机器学习之带你用 sklearn 做特征工程及模型聚合,果断收藏
人工智能学习路径
第一章 全网最详细的Python入门思维导图,果断收藏
第二章 Python桌面应用开发(PyQT)入门思维导图,果断收藏
第三章 Python数据分析(Numpy和Pandas学习)入门思维导图,果断收藏
第四章 Python人工智能概念之机器学习基础入门思维导图,果断收藏
第五章 机器学习之KNN最邻近分类算法入门思维导图,果断收藏
第六章 机器学习之逻辑回归(Logistic Regression)原理讲解和实例应用,果断收藏
文章目录
- 人工智能学习路径
- 一、特征工程是什么?
- 二、特征选择目的
- 三、数据预处理
- 四、数据预处理方法
- 五、数据清洗案例
-
- 删除重复与冗余
- 处理缺失值
- 归一化与标准化
- 公式定义
- 归一化和标准化选择
- 归一化和标准化原因
- 六、特征选择方法(经典三刀)
-
- 实例应用一:卡方(Chi2)检验 鸢尾花数据集
- 实例应用二:三种特征选择方案实战对比--乳腺癌数据集
- 七、模型超参数调整
-
- 使用GridSearchCV
- 使用随机搜索选择模型
- 从多种学习算法中选择最佳模型
一、特征工程是什么?
有这么一句话在业界广泛流传:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。那特征工程到底是什么呢?顾名思义,其本质是一项工程活动,目的是最大限度地从原始数据中提取特征以供算法和模型使用。通过总结和归纳,特征工程包括以下方面:
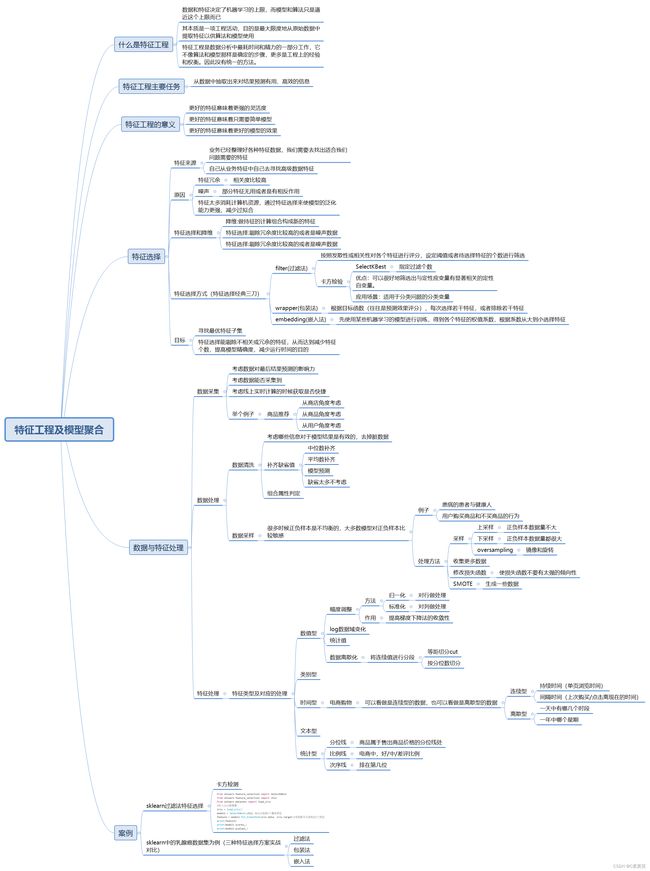
特征处理是特征工程的核心部分,sklearn提供了较为完整的特征处理方法,包括数据预处理,特征选择,降维等。首次接触到sklearn,通常会被其丰富且方便的算法模型库吸引,但是这里介绍的特征处理库也十分强大!
