K-近邻算法讲解以及实战
1.概述
邻近算法,或者说K最近邻(KNN,K-NearestNeighbor)分类算法是数据挖掘分类技术中最简单的方法之一。所谓K最近邻,就是k个最近的邻居的意思,说的是每个样本都可以用它最接近的k个邻居来代表。Cover和Hart在1968年提出了最初的邻近算法。KNN是一种分类(classification)算法,它输入基于实例的学习(instance-based learning),属于懒惰学习(lazy learning)即KNN没有显式的学习过程,也就是说没有训练阶段,数据集事先已有了分类和特征值,待收到新样本后直接进行处理。与急切学习(eager learning)相对应。
换句话说:KNN是通过测量不同特征值之间的距离进行分类。
2.KNN算法描述
- 计算测试数据与各个训练数据之间的距离
- 按照距离的递增关系进行排序
- 选取距离最小的K个点
- 统计前k个点所在类别出现的次数(频率)
- 返回前k个点中频率最高的类别作为测试数据的预测分类
用下面这个例子来解释下大概的原理,如下所示
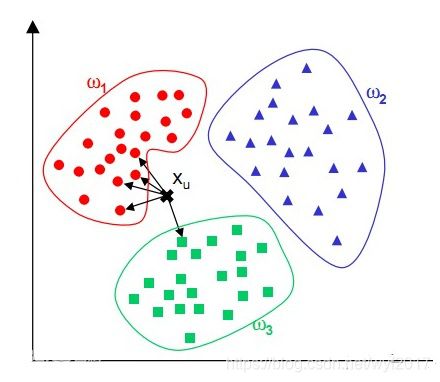
我们有三组样本数据ω1、ω2、ω3,测试数据为Xu,通过KNN算法,我们首先计算测试样本与样本数据之间的距离,然后取K个距离最近的点,然后统计这K个点所属类别的个数,最后取出现频数最高的那个点的类别作为预测样本的测试结果,从图中我们可以看到这里我们取K=5,然后这5个点中红色出现4次,绿色出现1次,最后我们将红色作为Xu的预测结果。
3.通过实战来运用KNN算法
这里我也是根据网上使用最多的一个实战项目来加深自己对KNN算法的理解,这个实战项目概述大致为:海伦女士一直使用在线约会网站寻找适合自己的约会对象。尽管约会网站会推荐不同的任选,但她并不是喜欢每一个人。经过一番总结,她发现自己交往过的人可以进行如下分类:1-不喜欢、2-有些喜欢、3-非常喜欢
飞行里程数 玩视频游戏百分比 每周消费的冰淇淋公升数 特征
40920 8.326976 0.953952 3 非常喜欢
14488 7.153469 1.673904 2 有些喜欢
26052 1.441871 0.805124 1 不喜欢
75136 13.147394 0.428964 1 不喜欢
38344 1.669788 0.134296 1 不喜欢
这里我们可以通过下面这个流程来实现这个算法
收集数据:可以使用爬虫进行数据的收集,也可以使用第三方提供的免费或收费的数据。一般来讲,数据放在txt文本文件中,按照一定的格式进行存储,便于解析及处理。
准备数据:使用Python解析、预处理数据。
分析数据:可以使用很多方法对数据进行分析,例如使用Matplotlib将数据可视化。
测试算法:计算错误率。
使用算法:错误率在可接受范围内,就可以运行k-近邻算法进行分类。
4.预处理数据
我们定义一个函数名为 filematrix(filename),其中filename为文件路径名,通过这个函数我们可以对数据进行预处理,然后返回预处理后的数据,代码如下:
'''
函数说明:打开并解析文件,对数据进行分类:1代表讨厌,2代表有些喜欢,3代表非常喜欢
'''
def filematrix(filename):
# 打开文件
fr = open(filename)
# 读取文件内容
getFile = fr.readlines()
# 获取文件行数
lines = len(getFile)
# 生成空矩阵,矩阵里面的元素为0
empty_Mat = np.zeros((lines,3)) # lines相当于行数,3为列数
# 分类标签向量
classLabelVector = []
# 行索引值
index = 0
for line in getFile:
# s.strip(rm),当rm空时,默认删除空白符(包括'\n','\r','\t',' ')
line = line.strip()
# 使用s.split(str="",num=string,cout(str))将字符串根据'\t'分隔符进行切片。
listFormLine = line.split('\t')
# print(listFormLine)
# 将数据前三列提取出来,存放到empty_Mat的矩阵中,也就是特征矩阵
empty_Mat[index,:] = listFormLine[:3]
# 每列的类别数据,就是 label 标签数据
classLabelVector.append(int(listFormLine[-1]))
# 行索引自增
index +=1
# 打印特征矩阵
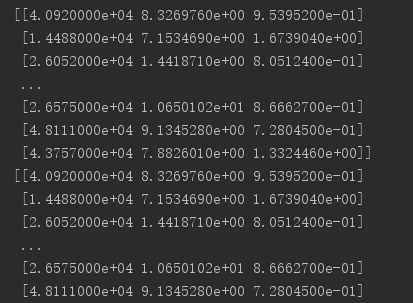
print(empty_Mat)
return empty_Mat,classLabelVector在主函数里面测试
if __name__ == '__main__':
filename = "D:\python-workspace\Machine_Learing\KNN\datingTestSet2.txt"
filematrix(filename)
运行结果如下:
|
|
5.可视化数据
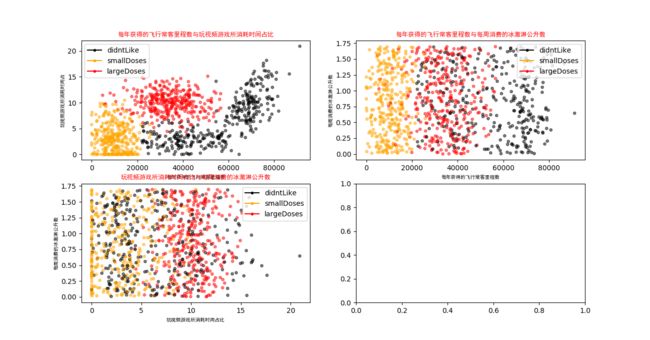
通过第4步我们获取到了我们需要的数据,但是我们想看看这三个特征:每年获得的飞行常客里程数、玩视频游戏所耗时间百分比
以及每周消费的冰淇淋公升数之间的关系,这里我们定义一个函数名字为:showdatas(datingDataMat,datingLabels)
其中 datingDataMat - 特征矩阵、datingLabels - 分类标签
def showdatas(datingDataMat,datingLabels):
# 设置汉字格式
font = FontProperties(fname=r"D:\python-workspace\SimHei.ttf", size=14)
