【深度学习】四位定长图形验证码识别(基于pytorch)
题记
验证码在我们网络中已经无处不在了,再爬虫中遇到也非常头疼,大部分都采用第三方平台如"超级鹰",进行识别,有没有什么方法可以不调第三方API呢。当然有那就是深度学习,本文介绍一下从数据集采集,
标注,构建网络,训练模型,测试结果,完整体系。找几张生活常见的验证码如登陆场景
在登陆模块最常见的就是这种四位数字+英文验证码接下来实现完整方案。
数据采集
深度学习的第一步就是采集数据,一个好的数据集就成功了一半了。数据采集也就是爬虫部分,大部分python学者因该都不陌生。代码如下:
header = headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/75.0.3770.142 Safari/537.36"
}
def save_dataset(path, mode, img):
with open(path, mode=mode) as f:
f.write(img)
def spider(url, num):
"""
4位验证码
:url 网站登录地址
:num 需要爬取图片个数
:return:
"""
for i in range(num):
try:
img = requests.get(url, headers=header, timeout=2).content
# img_name = ddddocrbz(img)
img_name = str(i)
# 保存路径
save_path = os.path.join("./train_all", img_name)
# 保存数据集
save_dataset(save_path, "wb", img)
print(f"采集成功4位验证码 {i} {img_name}")
except:
print("请求失败,重试")
spider("你要爬取的网站", 20000)
采集脚本很简单,就是将二进制文件,保存到本地文件夹当中。
数据标注
我们有了图片之后要干什么呢,当时是数据标注了,我们需要把图片重命名如:
![]()
这张图片我们需要让他的文件名是1a5z。
那我们因该怎么做呢,如果一张一张标注当然可以而且准确,但是非常耗费人工和时间,这里推荐一个开源库 ddddocr,里面有api可以识别验证码,如用如下:
pip install ddddocr -i https://pypi.tuna.tsinghua.edu.cn/simple
调用代码如下
import ddddocr
ocr = ddddocr.DdddOcr()
with open('1.png', 'rb') as f:
img_bytes = f.read()
res = ocr.classification(img_bytes)
print(res)
实例化ocr对象将一张二进制图片传入classification api即可得到结果,是不是一级棒。
https://github.com/sml2h3/ddddocr
这是ddddocr的github 如果想详细了的可以查看连接,让我们致敬大佬。
建议将我们爬取到的图片直接进行标注存储,这样就省去时间。代码如下:
ocr = ddddocr.DdddOcr(show_ad=False)
def save_dataset(path, mode, img):
with open(path, mode=mode) as f:
f.write(img)
def check_text(text: str, len_num: int):
if len(text) != len_num:
return False
text = text.lower()
captcha_array = "0123456789abcdefghijklmnopqrstuvwxyz"
for t in text:
if t not in captcha_array:
print("校验失败 {}".format(text))
return False
return text
def ddddocrbz(img_bytes):
res = ocr.classification(img_bytes)
return res
def spider(url, num):
"""
4位验证码
:url 网站登录地址
:num 需要爬取图片个数
:return:
"""
for i in range(num):
try:
img = requests.get(url, headers=header, timeout=2).content
# ddddocr识别结果
img_name = ddddocrbz(img)
# 校验识别结果是否在预期
img_name = check_text(img_name, 4)
if img_name:
# 保存路径
save_path = os.path.join("./qufushifan", img_name +"_" +str(time.time())+".png")
# 保存数据集
save_dataset(save_path, "wb", img)
print(f"采集成功4位验证码 {i} {img_name}")
except:
print("请求失败,重试")
spider("你要爬取的网站", 20000)
我们先实例化一次ocr对象写在第一行,免得每次都要实例化,可以看到 check_text用来校验ddddocr识别的内容,是否在预期之内,我这里将全部转为小写,并判断是否在其中和长度。然后直接将请求的二进制图片,传入ddddocr进行,将结果作为图片名称,为了保证名字不重复,加了时间戳。
采集+标注,结果如下
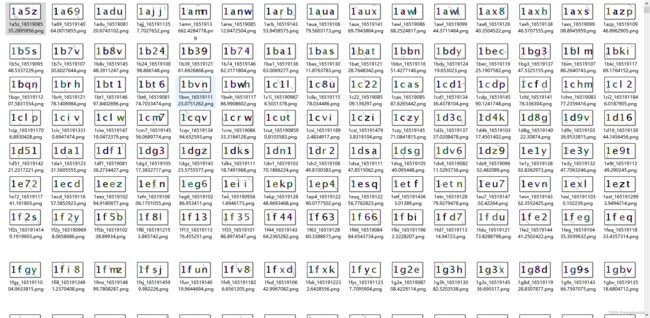
这样我们就有了训练集了,采集的时候记得再猜一部分作为测试集我得训练集是2w,测试集是2000。
加粗样式
深度学习开始
采用pytorch框架
Dataset
我们训练自己的数据要自己定义dataset
import os
from PIL import Image