二、特征选择目的
- 减少特征数量、降维,使模型泛化能力更强,减少过拟合(即降低方差);
- 简化模型,使之更易于被研究人员或用户理解
- 缩短训练时间
三、数据预处理
通过特征提取,我们能得到未经处理的特征,这时的特征可能有以下问题:
-
不属于同一量纲:
即特征的规格不一样,不能够放在一起比较。无量纲化可以解决这一问题。
-
信息冗余:
对于某些定量特征,其包含的有效信息为区间划分,例如学习成绩,假若只关心“及格”或不“及格”,那么需要将定量的考分,转换成“1”和“0”表示及格和未及格。二值化可以解决这一问题。
-
定性特征不能直接使用:
某些机器学习算法和模型只能接受定量特征的输入,那么需要将定性特征转换为定量特征。最简单的方式是为每一种定性值指定一个定量值,但是这种方式过于灵活,增加了调参的工作。
-
存在缺失值:
缺失值需要补充。
-
信息利用率低:
不同的机器学习算法和模型对数据中信息的利用是不同的。
我们使用sklearn中的preproccessing库来进行数据预处理,可以覆盖以上问题的解决方案。
四、数据预处理方法
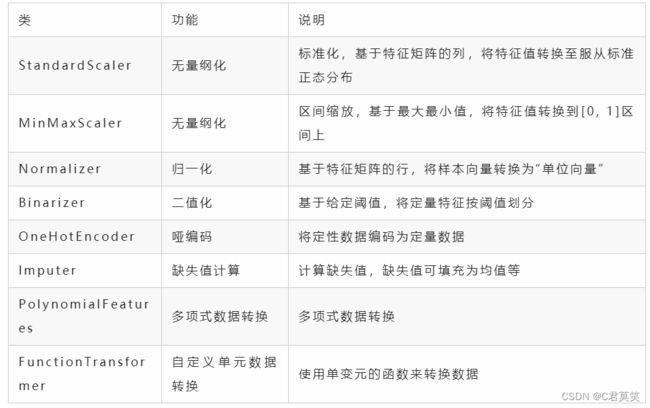
五、数据清洗案例
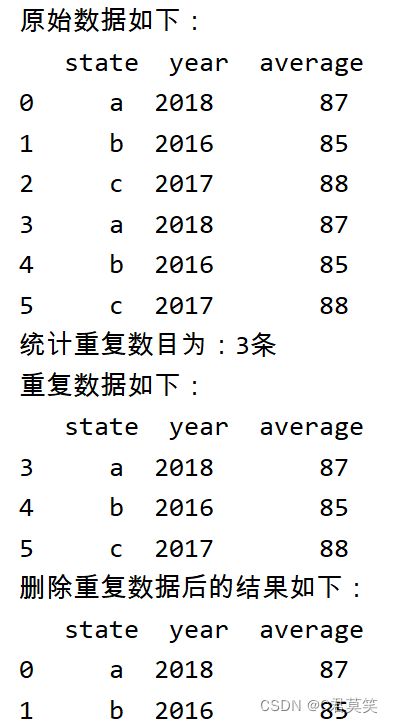
删除重复与冗余
import pandas as pd
import numpy as np
# 导入数据
data = pd.DataFrame({'state': ['a', 'b', 'c', 'a', 'b', 'c'], 'year': [2018, 2016, 2017, 2018, 2016, 2017],
'average': [87, 85, 88, 87, 85, 88]})
print("原始数据如下:\n", data)
##统计重复数目
data_dulicated_num = np.sum(data.duplicated())
print("统计重复数目为:{}条".format(data_dulicated_num))
##显示重复数据
data_dulicated = data.loc[data.duplicated()]
print("重复数据如下:\n", data_dulicated)
##删除重复数据 保留第一个
data_drop = data.drop_duplicates(keep='first')
print("删除重复数据后的结果如下:\n", data_drop)
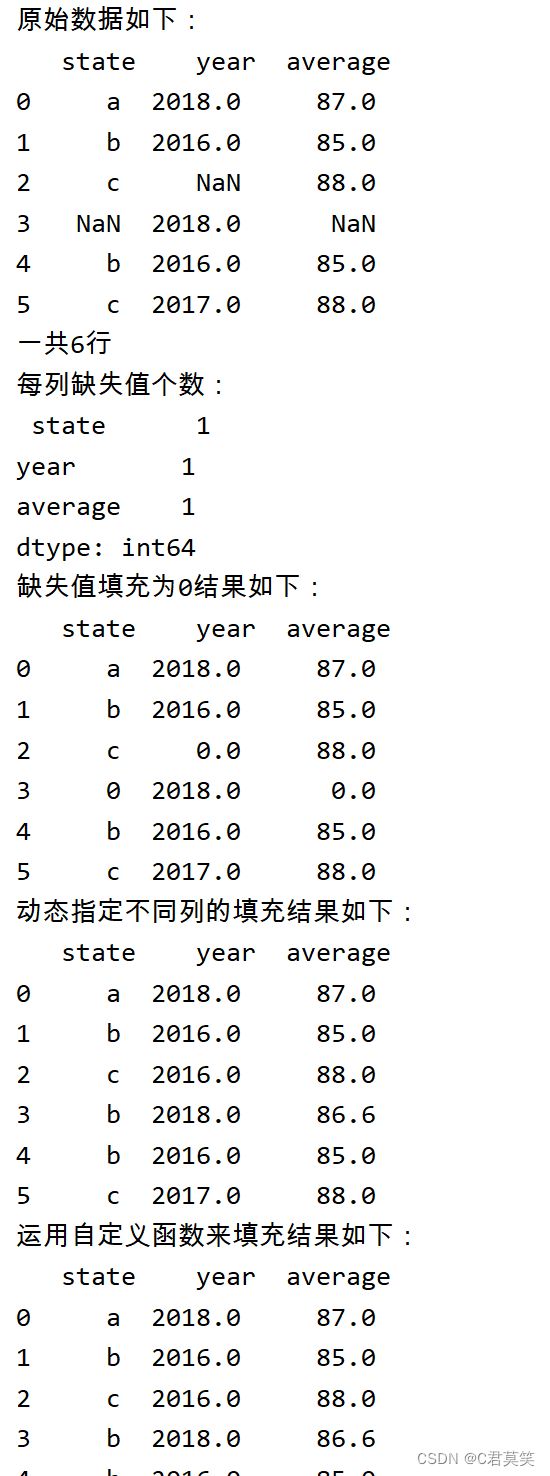
处理缺失值
import pandas as pd
import numpy as np
data = pd.DataFrame({'state': ['a', 'b', 'c', np.nan, 'b', 'c'], 'year': [2018, 2016, np.nan, 2018, 2016, 2017],
'average': [87, 85, 88, np.nan, 85, 88]})
print("原始数据如下:\n", data)
##统计行数及每列非空取值个数
print("一共{}行".format(len(data.index)))
##统计每列缺失值个数
print("每列缺失值个数:\n", data.isnull().sum(axis=0))
# 缺失值填充为0
print("缺失值填充为0结果如下:\n", data.fillna(0))
##4.对于不同的列,动态指定不同列的填充值,第一列指定众数填充,第二列使用众数,第三列使用均值
data['state'].fillna(data['state'].mode()[0], inplace=True)
data['year'].fillna(data['year'].mode()[0], inplace=True)
data['average'].fillna(value=data['average'].mean(), inplace=True)
print("动态指定不同列的填充结果如下:\n", data)
# 运用自定义函数来填充, 假设自定义函数就是取众数的第一个值
def SelfFunction(data):
return data.mode()[0]
data['state'].fillna(value=SelfFunction(data['state']), inplace=True)
data['year'].fillna(value=SelfFunction(data['year']), inplace=True)
data['average'].fillna(value=SelfFunction(data['average']), inplace=True)
print("运用自定义函数来填充结果如下:\n", data)
归一化与标准化
公式定义

归一化和标准化选择
- 若对输出结果范围有要求 ---- 用归一化
- 数据较为稳定,不存在极端的最大最小 ---- 用归一化
- 如果数据存在异常值和较多噪音 ---- 用标准化,可以间接通过中心化避免异常值和极端值的影响
归一化和标准化原因
- 消除量纲或数值对计算结果的影响
- 模型要求数据假定服从相应的分布