# 将fig画布分隔成1行1列,不共享x轴和y轴,fig画布的大小为(13,8)
# 当nrow=2,nclos=2时,代表fig画布被分为四个区域,axs[0][0]表示第一行第一个区域
fig, axs = plt.subplots(nrows=2, ncols=2, sharex=False, sharey=False, figsize=(13, 8))
numberOfLabels = len(datingLabels)
LabelsColors = []
for i in datingLabels:
if i == 1:
LabelsColors.append('black')
if i == 2:
LabelsColors.append('orange')
if i == 3:
LabelsColors.append('red')
# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第二列(玩游戏)数据画散点数据,散点大小为15,透明度为0.5
axs[0][0].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 1], color=LabelsColors, s=15, alpha=.5)
# 设置标题,x轴label,y轴label
axs0_title_text = axs[0][0].set_title(u'每年获得的飞行常客里程数与玩视频游戏所消耗时间占比', FontProperties=font)
axs0_xlabel_text = axs[0][0].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs0_ylabel_text = axs[0][0].set_ylabel(u'玩视频游戏所消耗时间占', FontProperties=font)
plt.setp(axs0_title_text, size=9, weight='bold', color='red')
plt.setp(axs0_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs0_ylabel_text, size=7, weight='bold', color='black')
# 画出散点图,以datingDataMat矩阵的第一(飞行常客例程)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[0][1].scatter(x=datingDataMat[:, 0], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)
# 设置标题,x轴label,y轴label
axs1_title_text = axs[0][1].set_title(u'每年获得的飞行常客里程数与每周消费的冰激淋公升数', FontProperties=font)
axs1_xlabel_text = axs[0][1].set_xlabel(u'每年获得的飞行常客里程数', FontProperties=font)
axs1_ylabel_text = axs[0][1].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs1_title_text, size=9, weight='bold', color='red')
plt.setp(axs1_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs1_ylabel_text, size=7, weight='bold', color='black')
# 画出散点图,以datingDataMat矩阵的第二(玩游戏)、第三列(冰激凌)数据画散点数据,散点大小为15,透明度为0.5
axs[1][0].scatter(x=datingDataMat[:, 1], y=datingDataMat[:, 2], color=LabelsColors, s=15, alpha=.5)
# 设置标题,x轴label,y轴label
axs2_title_text = axs[1][0].set_title(u'玩视频游戏所消耗时间占比与每周消费的冰激淋公升数', FontProperties=font)
axs2_xlabel_text = axs[1][0].set_xlabel(u'玩视频游戏所消耗时间占比', FontProperties=font)
axs2_ylabel_text = axs[1][0].set_ylabel(u'每周消费的冰激淋公升数', FontProperties=font)
plt.setp(axs2_title_text, size=9, weight='bold', color='red')
plt.setp(axs2_xlabel_text, size=7, weight='bold', color='black')
plt.setp(axs2_ylabel_text, size=7, weight='bold', color='black')
# 设置图例
didntLike = mlines.Line2D([], [], color='black', marker='.',
markersize=6, label='didntLike')
smallDoses = mlines.Line2D([], [], color='orange', marker='.',
markersize=6, label='smallDoses')
largeDoses = mlines.Line2D([], [], color='red', marker='.',
