From Goals, Waypoints & Paths To Long Term Human Trajectory Forecasting(二)
把把遇到甄姬那种傻鸟英雄和蠢驴选手,栓只狗在中路都比甄姬强。
在(一)的时候只是简单的对全文进行了意译,并没有涉及到网络结构。那接下来呢,对网络结构和代码进行分析与记录,由于网上还没有大神对该论文、代码进行解读,所以我的分析也仅代表自己的理解。
1. Y-Net网络结构
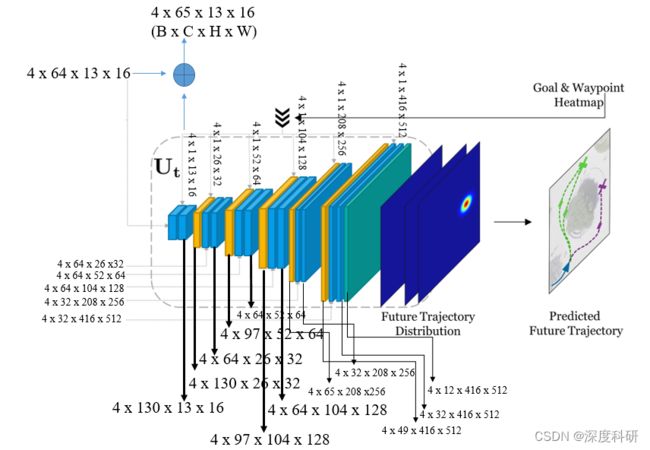
那Y-Net的网络结构长什么样子呢?Y-Net的网络结构就长下图这样子。看上去我好像在自言自语,其实你仔细揣摩就会发现,我真的是在自言自语。可以看到说,Y-Net网络输入的是一张张的图片,而不是序列。这一点很重要的,因为只有先搞清输入输出是什么,才能进行接下来的工作。那在(一)中的时候说,对于给定的RGB三通道图片![]() ,先通过语义分割网络得到图片
,先通过语义分割网络得到图片![]() 的语义分割图
的语义分割图 ,于此同时将行人的过去轨迹转化为轨迹热力图
,于此同时将行人的过去轨迹转化为轨迹热力图 ,然后将语义分割图与轨迹热力图进行concatenate拼接,之后送到我们的编码器
,然后将语义分割图与轨迹热力图进行concatenate拼接,之后送到我们的编码器![]() 当中。编码器
当中。编码器![]() 的最终输出
的最终输出![]() 作为解码器
作为解码器![]() 、
、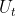 的输入,
的输入,![]() 的中间特征
的中间特征![]() 将与俩解码器的中间层输出进行skip connection,也就是进行特征融合。在Goal & Waypoint decoder中,最后的输出层由一个卷积层后跟一个像素级的sigmoid函数组成,对goal 和 waypont生成一个概率分布,从这个概率分布中采样我们所需的goal 和 waypoint,紧接着将采样得到的goal and waypoint转换为goal & waypoint Heatmap,记为
将与俩解码器的中间层输出进行skip connection,也就是进行特征融合。在Goal & Waypoint decoder中,最后的输出层由一个卷积层后跟一个像素级的sigmoid函数组成,对goal 和 waypont生成一个概率分布,从这个概率分布中采样我们所需的goal 和 waypoint,紧接着将采样得到的goal and waypoint转换为goal & waypoint Heatmap,记为![]() 。最后,对向量
。最后,对向量![]() 进行下采样以匹配中每个block的空间尺寸(从图中来看是要下采样6次,但是最后一个下采样箭头是不是画错位置了呢?另外,匹配的意思指的是”拼接“,而不是”输入“)
进行下采样以匹配中每个block的空间尺寸(从图中来看是要下采样6次,但是最后一个下采样箭头是不是画错位置了呢?另外,匹配的意思指的是”拼接“,而不是”输入“)
2. encoder 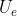
我们知道,编码器要干的事情就是提取图片的深层特征。Y-Net的encoder架构很显然是仿照U-Net encoder所设计的,encoder的输入是Segmentation Map与Trajectory Heatmap所拼接的张量tensor,那这个tensor的维度是多少呢?那我们先给定这个tensor的维度是![]() ,这在之后的代码解析中会涉及。我们来看看在代码中encoder是怎么实现的:
,这在之后的代码解析中会涉及。我们来看看在代码中encoder是怎么实现的:
class YNetEncoder(nn.Module):
def __init__(self, in_channels, channels=(64, 128, 256, 512, 512)):
"""
Encoder model
:param in_channels: int, semantic_classes + obs_len
:param channels: list, hidden layer channels
"""
super(YNetEncoder, self).__init__()
self.stages = nn.ModuleList()
# First block
self.stages.append(nn.Sequential(
nn.Conv2d(in_channels, channels[0], kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
))
# Subsequent blocks, each starting with MaxPool
for i in range(len(channels)-1):
self.stages.append(nn.Sequential(
nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False),
nn.Conv2d(channels[i], channels[i+1], kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(channels[i+1], channels[i+1], kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True)))
# Last MaxPool layer before passing the features into decoder
self.stages.append(nn.Sequential(nn.MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)))
def forward(self, x):
# Saves the feature maps Tensor of each layer into a list, as we will later need them again for the decoder
features = []
for stage in self.stages:
x = stage(x)
features.append(x)
return features显然,encoder的架构是很简单的,相应的注释都在代码中。我们来看一下前向传播过程:前向传播实际上就是数据输入将搭好的架构当中:

每一层的输出如下图所示:
2. decoder 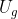
解码器实际上就是要恢复原图的大小,并融合深层的特征。那解码器![]() 是怎么实现该功能的呢?从图中我们可以看到,
