Pytorch框架中余弦相似度(Cosine similarity)、欧氏距离(Euclidean distance)源码解析
一、矩阵操作用于计算余弦相似度
余弦相似度:
![]()
我们知道,分子是矩阵的乘法,分母是两个标量的乘积。分母好办,关键是如何在计算分子?很简单,我们可以将公式变变形:
![]()
那么我们只需在矩阵乘法前,使其归一化,乘法之后就是余弦相似度了,来看一下代码(参考:https://zhuanlan.zhihu.com/p/383675457)
import torch
##计算两个特征的余弦相似度
def normalize(x, axis=-1):
x = 1. * x / (torch.norm(x, 2, axis, keepdim=True).expand_as(x) + 1e-12)
return x
##特征向量a
a=torch.rand(4,512)
##特征向量b
b=torch.rand(6,512)
##特征向量进行归一化
a,b=normalize(a),normalize(b)
##矩阵乘法求余弦相似度
cos=1-torch.mm(a,b.permute(1,0))
cos.shape
#输出
torch.Size([4, 6])我们来逐行解析一下这段代码吧。
x = 1. * x / (torch.norm(x, 2, axis, keepdim=True).expand_as(x) + 1e-12)这是归一化的公式,为什么是这个公式,我也不太明白。不过不妨碍我们解析。看到 torch.norm(x, 2, axis, keepdim=True) ,这是一个非常重要的知识点:torch.norm( input, p, din, out = None, keepdim = False )该函数的功能是求指定维度上的范数 ;其次看到 expand_as(tensor)函数,这是将张量scale扩展为参数tensor的大小。我这么说可能不太明白?那就糊涂着吧。
;其次看到 expand_as(tensor)函数,这是将张量scale扩展为参数tensor的大小。我这么说可能不太明白?那就糊涂着吧。
##特征向量a
a=torch.rand(4,512)
##特征向量b
b=torch.rand(6,512)
##特征向量进行归一化
a,b=normalize(a),normalize(b) 这三行就很简单了,从最后一行来看,就是把特征向量a,b归一化。这里面主要要知道 torch.rand(*sizes,out=None) 函数的用法。torch.rand(*sizes,out=None) 是均匀分布,返回的张量包含从区间(0,1)的均匀分布中随机抽取的一组随机数。第一个参数*size定义了输出张量的形状,也就是一个多大的矩阵。不明白?举个例子,比如 t1 = torch.rand(2,3),那它返回一个张量,张量的大小就是一个二行三列的矩阵,结果就是在(0,1)上随机抽取的随机数:
cos=1-torch.mm(a,b.permute(1,0))
cos.shape这就在求余弦相似度了,注意一下permute()函数,permute作用为调换Tensor的维度,参数为调换的维度。例如对于一个二维Tensor来说,调用tensor.permute(1,0)意为将1轴(列轴)与0轴(行轴)调换,相当于进行转置。
二、矩阵操作用于计算欧式距离
代码来自Triplet Loss,实质上都是这样写的,没有大碍。
先搞清楚原理(参考:https://blog.csdn.net/frankzd/article/details/80251042)现在我们有大小为 M X D 的矩阵P,和大小为 N X D 的矩阵C。记 是矩阵P的第i行,
是矩阵P的第i行,![]() ;
;![]() 是矩阵C的第j行,
是矩阵C的第j行,![]()
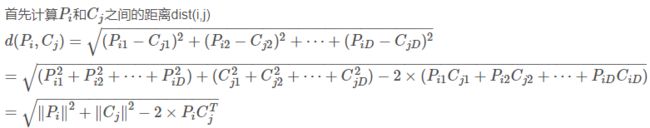

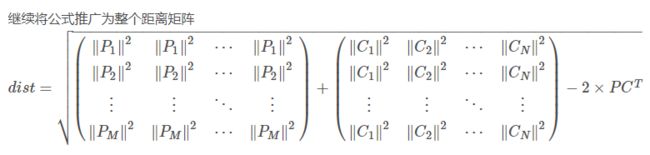
接着我们来看一下源代码怎么实现的:
def euclidean_dist(x, y):
"""
Args:
x: pytorch Variable, with shape [m, d]
y: pytorch Variable, with shape [n, d]
Returns:
dist: pytorch Variable, with shape [m, n]
"""
m, n = x.size(0), y.size(0)
xx = torch.pow(x, 2).sum(1, keepdim=True).expand(m, n)
yy = torch.pow(y, 2).sum(1, keepdim=True).expand(n, m).t()
dist = xx + yy
dist.addmm_(1, -2, x, y.t())
dist = dist.clamp(min=1e-12).sqrt() # for numerical stability
return dist现在我们来逐行解析 (参考:https://blog.csdn.net/IT_forlearn/article/details/100022244):
m, n = x.size(0), y.size(0)这一行比较简单,x的维度是[m,d],y的维度是[n,d],x.size(0) 就表示取x的第一个维度,即m。同理y.size(0)
xx = torch.pow(x, 2).sum(1, keepdim=True).expand(m, n)这一行就比较难理解了,xx经过pow()方法对每单个数据进行二次方操作后,在axis=1 方向(横向,就是第一列向最后一列的方向。怎么记呢?axis=0表示跨行,anxis=1表示跨列)加和,此时xx的shape为(m, 1),经过expand()方法,扩展n-1次,此时xx的shape为(m, n).
yy = torch.pow(y, 2).sum(1, keepdim=True).expand(n, m).t()
与上一行相比,yy会在上述操作后,再进行转置的操作。
dist = xx + yy这很简单,矩阵的加法
dist.addmm_(1, -2, x, y.t())这里要特别注意,代码是dist.addmm_不是dist.addmm,具体区别参考:https://blog.csdn.net/qq_36556893/article/details/90638449。dist.addmm_(1, -2, x, y.t()) 实现的公式为:dist=1*dist-2*(x @ ![]() )
)
dist = dist.clamp(min=1e-12).sqrt()clamp()函数可以限定dist内元素的最大最小范围,dist最后开方,得到样本之间的距离矩阵。