markersize=6, label='largeDoses')
# 添加图例
axs[0][0].legend(handles=[didntLike, smallDoses, largeDoses])
axs[0][1].legend(handles=[didntLike, smallDoses, largeDoses])
axs[1][0].legend(handles=[didntLike, smallDoses, largeDoses])
# 显示图片
plt.show()
这里设置字体需要下载SimHei.ttf,然后将这个东西放到你项目目录下就可以,我这里我将资源链接放在文末
# 设置汉字格式
font = FontProperties(fname=r"D:\python-workspace\SimHei.ttf", size=14)在主函数里面调用这个函数如下所示:
if __name__ == '__main__':
filename = "D:\python-workspace\Machine_Learing\KNN\datingTestSet2.txt"
#filematrix(filename)
empty_Mats, classLabelVectors = filematrix(filename)
showdatas(empty_Mats, classLabelVectors)
运行结果如下:
|
|
6.通过KNN进行分类
接下来我们定义一个函数名字叫做classify(input, dataSet, label, k),其中input为测试数据、dataSet为样本数据、label为标签矩阵、K为我们需要选取的邻近点个数
def classify(input, dataSet, label, k):
# 计算dataSet矩阵的行数
dataSize = dataSet.shape[0]
# 计算欧式距离
diff = np.tile(input, (dataSize, 1)) - dataSet
sqdiff = diff ** 2 # 对矩阵中的每个元素求平方
squareDist = np.sum(sqdiff, axis=1) # 行向量分别相加,从而得到新的一个行向量
dist = squareDist ** 0.5 # 对距离进行开平方
# 对距离进行排序
sortedDistIndex = np.argsort(dist) # argsort()根据元素的值从小到大对元素进行排序,返回下标
classCount = {}
for i in range(k):
voteLabel = label[sortedDistIndex[i]]
# 对选取的K个样本所属的类别个数进行统计
classCount[voteLabel] = classCount.get(voteLabel, 0) + 1
# 选取出现的类别次数最多的类别
maxCount = 0
for key, value in classCount.items():
if value > maxCount:
maxCount = value
classes = key
return classes到我们写到这里的时候,我们会发现一个问题就是我们在计算样本之间的距离时候,因为样本的数据都是很大的数字,计算出来的结果也是很大,比如我们随便用一组数据计算下:
对比一下,如果我们输入每年获得的飞行常客里程数很小,所得到的结果简直天壤之别,所以为了解决因为数据之间量级不同而引起的误差我们需要对数据进行归一化处理。
怎么将数据归一化?这里我们的思想是:取值范围处理为0到1或者-1到1之间,采用下面的方法就可以做到
new_value = (old_value - min_value) / (max_value - min_value)
这里我们定义一个函数名为:autoNorm(dataSet),dataSet为数据集
'''
函数说明:对数据进行归一化
Parameters:
dataSet - 特征矩阵
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
'''
def autoNorm(dataSet):
# 获取数据的最大和最小值
maxValue = dataSet.max(0)
minValue = dataSet.min(0)
# 最大与最小值的差
diffs = maxValue - minValue
# shape(dataSet)返回dataSet的矩阵行、列数(建立与dataSet结构一样的矩阵)
normDataSet = np.zeros(np.shape(dataSet))
# 返回dataSet的行数
m = dataSet.shape[0]
# 原始值减去最小值
#normDataSet = dataSet - np.tile(minValue,(m,1))
# 除以最大和最小值的差,得到归一化数据
#normDataSet = normDataSet / np.tile(diffs,(m,1))
# 这一步相当于上面2个步骤
for i in range(1, m):
normDataSet[i, :] = (dataSet[i, :] - minValue) / diffs
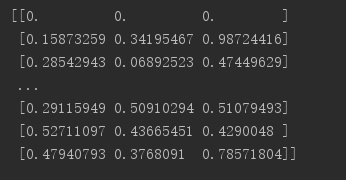
print(normDataSet)
return diffs,normDataSet,minValue
然后我们在主函数里面调用这个函数:
if __name__ == '__main__':
filename = "D:\python-workspace\Machine_Learing\KNN\datingTestSet2.txt"
#filematrix(filename)
