Why transformer?(二)
前面有说呢,seq2seq model里面会分成两块,一块是encoder,,另外一块是decoder。你input一个sequence,由encoder处理这个sequence,再把处理好的sequence丢给decoder,由decoder决定它要输出什么样的sequence。在前面的 Why transformer(一)里呢,我们有详细的剖析transformer encoder的架构。现在呢,我们来看一看transformer decoder是怎样运作的。
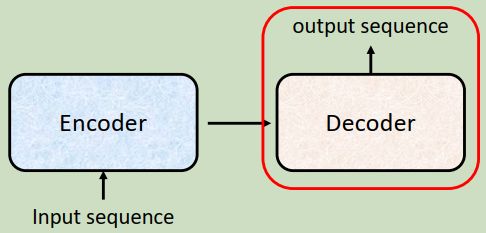
二、decoder
那decoder呢其实有两种,一种是Autoregressive的decoder,另一种是Non-Autoregressive的decoder。我们常用的是Autoregressive的decoder。那这个Autoregressive的decoder是怎么运作的呢?我们用语音辨识的例子来向大家说明。
语音辨识是怎样做的呢?提到语音辨识,就是输入一段声音输出一串文字。那你会把一段声音输入给encoder,输出是一排vector。我们在 Why transformer(一)有详细提到encoder是怎样运作的,这里就不再啰嗦了。那接下来呢就轮到decoder运作了,decoder要做的事情就是产生输出,由decoder产生语音辨识的结果。那decoder怎么产生这个语音辨识的结果呢?decoder要做的事情就是先把encoder的输出读进去,至于怎么读进去,这个我们在接下来会写到。

这里先假设encoder的输出是由某种方法读进decoder,这步我们等下在处理。那decoder怎么在语音辨识中产生一段文字呢?那首先呢你要先给decoder一个特殊的符号,这个特殊的符号代表“开始(beginning)” “beginning”也是用one-hot vactor来表示:其中一维是1,其它是0。在吃进去"beginning"之后,decoder会吐出一个向量,那这个vector里面有什么呢?这个vector的长度跟你的vocabulary的size是一样的。vocabulary指的是什么意思呢?你就先想好你的decoder输出的单位是什么。换句话说,假设今天我们做的是中文的语音辨识,我们的decoder输出的是中文,那你的vocabulary的size就是中文的方块字的数目。你要让你的decoder输出哪些可能的方块字,你就把它列在这边。

现在我们知道,在decoder吃进去"beginning"之后,decoder吐出的向量长度就跟你希望机器输出方块字的数目是一样长的。但decoder吐出的这个向量并不是最终的输出结果,只有分数最高的方块字才是最终的输出结果。
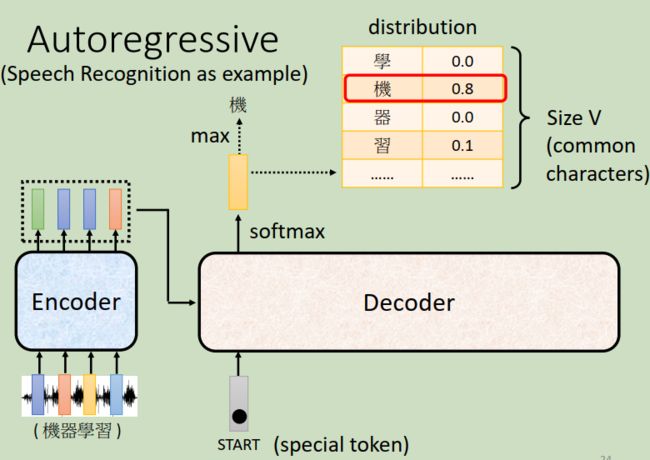
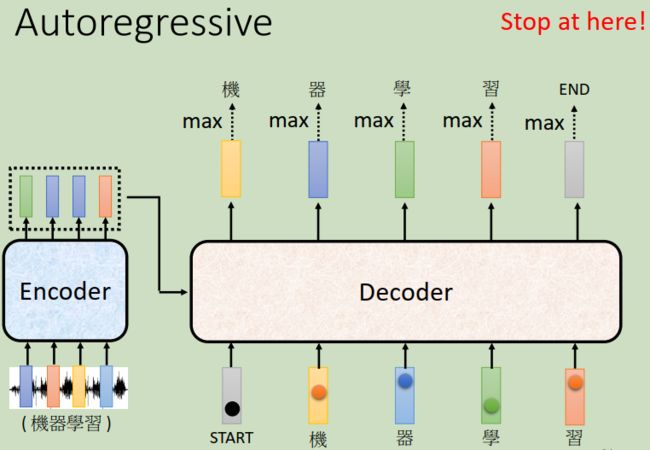