- 将数据缩放到指定的区间上
归一化、标准化案例
import pandas as pd
import numpy as np
# 数据变换
# 数据输入
# 将optional和required列进行归一化
data = pd.DataFrame({'student': ['张三', '李尔', '王五', '赵明', '王迪', '肖晓'], 'option': [3, 4, 2, 5, 3, 4],
'required': [90, 83, 67, 87, 81, 91], 'ideology': ['优', '良', '良', '优', '及格', '优']})
print("原始数据如下:\n", data)
data2 = data.copy()
data2['option'] = (data2['option'] - min(data2['option'])) / (max(data2['option'] - min(data2['option'])))
data2['required'] = (data2['required'] - min(data2['required'])) / (max(data2['required'] - min(data2['required'])))
print("将optional和required列进行归一化:\n", data2)
# 将optional和required列进行标准化
data3 = data.copy()
data3['option'] = (data3['option'] - np.mean(data3['option'])) / (data3['option']).std()
data3['required'] = (data3['required'] - np.mean(data3['required'])) / (data3['required']).std()
print("将optional和required列进行标准化:\n", data3)
六、特征选择方法(经典三刀)
当数据预处理完成后,我们需要选择有意义的特征输入机器学习的算法和模型进行训练。通常来说,从两个方面考虑来选择特征:
- 特征是否发散: 如果一个特征不发散,例如方差接近于0,也就是说样本在这个特征上基本上没有差异,这个特征对于样本的区分并没有什么用。
- 特征与目标的相关性: 这点比较显见,与目标相关性高的特征,应当优选选择。除方差法外,本文介绍的其他方法均从相关性考虑。
根据特征选择的形式又可以将特征选择方法分为3种:
- Filter:过滤法,按照发散性或者相关性对各个特征进行评分,设定阈值或者待选择阈值的个数,选择特征。
- Wrapper:包装法,根据目标函数(通常是预测效果评分),每次选择若干特征,或者排除若干特征。
- Embedded:嵌入法,先使用某些机器学习的算法和模型进行训练,得到各个特征的权值系数,根据系数从大到小选择特征。类似于Filter方法,但是是通过训练来确定特征的优劣。
实例应用一:卡方(Chi2)检验 鸢尾花数据集
使用sklearn中的IRIS(鸢尾花)数据集来对特征处理功能进行说明。IRIS数据集由Fisher在1936年整理,包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米。目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))。导入IRIS数据集的代码如下:
from sklearn.datasets import load_iris
#导入数据集
iris_datasets = load_iris()
iris_datas= iris_datasets.data
iris_target = iris_datasets.target
print("鸢尾花数据描述",iris_datasets.DESCR)
# print("鸢尾花数据集返回值",iris_datasets)
# print("鸢尾花数据集特征数据",iris_datasets['data']) #iris_datasets.data
# print("鸢尾花数据集目标值(标签)",iris_datasets.target)
我们使用sklearn中的feature_selection库来进行特征选择。
from sklearn.feature_selection import SelectKBest
from sklearn.feature_selection import chi2
from sklearn.datasets import load_iris
#导入IRIS数据集
iris = load_iris()
model1 = SelectKBest(chi2, k=2)#选择k个最佳特征
feature = model1.fit_transform(iris.data, iris.target)#该函数可以选择出k个特征
print(feature)
print(model1.scores_)
print(model1.pvalues_)
实例应用二:三种特征选择方案实战对比–乳腺癌数据集
以sklearn中的乳腺癌数据集为例,给出三种特征选择方案的基本实现,并简单对比特征选择结果。