from torch.utils.data import Dataset
from torchvision import transforms
import one_hot
class my_dataset(Dataset):
def __init__(self, root_dir):
super(my_dataset, self).__init__()
self.image_path = [os.path.join(root_dir, image_name) for image_name in os.listdir(root_dir)]
self.transforms = transforms.Compose(
[
transforms.ToTensor(), # 转为tensor类型
transforms.Resize([100, 300]), # 修改尺寸
transforms.Normalize([0.485, 0.456, 0.406], [0.229, 0.224, 0.225]), # 归一化
]
)
def __len__(self):
return self.image_path.__len__()
def __getitem__(self, index):
image_path = self.image_path[index]
image = Image.open(image_path).convert("RGB")
image = self.transforms(image)
label = image_path.split("/")[-1]
label = label.split("_")[0].lower()
# print(label)
try:
label_tensor = one_hot.text2Vec(label) # [4,36]
except:
label_tensor = one_hot.text2Vec("labe")
return image, label_tensor
if __name__ == '__main__':
train_data = my_dataset("数据集路径")
img, label = train_data[0]
继承torch Dataset实现__getitem__ 和__init__
init主要的功能是将我们的图片用
转换为tensor类型**,对图片修改尺寸 ,归一化
getitem将图片取出
PIL库读取进来转化为"RGB"
将图片和标签作为结果同时返回(我们标注时候是用下划线分开,取的时候通过下划线分割)
将标签进行onehot编码方便训练,可以看到统一将标签转为小写
我们可以拿出一张看一下:
![]()
onehot编码
import torch
captcha_array = list("0123456789abcdefghijklmnopqrstuvwxyz")
captcha_size = 4
def text2Vec(text):
"""
将标注文本转为onehot编码
:return vec
"""
vec = torch.zeros(captcha_size, len(captcha_array))
for i in range(len(text)):
vec[i, captcha_array.index(text[i])] = 1
return vec
def vec2Text(vec):
"""
将onehot编码转为标注文本
:return text
"""
vec = torch.argmax(vec, dim=1)
text = ""
for i in vec:
text += captcha_array[i]
return text
if __name__ == '__main__':
vec = text2Vec("aabcc1")
print(vec, vec.shape)
print(vec2Text(vec))
这是我们onehot转码的部分,里面用到了torch里的api如torch.zeros、torch.argmax
torch.zeros返回一个形状为为size,类型为torch.dtype,里面的每一个值都是0的tensor
torch.argmax返回指定维度最大值的索引
测试一下:
vec = text2Vec("abcd")
# 结果为
tensor([[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.],
[0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 1., 0., 0., 0., 0.,
0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0., 0.]]) torch.Size([4, 36])
output = vec2Text(vec)
# 结果为
abcd
就是一个tensor onehot的编码和解码
模型引用和训练
这里我们使用resnet34进行训练
import torch
import time
from tqdm import tqdm
from mydataset import my_dataset
from torch.utils.data import DataLoader
from torch import nn
from torch.optim import Adam
from Verification import Verification
import torchvision.models as models
if __name__ == '__main__':
train_dataset = my_dataset("/train_all")
train_dataloader = DataLoader(train_dataset, batch_size=64, shuffle=True, drop_last=True, num_workers=4)