是怎么实现该功能的呢?从图中我们可以看到,![]() 首先会被送到
首先会被送到![]() 的center block当中去,然后再将center block的输出送到接下来的模块。接下来的模块是反卷积——skip connection——卷积的重复操作:
的center block当中去,然后再将center block的输出送到接下来的模块。接下来的模块是反卷积——skip connection——卷积的重复操作:
class YNetDecoder(nn.Module):
def __init__(self, encoder_channels, decoder_channels, output_len, traj=False):
"""
Decoder models
:param encoder_channels: list, encoder channels, used for skip connections
:param decoder_channels: list, decoder channels
:param output_len: int, pred_len
:param traj: False or int, if False -> Goal and waypoint predictor, if int -> number of waypoints
"""
super(YNetDecoder, self).__init__()
# The trajectory decoder takes in addition the conditioned goal and waypoints as an additional image channel
if traj:
encoder_channels = [channel+traj for channel in encoder_channels] # encoder_channels:[33,33,65,65,65] ; traj = 1
encoder_channels = encoder_channels[::-1] # reverse channels to start from head of encoder; encoder_channels:goal[64,64,64,32,32] traj[65,65,65,33,33]
center_channels = encoder_channels[0]
decoder_channels = decoder_channels
# The center layer (the layer with the smallest feature map size)
self.center = nn.Sequential(
nn.Conv2d(center_channels, center_channels*2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(center_channels*2, center_channels*2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True)
)
# Determine the upsample channel dimensions
upsample_channels_in = [center_channels*2] + decoder_channels[:-1] # upsample_channels_in:goal[128,64,64,64,32] traj[130,64,64,64,32]
upsample_channels_out = [num_channel // 2 for num_channel in upsample_channels_in] # upsample_channels_out:goal[64,32,32,32,16] traj[65,32,32,32,16]
# Upsampling consists of bilinear upsampling + 3x3 Conv, here the 3x3 Conv is defined
self.upsample_conv = [
nn.Conv2d(in_channels_, out_channels_, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
for in_channels_, out_channels_ in zip(upsample_channels_in, upsample_channels_out)] # zip=goal[(128,64),(64,32),(64,32),(64,32),(32,16)] traj[(130,65),(64,32),(64,32),(64,32),(32,16)]
self.upsample_conv = nn.ModuleList(self.upsample_conv)
# Determine the input and output channel dimensions of each layer in the decoder
# As we concat the encoded feature and decoded features we have to sum both dims
in_channels = [enc + dec for enc, dec in zip(encoder_channels, upsample_channels_out)] # zip=goal[(64,64),(64,32),(64,32),(32,32),(32,16)] traj[(65,65),(65,32),(65,32),(33,32),(33,16)]
out_channels = decoder_channels # out_channels:[64,64,64,32,32] in_channels:goal[128,96,96,64,48] traj[130,97,97,65,49]
self.decoder = [nn.Sequential(
nn.Conv2d(in_channels_, out_channels_, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels_, out_channels_, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True))
for in_channels_, out_channels_ in zip(in_channels, out_channels)] # zip=goal[(128,64),(96,64),(96,64),(64,32),(48,32)] traj[(130,64),(97,64),(97,64),(65,32),(49,32)]