核心源码:
#加载数据集并引入必备包
from sklearn.datasets import load_breast_cancer
from sklearn.model_selection import train_test_split
from sklearn.feature_selection import SelectFromModel, SelectKBest, RFE
from sklearn.ensemble import RandomForestClassifier
from datetime import datetime
start_time = datetime.now()
#默认数据集训练模型,通过在train_test_split中设置随机数种子确保后续切分一致
X, y = load_breast_cancer(return_X_y=True)
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
print(rf.fit(X_train, y_train))
print(rf.score(X_test, y_test))
end_time = datetime.now()
print('默认数据集训练模型 Duration: {}'.format(end_time - start_time))
#过滤法的特征选择方案,调用sklearn中的SelectKBest实现,
# 内部默认采用F检验来度量特征与标签间相关性,选择特征维度设置为20个
start_time = datetime.now()
X_skb = SelectKBest(k=20).fit_transform(X, y)
X_skb_train, X_skb_test, y_train, y_test = train_test_split(X_skb, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
print(rf.fit(X_skb_train, y_train))
print(rf.score(X_skb_test, y_test))
end_time = datetime.now()
print('过滤法的特征选择 Duration: {}'.format(end_time - start_time))
#包裹法的特征选择方案,调用sklearn中的RFE实现,
# 传入的目标函数也就是算法模型为随机森林,特征选择维度也设置为20个
start_time = datetime.now()
X_rfe = RFE(RandomForestClassifier(), n_features_to_select=20).fit_transform(X, y)
X_rfe_train, X_rfe_test, y_train, y_test = train_test_split(X_rfe, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
print(rf.fit(X_rfe_train, y_train))
print(rf.score(X_rfe_test, y_test))
end_time = datetime.now()
print('包裹法的特征选择 Duration: {}'.format(end_time - start_time))
#嵌入法的特征选择方案,调用sklearn中的SelectFromModel实现,
#依赖的算法模型也设置为随机森林,特征选择维度仍然是20个
start_time = datetime.now()
X_sfm = SelectFromModel(RandomForestClassifier(), threshold=-1, max_features=20).fit_transform(X, y)
X_sfm_train, X_sfm_test, y_train, y_test = train_test_split(X_sfm, y, random_state=3)
rf = RandomForestClassifier(max_depth=5, random_state=3)
print(rf.fit(X_sfm_train, y_train))
print(rf.score(X_sfm_test, y_test))
end_time = datetime.now()
print('嵌入法的特征选择 Duration: {}'.format(end_time - start_time))
实验效果
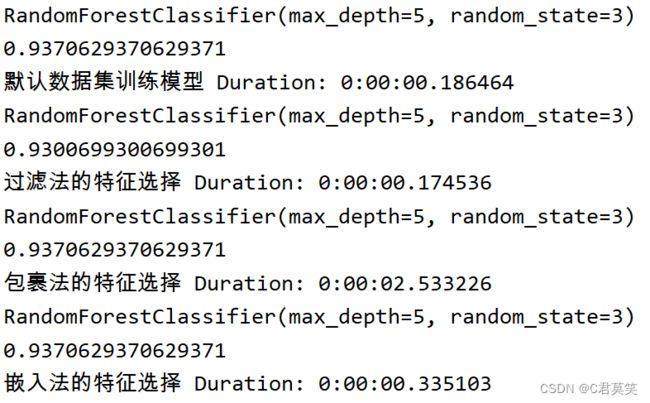
通过以上简单的对比实验可以发现:相较于原始全量特征的方案,在仅保留20维特征的情况下,过滤法带来了一定的算法性能损失,而包裹法和嵌入法则保持了相同的模型效果,但嵌入法的耗时明显更短。
七、模型超参数调整
在我们选择好一个模型后,接下来要做的是如何提高模型的精度。因此需要进行超参数调整,一种方法是手动调整超参数,直到找到超参数值的最佳组合。这将是一个非常复杂的工作,我们可以通过sklearn中的一些方法来进行搜索。我们所需要做的就是告诉它我们想用哪些超参数进行实验,以及尝试哪些值,然后它将使用交叉验证来评估所有可能的超参数值组合。
