自然语言处理①
文章目录
- 自然语言处理概述
-
- 自然语言理解
- 自然语言生成
- 文本情感分析
-
- 统计学方法
- 统计学方法的局限性
- SDK 实现文本情感分析
-
- 百度智能云控制台
- 创建自然语言处理应用
- 到底什么是SDK
- 情感倾向分析接口
自然语言处理概述
自然语言处理(Natural Language Processing,NLP)是一门综合计算机科学、语言学、统计学的人工智能技术,包含 自然语言理解 与 自然语言生成 两大方向。
自然语言理解
我们看到“夸克”两个字,便知道它是一种物理科学研究的单位;某些语境下,它还是浏览器名。阅读文章时,粗略扫一眼,便能大概了解文章谈论话题。
这便是语言的 理解 层面。我们能读懂文字、听懂对话、判断潜台词、提炼主旨。而自然语言理解任务,便是让机器也能够像人类一样理解语言。
- 搜索引擎在你输入拼音、几个字时,便能猜测你想要问什么问题,给出智能建议,其底层逻辑正是自然语言理解技术。
- 如众多 app 的智能推荐系统、前段时间流行的情绪地图、词云,也运用到了语言理解的各方各面。
- 我们平时使用的语音助手,在“听”懂你的指令方面,也体现出机器理解语言的智能。

自然语言生成
另一方面,我们能 运用 语言,书写文字、朗诵诗歌、将一种文字翻译成另一种、根据规定题目即兴写作或演讲、用语言描述事物。对应到人工智能领域,便是自然语言生成任务,旨在让机器学会创作。
- 语音助手不仅能听懂你,还能与你对话,这是
自然语言生成技术的功劳。 - 机器翻译能读懂原文本,并根据需要,翻译、生成目标语言文本,聊天机器人能根据你的话题作出回应,都属于语言应用层面。
- 我国地震台网中心的机器人,运用地震数据管理与服务系统,能自动抓取、加工数据,一旦监测到地震信息,能在短短几十秒内完成写稿、签发流程。
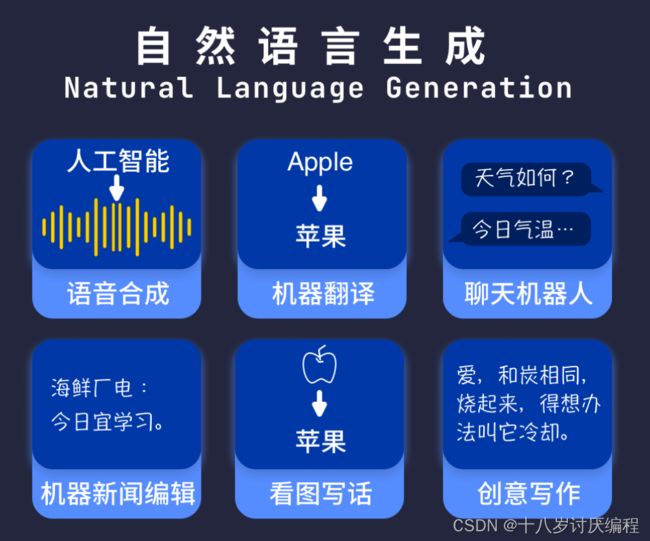
在这里我们可以通过文本情感分析技术来体验自然语言处理的强大功能。
文本情感分析
“文本情感分析”是一类技术的总称,指的是从教会机器认知文本情感,到合理运用文本情感信息实现具体应用的全过程。让我们再聚焦一点,看向它最核心的部分——文本情感分类(Text Sentiment Classification)。
所谓文本情感分类,顾名思义,指的是按照文本 情感,将文本分为若干类。常见的分类标准有:
- 二分类:将文本情感分为
积极(positive,也叫正向、正面)、消极(negative,也叫负向、负面)两种。 - 三分类:在二分类基础上,将文本情感分为
积极、消极、中立(neutral,也叫中性)三种。 - 多分类:考虑到人类情绪的复杂性,又有人提出将文本情感分为喜、哀、怒、惧、恶、惊六种,喜对应积极,惊包含积极与消极,其余四种均为消极。
二分类与多分类中出现的“积极”、“消极”、“中立”等类别,叫做一段文本的 情感极性标签。
文本情感分类任务的最终目标,就是教会计算机,按照我们人类理解语言的模式,正确地解读出一段文本中蕴含的情感色彩,得出它的情感极性标签。
由于二分类法直观、简单,分类准确率高于其它分类标准,因而被广泛应用在各类人工智能应用中。