verification = models.resnet34(num_classes=4 * 36).cuda(0)
loss_fn = nn.MSELoss().cuda(0)
optim = Adam(verification.parameters(), lr=0.001)
verification.train()
for epoch in range(20):
now = time.time()
print("训练epoch次数{}".format(epoch+1))
bar = tqdm(enumerate(train_dataloader), total=len(train_dataloader))
for i, (images, labels) in bar:
optim.zero_grad()
images = images.cuda(0)
labels = labels.cuda(0)
outputs = verification(images)
outputs = outputs.reshape(64, 4, 36)
loss = loss_fn(outputs, labels)
loss.backward()
optim.step()
if i % 1000 == 0:
print("训练次数{},损失率{}".format(i, loss.item()))
torch.save(verification, "Verification_resnet34_4w.pth")
- 实例化dataset路径为刚刚爬取标注的目录
- 创建训练集加载器train_dataloader将batch_size设置为64 shuffle=True随机打乱
drop_last舍弃不够一个batch_size的数据 - 创建模型 models.resnet34(num_classes=4 *
36).cuda(0)我们直接用resnet34为我们的训练模型num_classes为类型4位 x (0到9+a到z) - nn.MSELoss().cuda(0)损失函数为MSE
- Adam(verification.parameters(), lr=0.001),优化器采用Adam,学习率为0.001
- 开始训练20轮
- bar = tqdm(enumerate(train_dataloader),
total=len(train_dataloader))为进度条。具体可看tqdm库 - optim.zero_grad()梯度清零
- verification(images) 将图片传入模型
- outputs.reshape(64, 4, 36) 将结果reshape变为64batch_size,4_位数,36_类型
- loss = loss_fn(outputs, labels) 传入损失函数求loss值
- loss.backward()反向传播
- optim.step()更新参数
由于我是在GPU训练的所以要加上cuda(0)
如果没有GPU不加就好了
开始训练:

可以看出来loss一直在下降

训练结束
测试模型
from tqdm import tqdm
import common
from mydataset import my_dataset
from torch.utils.data import DataLoader
import one_hot
import torch
captcha_array = list("0123456789abcdefghijklmnopqrstuvwxyz")
if __name__ == '__main__':
test_dataset = my_dataset("/home/yons/Verification_Code/yzm46/yzm4_fixed/qufushifan_test")
test_dataloader = DataLoader(test_dataset, batch_size=1, shuffle=True)
model = torch.load("Verification_resnet34_4w.pth").cuda(0)
total = len(test_dataset)
yuce = 0
bar = tqdm(enumerate(test_dataloader), total=len(test_dataloader))
for i, (images, labels) in bar:
images = images.cuda(0)
labels = labels.cuda(0)
labels = labels.view(-1, len(captcha_array))
label_text = one_hot.vec2Text(labels)
output = model(images)
output_text = output.view(-1, len(captcha_array))
output_text = one_hot.vec2Text(output_text)
if output_text == label_text:
yuce += 1
print("正确率: {}%".format(yuce/total*100))
qufushifan_test目录为:

两千张测试集
将图片模型测试,得到onhot的tensor类型,再通过vec2Text转为字符串,与标注文本进行对比,最终得到准确率。
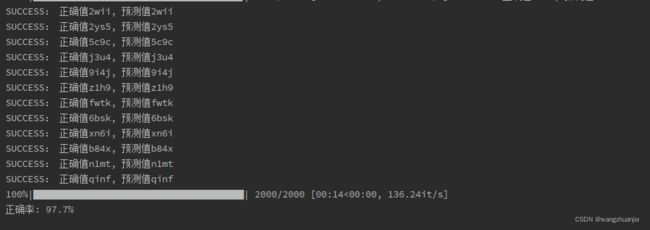
针对单一类型resnet34有很好的效果,虽然训练集只有2w张,准确率可以到达非常理想。
结束
resnet34和resnet18都不错,我这里采用的是resnet34因为比18多了16层所以导出的模型要大一些大约90多m,如果是resnet18大约40多m,针对单一类型的图形验证码还是很好解决的,如果要是别五位或者六位的也只需换一下参数,对于想解决此类验证码的朋友是一个不错的方法。
https://blog.csdn.net/qq_36551453?type=blog
这里@一下我的同事,也给予我很大帮助。
希望可以给朋友们一点帮助。