使用GridSearchCV
这种方法就是通过不断搜索匹配选出最好的超参数
# 导入所需库
import numpy as np
from sklearn import linear_model, datasets
from sklearn.model_selection import GridSearchCV
# 加载数据
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 创建模型
logistic = linear_model.LogisticRegression()
penalty = ['l1', 'l2']
C = np.logspace(0, 4, 10)
hyperparameters = dict(C=C, penalty=penalty)
# 创建网格搜索对象
gridsearch = GridSearchCV(logistic, hyperparameters, cv=5)
best_model = gridsearch.fit(features, target)
best_model.best_estimator_.get_params()
print(best_model.best_estimator_.get_params())
best_model.predict(features)
print(best_model.predict(features))

使用随机搜索选择模型
当您探索相对较少的组合时,网格搜索方法很好,如前一个示例中所示,但当超参数搜索空间较大时,通常最好使用randomizedsearchcv。该类的使用方式与GridSearchCVclass大致相同,但它不是尝试所有可能的组合,而是评估给定的通过在每次迭代中为每个HyperParameter选择一个随机值来计算随机组合的数量。
from sklearn import linear_model, datasets
from sklearn.model_selection import RandomizedSearchCV
from scipy.stats import uniform
# 加载数据
iris = datasets.load_iris()
features = iris.data
target = iris.target
# 创建模型
logistic = linear_model.LogisticRegression()
penalty = ['l1', 'l2']
#c来自一个均匀分布
c = uniform(loc=0, scale=4)
hyperparameters = dict(C=c, penalty=penalty)
randomizedsearchCV = RandomizedSearchCV(logistic, hyperparameters, random_state=1, n_iter=100, cv=5)
best_model = randomizedsearchCV.fit(features, target)
best_model.best_estimator_.get_params()
print(best_model.best_estimator_.get_params())
![]()
从多种学习算法中选择最佳模型
# 导入所需库
import numpy as np
from sklearn.ensemble import RandomForestClassifier
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn import linear_model, datasets
from sklearn.model_selection import GridSearchCV
np.random.seed(10)
# 加载数据
iris = datasets.load_iris()
features = iris.data
target = iris.target
pip = Pipeline([('classifier', RandomForestClassifier())])
search_space = [{'classifier':[LogisticRegression()],
'classifier__penalty': ['l1', 'l2'],
'classifier__C': np.logspace(0, 4, 10)},
{'classifier': [RandomForestClassifier()],
'classifier__n_estimators':[10, 100, 1000],
'classifier__max_features':[1, 2, 3]}]
gridsearch = GridSearchCV(pip, search_space, cv=5)
best_model = gridsearch.fit(features, target)
best_model.best_estimator_.get_params()
print(best_model.best_estimator_.get_params())
