _analyze
{
"tokenizer": "ik_max_word",
"text":"uin今天在学雷丰阳老师的课然后有写博客博客的账户名叫BearBrick0"
}
{
"tokens" : [
{
"token" : "uin",
"start_offset" : 0,
"end_offset" : 3,
"type" : "CN_WORD",
"position" : 0
},
{
"token" : "今天在",
"start_offset" : 3,
"end_offset" : 6,
"type" : "CN_WORD",
"position" : 1
},
{
"token" : "今天",
"start_offset" : 3,
"end_offset" : 5,
"type" : "CN_WORD",
"position" : 2
},
{
"token" : "在学",
"start_offset" : 5,
"end_offset" : 7,
"type" : "CN_WORD",
"position" : 3
},
{
"token" : "雷丰阳",
"start_offset" : 7,
"end_offset" : 10,
"type" : "CN_WORD",
"position" : 4
},
{
"token" : "老师",
"start_offset" : 10,
"end_offset" : 12,
"type" : "CN_WORD",
"position" : 5
},
{
"token" : "的",
"start_offset" : 12,
"end_offset" : 13,
"type" : "CN_CHAR",
"position" : 6
},
{
"token" : "课",
"start_offset" : 13,
"end_offset" : 14,
"type" : "CN_CHAR",
"position" : 7
},
{
"token" : "然后",
"start_offset" : 14,
"end_offset" : 16,
"type" : "CN_WORD",
"position" : 8
},
{
"token" : "后有",
"start_offset" : 15,
"end_offset" : 17,
"type" : "CN_WORD",
"position" : 9
},
{
"token" : "写",
"start_offset" : 17,
"end_offset" : 18,
"type" : "CN_CHAR",
"position" : 10
},
{
"token" : "博客",
"start_offset" : 18,
"end_offset" : 20,
"type" : "CN_WORD",
"position" : 11
},
{
"token" : "博客",
"start_offset" : 20,
"end_offset" : 22,
"type" : "CN_WORD",
"position" : 12
},
{
"token" : "的",
"start_offset" : 22,
"end_offset" : 23,
"type" : "CN_CHAR",
"position" : 13
},
{
"token" : "账户",
"start_offset" : 23,
"end_offset" : 25,
"type" : "CN_WORD",
"position" : 14
},
{
"token" : "户名",
"start_offset" : 24,
"end_offset" : 26,
"type" : "CN_WORD",
"position" : 15
},
{
"token" : "名叫",
"start_offset" : 25,
"end_offset" : 27,
"type" : "CN_WORD",
"position" : 16
},
{
"token" : "bearbrick0",
"start_offset" : 27,
"end_offset" : 37,
"type" : "LETTER",
"position" : 17
},
{
"token" : "bearbrick",
"start_offset" : 27,
"end_offset" : 36,
"type" : "ENGLISH",
"position" : 18
},
{
"token" : "0",
"start_offset" : 36,
"end_offset" : 37,
"type" : "ARABIC",
"position" : 19
}
]
}
如果后期还需要自定义分词的词库,直接改nginx目录下的es中的customTokens就OK了。