上图中“机”字的分数最高,所以输出“机” 。那接下来,你把“机”当作decoder新的input。原来decoder的input只有“beginning”这个特别的符号,现在除了“beginning”以外还有“机”作为它的input。那“机”呢也是表示为一个one-hot的vector。根据这两个输入呢decoder就要得出一个输出,输出一个蓝色的向量(如下图),根据softmax我们可以最终得到这个蓝色的向量输出是“器”。那接下来decoder会拿“器”当作它的input,现在decoder看到了“beginning”,看到了“机”,看到了“器”,那接下来就可能输出“学”...这个过程就反复的持续下去。decoder输出“学”以后,“学”会再被当做decoder输入,现在decoder看到了“beginning”,看到了“机”,看到了“器”,看到了“学”(那encoder这边也有输入了,只是我们等会再写),决定输出“习”
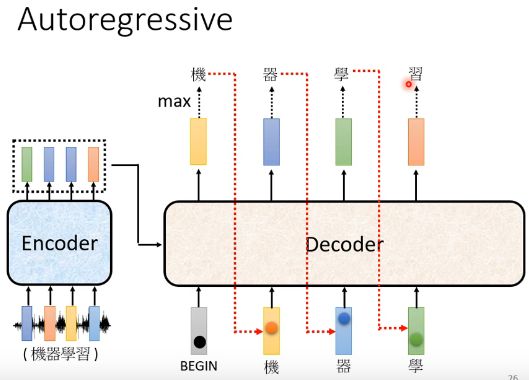
这边有一个关键的地方我们特意用红色的虚线给它标出来,也就是说decoder看到的输入其实是它在前一个时间点的输出。话句话说,decoder会把自己的输出当作接下来的输入。所以当decoder在产生一个句子的时候,它其实有可能看到错误的东西,因为它是看到自己前一步的输出嘛。 比如说decoder把机器的“器”辨识成了天气的“气”,那接下来decoder就会看到错误的辨识结果,但decoder还是会根据错误的辨识结果产生下一步正确的输出,比如说“学”。那decoder会不会发生“一步错步步错”的情况使整个句子都垮掉了呢?这又是一个深坑,不说话装高手先。
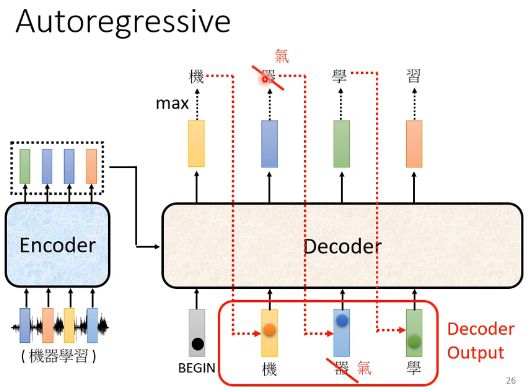
那接下来,我们来看一下decoder内部的结构长什么样子。在transformer里面,decoder是长这个样子的
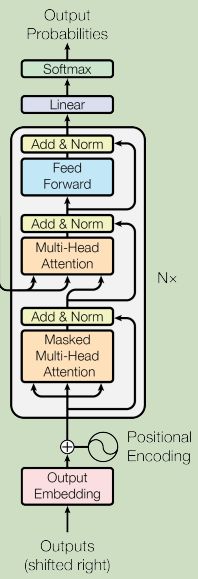
decoder看起来比encoder还要复杂一点 。那我们把encoder和decoder放在一起,稍微比较一下它们之间的差异。
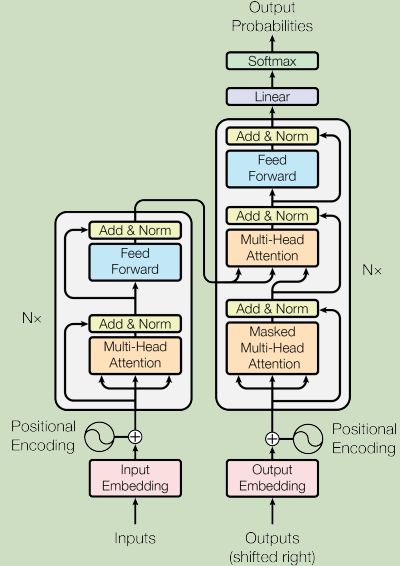
我们可以发现,如果把decoder中间那一部分盖起来(如下图所示),其实并没有那么大的差别。只不过在decoder最后我们会在做一个softmax,使得decoder的输出变为一个probabilities。
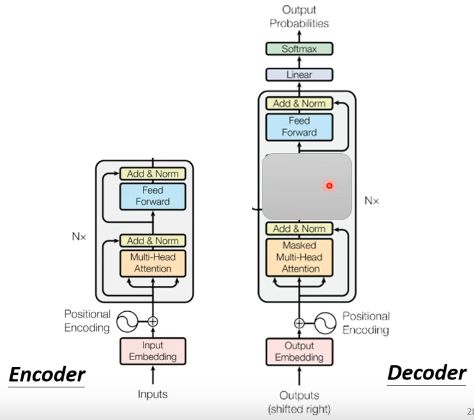
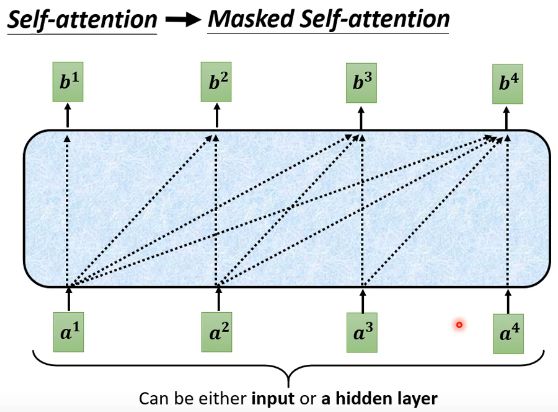
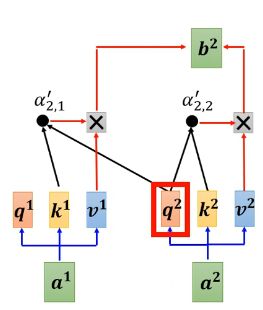
除了被遮挡起来的部分外,在decoder这边还有一处与encoder有一点差别:在Multi-Head Attention上面还加了一个Masked。这个Masked是什么意思呢? 这个Masked意思是这样的:先来简单回顾一下之前讲的self-attention,我们说输出b1的时候,其实是根据a1~a4所有的资讯去输出b1。那我们把self-attention转成Masked self-attention的时候,不同点在哪里呢?它的不同点是:现在不能考虑右边的部分。也就是产生b1的时候我们只能考虑a1的资讯,不能再考虑a2~a4的资讯;产生b2的时候只能考虑a1,a2的资讯,不能再考虑a3,a4的资讯;产生b3的时候只能考虑a1~a3的资讯,而不能考虑a4的资讯;产生b4的时候你可以用整个sequence的资讯。这个就是Masked self-attention