self.decoder = nn.ModuleList(self.decoder)
# Final 1x1 Conv prediction to get our heatmap logits (before softmax)
self.predictor = nn.Conv2d(in_channels=decoder_channels[-1], out_channels=output_len, kernel_size=1, stride=1, padding=0)
def forward(self, features):
# Takes in the list of feature maps from the encoder. Trajectory predictor in addition the goal and waypoint heatmaps
features = features[::-1] # reverse the order of encoded features, as the decoder starts from the smallest image
center_feature = features[0]
x = self.center(center_feature)
for i, (feature, module, upsample_conv) in enumerate(zip(features[1:], self.decoder, self.upsample_conv)):
x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False) # bilinear interpolation for upsampling
x = upsample_conv(x) # 3x3 conv for upsampling
x = torch.cat([x, feature], dim=1) # concat encoder and decoder features
x = module(x) # Conv
x = self.predictor(x) # last predictor layer
return x我们来看前向传播过程:在encoder的前向传播代码中,会将六层的future特征预存在feature[ ]中,这是为了在decoder中方便进行特征融合。读过U-Net的朋友应该知道,特征融合应该有相同的维度(当然channel数可以不同)。所以在![]() 的前向传播过程中,首先将encoder保存的特征进行逆排序,然后将feature进行切片——也就是代码中的feature[0]——赋给center_feature。经过两层卷积后以center_feature的输出维度作为后续block的输入x。在for循环当中,enumerate()是枚举函数,zip()函数将对应的元素打包成一个个元组,F.interpolate()对输入的x进行插值,为接下来上采样做准备;torch.cat()将encoder中间层的特征与decoder进行concatenate拼接,拼接好后输入到module()模块,该模块在decoder该类中有所定义,实际上就是decoder架构中反卷积后的两层卷积层。在for循环完之后,有一个self.predictor(),同样得,它在decoder该类中有定义,实际上就是
的前向传播过程中,首先将encoder保存的特征进行逆排序,然后将feature进行切片——也就是代码中的feature[0]——赋给center_feature。经过两层卷积后以center_feature的输出维度作为后续block的输入x。在for循环当中,enumerate()是枚举函数,zip()函数将对应的元素打包成一个个元组,F.interpolate()对输入的x进行插值,为接下来上采样做准备;torch.cat()将encoder中间层的特征与decoder进行concatenate拼接,拼接好后输入到module()模块,该模块在decoder该类中有所定义,实际上就是decoder架构中反卷积后的两层卷积层。在for循环完之后,有一个self.predictor(),同样得,它在decoder该类中有定义,实际上就是![]() 的输出层,经过它我们将得到goal $ waypoint heatmap logits.
的输出层,经过它我们将得到goal $ waypoint heatmap logits.
每一层的输出如下:

3. decoder
上面说过, 将采样得到的goal and waypoint转换为goal & waypoint Heatmap,记为![]() 。最后,对向量
。最后,对向量![]() 进行下采样以匹配中每个block的空间尺寸。采样的过程该怎么用代码实现呢?
进行下采样以匹配中每个block的空间尺寸。采样的过程该怎么用代码实现呢?
gt_waypoints_maps_downsampled = [nn.AvgPool2d(kernel_size=2**i, stride=2**i)(gt_waypoint_map) for i in range(1, len(features))]
gt_waypoints_maps_downsampled = [gt_waypoint_map] + gt_waypoints_maps_downsampled采样的结果将保存在列表里,将随![]() 、
、![]() 一同输入到当中:
一同输入到当中:
traj_input = [torch.cat([feature, goal], dim=1) for feature, goal in zip(features, gt_waypoints_maps_downsampled)]
pred_traj_map = model.pred_traj(traj_input)这一行代码一定要注意,得到的traj_input的输出为:(4,33,416,512),(4,33,208,256),(4,65,104,128),(4,65,52,64),(4,65,26,32),(4,65,13,16),从代码中我们可以看到,zip()函数将来自![]() 的特征即该行代码里的feature,与对
的特征即该行代码里的feature,与对![]() 下采样的结果打包成了元组,然后再进行concat拼接得到traj_input的输出。所以,待会在前向传播的时候,已经有了来自下采样的拼接,所以我希望读者看到这的时候不会疑惑。
下采样的结果打包成了元组,然后再进行concat拼接得到traj_input的输出。所以,待会在前向传播的时候,已经有了来自下采样的拼接,所以我希望读者看到这的时候不会疑惑。
那如何实现的网络架构呢?
