深度学习ANN识别手写数字数据集的FPGA实现(入门向)
目录
1 项目构思
2 神经元计算流程的实现
2.1 乘加模块的设计

1 项目构思
这里先写一点关于项目的构思,在后期实现过程中会慢慢填坑。
学习FPGA也有快一个月了,语言学的差不多了,准备实际上手一些项目。最近也阅读了一些关于优化CNN在硬件上的论文,运用loop pipeline或者loop unroll等优化计算。但突然发现自己现在最需要的还是先在FPGA上实现一个深度学习应用,于是还是先把目标放在了ANN上,也就是简单的全连接网络实现识别手写数字mnist数据集。
首要考虑的就是MAC与激活函数的实现。MAC就是乘加器,一个ANN单元必不可少的东西,激活函数呢,本来是一个连续函数,如何用离散的方式实现呢?目前还不清楚,看别人的项目是调用的现成IP核。这个问题值得看一下。相对于ANN,CNN的计算就显得简单粗暴了,卷积层的计算方式看起来很简单,但要考虑卷积核间并行与卷积层间并行问题,以及DSP单元(因为大多数CNN网络参数量很大,需要转定点数计算,便使用了DSP资源)资源分配问题。(当然不上板只是仿真的话不需要考虑实际硬件资源问题)
第二就是,数据读写。网络参数需要写成coe文件输入FPGA,或者小点的网络直接在代码中初始化,但这样很难修改网络参数与结构。另外图片数据的输入,可能还是需要加载到片外memory。
第三,数据量化。我们在FPGA上实现的是inference阶段,也就是前向传播的过程。训练这一过程是在其他平台进行的,因为训练这一部分并不能利用好FPGA的优势,FPGA主要还是在非批处理的时候,可以以很低的延迟进行图像处理,所以在部署到类似智能汽车里面的障碍物识别等应用中。在这里我们使用浮点数,因为网络很小,所以可能不需要考虑浮点数转定点等量化问题。但实际项目中,参数量化的问题是值得深入探讨的,如何在参数量化的同时不造成太多精度损失,这值得思考。(BNN,binary neural network也是量化的方向之一)另外,输入数据也可以进行量化的操作。这些都是我们平常“炼丹”的时候并不会考虑的问题lol。
所以目前最主要的就是实现一个简单的unit,包括乘加部分以及激活函数部分。参数则通过文件读取写入。之后则需要考虑层间连接如何部署的问题。
2 神经元计算流程的实现

这是一个全连接神经元的计算方式,一共m个W * X的积的和再加上偏置b,最后作为激活函数的输入。我们假设需要一个乘加模块和一个激活函数模块。
如何在fpga中实现这样的计算方式呢?最先想到且最简单的方式就是不在时间上对乘加模块进行复用,一个时钟上升沿到来时,直接把所有输入X与权重W,偏置b送到乘加模块进行计算,结果输出后送入激活函数模块。
但实际上这样的设计是不具有可行性的,一是一个单元的输入X个数,我们如果没有事先定义网络则m就是不确定的,模块端口数我们就不知道怎么定义了。(当然,可行的解决办法就是规定最大输入个数,但这样的做法不具有通用性)二是我们必须考虑FPGA板上资源的问题,不采用流水线的方式的话,是很难实现一个网络的并行计算的。这里重点介绍第二种设计方式。
我们乘加模块每个单元只为网络参数开启一个输入X端口和一个权重W端口。那么它的计算流程是怎样的呢?特别是对于刚开始接触这个领域的同学可能不清楚。我们接下来详细说一下:“我们在一个时钟周期内,将一组X与W送入乘加模块进行计算,结果放入一个用来进行最后累加的寄存器中,下一个时钟周期重复同样的事情,当最后一组W与X计算完成后,累加寄存器输出结果到激活函数并进行清零,以准备进行第二次计算流程,此时激活函数模块的输出端可获取这次计算流程的正确结果。”
2.1 乘加模块的设计
我们这里为了适配神经网络的数据类型float32,便采用了IEEE-754标准的单精度浮点数存储设计方式。