更具体一点, Masked self-attention做的事情是这样:我们要产生b2的时候,我们只拿a2的q与a1的k以及本身的k算attention score,不去管a2右边的地方,即:![]() ,
,![]() ;然后再分别乘上,
;然后再分别乘上,![]() 就加起来得到b2。
就加起来得到b2。
自然而然地,为什么要加Masked呢? 这件事情其实非常的直觉。你想想看我们decoder一开始的运作方式,它的输出是一个一个产生的,所以是先有a1,再有a2,再有a3,再有a4。这跟我们的self-attention不一样,原来的self-attention是一次整个输进你的model里面的,encoder是一次性把整个a1~a4都读进去。但是对decoder而言,先有a1,才有a2,才有a3,才有a4。所以实际上当你由a2计算b2的时候,你是没有a3,a4的,所以你根本就没办法把a3跟a4考虑进来,所以就是为什么在transformer论文的图上面特别强调说这不是一个一般的attention,而是Masked self-attention,意思就是想告诉你说,decoder的输出是一个一个产生的,所以它只能考虑它左边的东西,而没办法考虑它右边的东西
到这里,我们有一个关键的问题还没有提及,那就是decoder必须自己决定输出sequence的长度,换句话说,decoder必须学会自己断句,我们没有办法从输入的sequence的长度轻易的知道输出sequence的长度是多少,并不是说输入是四个向量,输出就一定是四个向量,decoder要学会自己停下来。比如说产生完”习“以后,decoder可能又会继续产生“惯”,接下来呢又一直持续产生下去,但我们希望decoder在产生”习”之后就停下来。 那怎么让decoder停下来呢?我们要做的事情其实就是要让decoder输出一个“断”的特殊标记。所以你要特别准备一个符号,这个符号就叫做“END”
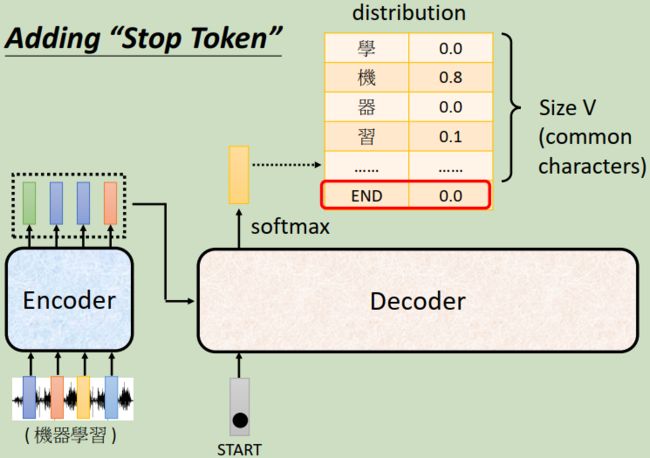
那我们期待说当decoder产生完“习”,再把“习”当作decoder的输入以后,decoder就要能够输出“END”。也就是说当把“习”当作输入以后,decoder看到了encoder输出的embedding,看到了“beginning”,看到了“机”,看到了“器”,看到了“学”,看到了“习”,decoder就要知道这个语音辨识的结果已经结束了,不需要再产生更多的词汇了,它产生出来的向量里面,这个“END”的probabilities必须要是最大的,然后就输出“END”这个符号,整个decoder产生sequence的过程就解结束了。那这个就是Autoregressive的decoder运作的方式。
好,那接下来,我们就要回答“encoder和decoder之间是怎么传递资讯”的
未完待续...