实现文本情感分类最简单的方法,便是 统计学方法。
统计学方法
前面我们提过:
文本类信息的特征是词语出现的
次数和位置
因此分析文本情感时,我们依然要从词语出发。
统计学方法分析文本情感极性的思路十分简单。研究者们请教语言学专家,按照经验和语言学规律,为常见词语赋予 情感值,并根据实际使用效果不断迭代,最终形成 情感词典。
一个词语的情感值,不仅由它本身含义决定,也由它出现的语境决定。比如“真”“善”“美”是形容优良品质的词。人们使用这些词语时,往往带有对美好的向往。因而它们的情感值是正值。而很多人谈论数学时,会加上“哎,太难了”等评价。所以“数学”这一中性的名词,其情感值也是负值。
储存情感词典的方式有很多,数据量比较小时,我们可以用 Python 中的 字典 类型保存,就像这样:
# 简单情感词典
senti_dict = {
'即使': 0.839603065334,
'是': -0.252600480826,
'数学': -1.55827119652,
'这样': -0.583219685861,
'的': 0.0353323193687,
'成熟': 1.31819982878,
'学科': 0.237792087229,
}
可以看到,字典 senti_dict 中储存着一个个 词语-情感值 键值对。即使 的情感值大约为 0.8396,大于 0,说明它带有的情感色彩是偏 积极 的,并且相较于情感值约为 0.2378 的 学科,它积极程度更高。而 数学 的情感值约为 -1.5583,带有的情感色彩偏向 消极。
有了情感词典,接下来,我们只要把句子拆成词语,并在情感词典中逐个查找词语对应情感值,再把情感值相加,就能得到整句话的 情感得分 了。
例如现在我们编写一个程序,分析以下的这句话:
即使是数学这样的成熟学科有时我们也理不清边界, 而像人工智能这样朝令夕改的更是不容易闹清楚了。
首先我们使用一个模块对这句话进行一个预处理(进行词语的手动拆分),并且提供一个情感词典。
模块:
# 模块名为data
sentence = '即使 是 数学 这样 的 成熟 学科 有时 我们 也 理不清 边界 而 像 人工智能 这样 朝令夕改 的 更是 不 容易 闹清楚 了'
# 本情感词典来源于
senti_dict = {
'即使': 0.839603065334,
'是': -0.252600480826,
'数学': -1.55827119652,
'这样': -0.583219685861,
'的': 0.0353323193687,
'成熟': 1.31819982878,
'学科': 0.237792087229,
'有时': 0.076137524806,
'我们': 1.16459874028,
'边界': 0.521423717761,
'而': -1.05423737475,
'像': 0.101821815241,
'人工智能': -0.202342581076,
'朝令夕改': -2.46796920412,
'更是': 0.47509147357,
'不': -1.06892630586,
'容易': 1.16597434456,
'闹': -0.665130539163,
'清楚': -0.232288031022,
'了': 0.380746624719
}
主程序:
from data import sentence, senti_dict
sum_score = 0
# 请在下方计算 sentence 的情感得分
for i in sentence.split(' '):
if i in senti_dict:
sum_score += senti_dict[i]
print('句子情感得分为:{}'.format(sum_score))
结果为:
句子情感得分为:-1.4187326538566
每句话的结果,我们可以用坐标 (情感得分, 情感极性) 表示。将所有句子处理结果画在平面直角坐标系中:

可以看到,情感积极的语句,得分集中在 0~10 分,情感消极的语句,得分集中在 -10~0 分。
所以我们可以得出初步结论:对于任何一个句子,如果它的情感得分为正(大于 0 分),则有极大概率是积极;反之为消极。
我们稍稍改造上面例子中的的代码,加上对情感极性的判断:
def get_sentiment(sentence):
sum_score = 0
# 用空格切分句子,并遍历分割出的每个词语
for word in sentence.split():
# 尝试获取 word 对应的情感值
score = senti_dict.get(word)
# 若返回值不为 None,说明该词语在情感词典中,累计得分
if score:
sum_score += score
# 情感得分为负,说明句子情感极性是消极的
if sum_score < 0:
return '消极'
# 否则为积极的
else:
return '积极'
一个简易的文本情感分析程序便完成了。但是这样的程序能达到“智能”的境界吗?
我们不得不说纯粹统计学的方法是存在局限性的。
统计学方法的局限性
①自然语言是在不断发展的
无论汉语还是英语,我们所使用的自然语言都是在不断发展的,既在创造新词,如 大数据、赋能,也在融合外来词,如 沙发、可乐,更有数不胜数的网络词汇,如 yyds(永远的神缩写)、油麦(幽默)。人工地维护情感词典费时费力,且严重滞后于语言的发展。
解决办法:针对这一点,研究者们也提出了自动提取、生成情感词典的方法,目前被广泛应用在各类人工智能应用中。
②难以适应复杂的语句
我们在计算情感得分时,只是简单地把各个词的情感值累加起来。这显然难以适应复杂的语句,比如:
Python 怎么那么难学? -> Python 学起来十分困难,情感偏消极
Python 也没那么难学。 -> Python 学起来没有想象中困难,情感偏积极
我们能轻松地分辨出,Python 怎么那么难学? 是消极的说法,而 Python 也没那么难学。 是积极的说法。
然而假若我们统计一下这两个句子的情感得分,便会发现,这两个句子情感得分都是负数,甚至第二个句子受否定词 没 的影响,得分更低。也就是说,程序“认为”它更消极。
解决办法:这一点困扰研究者们许久,至今依然没有非常完美的解决方案。
③数据量
要知道,机器是很笨的。我们人类天然地能够理解模糊问题,而机器,只能理解结构化的、准确的数据。因此想让机器在学习的过程中变得足够智能,必须增加习题数量(也就是我们人工标注极性的句子数量)、学习时间(机器学习算法下训练模型的时间)。
对于个人开发者而言,想要解决这些问题太困难了。
好在我们无需自己实现,只需站在巨人的肩膀上,便能摘取果实——借助开放平台。
我们使用开放平台 AI 服务的过程,实际上就是向指定 API 发送请求,拜托平台帮我们处理任务,再把结果返回给我们。
考虑到调用 API 的过程十分繁琐,多数厂商都贴心地把这些烦冗的过程与代码封装进了 SDK(Software Development Tookit,软件开发工具包),供你直接使用。
接下来我们以百度AI开放平台为例,去实现文本情感分析
SDK 实现文本情感分析
百度智能云控制台
使用百度账号登录百度智能云控制台 ,点击左上角 蓝色 导航按钮,能看到百度所有开放产品服务

我们选择人工智能下的 自然语言处理 服务,进入控制面板。
向下滑动页面,能看到每个 API 的名称、状态、调用量限制、QPS 限制。
以我们需要的文本情感分析任务为例,它在百度中对应的 API 叫做 情感倾向分析,个人认证用户拥有总计 50 万次免费调用额度,超过免费额度后,需要开通付费才能继续使用。具体计费、付费方式,可以浏览百度产品定价文档。
而 QPS(Query Per Second)限制,指的是每秒最多可以处理多少个请求。情感倾向分析接口的 QPS 限制为 2,所以我们在编写程序时需要注意控制调用服务的速度。这可以通过 time 模块的 sleep() 函数实现。
在正式使用百度 AI 服务前,我们还需要完成一项工作,创建应用。
创建自然语言处理应用
点击控制面板的创建应用即可。
创建完毕后,我们返回应用列表,能看到刚刚创建的应用,其中我们可以看到:
- App ID
- API Key
- Secret Key
App ID、API Key 和 Secret Key 由百度自动分配,是你所创建应用的唯一标识,你可以理解为它在百度服务中的“身份证”。
⚠️注意⚠️: App ID、API Key 和 Secret Key 十分重要。一旦泄漏,他人便可假借你的身份调用百度服务,后果不堪设想。
App ID、API Key 和 Secret Key 能够定位到你创建的具体应用。因此,我们也可以使用它,配合 SDK,在本地通过编写 Python 代码的方式实现人工智能程序.
到底什么是SDK
简单来说,SDK 是为开发者提供的一系列开发工具及文档的集合。