class YNetDecoder(nn.Module):
def __init__(self, encoder_channels, decoder_channels, output_len, traj=False):
"""
Decoder models
:param encoder_channels: list, encoder channels, used for skip connections
:param decoder_channels: list, decoder channels
:param output_len: int, pred_len
:param traj: False or int, if False -> Goal and waypoint predictor, if int -> number of waypoints
"""
super(YNetDecoder, self).__init__()
# The trajectory decoder takes in addition the conditioned goal and waypoints as an additional image channel
if traj:
encoder_channels = [channel+traj for channel in encoder_channels] # encoder_channels:[33,33,65,65,65] ; traj = 1
encoder_channels = encoder_channels[::-1] # reverse channels to start from head of encoder; encoder_channels:goal[64,64,64,32,32] traj[65,65,65,33,33]
center_channels = encoder_channels[0]
decoder_channels = decoder_channels
# The center layer (the layer with the smallest feature map size)
self.center = nn.Sequential(
nn.Conv2d(center_channels, center_channels*2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(center_channels*2, center_channels*2, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True)
)
# Determine the upsample channel dimensions
upsample_channels_in = [center_channels*2] + decoder_channels[:-1] # upsample_channels_in:goal[128,64,64,64,32] traj[130,64,64,64,32]
upsample_channels_out = [num_channel // 2 for num_channel in upsample_channels_in] # upsample_channels_out:goal[64,32,32,32,16] traj[65,32,32,32,16]
# Upsampling consists of bilinear upsampling + 3x3 Conv, here the 3x3 Conv is defined
self.upsample_conv = [
nn.Conv2d(in_channels_, out_channels_, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
for in_channels_, out_channels_ in zip(upsample_channels_in, upsample_channels_out)] # zip=goal[(128,64),(64,32),(64,32),(64,32),(32,16)] traj[(130,65),(64,32),(64,32),(64,32),(32,16)]
self.upsample_conv = nn.ModuleList(self.upsample_conv)
# Determine the input and output channel dimensions of each layer in the decoder
# As we concat the encoded feature and decoded features we have to sum both dims
in_channels = [enc + dec for enc, dec in zip(encoder_channels, upsample_channels_out)] # zip=goal[(64,64),(64,32),(64,32),(32,32),(32,16)] traj[(65,65),(65,32),(65,32),(33,32),(33,16)]
out_channels = decoder_channels # out_channels:[64,64,64,32,32] in_channels:goal[128,96,96,64,48] traj[130,97,97,65,49]
self.decoder = [nn.Sequential(
nn.Conv2d(in_channels_, out_channels_, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels_, out_channels_, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1)),
nn.ReLU(inplace=True))
for in_channels_, out_channels_ in zip(in_channels, out_channels)] # zip=goal[(128,64),(96,64),(96,64),(64,32),(48,32)] traj[(130,64),(97,64),(97,64),(65,32),(49,32)]
self.decoder = nn.ModuleList(self.decoder)
# Final 1x1 Conv prediction to get our heatmap logits (before softmax)
self.predictor = nn.Conv2d(in_channels=decoder_channels[-1], out_channels=output_len, kernel_size=1, stride=1, padding=0)
def forward(self, features):
# Takes in the list of feature maps from the encoder. Trajectory predictor in addition the goal and waypoint heatmaps
features = features[::-1] # reverse the order of encoded features, as the decoder starts from the smallest image
center_feature = features[0]
x = self.center(center_feature)
for i, (feature, module, upsample_conv) in enumerate(zip(features[1:], self.decoder, self.upsample_conv)):
x = F.interpolate(x, scale_factor=2, mode='bilinear', align_corners=False) # bilinear interpolation for upsampling
x = upsample_conv(x) # 3x3 conv for upsampling
x = torch.cat([x, feature], dim=1) # concat encoder and decoder features
x = module(x) # Conv
x = self.predictor(x) # last predictor layer
return x 实际上可以看到,的网络结构与![]() 并没有太大区别,不同的是的输入除了
并没有太大区别,不同的是的输入除了![]() 之外,还有下采样
之外,还有下采样![]() 的结果。前向传播的过程与
的结果。前向传播的过程与![]() 是一样的,这里就不在赘述。需要注意的是:前向传播中的feature实际上被赋予的是上面提到的traj_input的值。
是一样的,这里就不在赘述。需要注意的是:前向传播中的feature实际上被赋予的是上面提到的traj_input的值。
每一层的输入输出如下:
下次我们来看具体细节