一、SPP的应用的背景
在卷积神经网络中我们经常看到固定输入的设计,但是如果我们输入的不能是固定尺寸的该怎么办呢?
通常来说,我们有以下几种方法:
(1)对输入进行resize操作,让他们统统变成你设计的层的输入规格那样。但是这样过于暴力直接,可能会丢失很多信息或者多出很多不该有的信息(图片变形等),影响最终的结果。
(2)替换网络中的全连接层,对最后的卷积层使用global average pooling,全局平均池化只和通道数有关,而与特征图大小没有关系
(3)最后一个当然是我们要讲的SPP结构啦~
二、SPP结构分析
SPP结构又被称为空间金字塔池化,能将任意大小的特征图转换成固定大小的特征向量。
接下来我们来详述一下SPP是怎么处理滴~
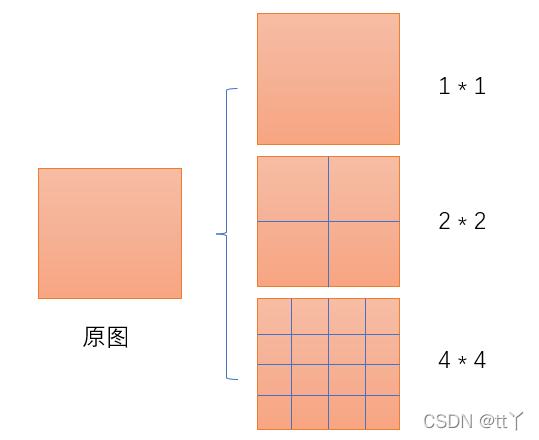
输入层:首先我们现在有一张任意大小的图片,其大小为w * h。
输出层:21个神经元 -- 即我们待会希望提取到21个特征。
分析如下图所示:分别对1 * 1分块,2 * 2分块和4 * 4子图里分别取每一个框内的max值(即取蓝框框内的最大值),这一步就是作最大池化,这样最后提取出来的特征值(即取出来的最大值)一共有1 * 1 + 2 * 2 + 4 * 4 = 21个。得出的特征再concat在一起。
而在YOLOv5中SPP的结构图如下图所示:

其中,前后各多加一个CBL,中间的kernel size分别为1 * 1,5 * 5,9 * 9和13 * 13。
三、SPPF结构分析
(x,y1这些是啥请看下面的代码)

四、YOLOv5中SPP/SPPF结构源码解析(内含注释分析)
代码注释与上图的SPP结构相对应。
class SPP(nn.Module):
def __init__(self, c1, c2, k=(5, 9, 13)):#这里5,9,13,就是初始化的kernel size
super().__init__()
c_ = c1 // 2 # hidden channels
self.cv1 = Conv(c1, c_, 1, 1)#这里对应第一个CBL
self.cv2 = Conv(c_ * (len(k) + 1), c2, 1, 1)#这里对应SPP操作里的最后一个CBL
self.m = nn.ModuleList([nn.MaxPool2d(kernel_size=x, stride=1, padding=x // 2) for x in k])
#这里对应SPP核心操作,对5 * 5分块,9 * 9分块和13 * 13子图分别取最大池化
def forward(self, x):
x = self.cv1(x)
with warnings.catch_warnings():
warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning忽略警告
return self.cv2(torch.cat([x] + [m(x) for m in self.m], 1))
#torch.cat对应concat
SPPF结构
class SPPF(nn.Module): # Spatial Pyramid Pooling - Fast (SPPF) layer for YOLOv5 by Glenn Jocher def __init__(self, c1, c2, k=5): # equivalent to SPP(k=(5, 9, 13)) super().__init__() c_ = c1 // 2 # hidden channels self.cv1 = Conv(c1, c_, 1, 1) self.cv2 = Conv(c_ * 4, c2, 1, 1) self.m = nn.MaxPool2d(kernel_size=k, stride=1, padding=k // 2) def forward(self, x): x = self.cv1(x)#先通过CBL进行通道数的减半 with warnings.catch_warnings(): warnings.simplefilter('ignore') # suppress torch 1.9.0 max_pool2d() warning y1 = self.m(x) y2 = self.m(y1) #上述两次最大池化 return self.cv2(torch.cat([x, y1, y2, self.m(y2)], 1)) #将原来的x,一次池化后的y1,两次池化后的y2,3次池化的self.m(y2)先进行拼接,然后再CBL欢迎大家批评指正,谢谢~
创作打卡挑战赛 赢取流量/现金/CSDN周边激励大奖