empty_Mats, classLabelVectors = filematrix(filename)
#showdatas(empty_Mats, classLabelVectors)
autoNorm(empty_Mats)
运行结果如下:
7.测试算法
编写好了上面几个函数,这里我们还需要对这个算法的准确度进行估测,我们在样本数据中选取10%数据作为测试数据、后面90%的数据作为样本数据,看看分类效果如何,我们定义一个函数名为: dataTest(filepath)
"""
函数说明:分类器测试函数
Parameters:
无
Returns:
normDataSet - 归一化后的特征矩阵
ranges - 数据范围
minVals - 数据最小值
"""
def dataTest(filepath):
# 将返回的特征矩阵和分类向量分别存储到datingDataMat和datingLabels中
datingDataMat, datingLabels = filematrix(filepath)
# 取所有数据的百分之十
hoRatio = 0.10
# 数据归一化,返回归一化后的矩阵,数据范围,数据最小值
ranges,normMat, minVals = autoNorm(datingDataMat)
# 获得normMat的行数
rows = normMat.shape[0]
# 百分之十的测试数据的个数
nums = int(hoRatio * rows)
# 分类错误概率
errorRate = 0
for i in range(nums):
# 前nums个数据作为测试集,后rows - nums个数据作为训练集
classifyResult = classify(normMat[i,:],normMat[nums:rows,:],datingLabels[nums:rows],3)
print("分类结果:%d\t真实类别:%d" % (classifyResult, datingLabels[i]))
if classifyResult != datingLabels[i]:
errorRate += 1
print("错误率:%f%%" % (errorRate / float(nums) * 100))然后在主函数里面调用这个函数,如下所示:
if __name__ == '__main__':
filename = "D:\python-workspace\Machine_Learing\KNN\datingTestSet2.txt"
#filematrix(filename)
empty_Mats, classLabelVectors = filematrix(filename)
#showdatas(empty_Mats, classLabelVectors)
#autoNorm(empty_Mats)
dataTest(filename)
运行结果如下所示:
 |
 |
可以看出我们的错误率还是挺低的。
7.完整测试算法
这里我们定义一个算法名字叫做:classifyPerson(file_path)
def classifyPerson(file_path):
# 分类结果
resultList = ['不喜欢','有些喜欢','非常喜欢']
# 三维特征用户输入
ffMiles = float(input("每年获得的飞行常客里程数:"))
precentTats = float(input("玩视频游戏所耗时间百分比:"))
iceCream = float(input("每周消费的冰激淋公升数:"))
# 打开并处理数据
datingDataMat, datingLabels = filematrix(file_path)
# 训练集归一化
ranges,normMat, minVals = autoNorm(datingDataMat)
# 生成NumPy数组,输入测试集数据
inArr = np.array([ffMiles,precentTats, iceCream])
# 测试集归一化
norminArr = (inArr - minVals) / ranges
# 返回分类结果
classify_result = classify(norminArr,normMat,datingLabels,3)
#print(classify_result)
# 打印结果
print("你可能%s这个人" % (resultList[classify_result - 1]))然后在主函数调用:
if __name__ == '__main__':
filename = "D:\python-workspace\Machine_Learing\KNN\datingTestSet2.txt"
#filematrix(filename)
empty_Mats, classLabelVectors = filematrix(filename)
#showdatas(empty_Mats, classLabelVectors)
#diff,normDataSets,minValues = autoNorm(empty_Mats)
#autoNorm(empty_Mats)
# dataTest(filename)
classifyPerson(filename)测试结果如下:
输入数据 : 32729 9.164656 1.624565
期望值:3(非常喜欢)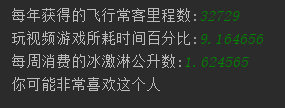
输入数据:54483 6.317292 0.018209
期望值:1(不喜欢)
以上就是KNN原理以及代码实现KNN算法的全过程。
获取上面需要的数据集以及SimHei.ttf,点击https://blog.csdn.net/wyf2017/article/details/96638855(关注这个公众号)
然后在后台回复:机器学习