我们可以使用一下的公式将float32转换为32位的二进制数字。也可以直接在网上搜索单精度浮点数在线转换,输入10进制的数便可以看的对于单精度数的二进制表示结果,方便我们在verilog里面进行编写。
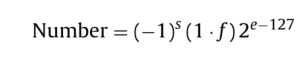
有公式了我们就可以自己设计模块来实现这个计算过程,不过考虑到复杂度以及最后实现的设计可配置性,我们采用了vivado现成的浮点数计算IP,它有很多可配置选项,包括延迟,所占资源,以及实现的计算公式选择等,不过对于不熟悉它的人来说,需要自己去读它的产品文档。先在最左侧IP Catalog里面,搜索floating point。之后可以在sources里面找到它右键进行customlize。
`timescale 1ns / 1ps
module junction(
x, weight, result,x_last,clk,result_valid,x_valid,w_valid
);
input clk;
input [31:0]x;
input x_last;
input [31:0]weight;
input x_valid;
input w_valid;
output [31:0]result;
output result_valid;
wire [31:0]y_out;
wire [31:0]result_out;
wire y_valid;
wire y_last;
reg[31:0]result;
wire acc_out_last;
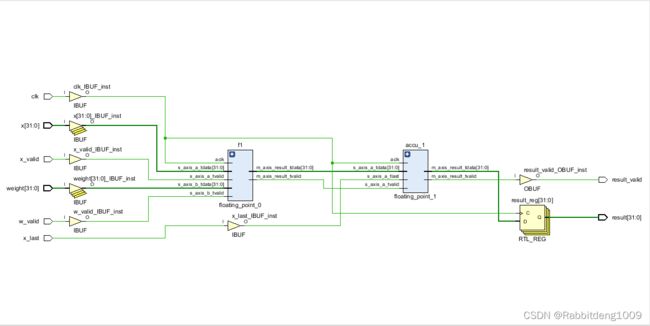
floating_point_0 f1(.aclk(clk),.s_axis_a_tvalid(x_valid),.s_axis_a_tdata(x),.s_axis_b_tvalid(w_valid),.s_axis_b_tdata(weight)
,.m_axis_result_tdata(y_out),.m_axis_result_tvalid(y_valid)); //weight: y= w*x + C bias: y=1*bias
floating_point_1 accu_1(.aclk(clk),. s_axis_a_tvalid(y_valid), .s_axis_a_tdata(y_out),
.s_axis_a_tlast(x_last),.m_axis_result_tvalid(result_valid),.m_axis_result_tdata(result_out),.m_axis_result_tlast(acc_out_last));
always@(posedge clk)
result <= result_out;
endmodule
floating_point_0是我们的浮点数乘法模块,在这里实例化进行使用,注意我们把工作方式设为非阻塞方式。
floating_point_1是我们的累加器,也是浮点数IP实现的。注意a_tlast的作用,它表示此输入是最后一个,下一个输入开启新的累加过程。
编写test_bench进行测试,权重W我们设置为0.5,X是0.5与2每个时钟交替送入。b_out便是累加器输出结果。y为存储结果的寄存器。
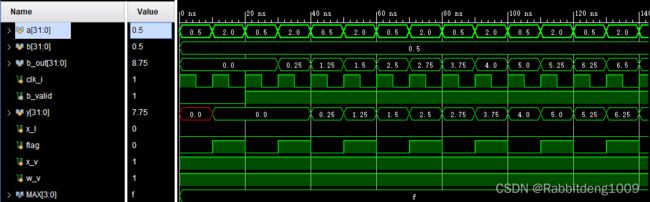
b_out前面为0是因为计算的延迟,这是我们在配置IP时候自定义的。
以上便实现到summing_function为止的所有功能。激活函数我们设计Sigmoid以及Relu两种。
我们考虑使用简单的分段函数进行近似Sigmoid。而们实际的网络架构中用的是Relu,它加快了收敛过程以及提高了准确率效果。