它就像一个工具箱。我们想实现什么功能,从其中取出对应的工具就能直接使用,不需要自己从 0 开始。可以说,SDK 大大减轻了程序员的工作量,让我们得以在前人的智慧成果上,放开双手去做更多的事。
提到“工具箱”“取出工具”,你想到了什么?
没错,模块!
Python 中的 SDK 通常是以 库(若干个模块的集合) 的形式存在的,需要用 pip 命令安装。之后我们就能在代码中调用库或者库中的模块,实现想要的功能。因此使用 SDK 开发,实际上就是调用厂商提供的第三方库。
这里的 内置 与 第三方 是相对于 Python 本身而言的。所有需要额外安装的模块、库,都是第三方库
如果你想在自己的计算机上使用百度 Python SDK,需要在命令行工具(Windows 电脑下为 cmd 或者 powershell,MacOS 下为 终端)中输入下列命令安装:
pip install baidu-aip -i https://pypi.tuna.tsinghua.edu.cn/simple
命令中的 pip 是 Python 内置的第三方模块管理器,install baidu-aip 表示安装 baidu-aip 库,也就是我们所需的 SDK。后面的 -i https://pypi.tuna.tsinghua.edu.cn/simple 表示使用清华镜像下载。国内使用镜像下载会更快,如果你在海外的话,可以去掉这一段。
使用 Mac 的用户,电脑内可能预装了 Python 2.7,此时 pip 指令绑定的是 Python 2.x 版本,因此需要使用 pip3 指令安装。完整命令是:pip3 install baidu-aip。
有些用户在安装完之后使用的时候会出现ModuleNotFoundError: No module named ‘chardet’。
解决这个问题我们只需要再安装第三方模块chardet即可。
装好的 SDK 中包含一个个 类,每个类代表着百度一项人工智能服务,如自然语言处理(AipNlp)、语音识别(AipSpeech)等等。可以通过 from … import … 语法导入:
# 导入自然语言处理类
from aip import AipNlp
# 导入语音识别类
from aip import AipSpeech
我们想使用百度的自然语言处理服务的话,需要传入应用的 App ID、API Key、Secret Key 来 实例化 AipNlp 类。
from aip import AipNlp
# 你的 App ID, API Key 及 Secret Key
APP_ID = 'xxxx'
API_KEY = 'xxxxxxx'
SECRET_KEY = 'xxx'
# 实例化 AipNlp 类,用以调用百度自然语言处理相关服务
client = AipNlp(APP_ID, API_KEY, SECRET_KEY)
情感倾向分析接口
接下来我们看看情感倾向分析接口的文档:

情感倾向分析接口的文档:https://cloud.baidu.com/doc/NLP/s/tk6z52b9z#%E6%83%85%E6%84%9F%E5%80%BE%E5%90%91%E5%88%86%E6%9E%90
我们参照文档的提示,可以编写以下代码:
from aip import AipNlp
# 你的 APP ID, API Key,及 Secret Key
APP_ID = 'xxxxxx'
API_KEY = 'xxxxxxxxxxxxxxxxxxx'
SECRET_KEY = 'xxxxxxxxxx'
sentence = '即使是数学这样的成熟学科,有时我们也理不清边界,而像人工智能这样朝令夕改的,更是不容易闹清楚了。'
# 实例化 AipNlp 类,用以调用百度自然语言处理相关服务
emotion = AipNlp(APP_ID, API_KEY, SECRET_KEY)
# 调用实例的 sentimentClassify() 方法,分析 sentence 的情感倾向
print(emotion.sentimentClassify(sentence))
# 打印分析结果
结果如下:
{
'log_id': 2060433065579573009, # 百度自动分配,每个请求的结果都不一样
'text': '即使是数学这样的成熟学科,有时我们也理不清边界,而像人工智能这样朝令夕改的,更是不容易闹清楚了。',
'items': [
{
'positive_prob': 0.169479,
'confidence': 0.62338,
'negative_prob': 0.830521,
'sentiment': 0
}
]
}
注意:我们在传入参数时,不仅能传入字符串类型变量,还能传入所有元素都是字符串的列表、元组变量。百度会帮我们把列表(或者元组)中所有字符串元素拼接成一个完整字符串(text 中对应内容),当作一句话进行处理,items 列表中依然只有一个元素,反应着多句话和在一起的情感极性。
如果程序报错也可以查看百度错误信息文档:

百度错误信息文档:
https://cloud.baidu.com/doc/NLP/s/tk6z52b9z#%E9%94%99%E8%AF%AF%E8%BF%94%E5%9B%9E%E6%A0%BC%E5%BC%8F